今年在公司重構(寫)了一個老專案,踩了無數的坑,
中間好幾次遇到問題,甚至感覺專案可能要失敗了,好在最后終于成功上線了,
雖然被坑的不要不要的,但也從中領悟到了不少東西,在這里記錄一下,順便分享給大家樂呵樂呵,
先簡單介紹下專案,一個面向C端用戶的服務,主要提供包括動態、評論、圈子、好友、關注、Feed等常見的社區功能,另外還有其他一些個性化的功能,
榷訓比較高,整個服務QPS上萬,高頻業務,單個介面QPS上千,單項業務資料量過億,比如評論,
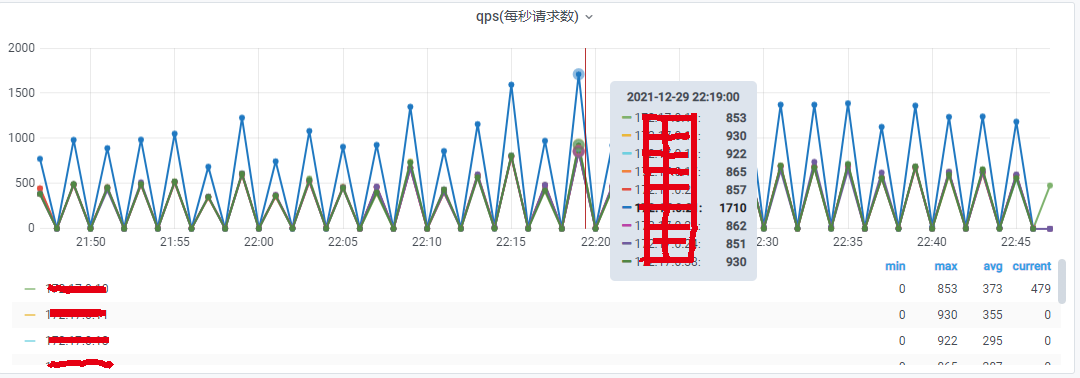 圖1.qps監控圖
圖1.qps監控圖
在上述高并發、海量資料的情況下,整個系統設計時需要注意的坑,和我總結的一些經驗:
資料庫層面
MySQL分庫分表
因為是重寫整個專案,包括重新設計底層資料庫,必然要考慮到分庫分表,
最初在網上參考了一些分庫分表的原則,實際操作中,發現大部分資料都有些縹緲,
如果是簡單的應用怎么分表,甚至不分都可以,所以這些原則你也不能說它是錯的,但它在你最需要參考的時候往往沒啥用,
下面說下我個人總結的一些原則:
先說分庫
分庫的主要目標,應該是緩解主庫(Master)的壓力,
絕大部分服務都是讀多寫少,在讀寫分離,1主N從的情況下,即便為了保證一致性,部分讀請求路由到主庫,主庫壓力依舊很低,
通過監控服務的寫請求量和資料庫服務器的CPU壓力等性能指標,只要主庫壓力不大,就沒必要分庫,讀庫如果壓力大,直接加從庫實體即可,
一種極端的情況,就是分表數量過多了,一個庫里表數量遞增,成萬上億了,那還是分庫的好,
還有一點,從運維的角度考慮,單庫冷備,資料不應該超過500GB,如果單庫資料量達到1個TB,運維也不好備份,為了正常備份也要分庫,
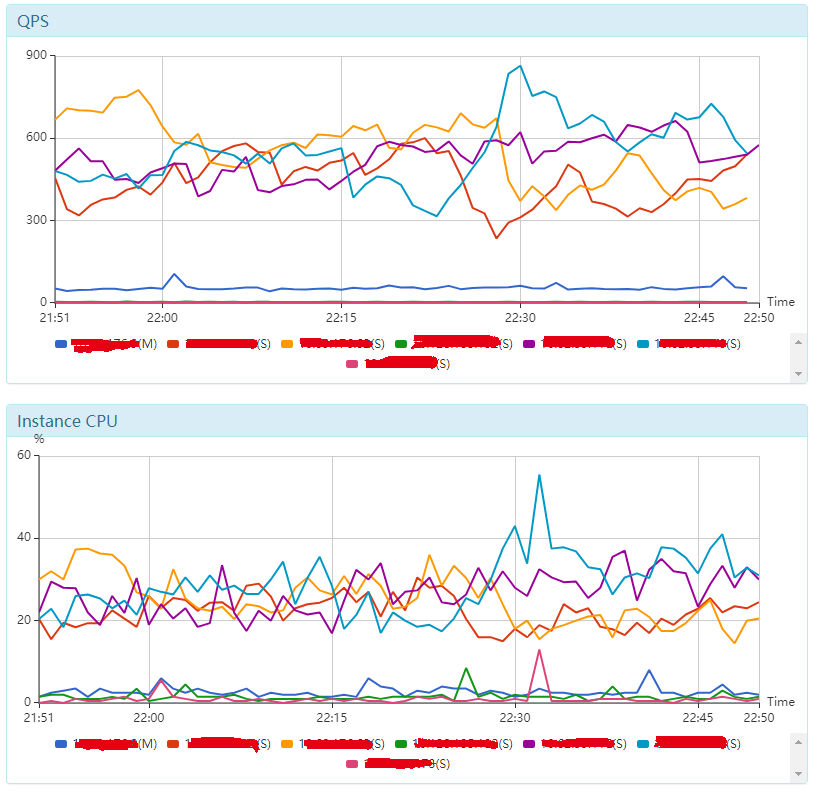
圖2.資料庫監控圖
再說分表
在請求量不大 或 資料量不大的情況下,分不分表都無所謂,
考慮mysql的性能、樹的深度等,可以簡單的認為單表500W左右即可,
但實際中往往需要結合具體的業務設計和查詢場景,
比如,1張幾千萬資料量的訂單表,如果業務上,只需要根據主鍵或唯一索引,每次查詢一條記錄,那么不分表也是完全可行的,
但有時出于運維需要,分表會更方便一些,比如研發人員可能會想手寫一些SQL上去進行一些范圍查詢,為排查問題提供一些方便,(這里說的方便是指相對單表幾千萬,如果查詢欄位沒有索引,范圍查詢基本不可用,)
特別需要注意的是,如果一項業務資料需要高頻的用到 count陳述句查詢總數 或 order by進行排序,我建議分的表越多越好,管他3721先分1000張表再說,
多分表的好處就是,只要表中的資料量足夠少,即便你索引設計的不好,甚至查詢完全不走索引,也不容易產生慢查詢,哈哈哈!
