我試圖從這個世界銀行 API 獲取一個資料表,其中僅獲取國家、年份和價值,但我似乎無法僅過濾我想要的資料。我已經看到這些型別的問題已經被問到,但所有的答案似乎都沒有奏效。
真的很感激一些幫助。謝謝!
import requests
import pandas as pd
from bs4 import BeautifulSoup
import json
url ="http://api.worldbank.org/v2/country/{}/indicator/NY.GDP.PCAP.CD?date=2015&format=json"
country = ["DZA","AGO","ARG","AUS","AUT","BEL","BRA","CAN","CHL","CHN","COL","CYP", "CZE","DNK","FIN","FRA","GEO","DEU",
"GRC""HUN","ISL","IND","IDN","IRL","ISR","ITA","JPN","KAZ","KWT","LBN","LIE","MYS","MEX","MCO","MAR","NPL","NLD",
"NZL","NGA","NOR","OMN","PER","PHL","POL","PRT","QAT","ROU","SGP","ZAF","ESP","SWE","CHE","TZA","THA","TUR","UKR",
"GBR","USA","VNM","ZWE"]
html={}
for i in country:
url_one = url.format(i)
html[i] = requests.get(url_one).json()
my_values=[]
for i in country:
value=html[i][1][0]['value']
my_values.append(value)
編輯
我的資料目前看起來像這樣,我正在嘗試提取 '{'country': {'id': 'AO', 'value': 'Angola''}、'date' 和'價值'
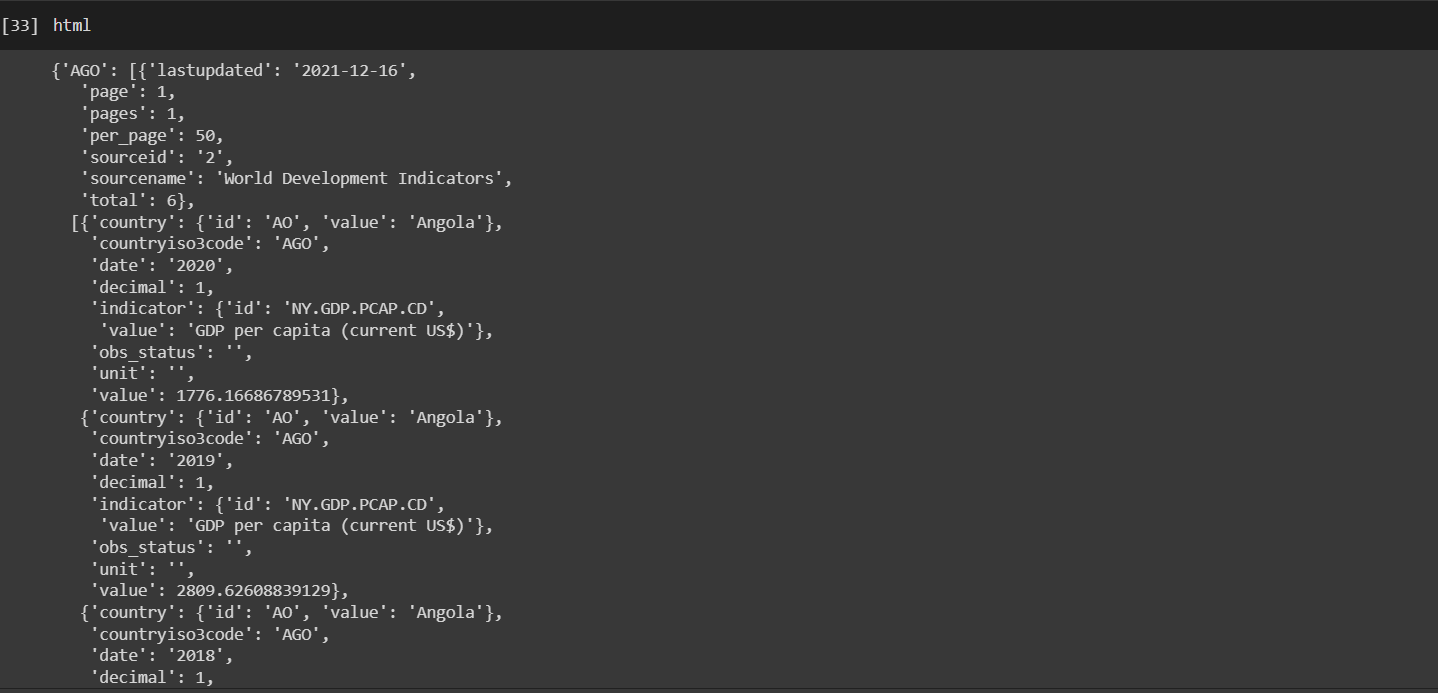
編輯 2
得到了我正在尋找的資料,但每次重復兩次
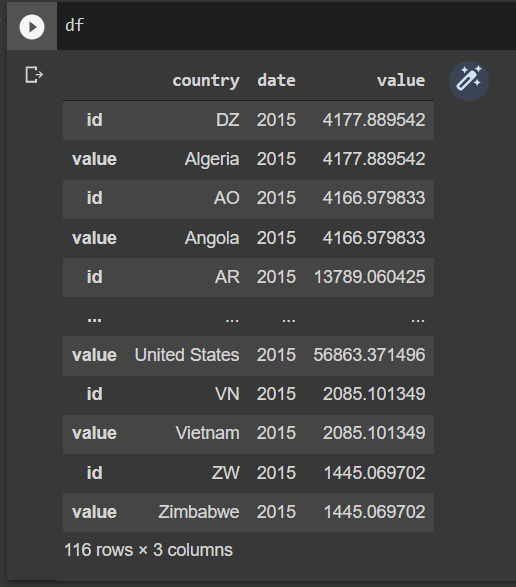
uj5u.com熱心網友回復:
注意: 假設一次存盤所有年份的資訊而不只是一年的資訊會很好 - 使您能夠在以后的處理中簡單地進行過濾。看看,你們國家之間少了一個“,”"GRC""HUN"
有多種選擇可以實作您的目標,只需指出其中兩個正確的方向即可。
選項1
從 json 回應中選擇所需的資訊,創建一個重塑的 dict 并將append()其my_values:
for d in data[1]:
my_values.append({
'country':d['country']['value'],
'date':d['date'],
'value':d['value']
})
例子
import requests
import pandas as pd
url = 'http://api.worldbank.org/v2/country/%s/indicator/NY.GDP.PCAP.CD?format=json'
countries = ["DZA","AGO","ARG","AUS","AUT","BEL","BRA","CAN","CHL","CHN","COL","CYP", "CZE","DNK","FIN","FRA","GEO","DEU",
"GRC","HUN","ISL","IND","IDN","IRL","ISR","ITA","JPN","KAZ","KWT","LBN","LIE","MYS","MEX","MCO","MAR","NPL","NLD",
"NZL","NGA","NOR","OMN","PER","PHL","POL","PRT","QAT","ROU","SGP","ZAF","ESP","SWE","CHE","TZA","THA","TUR","UKR",
"GBR","USA","VNM","ZWE"]
my_values = []
for country in countries:
data = requests.get(url %country).json()
try:
for d in data[1]:
my_values.append({
'country':d['country']['value'],
'date':d['date'],
'value':d['value']
})
except Exception as err:
print(f'[ERROR] country ==> {country} error ==> {err}')
pd.DataFrame(my_values).sort_values(['country', 'date'], ascending=True)
選項#2
直接從 json 回應創建資料幀,連接它們并對最終資料幀進行一些調整:
for d in data[1]:
my_values.append(pd.DataFrame(d))
...
pd.concat(my_values).loc[['value']][['country','date','value']].sort_values(['country', 'date'], ascending=True)
輸出
| 國家 | 日期 | 價值 |
|---|---|---|
| 阿爾及利亞 | 1971年 | 341.389 |
| 阿爾及利亞 | 1972年 | 442.678 |
| 阿爾及利亞 | 1973年 | 554.293 |
| 阿爾及利亞 | 1974年 | 818.008 |
| 阿爾及利亞 | 1975年 | 936.79 |
| ... | ... | ... |
| 津巴布韋 | 2016年 | 1464.59 |
| 津巴布韋 | 2017年 | 1235.19 |
| 津巴布韋 | 2018年 | 1254.64 |
| 津巴布韋 | 2019年 | 1316.74 |
| 津巴布韋 | 2020年 | 1214.51 |
uj5u.com熱心網友回復:
Pandasread_json方法需要有效的 JSON str、path 物件或類似檔案的物件,但你把 string.
https://pandas.pydata.org/docs/reference/api/pandas.read_json.html
試試這個:
import requests
import pandas as pd
url = "http://api.worldbank.org/v2/country/%s/indicator/NY.GDP.PCAP.CD?date=2015&format=json"
countries = ["DZA","AGO","ARG","AUS","AUT","BEL","BRA","CAN","CHL","CHN","COL","CYP", "CZE","DNK","FIN","FRA","GEO","DEU",
"GRC""HUN","ISL","IND","IDN","IRL","ISR","ITA","JPN","KAZ","KWT","LBN","LIE","MYS","MEX","MCO","MAR","NPL","NLD",
"NZL","NGA","NOR","OMN","PER","PHL","POL","PRT","QAT","ROU","SGP","ZAF","ESP","SWE","CHE","TZA","THA","TUR","UKR",
"GBR","USA","VNM","ZWE"]
datas = []
for country in countries:
data = requests.get(url %country).json()
try:
values = data[1][0]
datas.append(pd.DataFrame(values))
except Exception as err:
print(f"[ERROR] country ==> {country} with error ==> {err}")
df = pd.concat(datas)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/403836.html
標籤: