本期是對熱播網劇《雪中悍刀行》的一次爬蟲與資料分析,總爬取條數1W條評論,很適合新人練手,案例中還特別加入了對評論的情緒文本分析處理,供大家參考,

爬蟲方面:由于騰訊的評論資料是封裝在json里面,所以只需要找到json檔案,對需要的資料進行提取保存即可,
視頻網址:
https://v.qq.com/x/cover/mzc0020020cyvqh.html
評論json資料網址:
https://video.coral.qq.com/varticle/7579013546/comment/v2
注:只要替換視頻數字id的值,即可爬取其他視頻的評論
本文內容僅作為編程技術學習討論,相關代碼和資料不可用于商業用途,否則后果自負,
如何查找視頻id?
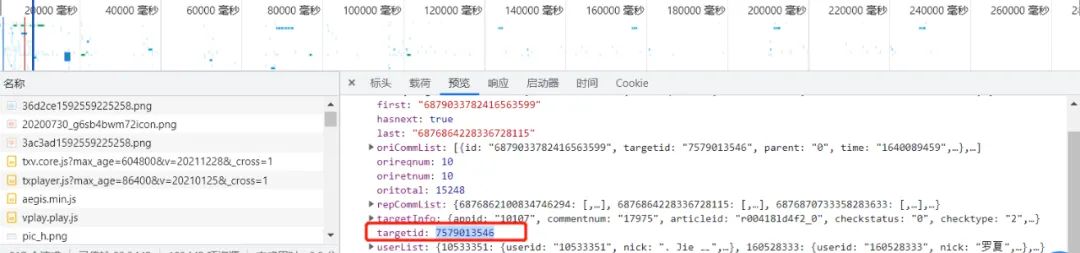
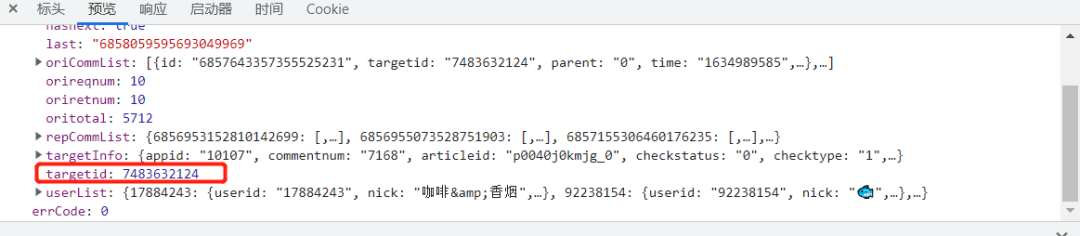
通過Chrome開發者工具的Network查找請求,具體使用可參考舊文:爬蟲必備工具,掌握它就解決了一半的問題
專案結構:
一. 爬蟲部分:
1. 爬取評論內容代碼:
spiders.py
import requests
import re
import random
def get_html(url, params):
uapools = [
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14'
]
thisua = random.choice(uapools)
headers = {"User-Agent": thisua}
r = requests.get(url, headers=headers, params=params)
r.raise_for_status()
r.encoding = r.apparent_encoding
r.encoding = 'utf-8'# 不加此句出現亂碼
return r.text
def parse_page(infolist, data):
commentpat = '"content":"(.*?)"'
lastpat = '"last":"(.*?)"'
commentall = re.compile(commentpat, re.S).findall(data)
next_cid = re.compile(lastpat).findall(data)[0]
infolist.append(commentall)
return next_cid
def print_comment_list(infolist):
j = 0
for page in infolist:
print('第' + str(j + 1) + '頁\n')
commentall = page
for i in range(0, len(commentall)):
print(commentall[i] + '\n')
j += 1
def save_to_txt(infolist, path):
fw = open(path, 'w+', encoding='utf-8')
j = 0
for page in infolist:
#fw.write('第' + str(j + 1) + '頁\n')
commentall = page
for i in range(0, len(commentall)):
fw.write(commentall[i] + '\n')
j += 1
fw.close()
def main():
infolist = []
vid = '7579013546';
cid = "0";
page_num = 3000
url = 'https://video.coral.qq.com/varticle/' + vid + '/comment/v2'
#print(url)
for i in range(page_num):
params = {'orinum': '10', 'cursor': cid}
html = get_html(url, params)
cid = parse_page(infolist, html)
print_comment_list(infolist)
save_to_txt(infolist, 'content.txt')
main()
2. 爬取評論時間代碼
sp.py
import requests
import re
import random
def get_html(url, params):
uapools = [
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14'
]
thisua = random.choice(uapools)
headers = {"User-Agent": thisua}
r = requests.get(url, headers=headers, params=params)
r.raise_for_status()
r.encoding = r.apparent_encoding
r.encoding = 'utf-8'# 不加此句出現亂碼
return r.text
def parse_page(infolist, data):
commentpat = '"time":"(.*?)"'
lastpat = '"last":"(.*?)"'
commentall = re.compile(commentpat, re.S).findall(data)
next_cid = re.compile(lastpat).findall(data)[0]
infolist.append(commentall)
return next_cid
def print_comment_list(infolist):
j = 0
for page in infolist:
print('第' + str(j + 1) + '頁\n')
commentall = page
for i in range(0, len(commentall)):
print(commentall[i] + '\n')
j += 1
def save_to_txt(infolist, path):
fw = open(path, 'w+', encoding='utf-8')
j = 0
for page in infolist:
#fw.write('第' + str(j + 1) + '頁\n')
commentall = page
for i in range(0, len(commentall)):
fw.write(commentall[i] + '\n')
j += 1
fw.close()
def main():
infolist = []
vid = '7579013546';
cid = "0";
page_num =3000
url = 'https://video.coral.qq.com/varticle/' + vid + '/comment/v2'
#print(url)
for i in range(page_num):
params = {'orinum': '10', 'cursor': cid}
html = get_html(url, params)
cid = parse_page(infolist, html)
print_comment_list(infolist)
save_to_txt(infolist, 'time.txt')
main()
二. 資料處理部分
1. 評論的時間戳轉換為正常時間
time.py
# coding=gbk
import csv
import time
csvFile = open("data.csv",'w',newline='',encoding='utf-8')
writer = csv.writer(csvFile)
csvRow = []
#print(csvRow)
f = open("time.txt",'r',encoding='utf-8')
for line in f:
csvRow = int(line)
#print(csvRow)
timeArray = time.localtime(csvRow)
csvRow = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
print(csvRow)
csvRow = csvRow.split()
writer.writerow(csvRow)
f.close()
csvFile.close()
2. 評論內容讀入csv
CD.py
# coding=gbk
import csv
csvFile = open("content.csv",'w',newline='',encoding='utf-8')
writer = csv.writer(csvFile)
csvRow = []
f = open("content.txt",'r',encoding='utf-8')
for line in f:
csvRow = line.split()
writer.writerow(csvRow)
f.close()
csvFile.close()
3. 統計一天各個時間段內的評論數
py.py
# coding=gbk
import csv
from pyecharts import options as opts
from sympy.combinatorics import Subset
from wordcloud import WordCloud
with open('../Spiders/data.csv') as csvfile:
reader = csv.reader(csvfile)
data1 = [str(row[1])[0:2] for row in reader]
print(data1)
print(type(data1))
#先變成集合得到seq中的所有元素,避免重復遍歷
set_seq = set(data1)
rst = []
for item in set_seq:
rst.append((item,data1.count(item))) #添加元素及出現個數
rst.sort()
print(type(rst))
print(rst)
with open("time2.csv", "w+", newline='', encoding='utf-8') as f:
writer = csv.writer(f, delimiter=',')
for i in rst: # 對于每一行的,將這一行的每個元素分別寫在對應的列中
writer.writerow(i)
with open('time2.csv') as csvfile:
reader = csv.reader(csvfile)
x = [str(row[0]) for row in reader]
print(x)
with open('time2.csv') as csvfile:
reader = csv.reader(csvfile)
y1 = [float(row[1]) for row in reader]
print(y1)
4. 統計最近評論數
py1.py
# coding=gbk
import csv
from pyecharts import options as opts
from sympy.combinatorics import Subset
from wordcloud import WordCloud
with open('../Spiders/data.csv') as csvfile:
reader = csv.reader(csvfile)
data1 = [str(row[0]) for row in reader]
#print(data1)
print(type(data1))
#先變成集合得到seq中的所有元素,避免重復遍歷
set_seq = set(data1)
rst = []
for item in set_seq:
rst.append((item,data1.count(item))) #添加元素及出現個數
rst.sort()
print(type(rst))
print(rst)
with open("time1.csv", "w+", newline='', encoding='utf-8') as f:
writer = csv.writer(f, delimiter=',')
for i in rst: # 對于每一行的,將這一行的每個元素分別寫在對應的列中
writer.writerow(i)
with open('time1.csv') as csvfile:
reader = csv.reader(csvfile)
x = [str(row[0]) for row in reader]
print(x)
with open('time1.csv') as csvfile:
reader = csv.reader(csvfile)
y1 = [float(row[1]) for row in reader]
print(y1)
三. 資料分析
資料分析方面:涉及到了詞云圖,條形,折線,餅圖,后三者是對評論時間與主演占比的分析,然而騰訊的評論時間是以時間戳的形式顯示,所以要進行轉換,再去統計出現次數,最后,新加了對評論內容的情感分析,
1. 制作詞云圖
wc.py
import numpy as np
import re
import jieba
from wordcloud import WordCloud
from matplotlib import pyplot as plt
from PIL import Image
# 上面的包自己安裝,不會的就百度
f = open('content.txt', 'r', encoding='utf-8') # 這是資料源,也就是想生成詞云的資料
txt = f.read() # 讀取檔案
f.close() # 關閉檔案,其實用with就好,但是懶得改了
# 如果是文章的話,需要用到jieba分詞,分完之后也可以自己處理下再生成詞云
newtxt = re.sub("[A-Za-z0-9\!\%\[\]\,\,]", "", txt)
print(newtxt)
words = jieba.lcut(newtxt)
img = Image.open(r'wc.jpg') # 想要搞得形狀
img_array = np.array(img)
# 相關配置,里面這個collocations配置可以避免重復
wordcloud = WordCloud(
background_color="white",
width=1080,
height=960,
font_path="../文悅新青年.otf",
max_words=150,
scale=10,#清晰度
max_font_size=100,
mask=img_array,
collocations=False).generate(newtxt)
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
wordcloud.to_file('wc.png')
輪廓圖:wc.jpg

詞云圖:result.png (注:這里把英文字母過濾掉)

2. 制作最近評論數條形圖
DrawBar.py
# encoding: utf-8
import csv
import pyecharts.options as opts
from pyecharts.charts import Bar
from pyecharts.globals import ThemeType
class DrawBar(object):
"""繪制柱形圖類"""
def __init__(self):
"""創建柱狀圖實體,并設定寬高和風格"""
self.bar = Bar(init_opts=opts.InitOpts(width='1500px', height='700px', theme=ThemeType.LIGHT))
def add_x(self):
"""為圖形添加X軸資料"""
with open('time1.csv') as csvfile:
reader = csv.reader(csvfile)
x = [str(row[0]) for row in reader]
print(x)
self.bar.add_xaxis(
xaxis_data=x,
)
def add_y(self):
with open('time1.csv') as csvfile:
reader = csv.reader(csvfile)
y1 = [float(row[1]) for row in reader]
print(y1)
"""為圖形添加Y軸資料,可添加多條"""
self.bar.add_yaxis( # 第一個Y軸資料
series_name="評論數", # Y軸資料名稱
y_axis=y1, # Y軸資料
label_opts=opts.LabelOpts(is_show=True,color="black"), # 設定標簽
bar_max_width='100px', # 設定柱子最大寬度
)
def set_global(self):
"""設定圖形的全域屬性"""
#self.bar(width=2000,height=1000)
self.bar.set_global_opts(
title_opts=opts.TitleOpts( # 設定標題
title='雪中悍刀行近日評論統計',title_textstyle_opts=opts.TextStyleOpts(font_size=35)
),
tooltip_opts=opts.TooltipOpts( # 提示框配置項(滑鼠移到圖形上時顯示的東西)
is_show=True, # 是否顯示提示框
trigger="axis", # 觸發型別(axis坐標軸觸發,滑鼠移到時會有一條垂直于X軸的實線跟隨滑鼠移動,并顯示提示資訊)
axis_pointer_type="cross"# 指示器型別(cross將會生成兩條分別垂直于X軸和Y軸的虛線,不啟用trigger才會顯示完全)
),
toolbox_opts=opts.ToolboxOpts(), # 工具箱配置項(什么都不填默認開啟所有工具)
)
def draw(self):
"""繪制圖形"""
self.add_x()
self.add_y()
self.set_global()
self.bar.render('../Html/DrawBar.html') # 將圖繪制到 test.html 檔案內,可在瀏覽器打開
def run(self):
"""執行函式"""
self.draw()
if __name__ == '__main__':
app = DrawBar()
app.run()
效果圖:DrawBar.html
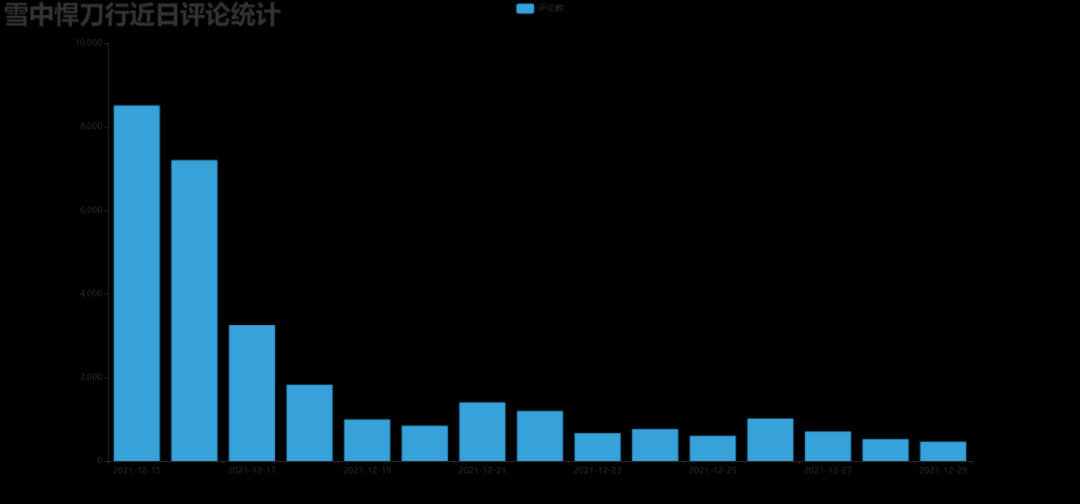
3. 制作每小時評論條形圖
DrawBar2.py
# encoding: utf-8
# encoding: utf-8
import csv
import pyecharts.options as opts
from pyecharts.charts import Bar
from pyecharts.globals import ThemeType
class DrawBar(object):
"""繪制柱形圖類"""
def __init__(self):
"""創建柱狀圖實體,并設定寬高和風格"""
self.bar = Bar(init_opts=opts.InitOpts(width='1500px', height='700px', theme=ThemeType.MACARONS))
def add_x(self):
"""為圖形添加X軸資料"""
str_name1 = '點'
with open('time2.csv') as csvfile:
reader = csv.reader(csvfile)
x = [str(row[0] + str_name1) for row in reader]
print(x)
self.bar.add_xaxis(
xaxis_data=x
)
def add_y(self):
with open('time2.csv') as csvfile:
reader = csv.reader(csvfile)
y1 = [int(row[1]) for row in reader]
print(y1)
"""為圖形添加Y軸資料,可添加多條"""
self.bar.add_yaxis( # 第一個Y軸資料
series_name="評論數", # Y軸資料名稱
y_axis=y1, # Y軸資料
label_opts=opts.LabelOpts(is_show=False), # 設定標簽
bar_max_width='50px', # 設定柱子最大寬度
)
def set_global(self):
"""設定圖形的全域屬性"""
#self.bar(width=2000,height=1000)
self.bar.set_global_opts(
title_opts=opts.TitleOpts( # 設定標題
title='雪中悍刀行各時間段評論統計',title_textstyle_opts=opts.TextStyleOpts(font_size=35)
),
tooltip_opts=opts.TooltipOpts( # 提示框配置項(滑鼠移到圖形上時顯示的東西)
is_show=True, # 是否顯示提示框
trigger="axis", # 觸發型別(axis坐標軸觸發,滑鼠移到時會有一條垂直于X軸的實線跟隨滑鼠移動,并顯示提示資訊)
axis_pointer_type="cross"# 指示器型別(cross將會生成兩條分別垂直于X軸和Y軸的虛線,不啟用trigger才會顯示完全)
),
toolbox_opts=opts.ToolboxOpts(), # 工具箱配置項(什么都不填默認開啟所有工具)
)
def draw(self):
"""繪制圖形"""
self.add_x()
self.add_y()
self.set_global()
self.bar.render('../Html/DrawBar2.html') # 將圖繪制到 test.html 檔案內,可在瀏覽器打開
def run(self):
"""執行函式"""
self.draw()
if __name__ == '__main__':
app = DrawBar()
app.run()
效果圖:DrawBar2.html
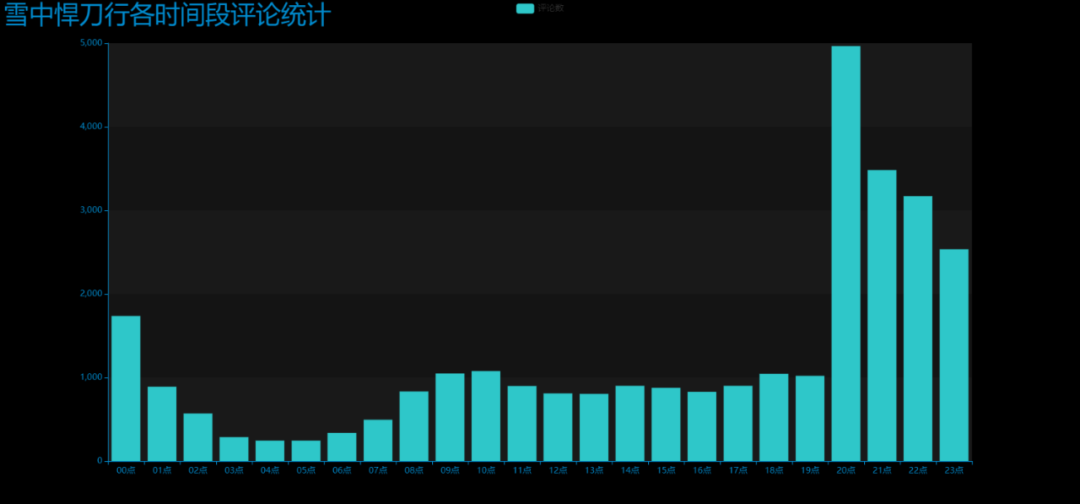
4. 制作近日評論數餅圖
pie_pyecharts.py
import csv
from pyecharts import options as opts
from pyecharts.charts import Pie
from random import randint
from pyecharts.globals import ThemeType
with open('time1.csv') as csvfile:
reader = csv.reader(csvfile)
x = [str(row[0]) for row in reader]
print(x)
with open('time1.csv') as csvfile:
reader = csv.reader(csvfile)
y1 = [float(row[1]) for row in reader]
print(y1)
num = y1
lab = x
(
Pie(init_opts=opts.InitOpts(width='1700px',height='450px',theme=ThemeType.LIGHT))#默認900,600
.set_global_opts(
title_opts=opts.TitleOpts(title="雪中悍刀行近日評論統計",
title_textstyle_opts=opts.TextStyleOpts(font_size=27)),legend_opts=opts.LegendOpts(
pos_top="10%", pos_left="1%",# 圖例位置調整
),)
.add(series_name='',center=[280, 270], data_pair=[(j, i) for i, j in zip(num, lab)])#餅圖
.add(series_name='',center=[845, 270],data_pair=[(j,i) for i,j in zip(num,lab)],radius=['40%','75%'])#環圖
.add(series_name='', center=[1380, 270],data_pair=[(j, i) for i, j in zip(num, lab)], rosetype='radius')#南丁格爾圖
).render('pie_pyecharts.html')
效果圖
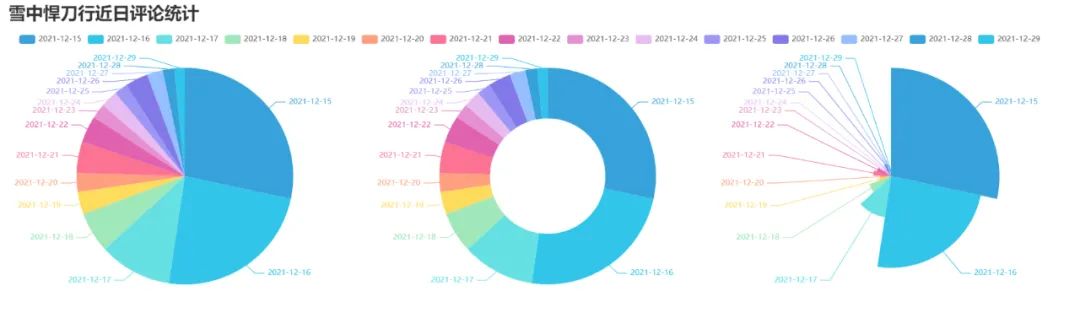
5. 制作每小時評論餅圖
pie_pyecharts2.py
import csv from pyecharts import options as opts from pyecharts.charts import Pie from random import randint from pyecharts.globals import ThemeTypestr_name1 = '點' with open('time2.csv') as csvfile: reader = csv.reader(csvfile) x = [str(row[0]+str_name1) for row in reader] print(x) with open('time2.csv') as csvfile: reader = csv.reader(csvfile) y1 = [int(row[1]) for row in reader] print(y1) num = y1 lab = x ( Pie(init_opts=opts.InitOpts(width='1650px',height='500px',theme=ThemeType.LIGHT,))#默認900,600 .set_global_opts( title_opts=opts.TitleOpts(title="雪中悍刀行每小時評論統計" ,title_textstyle_opts=opts.TextStyleOpts(font_size=27)), legend_opts=opts.LegendOpts( pos_top="8%", pos_left="4%",# 圖例位置調整 ), ) .add(series_name='',center=[250, 300], data_pair=[(j, i) for i, j in zip(num, lab)])#餅圖 .add(series_name='',center=[810, 300],data_pair=[(j,i) for i,j in zip(num,lab)],radius=['40%','75%'])#環圖 .add(series_name='', center=[1350, 300],data_pair=[(j, i) for i, j in zip(num, lab)], rosetype='radius')#南丁格爾圖 ).render('pie_pyecharts2.html')
效果圖
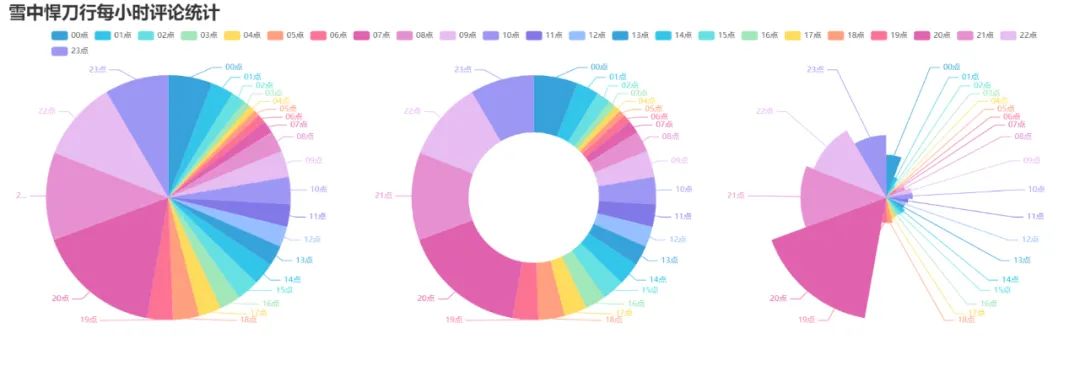
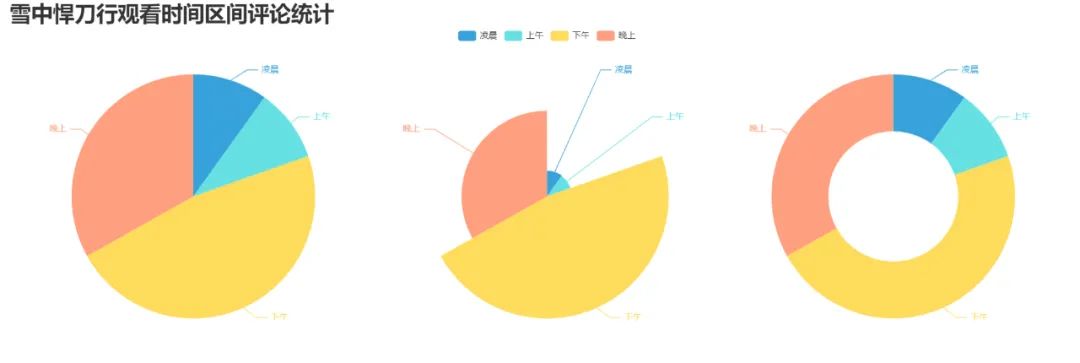
6. 制作觀看時間區間評論統計餅圖
pie_pyecharts3.py
# coding=gbk import csv from pyecharts import options as opts from pyecharts.globals import ThemeType from sympy.combinatorics import Subset from wordcloud import WordCloud from pyecharts.charts import Pie from random import randintwith open(/data.csv') as csvfile: reader = csv.reader(csvfile) data2 = [int(row[1].strip('')[0:2]) for row in reader] #print(data2) print(type(data2)) #先變成集合得到seq中的所有元素,避免重復遍歷 set_seq = set(data2) list = [] for item in set_seq: list.append((item,data2.count(item))) #添加元素及出現個數 list.sort() print(type(list)) #print(list) with open("time2.csv", "w+", newline='', encoding='utf-8') as f: writer = csv.writer(f, delimiter=',') for i in list: # 對于每一行的,將這一行的每個元素分別寫在對應的列中 writer.writerow(i) n = 4#分成n組 m = int(len(list)/n) list2 = [] for i in range(0, len(list), m): list2.append(list[i:i+m]) print("凌晨 : ",list2[0]) print("上午 : ",list2[1]) print("下午 : ",list2[2]) print("晚上 : ",list2[3]) with open('time2.csv') as csvfile: reader = csv.reader(csvfile) y1 = [int(row[1]) for row in reader] print(y1) n =6 groups = [y1[i:i + n] for i in range(0, len(y1), n)] print(groups) x=['凌晨','上午','下午','晚上'] y1=[] for y1 in groups: num_sum = 0 for groups in y1: num_sum += groups str_name1 = '點' num = y1 lab = x ( Pie(init_opts=opts.InitOpts(width='1500px',height='450px',theme=ThemeType.LIGHT))#默認900,600 .set_global_opts( title_opts=opts.TitleOpts(title="雪中悍刀行觀看時間區間評論統計" , title_textstyle_opts=opts.TextStyleOpts(font_size=30)), legend_opts=opts.LegendOpts( pos_top="8%", # 圖例位置調整 ), ) .add(series_name='',center=[260, 270], data_pair=[(j, i) for i, j in zip(num, lab)])#餅圖 .add(series_name='',center=[1230, 270],data_pair=[(j,i) for i,j in zip(num,lab)],radius=['40%','75%'])#環圖 .add(series_name='', center=[750, 270],data_pair=[(j, i) for i, j in zip(num, lab)], rosetype='radius')#南丁格爾圖 ).render('pie_pyecharts3.html')
效果圖
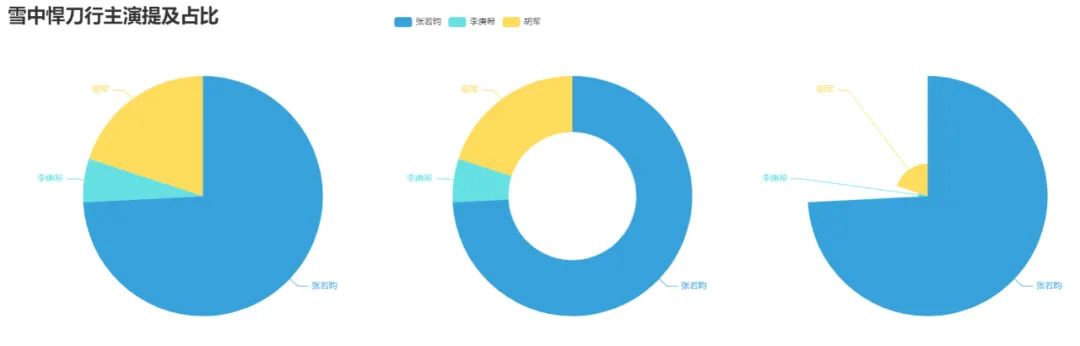
7. 制作雪中悍刀行主演提及占比餅圖
pie_pyecharts4.py
import csv
from pyecharts import options as opts
from pyecharts.charts import Pie
from random import randint
from pyecharts.globals import ThemeType
f = open('content.txt', 'r', encoding='utf-8') # 這是資料源,也就是想生成詞云的資料
words = f.read() # 讀取檔案
f.close() # 關閉檔案,其實用with就好,但是懶得改了
name=["張若昀","李庚希","胡軍"]
print(name)
count=[float(words.count("張若昀")),
float(words.count("李庚希")),
float(words.count("胡軍"))]
print(count)
num = count
lab = name
(
Pie(init_opts=opts.InitOpts(width='1650px',height='450px',theme=ThemeType.LIGHT))#默認900,600
.set_global_opts(
title_opts=opts.TitleOpts(title="雪中悍刀行主演提及占比",
title_textstyle_opts=opts.TextStyleOpts(font_size=27)),legend_opts=opts.LegendOpts(
pos_top="3%", pos_left="33%",# 圖例位置調整
),)
.add(series_name='',center=[280, 270], data_pair=[(j, i) for i, j in zip(num, lab)])#餅圖
.add(series_name='',center=[800, 270],data_pair=[(j,i) for i,j in zip(num,lab)],radius=['40%','75%'])#環圖
.add(series_name='', center=[1300, 270],data_pair=[(j, i) for i, j in zip(num, lab)], rosetype='radius')#南丁格爾圖
).render('pie_pyecharts4.html')效果圖
8. 評論內容情感分析
SnowNLP.py
import numpy as np
from snownlp import SnowNLP
import matplotlib.pyplot as plt
f = open('content.txt', 'r', encoding='UTF-8')
list = f.readlines()
sentimentslist = []
for i in list:
s = SnowNLP(i)
print(s.sentiments)
sentimentslist.append(s.sentiments)
plt.hist(sentimentslist, bins=np.arange(0, 1, 0.01), facecolor='g')
plt.xlabel('Sentiments Probability')
plt.ylabel('Quantity')
plt.title('Analysis of Sentiments')
plt.show()效果圖(情感各分數段出現頻率)
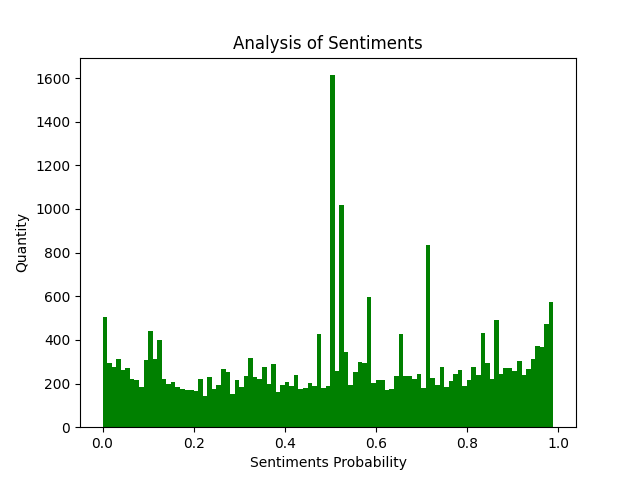
SnowNLP情感分析是基于情感詞典實作的,其簡單的將文本分為兩類,積極和消極,回傳值為情緒的概率,也就是情感評分在[0,1]之間,越接近1,情感表現越積極,越接近0,情感表現越消極,
總結
以上就是如何獲取騰訊視頻評論并整理后進行可視化分析,屬于資料分析及可視化的常規操作,沒有特別高深的技術,還比較適合資料分析初學者練習,讀者可以自行動手嘗試,全部代碼已在文中給出,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/404152.html
標籤:python