小結:這次重構就被老系統的1000張表給坑了,因為每張表只有幾萬條資料,我覺得太浪費了, 想當然的縮到了20張表,
但又沒有很好的去分析查詢場景,設計索引,導致上線時,只放了1%的量,就崩了,看監控全部都是慢查詢,
當然,最終我是通過優化索引來解決慢查詢,而不是加分表數量,但在有些情況下,這也是一種思路,
MySQL索引、欄位設計
說到欄位設計,之前自己設計表,總喜歡加些固定欄位,比如create_time, create_user, is_delete等,因為運維方便,
重構了這個系統之后發現,可快拉倒吧,性能都成問題呢,就別整這些花里胡哨的了,
欄位能少則少,名字能短則短,型別能用tinyint就不要用int,

“桌子有多小就要多小,椅子有多擠就要多擠,不要讓客人坐得那么舒服,吃完就趕快走,吸管有多粗就要多粗,冰有多大塊就放多大塊,這樣汽水就可以一口喝完再買另一杯了,你是新來的嗎,這還要我教,一點變通都不會,笨蛋,”
——周星馳《食神》
索引這塊低頻小資料量無所謂,高頻海量資料務必所有查詢走索引,
再看一些實際例子,
1. is_delete 欄位(邏輯洗掉)
假設以評論為例,單表500w,單條動態下平均上萬條評論,
業務場景中要查詢動態下的所有評論,where 子句要加上條件 is_delete = 0,
如果查詢出符合條件的結果集,有幾萬甚至十幾萬條,不把 is_delete 欄位加到聯合索引中,這必將是一條慢查詢,再加上高并發,只要幾百的qps,很容易把服務打崩,
每個查詢加上這么一個條件又有點畫蛇添足,除非運維需要,基本上不會有業務要查詢 is_delete = 1的情況,索性直接物理洗掉,再加個歸檔表,要找回時,去歸檔表里找,
這樣就不用在每個聯合索引里多加一個欄位了,
2. tinyint 和 int
tinyint 主要用于一些狀態標志位,比如 審核狀態:0-未審核 1-審核通過 2-審核未通過,
使用tinyint 一是節約空間,二是方便識別,一看就知道是標志位,
另外這種標志位經常出現在查詢條件中,但又不會單獨作為查詢條件,因此建立索引時,必然是在聯合索引中出現,而聯合索引是有長度限制的,雖然大部分時候都不會遇到,但還是值得注意,
另外有的人標志位喜歡用byte,但在代碼里要轉型就很蛋疼了,
3.聯合索引的設計
就一個原則:查詢條件里有的,都加進去,
除了要把 where 子句中的條件欄位加進去外,在有order by 的情況下,還要把 order by 的欄位加到最后,
比如:查詢動態id是123,狀態是審核通過且上線的20條評論,按時間倒序排列,
select * from comment where news_id = 123 and audit_status = 1 and online_status = 1 order by ctime desc limit 20
那我們應該建立聯合索引 news_id, audit_status, online_status, ctime
注意:在網上參考資料時,很多都說索引的建立原則,欄位的區分度要高,
這個原則好像并沒什么道理,至少在建立聯合索引時不適用,
在建立單一索引時,也沒有想到適用的具體場景,
比如有單表5千萬條身份資訊,其中20條gender=1,5千萬條gender=0,
如果你就是要查詢gender=1的串列,如果不在gender列建立索引,即便只有20條資料,也必然是個慢查詢,
小結:索引的建立,必須針對查詢陳述句,結合實際查詢場景考慮如何去建索引,
歡迎關注我的公眾號

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/398379.html
標籤:Java