我有一個表 df1,其中包含 Itemlist1 和 Itemlist2 列,其中該表中的每個單元格可以包含從 1 開始的任意數量的專案。示例:一個單元格中可以有 1 個專案 A,另一個單元格中可以有 2 個專案 B、C 和 3 A、D、E 項在另一個。
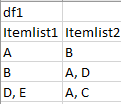
我有另一個表 df2,其中包含每個專案的價格和成本。
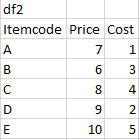
我想用 2 個新列添加到 df1、Totalprice 和 Totalcost 創建這個最終的 df。Totalprice 和 Totalcost 是 df1 每一行中所有專案的總和。示例:在第 2 行中,Totalprice 是專案 B、A、D 的價格總和,而 Totalcost 是專案 B、A、D 的成本總和。
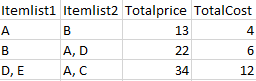
我正在考慮將所有專案組合到 df1 中的一列中,將每個專案拆分為一列,然后將其與 df2 合并。這就是我迄今為止所擁有的。
df1["items"]=df1[["Itemlist1","Itemlist2"]].agg(', '.join,axis=1)
df3=df1['items'].str.split(', ',expand=True)
由于每行中的專案數不固定,列名也不匹配,如何回圈將其與 df2 合并?
或者,是否有更好的方法來達到我想要的最終 df?請提出任何建議。謝謝你。
uj5u.com熱心網友回復:
從您的 df3,執行replace,然后sum使用axis=1
cost_dict = dict(zip(df2.Itemcode,df2.Cost))
price_dict = dict(zip(df2.Itemcode,df2.Price))
df1['totalcost'] = df3.replace(cost_dict).sum(axis=1)
df1['totalprice'] = df3.replace(price_dict).sum(axis=1)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/403828.html
標籤: