1-1 鏈表(List)及經典問題
鏈表基礎知識
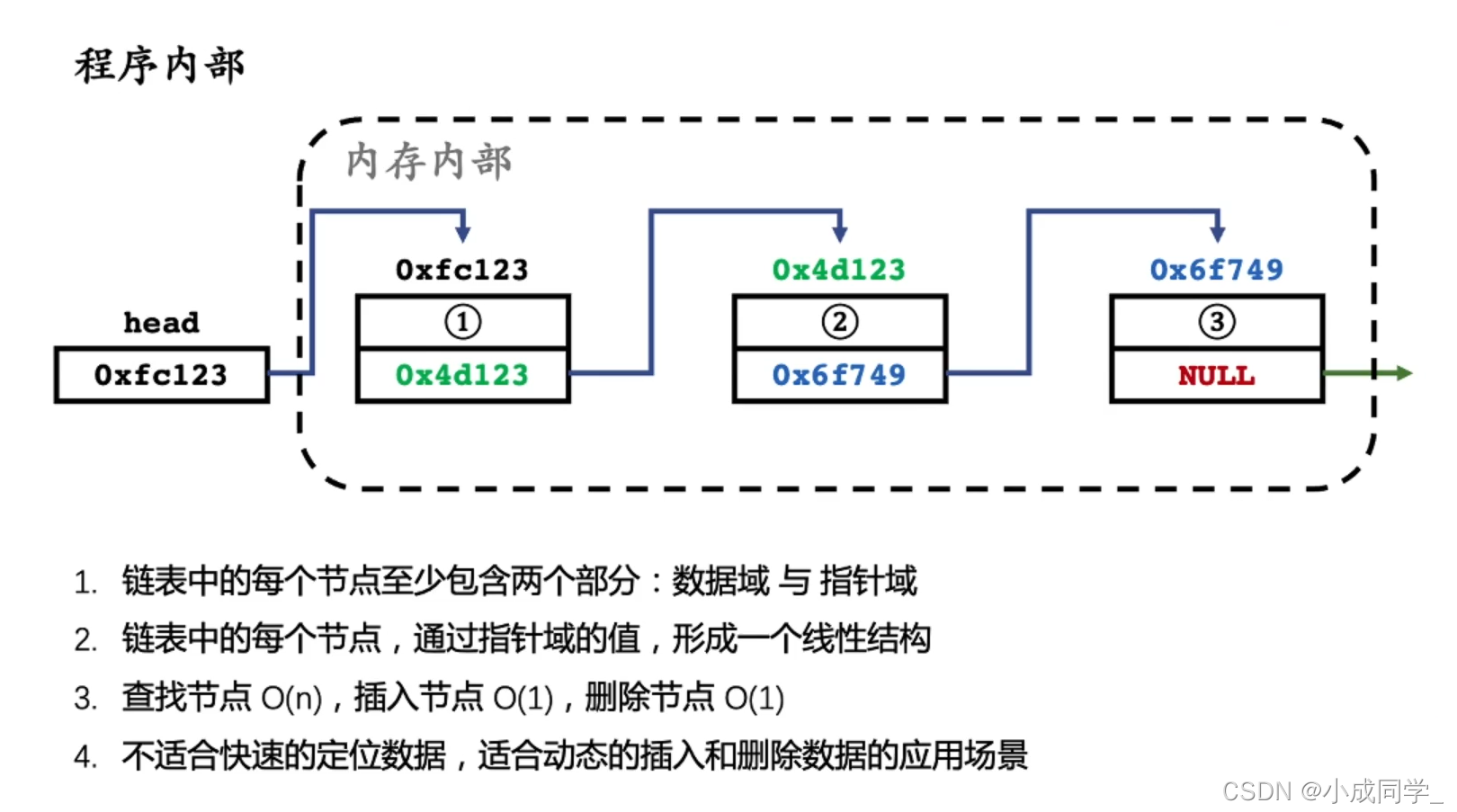
鏈表的典型應用場景

現在我們有這樣一個需求:現在這個4GB的記憶體是一個連續的存盤空間,我們要在這個存盤空間里面開辟1GB的連續的存盤空間,接下來我們是要在4GB的記憶體空間劃分出來1GB的存盤空間,如圖:

malloc函式是c語言里的內容,就好比java里的new;作用相同的,就是開辟存盤空間,
可以想象成我找了一個1GB大小的陣列,雖然有點夸張,只是舉例,
經過我這樣的申請空間之后,我們把我們的整個資料切分了,原本是好好的一整塊陣列,變成兩塊了,一個是2GB的碎片,一個是1GB的碎片,如圖:

那我們接下來在程式里申請空間的話,我們如何去管理這個記憶體碎片?
作業系統底層里面,把兩個記憶體碎片用鏈表給他竄起來,我們可以通過2GB找到1GB的碎片,這樣就不至于說我們記憶體里面出現碎片丟失,有一片存盤空間找不到的情況;這是簡單的一個應用,
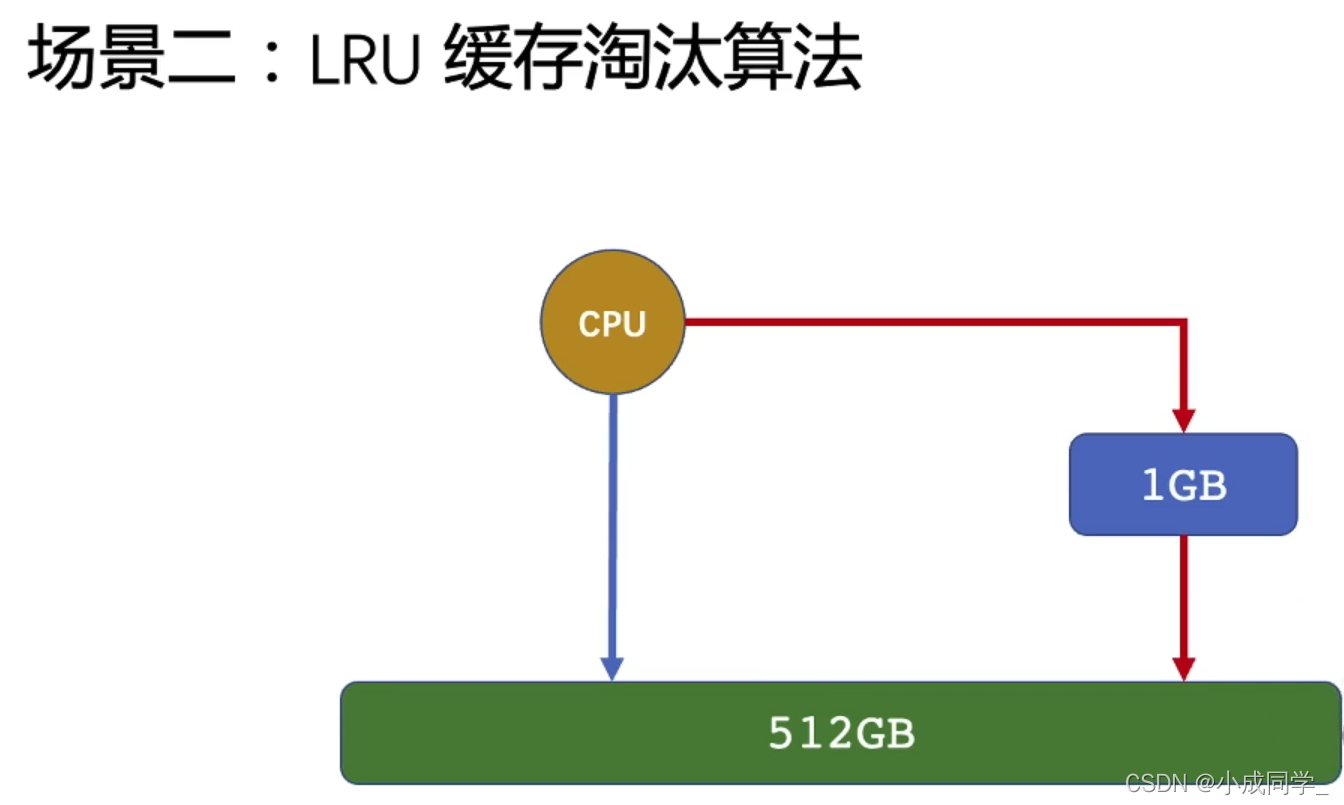
現在只是簡單拿出來了解一下,后續會對這個LRU快取淘汰演算法進行詳細的講解,
什么是LRU?你可以理解為冰箱里有好多菜,我周一買了些菜,周二買了些菜,周日也買了些菜,但我們最后發現冰箱里放不下了,這時候我們新買的菜也不能不放進冰箱里,所以這時我們只能在冰箱里挑出一些菜給它扔掉,這時候我們會扔哪些菜呢?答案肯定是放的最久的菜,因為是最容易壞的,

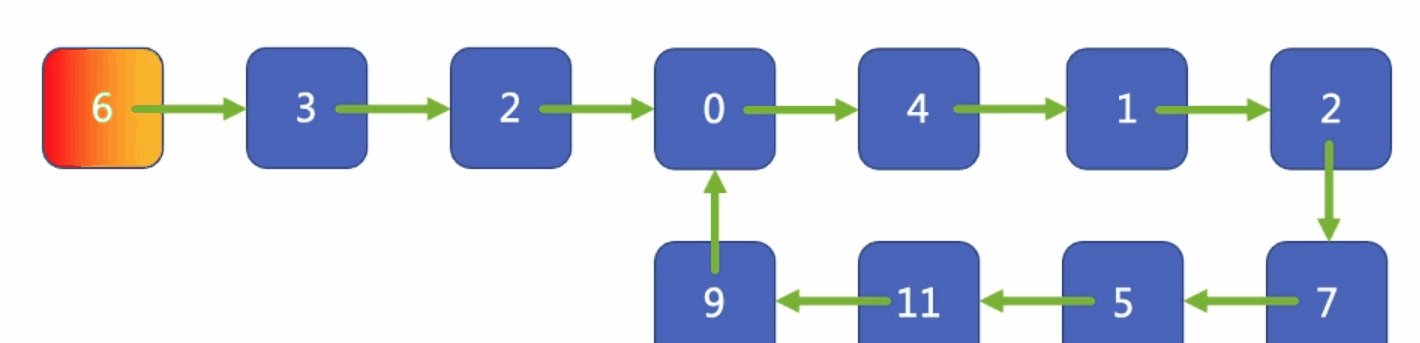
那我們如何區分哪個最久呢?我們可以用鏈表給它鏈起來,這樣我們就知道,哪個菜是最開始就放進冰箱里的,我們可以優先將它淘汰掉,并放入我們新的菜,就好比將圖片中的資料1刪掉,存入新的資料5,再想填入新的資料,刪掉資料2,以此類推,
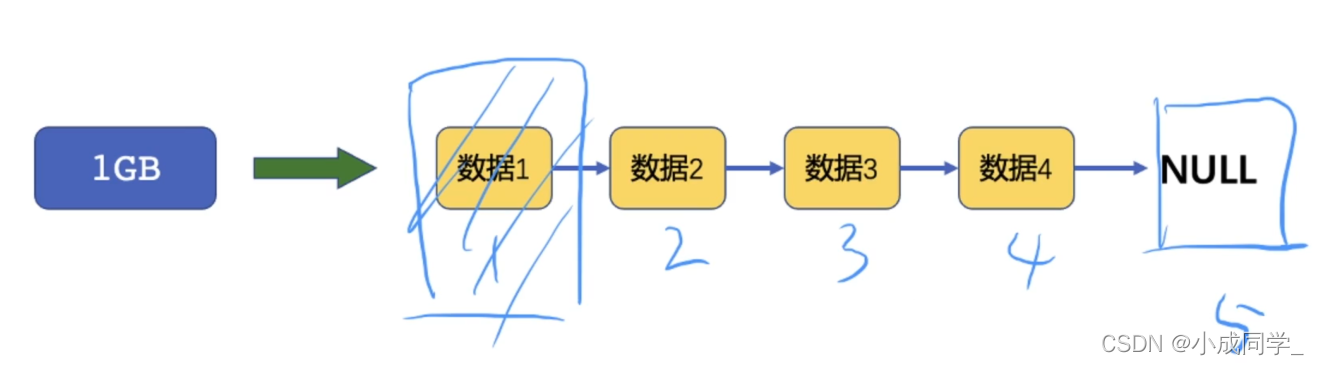
假設資料3是我們非常想吃的菜,但按照順序即將被淘汰掉,我們可以把資料3拿出來,放在最后,更新一下它的優先級,這樣的話資料3的優先級就高于資料4,我們洗掉資料2之后,會洗掉資料4;這是鏈表常用的一個實作方式,

鏈表使用的場景還是非常多的,
鏈表與陣列的結構性能對比
陣列的存盤是連續、聚合的
鏈表的存盤是離散的,我們通過抽象的指標域概念連接了起來
陣列是一段連續的存盤空間,支持資料隨機訪問,我們想找到哪個資料就可以立刻找到;但我們假設有一個100記憶體的陣列,我想對這個陣列進行擴容的話,我可能需要申請一個200記憶體的陣列,再把100記憶體陣列的所有資料原封不動的搬過去,這樣我們才能得到一個200記憶體的陣列,
鏈表是非連續的,擴容非常簡單,找一個結點,就可以實作插入或者洗掉;但我們如果訪問資料的話,就只能隨機的訪問,它不能按順序進行訪問;
這是我們從資料結構層面進行對比,
那我們從硬體層面考慮呢?
CPU讀取優化
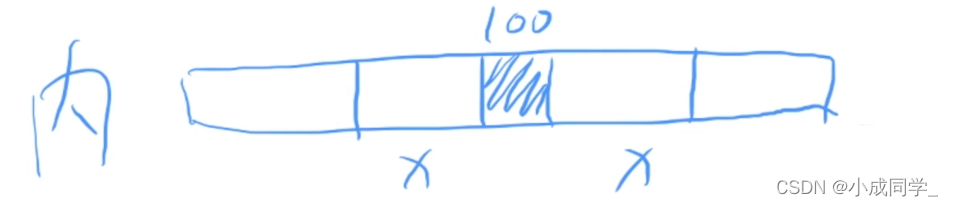
讀取陣列時,假設我想讀取陣列的第100個數,我可以直接找到資料并將它拿出來,但真正計算機實作里面,我們真的是只把100這一個資料從記憶體拿到cpu里面嗎?其實不是的,記憶體的內容導到cpu里,這叫做背景關系切換,這種資料之間的讀取是非常耗時的,所以說cpu不會大材小用的,你想讀一個東西,我就只老老實實的讀一個嗎?cpu不是這樣的,cpu很不老實,在我們當前節點前后,分別多讀取一段記憶體空間,具體資料各個硬體不一樣,當我們讀取100的時候,cpu很多余的將100前后的x個空間都拿出來,它具體讀取的內容是x+1+x,雖然你只想讀取一個,但是cpu會讀取2x+1個數,
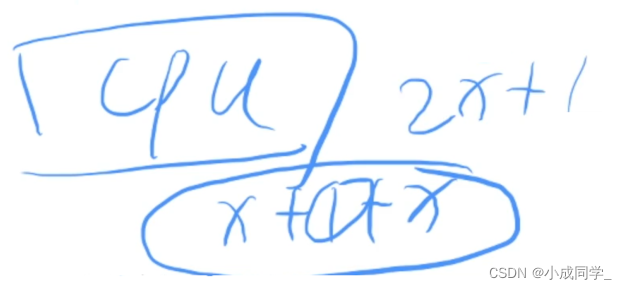
cpu為什么會這么做?正是因為陣列的連續的,如果我想讀取一個數的話,那么我讀取前面或者后面這個數的概率會大一點,所以它會進行一個多余的操作,但這個操作也不算是多余,它讀取一個資料,和再讀取這個資料前后的資料,如果時間消耗幾乎是一樣的話,cpu為什么不多讀一點呢?這就是我們cpu層面上的快取優化,
那對于鏈表來說,可以用這種優化嗎?答案肯定是不能的,因為鏈表的存盤是非常隨機的,在記憶體里一個在東面,一個在西面,當你cpu想讀當前這一個鏈表結點時,它不知道你前面的結點和后面的結點都在哪里,所以說鏈表有很大的一個缺點,它沒有辦法運用在我們的cpu快取優化;對應到我們的工程實作里面,這兩個的差距是非常非常大的,
LeetCode真題
經典面試題—鏈表的訪問
LeetCode141.環形鏈表
難度:easy
判斷鏈表是否有環
經典的快慢指標編程思想 但是我們從初學者的角度來看 是不會想到用快慢指標的
哈希表
最樸素的思想肯定是這種
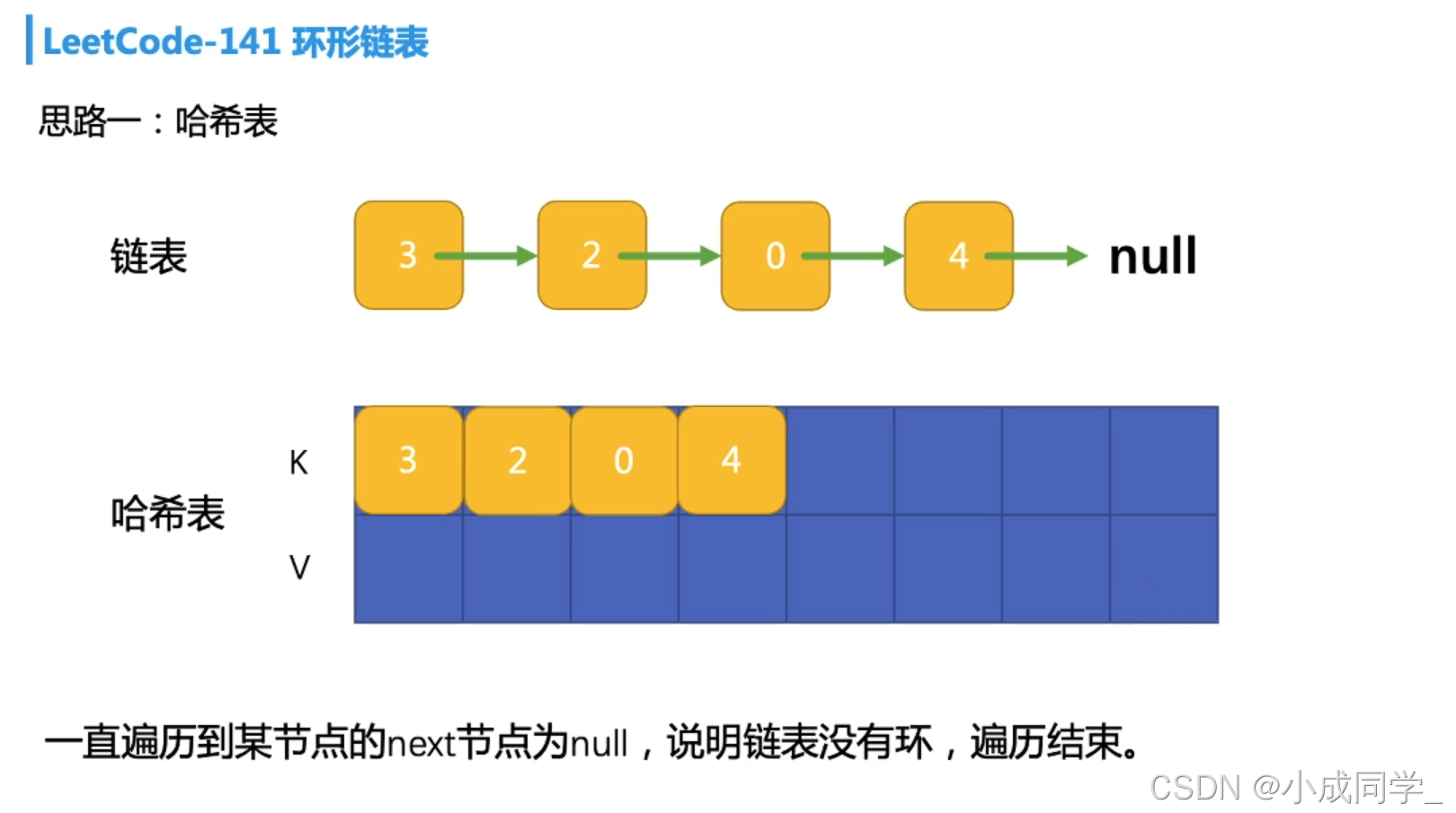
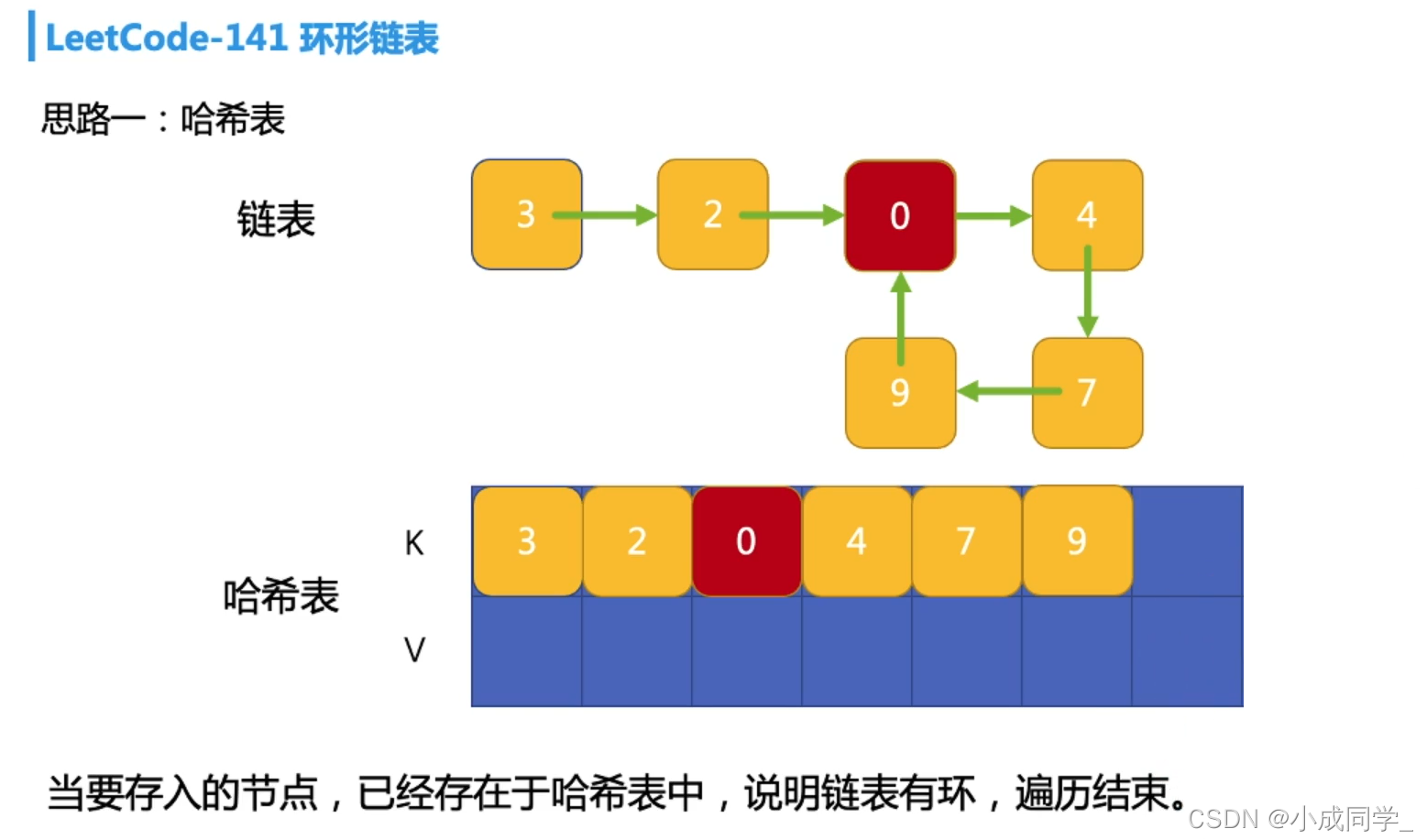
哈希的形式,我們只需要依次遍歷整個鏈表,并創建一個哈希表來存盤遍歷過的結點,遍歷每一個結點,然后存入哈希表;在存入哈希表之前,先判斷哈希表中是否存在該結點,
如果不存在,則存入哈希表;如果已存在,說明遍歷到了重復結點,鏈表有環,
先來看無環的情況:
有環情況:
這個也是大部分人第一次遇到這種題的思路;大家在面試的時候,可以先寫出這種最暴力的方式,然后再去優化,不要一直想著怎么去優化然后連最簡單的方式都不寫,要不然面試官會以為你連最簡單的方式都不會,
總結
我們只需要遍歷這個鏈表,在遍歷程序中記錄我們遍歷的每個結點,
如果遇到
next結點為null的結點,說明沒有環,如果遇到我們以前遍歷過的結點,說明有環,
但是這種方式是不是有點復雜,我需要開辟一個額外的存盤空間來存盤每一個鏈表結點的地址,我們有更優化的方法嗎?
題中有一段話:
進階:你能用
O(1)(即,常量)記憶體解決此問題嗎?
快慢指標
也就是說你不要動態的去申請記憶體空間,那我們如何不借助哈希表來實作這個題呢?那就是我們剛才提到的快慢指標,
我們定義兩個指標,p是慢指標(用紅色標記),q是快指標(用黃色標記),每次讓p結點走一步,q結點走兩步,
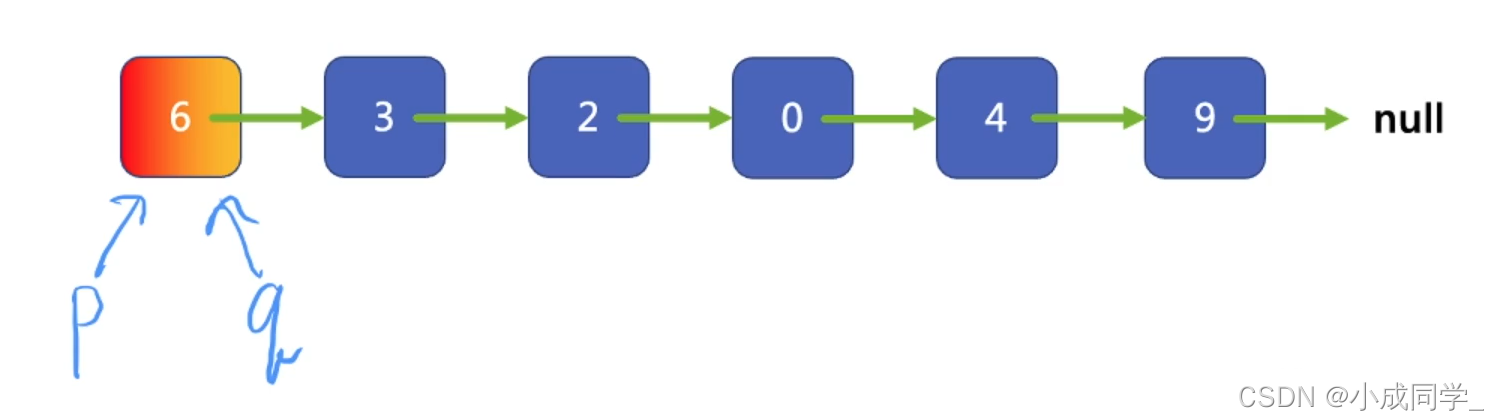
無環:

當快指標的next結點為null,或者快指標本身結點為null時,說明該鏈表沒有環,遍歷結束,
我們再來看一下有環的情況:
如果鏈表有環,那么快慢指標一定會相遇,指向同一個結點,當指向同一個結點時,遍歷結束,
LeetCode題解:兩種方法代碼實作
LeetCode142.環形鏈表II
難度:mid
141是判斷是否有環,142是求環的起點,
最簡單的方法肯定還是利用哈希表來判斷,這里不過多贅述,我們直接上快慢指標,
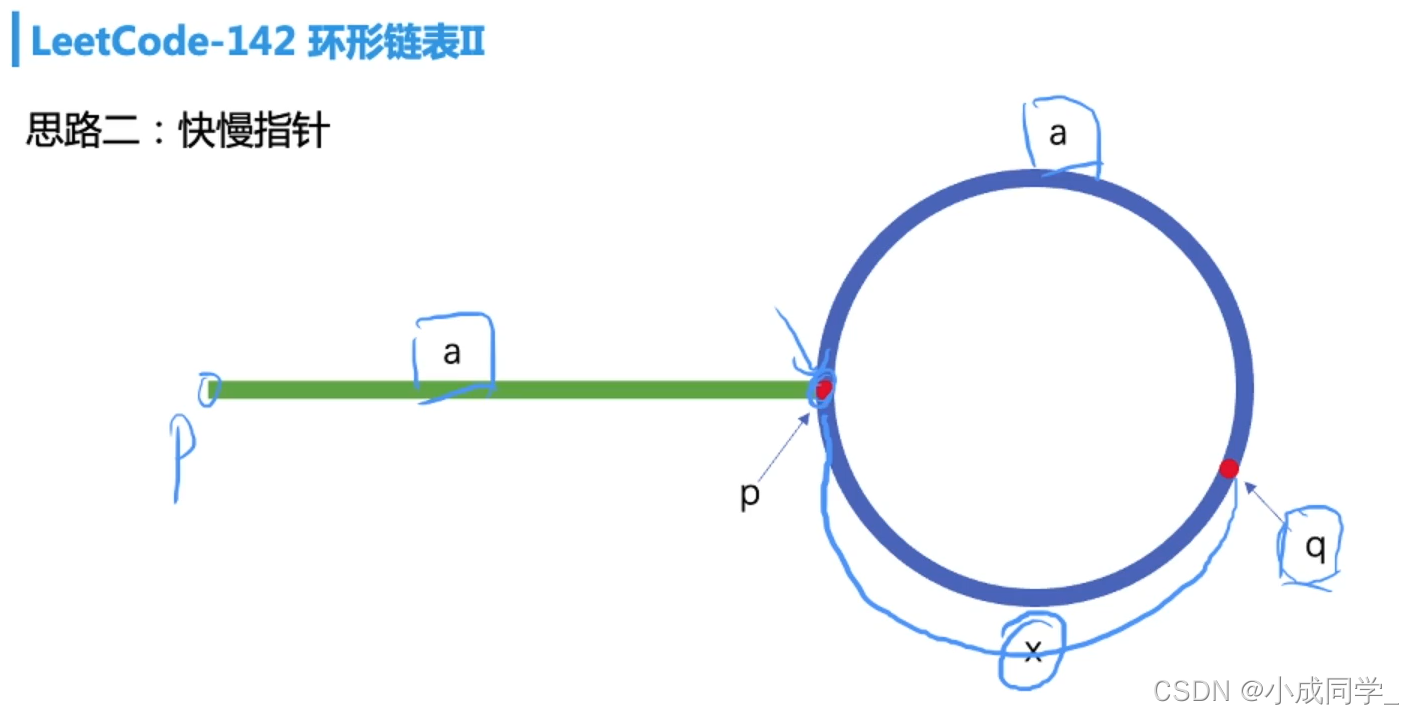
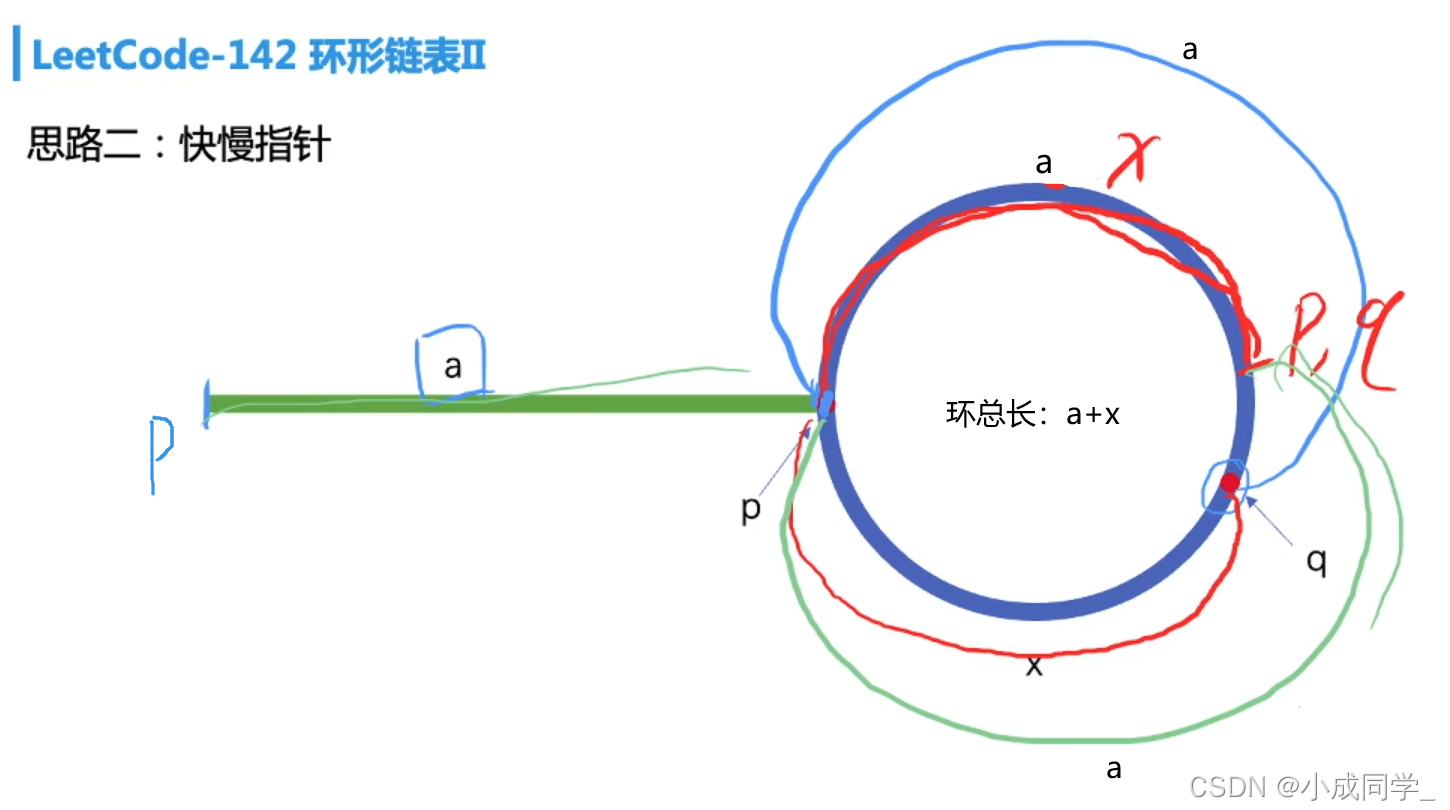
設p走了a的距離,同時q走了2a的距離,此時p處在環的起點,q在環里,設q距離p的距離為x,
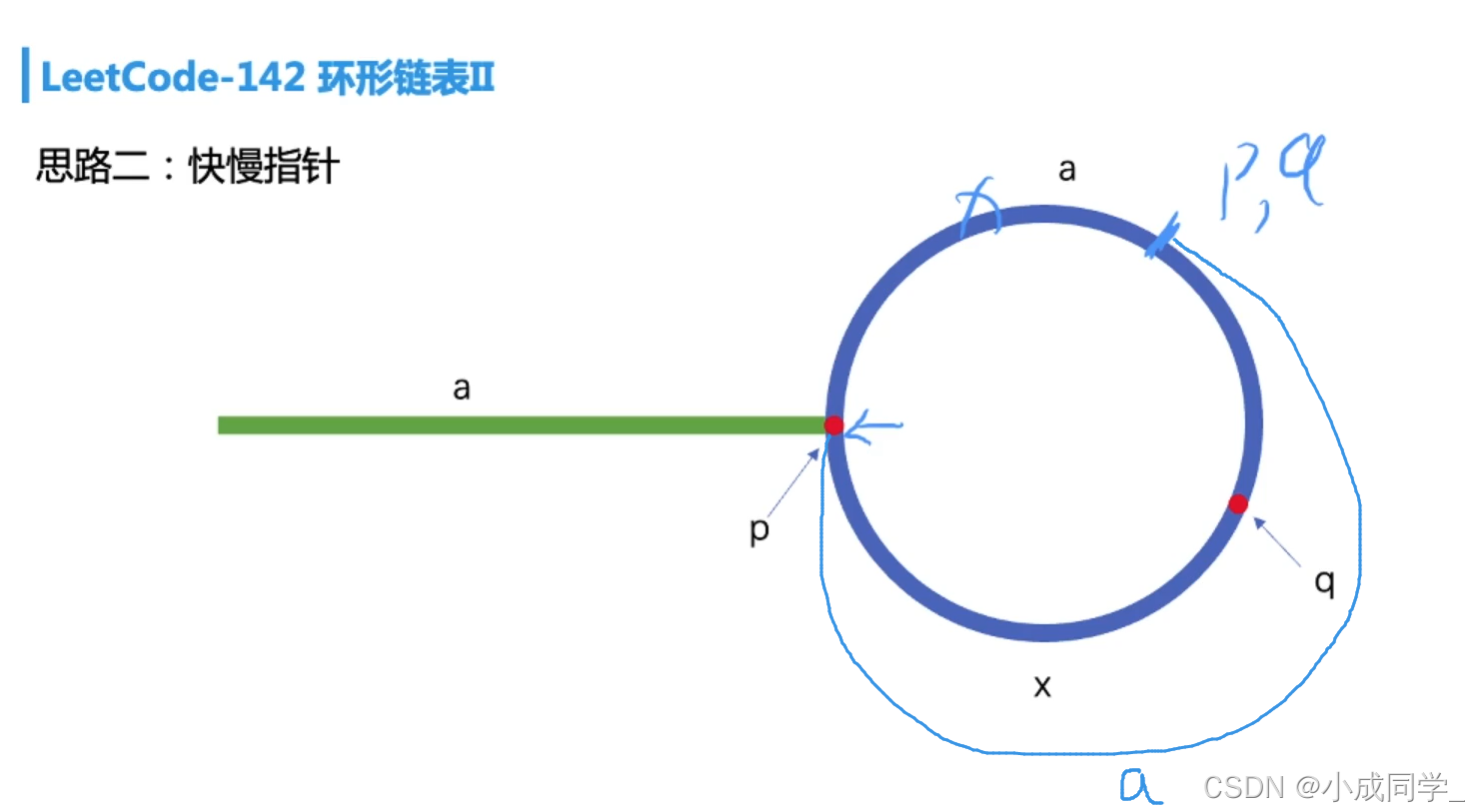
由于q與p之間的距離為x,所以當p再走x步時,q走了2x步,此時p,q兩點相遇;所以相遇點離我們環起點的位置肯定是x,
鏈表環的總長為a+x,當我們拿到x的長度時,我們也得到了a的長度,此a的長度跟p第一次走到環的起點a的長度是一樣的,
此時我們可以將p重新指向頭結點,p,q同時走a步,即再次相遇,此相遇位置即為環的起點,
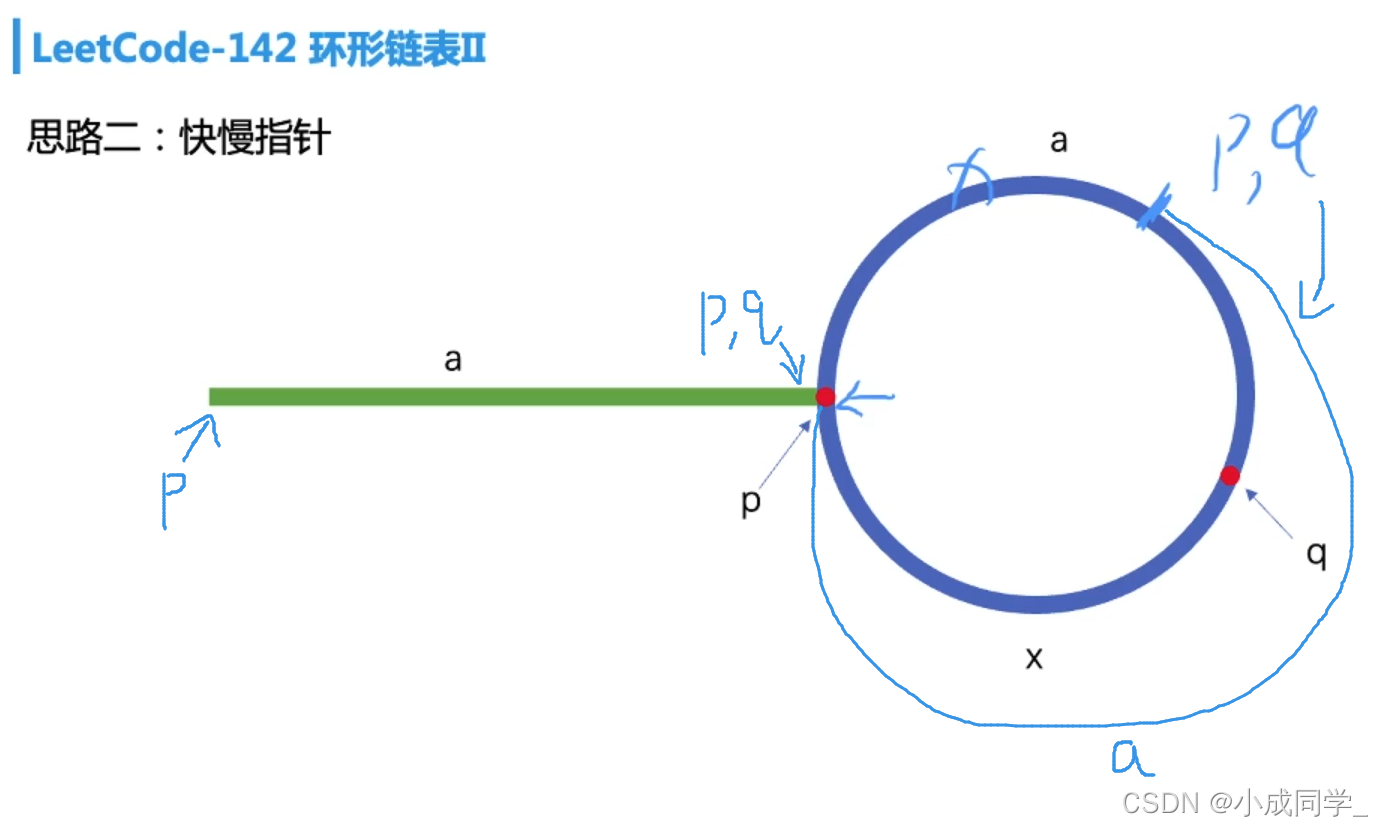
重新分析一下整體程序:先看淺藍色的線,p先走了a步,q走了2a步,此時p在環的起點,q在環里,設環的總長為a+x,看紅色的線,先看下面,此時q距離p的距離即為x,再看上面,當p再走x步時,q走2x步,p,q兩點相遇,此時相遇點距離起點的距離為x,看綠色的線,從而剩下的距離即為環的總長減去x,(a+x)-x=a,所以此時,我們可以將p指向頭結點,p和q同時走a步,即p和q再次相遇,此時即為環的起點,
LeetCode題解:兩種方法代碼實作
經典面試題—鏈表的反轉
leetcode206.反轉鏈表
難度:easy
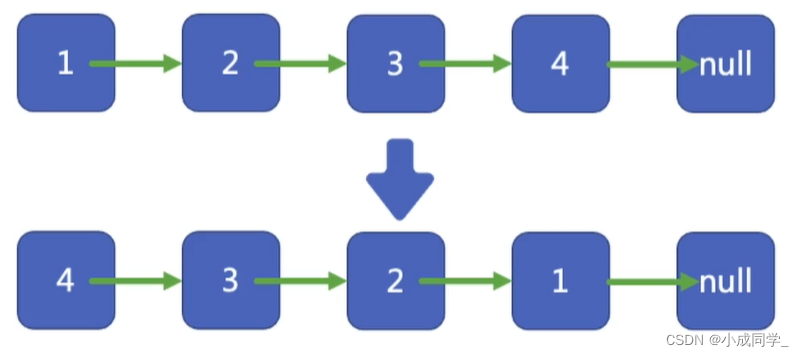
迭代實作
雙指標掃描
這個鏈表反轉其實很像如何交換兩個變數的值,我們需要借助另一個變數來實作,
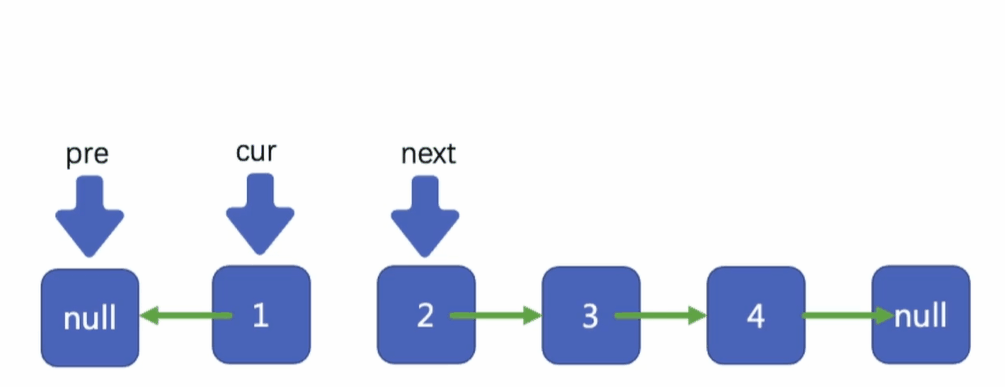
定義指標pre,pre指向null,
定義指標cur,cur指向我們的頭結點,
定義指標next,next指向cur所指向結點的下一個結點,
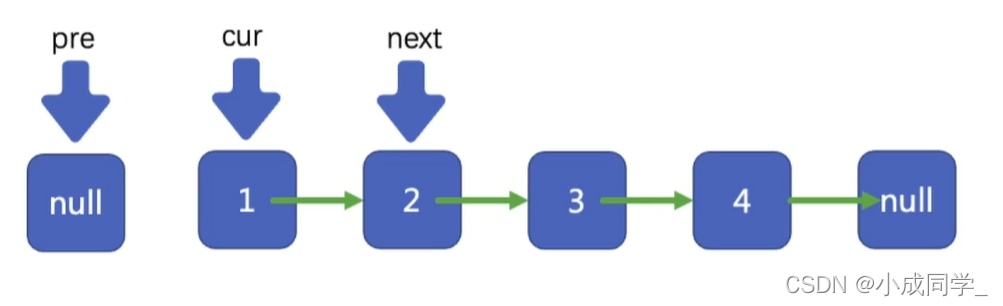
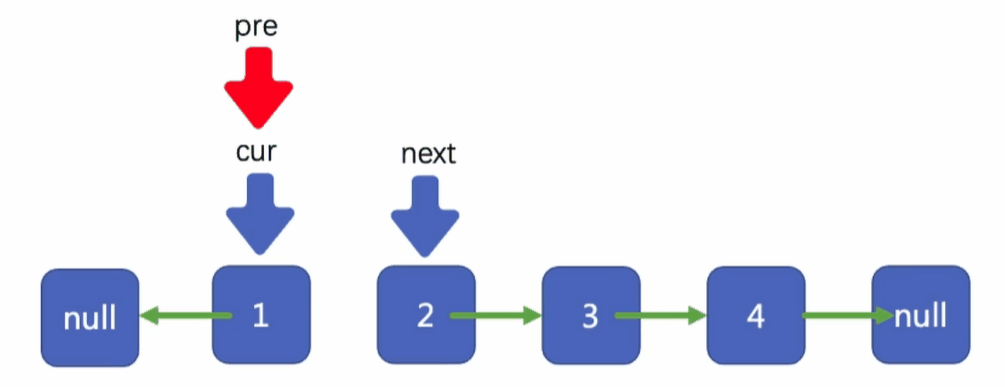
首先,我們先將cur指標所指向的結點指向pre指標所指向的結點
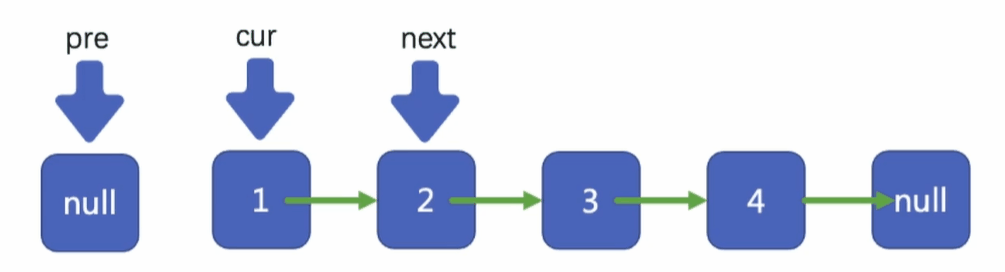
然后移動指標pre到指標cur所在的位置
移動cur到next所在的位置
將我們的next指標指向cur指標所指向結點的下一個結點
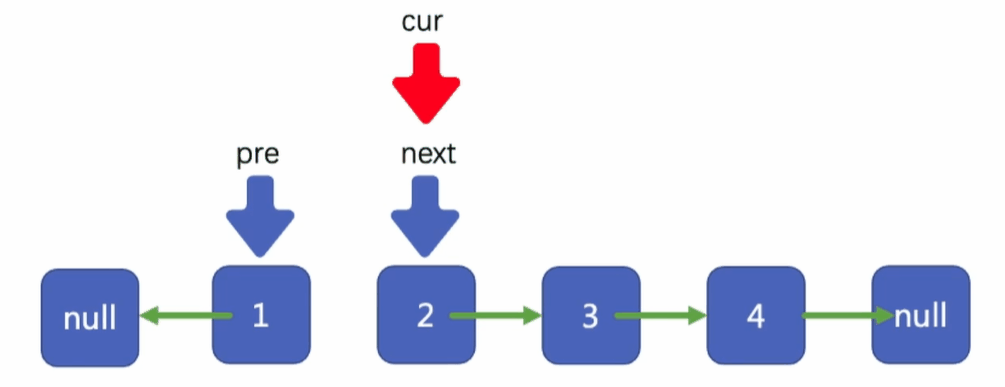
此時我們就完成了第一個結點的反轉,1指向了null,
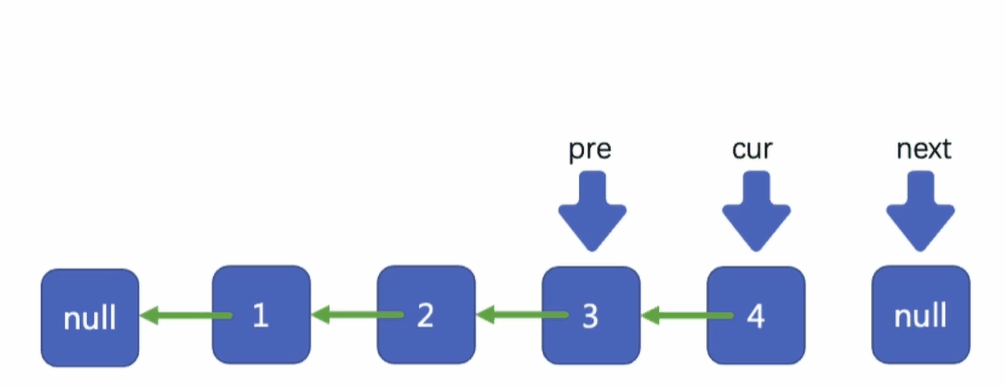
我們繼續剛才的操作,將2反轉,
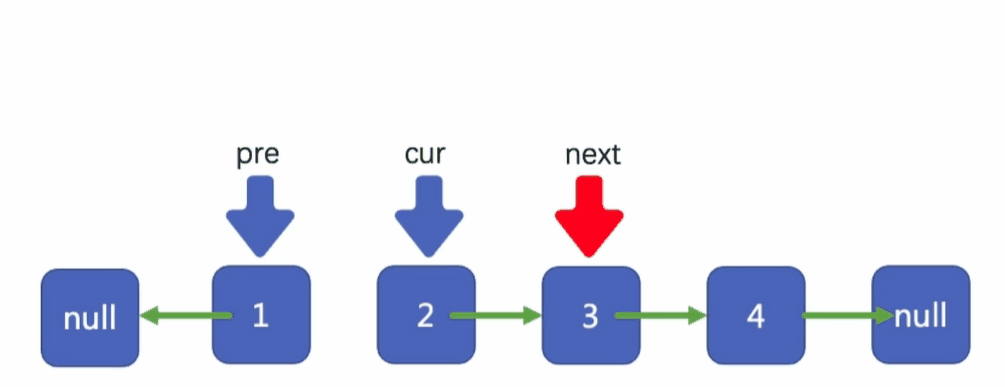
將剩下的反轉,
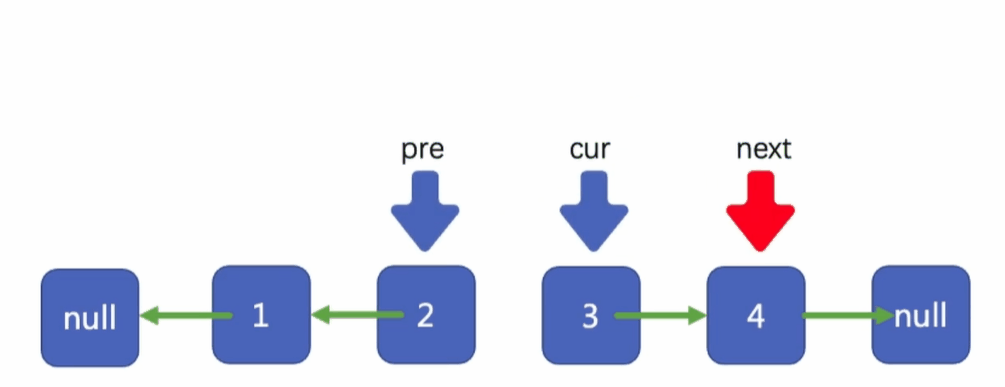
當cur指標指向null的時候,我們就完成了整個鏈表的反轉,
遞回實作
我們可以借助系統堆疊來實作,入堆疊的順序是1->2->3->4,但我們彈出堆疊的順序為4->3->2->1,
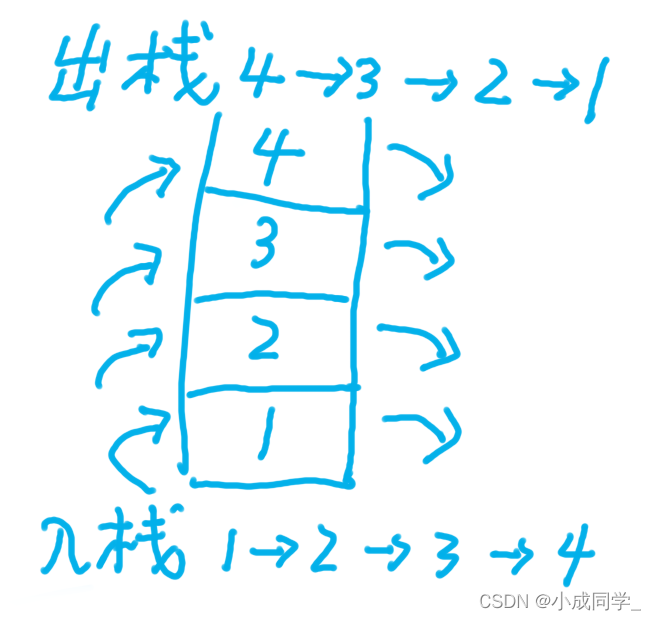
遞回實作對于新手比較難理解,后續到堆疊的部分會對這里有著更好的理解,
可以根據這張圖看代碼,
LeetCode題解:兩種方法代碼實作
遞回方法也可以看一下這個人的題解,清晰易懂,
leetcode92.反轉鏈表II
難度:mid
反轉給定區間的鏈表,
首先我們定義一個虛擬頭結點,起名叫做hair,它指向我們的真實頭結點,它在鏈表里有一個專有名詞:哨兵結點,
為什么要定義一個這樣的結點?其實這個東西很簡單,它相當于在頭結點上面加了一個邊界條件,來防止一些邊界特判,
假如我們要反轉的是1->2->3,那我們反轉完之后就是3->2->1->4->5->null,按照我們之前的編程經驗來看,我們首先定義一個int p = head,然后再對p進行操作,最后返回的就是head,通常不對head進行操作,但對于這種情況,我們還可以直接回傳head嗎?head指向的是1,我們最終的鏈表就只剩1->4->5->null,前面的數被丟掉了;所以這時我們在最前面加入一個哨兵結點,就可以防止這種邊緣特判,否則我們就要反轉一次判斷一下誰是頭結點,把頭結點記錄一下,然后再反轉再記錄,會很麻煩,而且還加了很多特判,
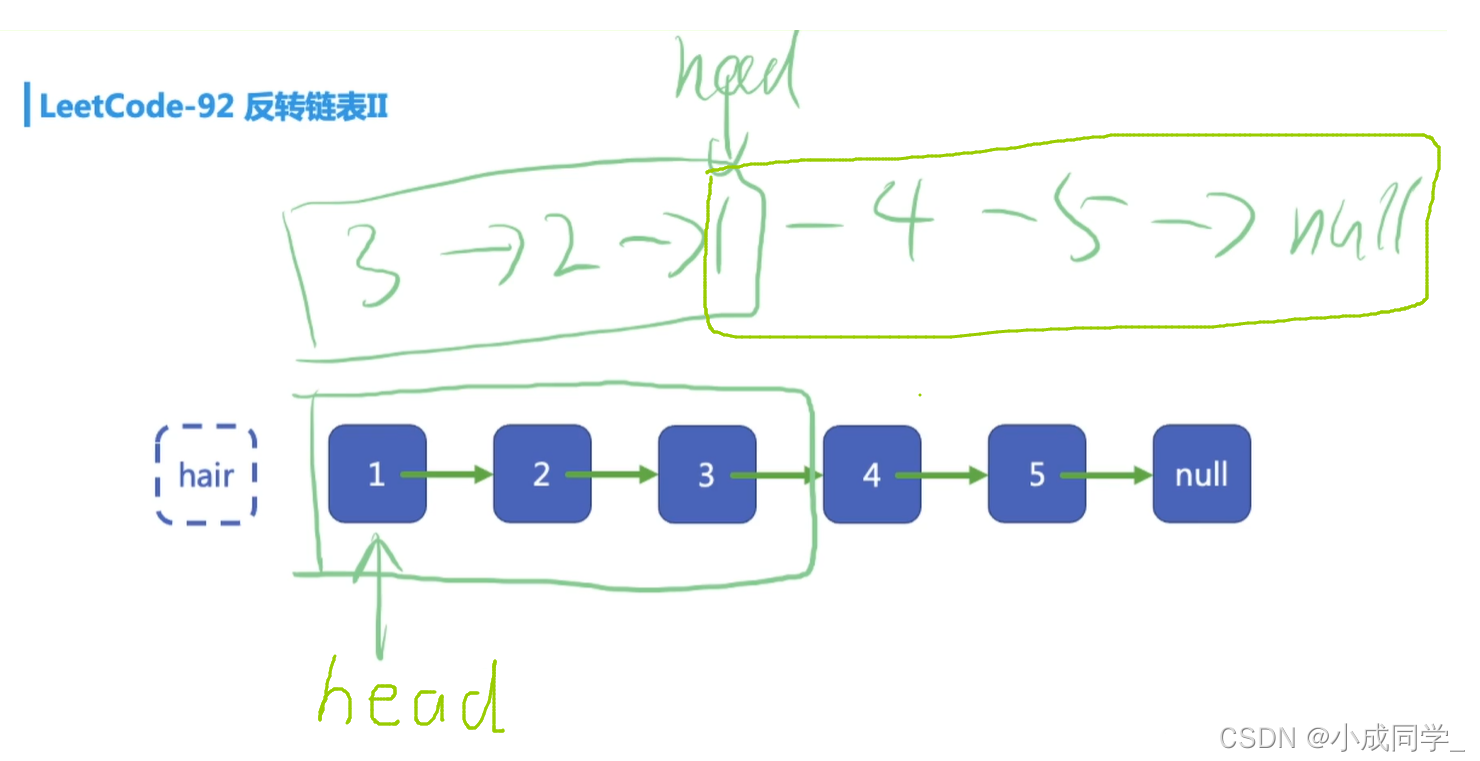
哨兵結點沒有什么實際的意義,它不參與我們鏈表中的活動,你可以把它想象為空,或者里面存的值是-1但它的任務只有一個,快速找到頭結點,
先將hair指向頭結點
定義一個指標pre指向hair
定義一個cur指向pre指標所指向結點的下一個結點
讓我們的pre指標和cur指標同時向后移動,直到我們找到了第left個結點,也就是題中的2,
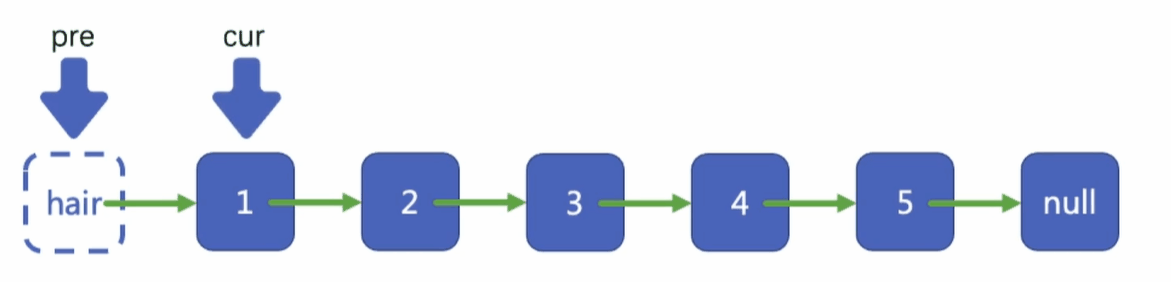
雙指標-頭插法
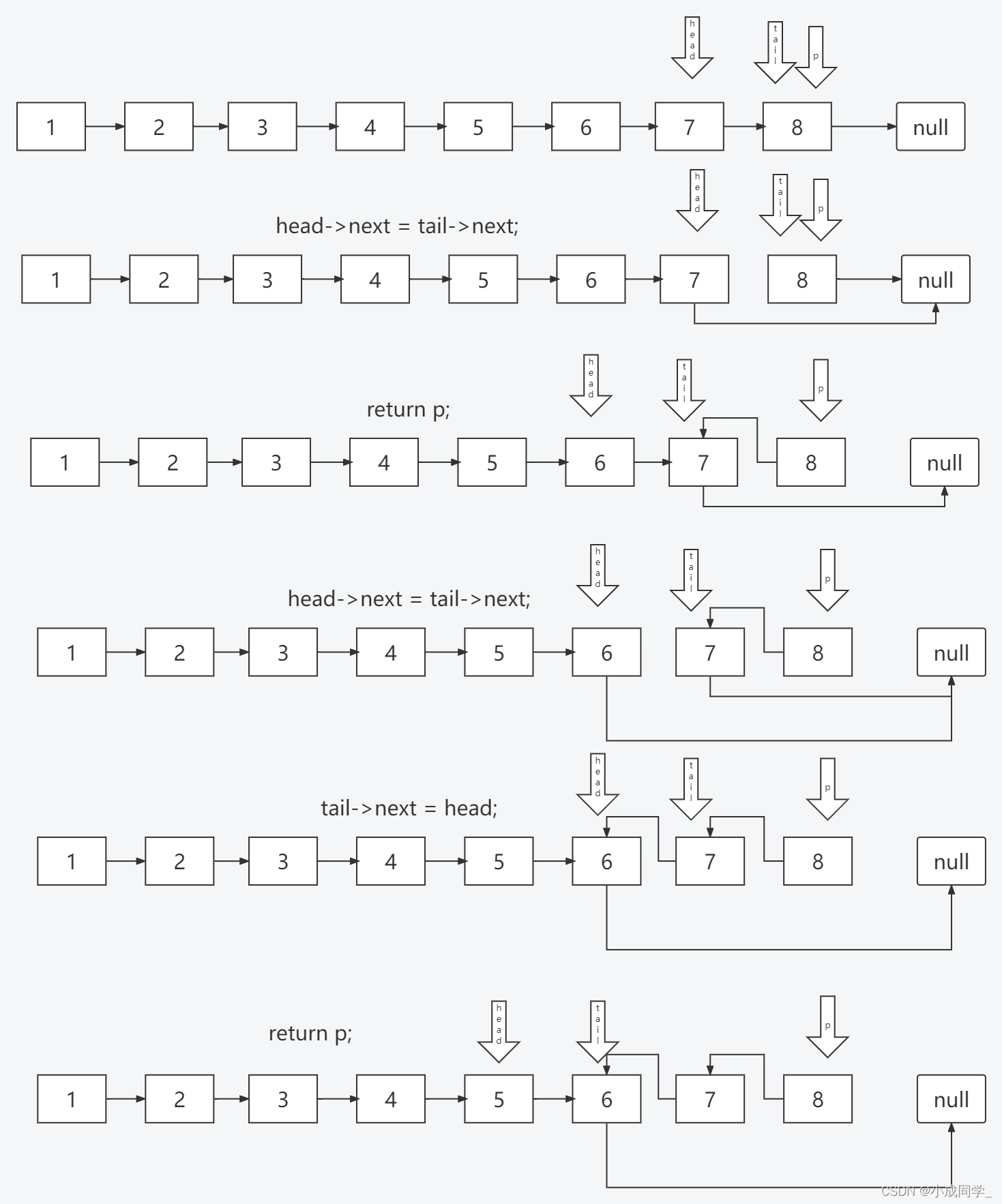
我們可以先將中間的3洗掉 然后插入到1和2之間 此時的鏈表是這樣的

那么同理,cur指向的還是2,pre指向的還是1,所以我們也可以很輕易的將4洗掉,插入到1和3之間
此時鏈表已經達到了題中的反轉要求
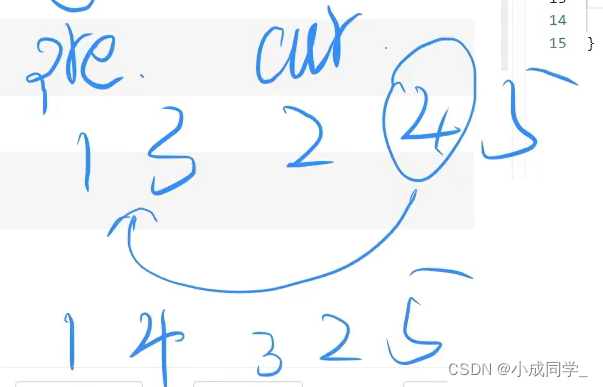
但是單向鏈表我們想要洗掉一個結點,我們必須通過它的上一個結點,在插入的程序中,我們應該注意什么?
一個鏈表1->2,我們想將3插入到1和2之間,我只可以通過1才可以找到2,因為1的下一個結點就是2,我們把1叫做A,把3叫做B,首先讓B結點的下一個結點指向A結點的下一個結點,也就是B.next = A.next,如圖
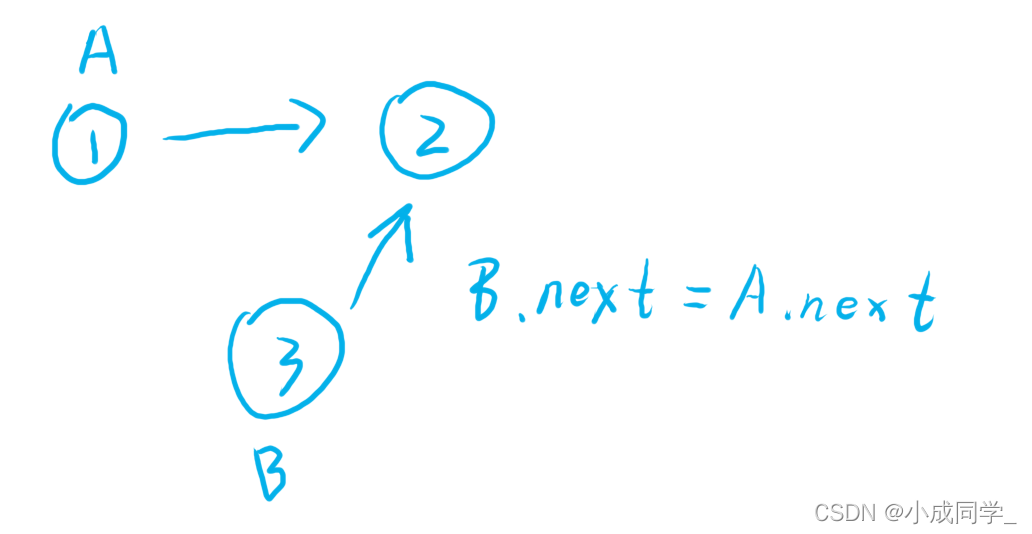
這么做的目的就是防止1結點和2結點之間斷開,而找不到2結點了,這樣我們就可以放心大膽的讓A的下一個結點指向B,也就是A.next = B,如圖
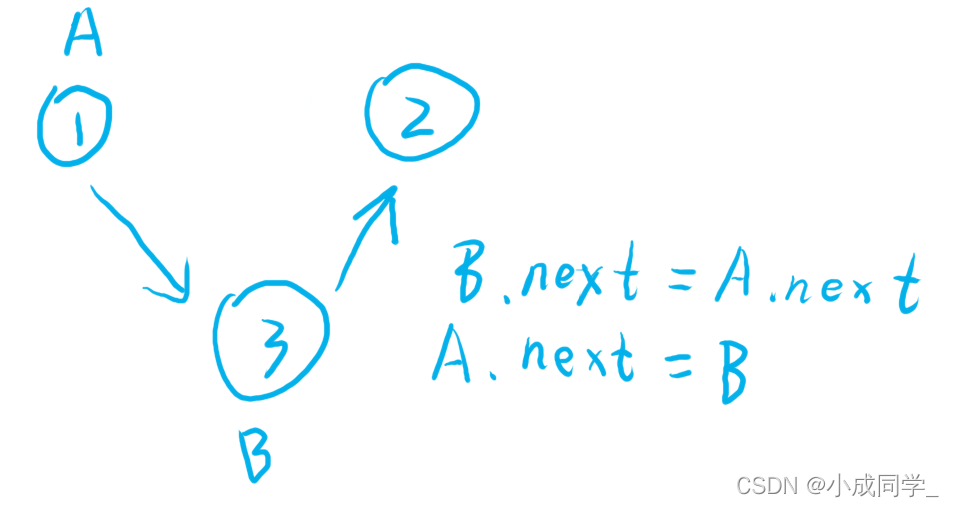
這樣3就插入進去了,這就是一個頭插法的程序,所以本題我們就可以用這個方法來解決,
我們的核心思路就是將cur后面的結點插入到pre后面,
遞回
遞回還是比較難理解,由于博主也還是初學者,怕我講的不到位,所以直接給大家看代碼吧,
LeetCode題解:兩種方法代碼實作
經典面試題—鏈表的結點洗掉
leetcode19.洗掉鏈表的倒數第N個結點
難度:mid
我們想洗掉一個結點,那就一定需要這個結點前面的結點,
假如我們想洗掉b,我們可以使a不指向b而指向c,這樣就完成了洗掉,之后要將b釋放掉,代碼就是a.next = a.next.next
那我們該如何找到a呢?
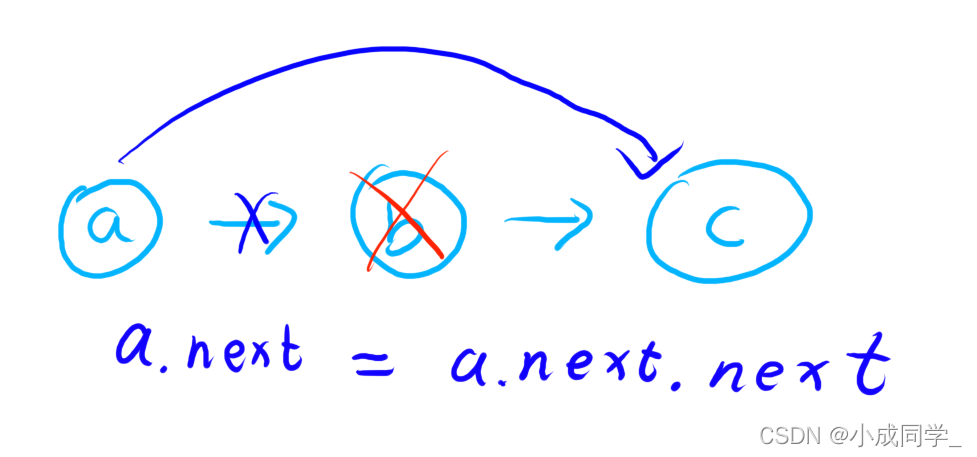
雙重遍歷 計算鏈表長度
洗掉鏈表倒數第N個結點,也就是洗掉鏈表第Length - N 結點的下一個結點,
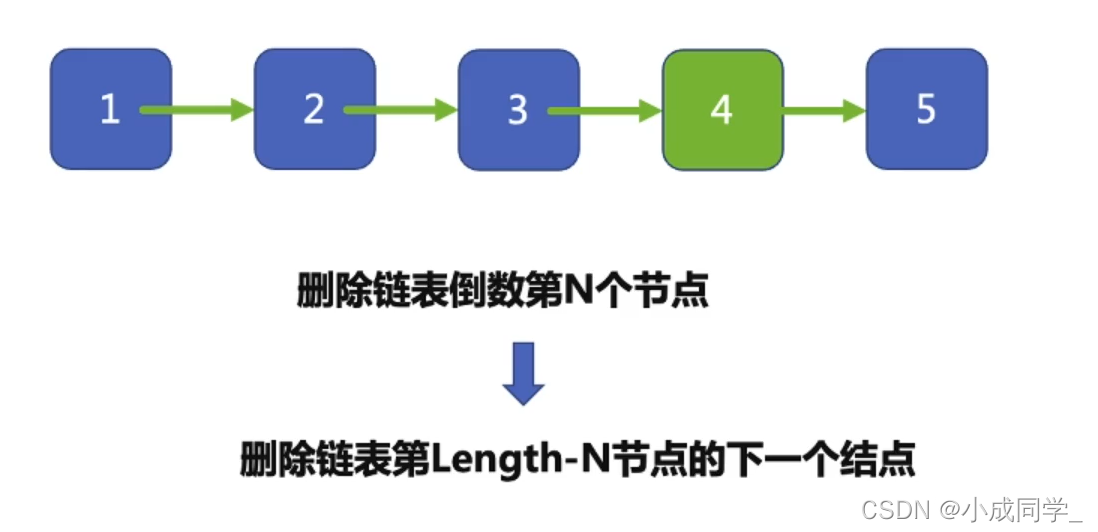
我們需要先遍歷鏈表,求出Length的長度,然后將4洗掉,
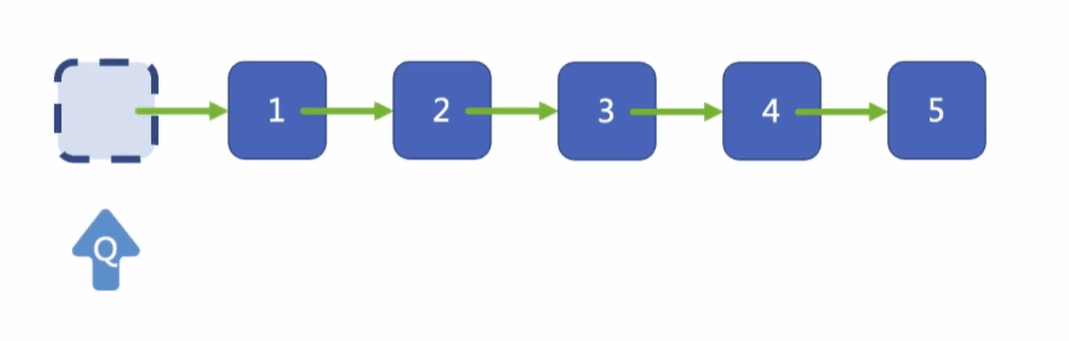
題中有一段話:
進階:你能嘗試使用一趟掃描實作嗎?
我們按上述方法是掃描了兩遍,才可以洗掉結點,我們如何只掃描一遍就完成洗掉操作呢?
雙指標
我們還是需要我們的老朋友,哨兵結點,
同樣也是雙指標掃描,快慢指標,p指向hair,q指向head,先讓q走n步,此時p和q同時走,當q走到null時,p必定指向的是待洗掉結點的前一個結點,
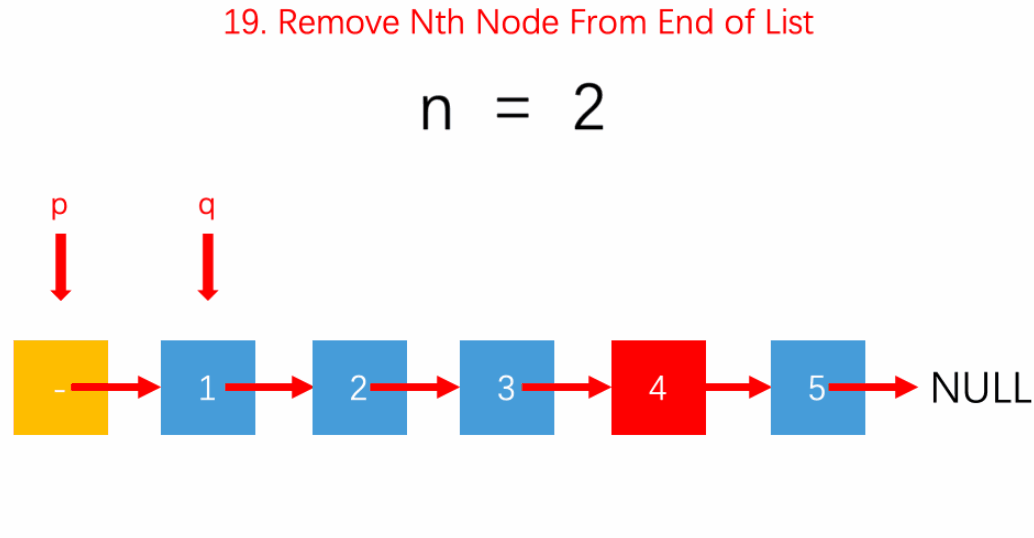
圖是力扣程式員吳師兄的,
LeetCode題解:兩種方法代碼實作
leetcode83.洗掉排序鏈表中的重復元素
難度:easy
其實還是挺簡單的,畢竟是升序排列,也就是說重復元素必定是挨在一起的,我們可以用指標指向的val值跟下一個結點的val值進行對比,如果相同,則直接指向相同結點的下一結點,如果不同,指標往下移,
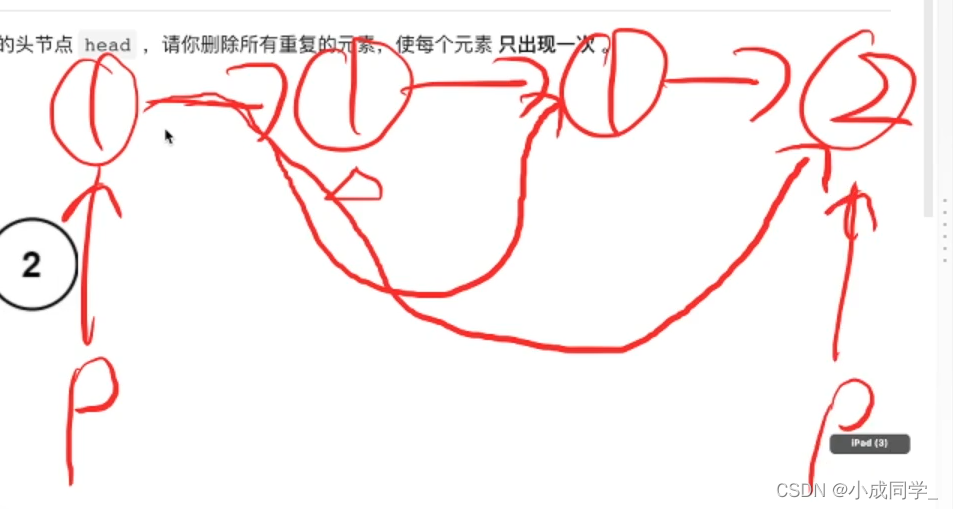
鏈表總結,鏈表這個資料結構看似簡單,沒有過多的條件,但它的題都非常有意思,它不涉及一些資料結構演算法的思維,但是它每一題的解法都特別巧妙,可以把鏈表題當成智力測驗題,腦筋急轉彎,第一次上手那種環形鏈表,誰能想到用快慢指標呢?這個在面試當中其實是一樣的,你不會這個東西你肯定就一直不會,我們如果在面試如果遇到了這種題,在面試的時候也很難再想出來,如果你面試之前做過了這些東西,那么你面試的時候也能大概率的想出來,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/404340.html
標籤:java