我正在使用這樣的資料集,其中“國家/地區名稱”的值重復多次,“指標名稱”重復多次。
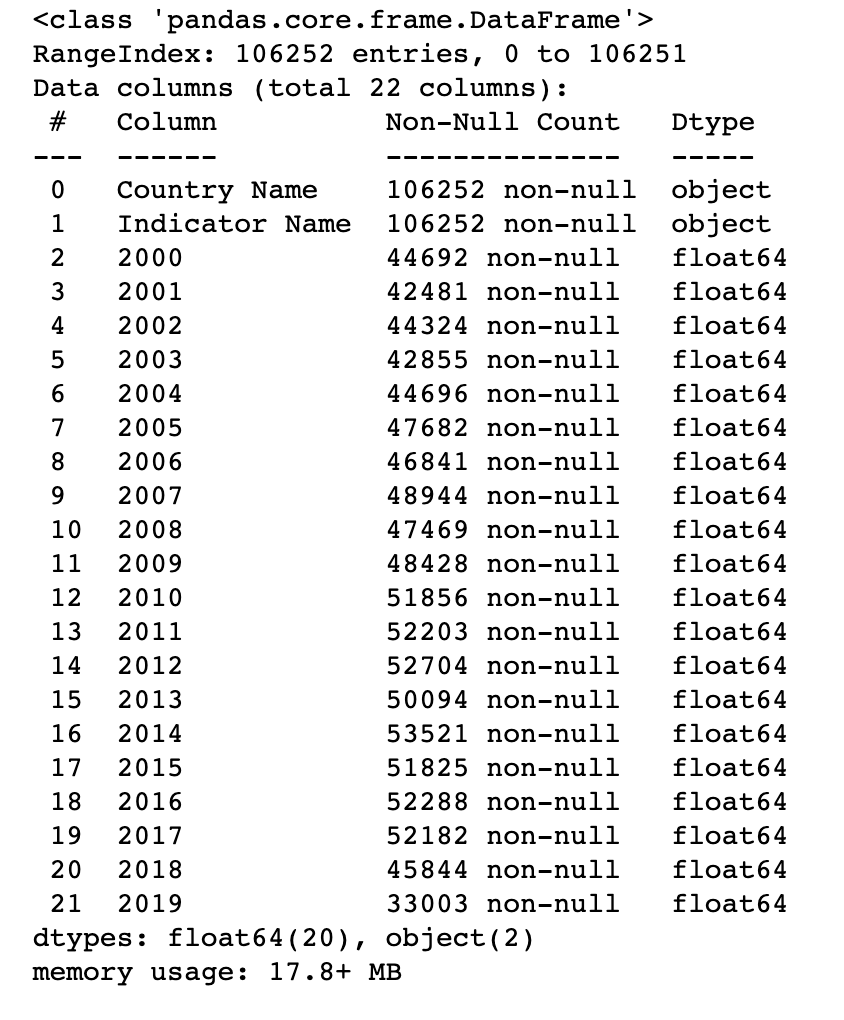
我想創建一個新的資料集,它的列是這樣的
Year CountryName IndicatorName1 IndicatorName2 ... IndicatorNameX
2000. USA. value1. value2. valueX
2000. Canada. value1. value2. valueX
2001. USA. value1. value2. valueX
2001. Canada. value1. value2. valueX
有可能做到嗎??
感謝提前!
uj5u.com熱心網友回復:
您可以pivot按照@Chris 的建議使用,但您也可以嘗試:
out = df.set_index(['Country Name', 'Indicator Name']).unstack('Country Name').T \
.rename_axis(index=['Year', 'Country'], columns=None).reset_index()
print(out)
# Output
Year Country IndicatorName1 IndicatorName2
0 2000 France 1 3
1 2000 Italy 2 4
2 2001 France 5 7
3 2001 Italy 6 8
設定Pandas / MRE:
data = {'Country Name': ['France', 'Italy', 'France', 'Italy'],
'Indicator Name': ['IndicatorName1', 'IndicatorName1',
'IndicatorName2', 'IndicatorName2'],
2000: [1, 2, 3, 4],
2001: [5, 6, 7, 8]}
df = pd.DataFrame(data)
print(df)
# Output
Country Name Indicator Name 2000 2001
0 France IndicatorName1 1 5
1 Italy IndicatorName1 2 6
2 France IndicatorName2 3 7
3 Italy IndicatorName2 4 8
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/403834.html
標籤: