引子
剛才下班回家路上,無意中聽到大街上放的歌,歌詞有這么一句:“氈房外又有駝鈴聲聲響起,我知道那一定不是你”,這一句我似乎聽懂了歌者的魂牽夢繞和絕望,如果在十年前我大概只能感受出悠揚的聲調里溢位的悲涼吧,
在作業上,我沒有十年的時間來把思考能力上升一個等級,對于一個問題,需要在很短的時間反復思考,深層次的弄懂,懂得,有三個初級境界,對應三個方法:
1>字面理解-what、why、how
2>前因后果-5why
3>選擇最優-SMART
想了解what、why、how黃金圈法則或者5why分析法可參考我之前的文章:《代碼榮辱觀-以運用風格為榮,以隨意編碼為恥》;想了解SMART原則可參考我之前的文章:《知名互聯網公司需要什么樣的人才》,
回到主線:為什么是初級境界?我自己也不知道更高級別的境界是有什么,因為自己境界沒有達到,但是至少有:刻入骨髓 這一境界,
舉個例子:十二年前,有次在大街上走,我走過一個【北京銀行】的大門,銀行二樓的玻璃嘩啦啦掉下來,我知道身后有危險,有很多玻璃落到了距離我身后不到十公分的地方,我當時很鎮定的繼續向前走,等過了危險區,我很想神經質的大叫,因為走路時再多猶豫2秒,可能腦袋上被扎的全是玻璃,所以走路時時時刻刻都會想著離樓房遠一些,并且好像感受到了自己腦袋被玻璃扎,我理解這可以算作把樓房玻璃很危險的理解刻入骨髓,
字面理解
今天舉的這個例子純粹是技術問題,終于不需要用蹩腳的比喻把事情描述的更難理解來達到脫敏的效果,
what
我們采用的是dubbo服務,這是個穩定成熟的RPC框架,但是我們在某些應用中會發現,只要這個應用一發布(或者重啟),就會出現請求超時的問題,如下圖所示: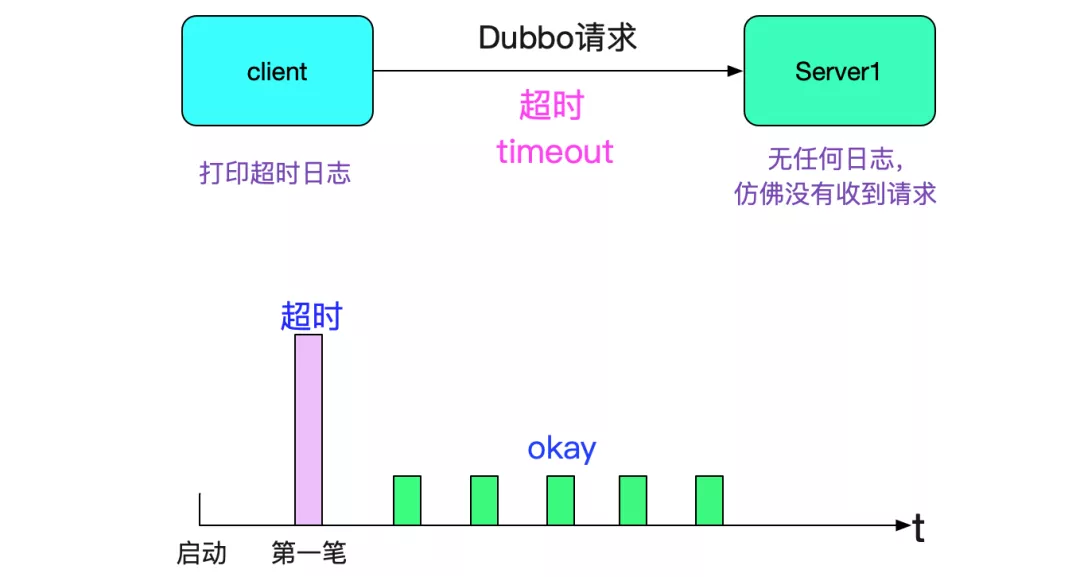
而且都是第一筆請求會報錯,之后就再也沒有問題了,
why
我當時很快就定位了問題,因為在內網wiki上、技術博客上,很多人都寫了這個坑,所以不講排查思路了,直接講結論:
在server端連接數過多, linux系統有個連接佇列溢位了,溢位的連接被丟棄,但是client端不知道,仍然給此server發送訊息,連接沒有建立自然發送不成功,client發第一筆訊息超時,相當于探活失敗,client端于是重新建立連接,連接成功建立后開始正常的通信,所以后面都成功了,
how
怎么來解決這個問題呢?四個思路,
第一個是佇列溢位了,那就說明佇列太小,可以把佇列值改大,dubbo使用的是一個寫死的默認值:50,可以修改dubbo原始碼把值改大或者干脆動態獲取佇列值,
第二個是佇列數不變,實際連接數減少,減少server端的連接方,比如有些client端其實沒有實際業務呼叫這個server端了,就雙方聊聊把無用的依賴去掉,
第三個是可以讓服務端在丟棄連接的同時給client端通知一下,linux有個系統引數/proc/sys/net/ipv4/tcp_abort_on_overflow,默認為0,不會給client端發通知,但是設定為1時會給server端發一個reset請求,客戶端收到會重連,
第四個是讓client端定時心跳探測,探測發現超時了馬上重連,超時的那筆只是探測請求,不影響業務,

前因后果
作為軟體工程師,重要的一個軟素質是批判性思維,多問幾個問題,找到答案,理解就能更進一步,
Q1: 提到溢位的佇列到底是什么佇列?
A: 下圖是TCP連接三次握手的示意圖,
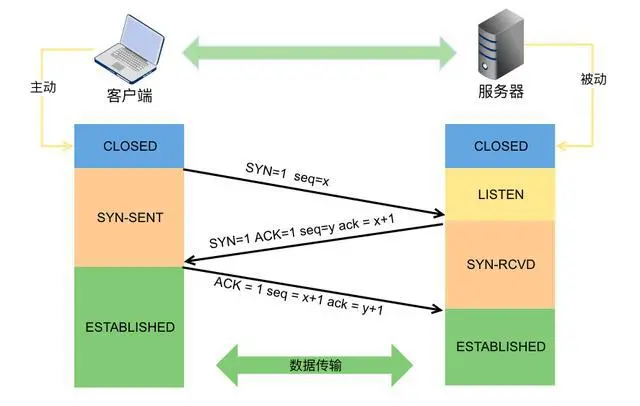
一次握手:
一開始client端和server端都處于closed狀態(未建立連接狀態),client端主動向server端發起syn請求建立連接請求,server端收到后將與client端的連接設定為listen狀態(半連接狀態),問題來了,server端怎么保存與client端的狀態呢?總需要有地方存呀,存的地方就是佇列,連接佇列又叫backlog佇列,到這里,server端與client端的半連接建立了,這里的backlog佇列也叫半連接佇列,
二次握手:
server端回傳ack應答+syn請求給client,意思是:ack我收到了你的請求,syn你收到我的了沒?client端收到server端回應,將自己的狀態設定為established狀態(連接狀態),
三次握手:
client向server端發送一個ack回應,告訴server端收到,然后server端收到后將與client端的連接設定為established狀態(全連接狀態),同樣,全連接狀態在server端也需要一個backlog佇列存盤,這里的backlog佇列也叫全連接佇列,
Q2: backlog佇列到底是全連接佇列還是半連接佇列?
A: 這個問題讓我想起別的事情,我大學是東北大學,有次看到校內論壇上有個帖子:“東北大學和東南大學誰更有資格叫東大?”最終沒啥結論,東北大學內網再論證自己該叫東大,東南大學內網肯定不認,
但是backlog的問題還是有達成共識的可能的,backlog其實是一個連接佇列,在Linux內核2.2之前,backlog包括半連接狀態和全連接狀態兩種佇列,在Linux內核2.2之后,分離為兩個backlog來分別限制半連接(SYN_RCVD狀態)佇列大小和全連接(ESTABLISHED狀態)佇列大小,
半連接佇列:
佇列長度由/proc/sys/net/ipv4/tcp_max_syn_backlog指定,默認為2048,
全連接佇列:
佇列長度由/proc/sys/net/core/somaxconn和使用listen函式時傳入的引數,二者取最小值,默認為128,
在Linux內核2.4.25之前,是寫死在代碼常量 SOMAXCONN ,在Linux內核2.4.25之后,在組態檔/proc/sys/net/core/somaxconn中直接修改,或者在 /etc/sysctl.conf 中配置 net.core.somaxconn = 128 ,
想到這里我恍然大悟,東北大學、東方大學、東南大學在自己的地盤都有資格簡稱東大(這里講這個插曲是為了澄清一件事情:我昨天下午4點發的文章里標題是一個北大妹子,那篇文章是幫朋友的忙,北大妹子不是我,我是東大妹子),
Q3: 到底是全連接佇列還是半連接佇列溢位導致了超時?
A: server端與client端進行二次握手的前提是server端認為自己與client建立連接是沒有任何問題的,如果server端半連接佇列溢位了,自己這邊都沒有處于半連接狀態,自然不會發送ack+syn給client端,client端做的應該是重新嘗試建立連接,不是發送資料,請求會發送到已經建立好連接的server端(server端是多機器多活部署的)不會造成請求超時,
而二次握手一旦完成,進行三次握手時,如果全連接佇列已滿,服務器收到客戶端發來的ACK, 不會將該連接的狀態從SYN_RCVD變為ESTABLISHED,但是客戶端已經認為連接建立好了開始發送資料了,這時候是有可能造成超時的,
Q4: 全連接佇列滿了之后server端是怎么處理的呢?
當全連接佇列已滿時,則根據 tcp_abort_on_overflow 的值來執行相應動作,
tcp_abort_on_overflow = 0 處理:
則服務器建立該連接的定時器,這個定時器是一個服務器的規則是從新發送syn+ack的時間間隔成倍的增加,比如從新了第二次握手,進行了5次,這五次的時間分別是 1s, 2s,4s,8s,16s,這種倍數規則叫“二進制指數退讓”(binary exponential backoff),
給客戶端定時從新發回SYN+ACK即重新進行第二次握手,(如果客戶端設定的超時時間比較短就很容易出現例外)服務器重新進行第二次握手的次數由/proc/sys/net/ipv4/tcp_synack_retries 這個linux系統引數決定,
tcp_abort_on_overflow = 1 處理:
當 tcp_abort_on_overflow 等于1 時,發送一個reset請求重置連接,客戶端收到可以嘗試再次從第一次握手開始建立連接或者其他處理,
Q5: 怎么驗證確實是backlog佇列溢位呢?
ss 是 Socket Statistics 的縮寫,ss 命令可以用來獲取 socket 統計資訊,ss -l 是顯示listen狀態的資料,如下所示:
[root@localhost ~]# ss -lState Recv-Q Send-Q Local Address:Port Peer Address:PortLISTEN 0 128 *:http *:*LISTEN 0 128 :::ssh :::*LISTEN 0 128 *:ssh *:*LISTEN 0 100 ::1:smtp :::*LISTEN 0 100 127.0.0.1:smtp *:*
在LISTEN狀態,其中 Send-Q 即為全連接佇列的最大值,Recv-Q 則表示全連接佇列中等待被server段處理的數量,數量為0,說明處理能力很夠;Send-Q =Recv-Q ,滿了,再來就丟棄掉了,
但是這是一個實時的資料,一段時間有擁塞,過一會兒就好了怎么查呢?
