我有一個測驗資料框df,我想從中洗掉Hits列中的重復值,但不洗掉與重復值關聯的行。然而,條件是僅在行索引的某些特定范圍內進行洗掉。
df <- data.frame(
Hits = c("#a", "#ID:987129470", "#b", "Hit1", "Hit1", "Hit2", "Hit3", "Hit3", "#a", "#ID:6971324987", "#b", "Hit1", "Hit2", "Hit2", "Hit3"),
Category1 = c(NA, NA, NA, 0.001, 0.001, 0.002, 0.003, 0.003, NA, NA, NA, 0.023, 0.341, 0.341, 0.569),
Category2 = c(NA, NA, NA, 100, 100, 99, 98, 98, NA, NA, NA, 100, 95, 95, 97),
Category3 = c(NA, NA, NA, 100, 100, 99, 98, 98, NA, NA, NA, 98, 97, 97, 92))
df 看起來像這樣
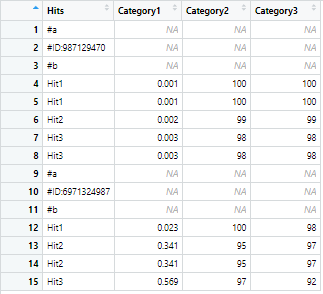
在這種情況下,要執行洗掉操作的行索引的范圍是4:8和12:15。基本上,每個 ID 下的重復命中將被洗掉,保持其他列中的關聯值完整無缺。輸出應該是這樣的
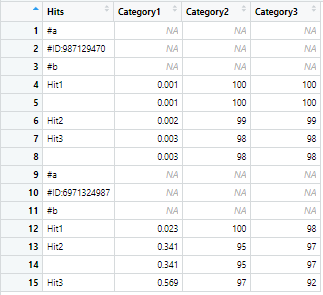
在原始資料幀(有 ~100k 行!)中,無法指定范圍。我該如何解決這個問題?
uj5u.com熱心網友回復:
首先通過開始使用#a
然后使用ifelse陳述句來創建組。
library(dplyr)
df %>%
group_by(id_Group = cumsum(Hits=="#a")) %>%
mutate(Hits = ifelse(duplicated(Hits), "", Hits)) %>%
ungroup() %>%
select(-id_Group)
Hits Category1 Category2 Category3
<chr> <dbl> <dbl> <dbl>
1 "#a" NA NA NA
2 "#ID:987129470" NA NA NA
3 "#b" NA NA NA
4 "Hit1" 0.001 100 100
5 "" 0.001 100 100
6 "Hit2" 0.002 99 99
7 "Hit3" 0.003 98 98
8 "" 0.003 98 98
9 "#a" NA NA NA
10 "#ID:6971324987" NA NA NA
11 "#b" NA NA NA
12 "Hit1" 0.023 100 98
13 "Hit2" 0.341 95 97
14 "" 0.341 95 97
15 "Hit3" 0.569 97 92
uj5u.com熱心網友回復:
另一種可能的解決方案:
library(tidyverse)
df <- data.frame(
Hits = c("#a", "#ID:987129470", "#b", "Hit1", "Hit1", "Hit2", "Hit3", "Hit3", "#a", "#ID:6971324987", "#b", "Hit1", "Hit2", "Hit2", "Hit3"),
Category1 = c(NA, NA, NA, 0.001, 0.001, 0.002, 0.003, 0.003, NA, NA, NA, 0.023, 0.341, 0.341, 0.569),
Category2 = c(NA, NA, NA, 100, 100, 99, 98, 98, NA, NA, NA, 100, 95, 95, 97),
Category3 = c(NA, NA, NA, 100, 100, 99, 98, 98, NA, NA, NA, 98, 97, 97, 92))
df %>%
group_by(Hits, if_else(str_detect(Hits, "Hits*"), 1, 0) %>% data.table::rleid(.)) %>%
mutate(Hits = if_else(row_number() > 1 & str_detect(Hits, "Hits*"), "", Hits)) %>%
ungroup %>% select(-last_col())
#> # A tibble: 15 × 4
#> Hits Category1 Category2 Category3
#> <chr> <dbl> <dbl> <dbl>
#> 1 "#a" NA NA NA
#> 2 "#ID:987129470" NA NA NA
#> 3 "#b" NA NA NA
#> 4 "Hit1" 0.001 100 100
#> 5 "" 0.001 100 100
#> 6 "Hit2" 0.002 99 99
#> 7 "Hit3" 0.003 98 98
#> 8 "" 0.003 98 98
#> 9 "#a" NA NA NA
#> 10 "#ID:6971324987" NA NA NA
#> 11 "#b" NA NA NA
#> 12 "Hit1" 0.023 100 98
#> 13 "Hit2" 0.341 95 97
#> 14 "" 0.341 95 97
#> 15 "Hit3" 0.569 97 92
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/402321.html
標籤: