#加載R包
> library(psych)
> library(reshape2)
> library(ggplot2)
> library(factoextra)
##提前把名為ehbio_salmon.DESeq2.normalized.symbol.txt的檔案放在作業目錄,以制表符分割的.txt檔案
> exprData <- "ehbio_salmon.DESeq2.normalized.symbol.txt" ##這里只是定義exprData和sampleFile兩個變數,文本型別的(一開始我還以為就把檔案內容給賦值
> sampleFile <- "sampleFile" ##了)
> data <- read.table(exprData,header = T,row.names = NULL,sep ="\t") ###read.table()讀入檔案,
> class(data$id) ##判斷某一列的資料型別
[1] "character
> data <- read.table(exprData,header = T,row.names = "id",sep ="\t") ##一開始不明白row.names=NULL是怎么回事,并且我試了不加這個引數時data是一樣的,
Error in read.table(exprData, header = T, row.names = "id", sep = "\t") : ##看檔案知道row.names是指定哪一列為行名的,
'row.names'里不能有重復的名字 ##看了錯誤提示有些懵懂,之所以不能以id列為行名,是因為這列id有相同的,我下面驗證了一下
> rownames(data) <- data$id
Error in `.rowNamesDF<-`(x, value = https://www.cnblogs.com/SWTwanzhu/p/value) : 不允許有重復的'row.names'
此外: Warning message:
non-unique values when setting 'row.names': ‘ALG1L9P’, ‘ATXN7’, ‘BMS1P21’, ‘BMS1P4’, ‘CCDC39’, ‘CYB561D2’, ‘DIABLO’, ‘DNAJC9-AS1’, ‘DUXAP8’, ‘GOLGA8M’, ‘HSPA14’, ‘IPO5P1’, ‘ITFG2-AS1’, ‘LINC-PINT’, ‘LINC00484’, ‘LINC00941’, ‘LINC01238’, ‘LINC01297’, ‘LINC01422’, ‘LINC01481’, ‘MATR3’, ‘OR7E47P’, ‘PKD1P1’, ‘POLR2J3’, ‘POLR2J4’, ‘RAET1E-AS1’, ‘RF00012’, ‘RF00017’, ‘RF00019’, ‘RF02271’, ‘RGS5’, ‘RMRP’, ‘SCO2’, ‘SNHG28’, ‘SNX29P2’, ‘SPATA13’, ‘TBCE’, ‘TMSB15B’, ‘ZNF503’
# 處理重復名字,謹慎處理,先找到名字重復的原因再決定是否需要按一下方式都保留
> rownames_data <- make.names(data[,1],unique=T) ##有效名稱由字母 數字及dot和下劃線組成,字串中的空格或者-等“非法”字符都會被轉為.,
> length(rownames_data) ##上面講第一列匯出到rownames_data,遇上重復名稱,按順序加上.1 .2 ...等后綴,
[1] 27186
> data <- data[,-1,drop = F] ##[1,]訪問第一行or 1:n;[,1]訪問第一列or 1:n,這里是得到去掉第一列的剩余資料,drop=F表示更改是余下資料型別不變,
> rownames(data) <- rownames_data ##將沒有重復的第一列資料保存到data中,作為行名,
****
> write.table(rownames_data,file = "rownames_data.csv",quote = F) ##不加quote引數,字串及行號都會加上引號,行號默認有1 2 3,,列名x
> write.table(rownames_data,file = "rownames_data_1.csv",quote = F,row.names = F) ##
> write.table(rownames_data,file = "rownames_data_1.csv",quote = F,row.names = F,col.names = F) ##不要引號,不要行列名
****
> data <- data[rowSums(data)>0,] #去掉和為零的行
> nrow(data)
[1] 27186
> data <- data[apply(data, 1,var)!= 0,] ##!=表示不等于;去掉方差為0 的行,這些本身沒有意義,也妨礙后續運算;1表示對陣列的行進行操作
> ?rowSums ##計算一個陣列的行的和,回傳的是一個向量,長度為這個陣列的行數,
> x <- cbind(x1 = 3, x2 = c(4:1, 2:5))
> x
x1 x2
[1,] 3 4
[2,] 3 3
[3,] 3 2
[4,] 3 1
[5,] 3 2
[6,] 3 3
[7,] 3 4
[8,] 3 5
> rowSums(x)
[1] 7 6 5 4 5 6 7 8
> colSums(x)
x1 x2
24 24
> x1 <- x[rowSums(x)>5,]
> x1
x1 x2
[1,] 3 4
[2,] 3 3
[3,] 3 3
[4,] 3 4
[5,] 3 5
## apply(X, MARGIN, FUN, ...) 函式:Returns a vector or array or list of values obtained by applying a function to margins of an array or matrix.
##
X
an array, including a matrix.MARGIN
a vector giving the subscripts which the function will be applied over. E.g., for a matrix 1 indicates rows, 2 indicates columns, c(1, 2) indicates rows and columns. Where X has named dimnames, it can be a character vector selecting dimension names.
****
> mads <- apply(data,1,mad) ##計算中值絕對偏差 (MAD, median absolute deviation)度量基因表達變化幅度
> data <- data[rev(order(mads)),] ##將資料先按索引排序-升序order(),然后在反過來,然后在按照反過來的索引順序形成data,
> a <- c(1,4,0,9,57,32,6) > order(a) [1] 3 1 2 7 4 6 5 ##0在a中的索引值是3,故3在order()之后的第一位,order()回傳的是索引值,以此類推 > rev(order(a)) [1] 5 6 4 7 2 1 3 > b <- a[rev(order(a))] > b <- a[rev(order(a)),] Error in a[rev(order(a)), ] : 量度數目不對 > b <- a[rev(order(a))] > b [1] 57 32 9 6 4 1 0
> abc <- data.frame(a = c(1:3),b = c(4:6),c = c(7:9)) > abc a b c 1 1 4 7 2 2 5 8 3 3 6 9 > mads <- apply(abc,1,mad) > mads [1] 4.4478 4.4478 4.4478 > cbind(abc,d = c(1,1,1)) a b c d 1 1 4 7 1 2 2 5 8 1 3 3 6 9 1 > abc a b c 1 1 4 7 2 2 5 8 3 3 6 9 > abc <- cbind(abc,d = c(1,1,1)) ##給加一列 > abc a b c d 1 1 4 7 1 2 2 5 8 1 3 3 6 9 1 > mads <- apply(abc,1,mad) > abc a b c d 1 1 4 7 1 2 2 5 8 1 3 3 6 9 1 > mads [1] 2.2239 2.9652 3.7065 > abc <- abc[rev(order(mads)),] ##從結果看,按行的mad的降序重新排列了資料框 > abc a b c d 3 3 6 9 1 2 2 5 8 1 1 1 4 7 1
##data[x:y],訪問資料框時,如果不加標點訪問的是啥呢?
> data_t[1:5] [1] 245667.7 427435.1 221687.5 371144.2 240187.2 > data_t[,1:5] FN1 DCN CEMIP CCDC80 IGFBP5 untrt_N61311 245667.7 212953.1 40996.34 137229.15 77812.65 untrt_N052611 427435.1 360796.2 137783.10 232772.17 288609.20 untrt_N080611 221687.5 258977.3 53813.92 86258.13 210628.87 untrt_N061011 371144.2 408573.1 91066.80 212237.32 168067.42 trt_N61311 240187.2 210002.2 62301.12 136730.76 96021.74 trt_N052611 450103.2 316009.1 223111.85 226070.89 217439.21 trt_N080611 280226.2 225547.4 212724.84 124634.56 162677.38 trt_N061011 376518.2 393843.7 157919.47 236237.81 168387.36
> data_t <- t(data) ##t()函式對資料框進行轉置,行變列+列變行,對角線不變,
> abc_t <- t(abc) > abc a b c d 3 3 6 9 1 2 2 5 8 1 1 1 4 7 1 > abc_t 3 2 1 a 3 2 1 b 6 5 4 c 9 8 7 d 1 1 1
##文中說rows are samples and columns are variables,這句話不太懂,
> variableL <- ncol(data_t)
> variableL
[1] 27186
> if(sampleFile != ""){ ##這里的if()是何意???
+ sample <- read.table(sampleFile,header = T,row.names = 1,sep ="\t")
+ data_t_m <- merge(data_t,sample,by = 0)
+ rownames(data_t_m) <- data_t_m$Row.names
+ data_t <- data_t_m[,-1]
+ }
> data_t[,1:5]
FN1 DCN CEMIP CCDC80 IGFBP5
trt_N052611 450103.2 316009.1 223111.85 226070.89 217439.21
trt_N061011 376518.2 393843.7 157919.47 236237.81 168387.36
trt_N080611 280226.2 225547.4 212724.84 124634.56 162677.38
trt_N61311 240187.2 210002.2 62301.12 136730.76 96021.74
untrt_N052611 427435.1 360796.2 137783.10 232772.17 288609.20
untrt_N061011 371144.2 408573.1 91066.80 212237.32 168067.42
untrt_N080611 221687.5 258977.3 53813.92 86258.13 210628.87
untrt_N61311 245667.7 212953.1 40996.34 137229.15 77812.65
## row.names = 1?
## merge()?
## rownames(data_t_m) <- data_t_m$Row.names?
row.names = 1?
> sample_2 <- read.table("new_1.txt",header = T,row.names = 2,sep ="\t") > sample_2 Samp untrt1 untrt_N61311 untrt2 untrt_N052611 untrt3 untrt_N080611 untrt4 untrt_N061011 trt5 trt_N61311 trt6 trt_N052611 trt7 trt_N080611 trt8 trt_N061011 > sample_2 <- read.table("new_1.txt",header = T,row.names = NULL,sep ="\t") > sample_2 Samp conditions 1 untrt_N61311 untrt1 2 untrt_N052611 untrt2 3 untrt_N080611 untrt3 4 untrt_N061011 untrt4 5 trt_N61311 trt5 6 trt_N052611 trt6 7 trt_N080611 trt7 8 trt_N061011 trt8
##看來引數row.names是指定哪一列作為行名,
##所以上面的row.names = 1表示的是以第一列為行名,所以原資料框中第一行第一列的Samp就去掉了,
merge()?
> data_t[,1:5] FN1 DCN CEMIP CCDC80 IGFBP5 untrt_N61311 245667.7 212953.1 40996.34 137229.15 77812.65 untrt_N052611 427435.1 360796.2 137783.10 232772.17 288609.20 untrt_N080611 221687.5 258977.3 53813.92 86258.13 210628.87 untrt_N061011 371144.2 408573.1 91066.80 212237.32 168067.42 trt_N61311 240187.2 210002.2 62301.12 136730.76 96021.74 trt_N052611 450103.2 316009.1 223111.85 226070.89 217439.21 trt_N080611 280226.2 225547.4 212724.84 124634.56 162677.38 trt_N061011 376518.2 393843.7 157919.47 236237.81 168387.36 > sample <- read.table(sampleFile,header = T,row.names = 1,sep ="\t") > sample conditions untrt_N61311 untrt untrt_N052611 untrt untrt_N080611 untrt untrt_N061011 untrt trt_N61311 trt trt_N052611 trt trt_N080611 trt trt_N061011 trt ##這里可以看出data_t與sample的行名是一致的,隱隱約約覺得有個問題:這倆只是行名一致,又不是某列,這也能合并啊?? > data_t_m <- merge(data_t,sample,by = 0) ##merge()中引數all默認為FALSE,即合并時取交集--回傳匹配的行;all = TRUE時,取按相同列取并集, > data_t_m[,1:5] ##data_t_m的前5列 ###為何相同的列合并之后有了行名,還叫Row.names?? Row.names FN1 DCN CEMIP CCDC80 1 trt_N052611 450103.2 316009.1 223111.85 226070.89 2 trt_N061011 376518.2 393843.7 157919.47 236237.81 3 trt_N080611 280226.2 225547.4 212724.84 124634.56 4 trt_N61311 240187.2 210002.2 62301.12 136730.76 5 untrt_N052611 427435.1 360796.2 137783.10 232772.17 6 untrt_N061011 371144.2 408573.1 91066.80 212237.32 7 untrt_N080611 221687.5 258977.3 53813.92 86258.13 8 untrt_N61311 245667.7 212953.1 40996.34 137229.15 > ncol(sample) [1] 1 > ncol(data_t) [1] 27186 > ncol(data_t_m) [1] 27188 > data_t_m[,27182:27188] ##后7列
FSTL4 COL23A1 BEST2 IBSP LTF TAC1 conditions 1 1.515631 0.0000000 0.000000 0.0000000 1.722211 0.000000 trt 2 0.000000 1.7616370 1.181002 0.0000000 0.000000 0.000000 trt 3 0.000000 0.7821581 1.935371 0.7084139 2.398343 0.000000 trt 4 0.000000 3.7734772 2.274773 0.0000000 0.000000 3.956904 trt 5 5.018991 0.0000000 0.000000 4.1753179 0.000000 0.960596 untrt 6 0.000000 0.0000000 0.000000 0.0000000 0.000000 0.000000 untrt 7 2.512400 0.0000000 0.000000 0.0000000 2.629531 0.000000 untrt 8 0.000000 0.0000000 0.000000 0.0000000 0.000000 0.000000 untrt
####不明白的地方是data_t和sample合并之后為何行的順序會發生變化,且變化之后的順序又是什么順序呢?
rownames(data_t_m) <- data_t_m$Row.names?
> rownames(data_t_m) <- data_t_m$Row.names ##把Row.names這一列(是第一列)內容設定為行名,但是這一列不變!
> data_t <- data_t_m[,-1] ##去掉第一列,
> pca <- prcomp(data_t[,1:variableL],scale = T)
PCA結果展示 ##有限展示,因為剛接觸,這部分圖的邏輯不太懂
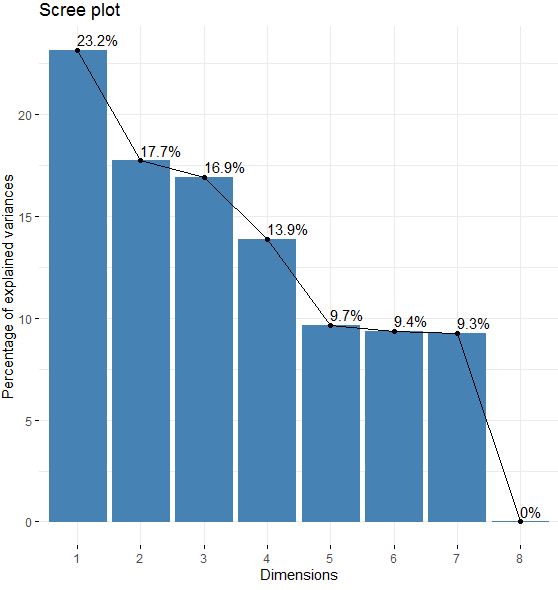
> fviz_eig(pca, addlabels = TRUE) ##addlabel引數為T,顯示百分比,
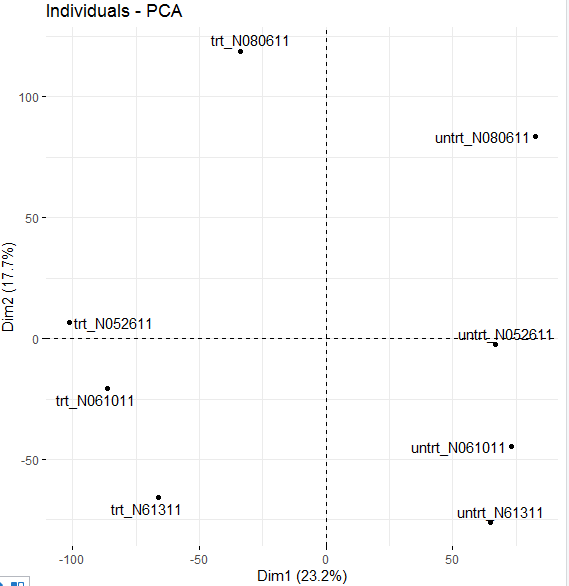
> fviz_pca_ind(pca, repel=T) ##repel=T 自動調整文本位置
> fviz_pca_ind(pca)
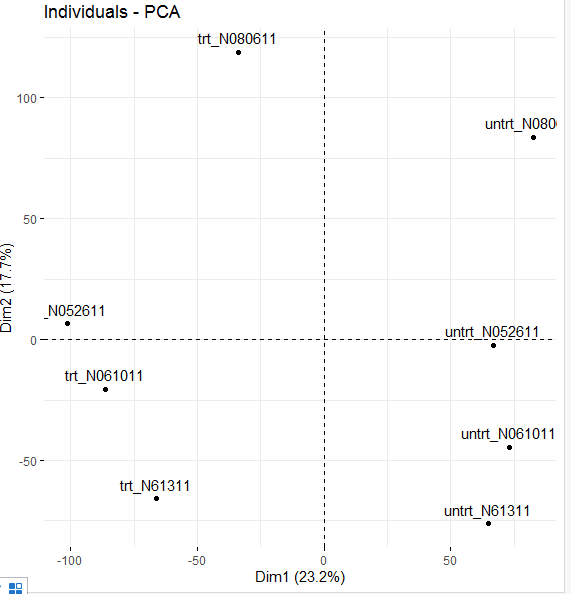
后面略過,沒跟著學了
參考https://mp.weixin.qq.com/s/4R14xJkQVPtaufaoXOcPIw
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/408.html
標籤:R
下一篇:利用 R 繪制擬合曲線