可以使用netstat -s 可以查看被全連接佇列丟棄的資料,
[root@localhost ~]# netstat -s | grep "times the listen queue of a socket overflowed"35552 times the listen queue of a socket overflowed
補充說明: 半連接佇列很多文章叫做SYN QUEUE佇列,全連接佇列很多文章叫做ACCEPT QUEUE佇列,這是一些研究linux原始碼的同學根據原始碼的命名來叫的,

選擇最優
馬云說:“選擇比努力重要” ,懂得三境界,第三境界的重點不是懂,而是得,最終要根據懂了的內容決策出最優方案,
除了字面理解里提到的四種思路,前因后果里還提到了重新進行第二次握手的次數由/proc/sys/net/ipv4/tcp_synack_retries 這個linux系統引數決定,
分別來分析一下各個方案的可行性和優缺點:
方案1:把佇列值調大
這個佇列值是指全連接佇列,調大之后,client端的二次握手就在這個佇列里排隊等待server端真正建立連接,假設佇列值調到上限65535,第65535號請求在排隊的程序,client端是established狀態,資料可能會發送過來,服務端還沒有established狀態,還不能處理,
到什么時候能處理呢?65535個請求全部處理完需要13s的樣子,對一般的服務來說妥妥的超時,所以nginx和redis都是使用的511,讓回應時間在100ms內完成,
方案2:減少連接數
只要能減少的下來,這是理想的法子,現在server端都過載了,可想而知,接入的client端不再少數,推動他們一個個去梳理和改造,就算大家執行力很強,把改下的下了,可想而知,廢棄的也一般不會有多少,不展開了啊,現在已經三千多字了,爭取五千字內結束,
還有沒有別的方法減少連接數呢?最簡單的就是使用分治法,
劃分子集
跟同事討論請教的時候,他給我提供了一個劃分子集的思路,讓client端只和server端一部分服務器建立連接,有兩種分配誰跟誰連接的演算法,一個是隨機演算法,但是server端服務器我最多見過幾千臺組成一個集群的,對隨機(雖然連接數是服務器臺數的n倍)來說,樣本是很少的,會很不均勻;另外一個是確定性演算法,思路也很簡單,連接的client端及數量是確定的,那就排個序,按照server端數量分配一下,這樣連接數是均勻的,但是就沒辦法做到請求級別的流量均勻,
粘滯連接
盡可能讓客戶端總是向同一提供者發起呼叫,除非該提供者掛了,再連另一臺,<dubbo:protocol name="dubbo" sticky="true" />,如果每個client端都只和一個server端建立連接,那server端壓力就是原來的(1/機器臺數),不夠加機器就行了,橫向可擴展,

這種做法最大的問題是高可用和并發請求的問題,對于可用性要求不高、請求量不高的服務(比如后臺定時任務定時拉取可重試)其實是可以用的,但是這需要client端的自覺性,而對維護這個client端的人員來講,他們自身是沒有好處的,因為原本也就是只是重啟時發生一次超時嘛,所以客戶端在可以的情況下愿不愿意這樣做就看格局了,
方案3:服務端通知
服務端通知上面前因后果中有提到可以設定
/proc/sys/net/ipv4/tcp_synack_retries
重新進行幾次進行第二次握手,但是這個階段,client端可能會發資料包過來造成超時;另外,可以設定
/proc/sys/net/ipv4/tcp_abort_on_overflow=1
整個握手直接斷掉,client端是closed狀態,它會找其他established狀態的連接進行資料包發送,不會造成超時,事實上,調研了一些大廠,
tcp_abort_on_overflow=1是作為默認配置的,
方案4:客戶端探測
客戶端探測想自己做的話比較麻煩,比如說把,客戶端調了n個服務,每個服務建立了n個連接,資源開銷大,還必須要復用這些已經建立的連接,復雜度高,
其實provider 和consumer 有雙向心跳(探測)的,那為什么沒檢測出并進行重連?
這個首先面臨的問題:client端認為連接成功了,但server端認為沒有成功,那么server端 是不會發送心跳給 client端的,
client端是不是應該發心跳給server端呢?是的,原來使用dubbo2.5.3版本時3分鐘client端會發送一個探測,之后把問題連接closed掉,只是dubbo 2.6.9使用了netty4,他們強強聯手搞出來一個bug,探測機制楞沒生效!
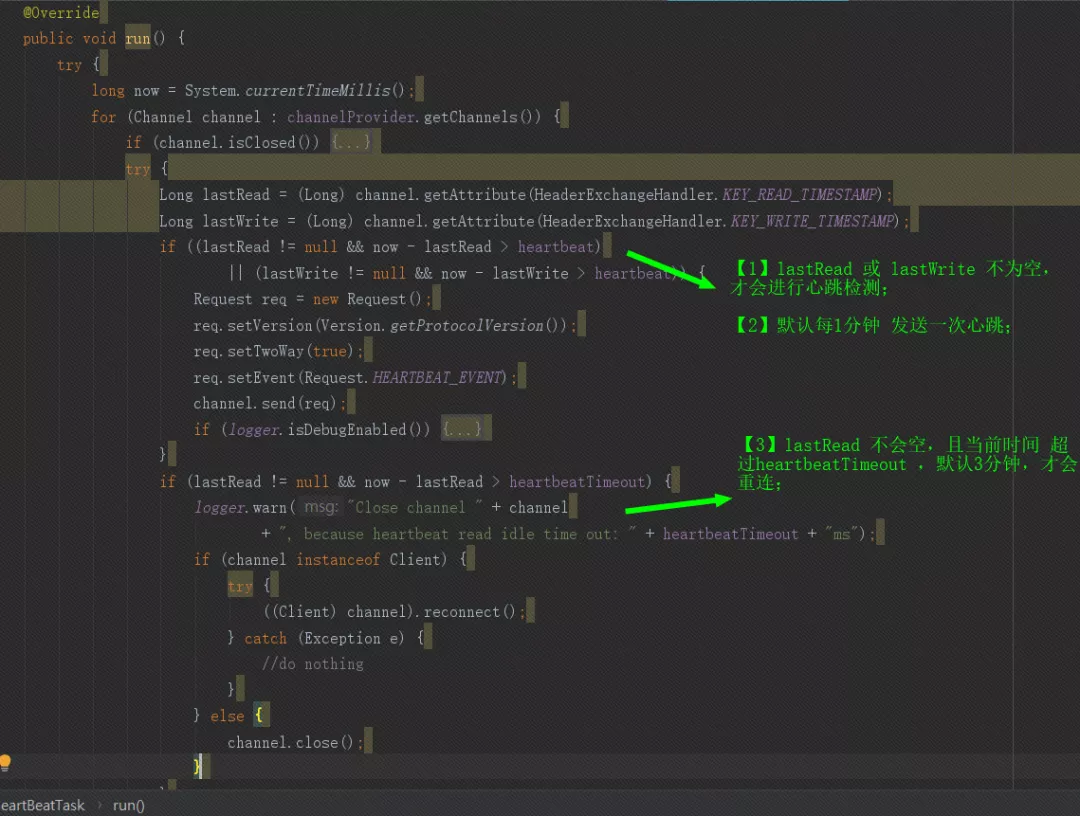
心跳有個條件,就是lastRead 和 lastWrite 不為空,那就需要看哪里設定了這兩個引數,通過代碼查到client端連接成功和server端連接成功的時候都會設定,這里只考慮client端情況,對比netty3發現netty4里少了
NettyServerHandler的handler鏈處理,這個handler鏈處理就是用來初始化那兩個值的,
除了改client端原始碼,有沒有別的方法讓client端探測生效呢?其實什么都不用TCP就有keepalive(探活)機制,默認是7200秒,也就是2小時,可以修改:
/proc/sys/net/ipv4/tcp_keepalive_time
單位是秒
好了,解決問題的方法就講到這里,完結撒花~~
咦,說好的SMART原則呢?
S代表具體的(Specific)
M代表可衡量的(Measurable)
A代表可達到的(Attainable)
R代表與最終目標是相關的(Relevant)
T代表有明確的截止期限(Time-bound)
編程一生,公眾號:編程一生知名互聯網公司需要什么樣的人才
方案這么多,哪種是最好的呢?看場景,方案4提到了問題其實是開源組件有bug導致,但改開源組件,看公司規劃、開源社區支持,A可行性上有制約;
方案2涉及很多整改和推動,T時效上有制約,方案雖多,排除法排除一下能剩下一個就不錯了,

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/401394.html
標籤:Java