現在擁有了正則運算式這把神兵利器,我們就可以進?對爬取到的全部??源代碼進?篩選了,
下?我們?起嘗試?下爬取內涵段??站:
http://www.neihan8.com/article/list_5_1.html
打開之后,不難看到???個?個灰常有內涵的段?,當你進?翻?的時候,注意 url 地址的變化:
第??url: http: //www.neihan8.com/article/list_5_1 .html
第??url: http: //www.neihan8.com/article/list_5_2 .html
第三?url: http: //www.neihan8.com/article/list_5_3 .html
第四?url: http: //www.neihan8.com/article/list_5_4 .html
這樣我們的 url 規律找到了,要想爬取所有的段?,只需要修改?個引數即可, 下?我們就開始?步?步將所有的段?爬取下來吧,
第?步:獲取資料
1、按照我們之前的?法,我們需要寫?個加載??的?法,
- 這?我們統?定義?個類,將 url 請求作為?個成員?法處理
- 我們創建?個?件,叫 duanzi_spider.py
- 然后定義?個 Spider 類,并且添加?個加載??的成員?法
import urllib2 class Spider: """ """ 內涵段?爬?類 def loadPage(self, page): """ """ @brief 定義?個 url 請求??的?法 @param page 需要請求的第?? @returns 回傳的??html url = "http://www.neihan8.com/article/list_5_" + str(page) + ".html" #User-Agent 頭 user_agent = 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0' headers = {'User-Agent': user_agent} req = urllib2.Request(url, headers = headers) response = urllib2.urlopen(req) html = response.read() print html #return html
以上的 loadPage 的實作體想必?家應該很熟悉了,需要注意定義 python類 的成員?法需要額外添加?個引數 self .
- 那么 loadPage(self, page) 中的 page 是我們指定去請求第??
- 最后通過 print html 列印到螢屏上
- 然后我們寫?個 main 函式?到測驗?個 loadPage?法
2、寫 main 函式測驗?個 loadPage?法
if name """ == ' main ': """ ====================== 內涵段??爬? ====================== print '請按下回?開始' raw_input() #定義?個 Spider 物件 mySpider = Spider() mySpider.loadpage(1)
程式正常執?的話,我們會在螢屏上列印了內涵段?第??的全部 html代碼, 但是我們發現,html 中的中?部分顯示的可能是亂碼 ,
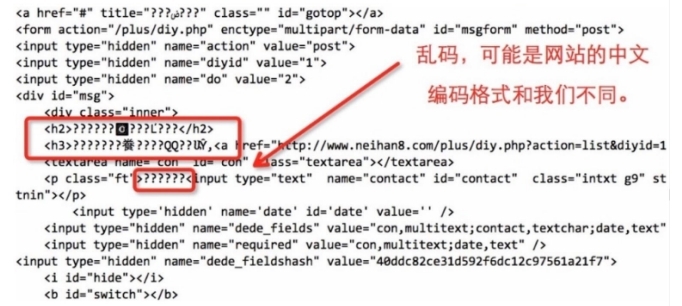
那么我們需要簡單的將得到的??源代碼處理?下,
def loadPage(self, page): """ """ @brief 定義?個 url 請求??的?法 @param page 需要請求的第?? @returns 回傳的??html url = "http://www.neihan8.com/article/list_5_" + str(page) + ".html" #User-Agent 頭 user_agent = 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0' headers = {'User-Agent': user_agent} req = urllib2.Request(url, headers = headers) response = urllib2.urlopen(req) html = response.read() gbk_html = html.decode('gbk').encode('utf-8') # print gbk_html return gbk_html
注意 :對于每個?站對中?的編碼各?不同,所以 html.decode(‘gbk’) 的寫法并不是通?寫法,根據?站的編碼?異,
這樣我們再次執?以下 duanzi_spider.py ,會發現之前的中?亂碼可以正常顯示了,
第?步:篩選資料
接下來我們已經得到了整個??的資料, 但是,很多內容我們并不關?,所以下?步我們需要進?篩選, 如何篩選,就?到了上?節講述 的正則運算式,
?先,
import re
然后, 在我們得到的 gbk_html 中進?篩選匹配,
我們需要?個匹配規則:
我們可以打開內涵段?的??,?標點擊右鍵 “ 查看源代碼 ” 你會驚奇的發現,我們需要的每個段?的內容都是在?個
 所以,我們只需要匹配到??中所有
所以,我們只需要匹配到??中所有
所以,我們只需要匹配到??中所有 <div > 到</div> 的資料就可以了,
根據正則運算式,我們可以推算出?個公式是:
<div.?>(.?)</div>
這個運算式實際上就是匹配到所有 div 中 filtered" />然后將這個正則應?到代碼中,我們會得到以下代碼:
def loadPage(self, page): """ """ @brief 定義?個 url 請求??的?法 @param page 需要請求的第?? @returns 回傳的??html url = "http://www.neihan8.com/article/list_5_" + str(page) + ".html" #User-Agent 頭 user_agent = 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0' headers = {'User-Agent': user_agent} req = urllib2.Request(url, headers = headers) response = urllib2.urlopen(req) html = response.read() gbk_html = html.decode('gbk').encode('utf-8') #找到所有的段?內容<div class = "f18 mb20"></div> #re.S 如果沒有 re.S 則是只匹配??有沒有符合規則的字串,如果沒有則 下 ??重新匹配 # 如果加上 re.S 則是將所有的字串將?個整體進?匹配 pattern = re.compile(r'<div.*?>(.*?)</di v>', re.S) item_list = pattern.findall(gbk_html) return item_list def printOnePage(self, item_list, page): """ @brief 處理得到的段?串列 @param item_list 得到的段?串列 @param page 處理第?? """ print "******* 第 %d ? 爬取完畢...*******" %page for item in item_list: print "================" print ite
這?需要注意?個是 re.S 是正則運算式中匹配的?個引數,
如果 沒有 re.S 則是 只匹配?? 有沒有符合規則的字串,如果沒有則下??重新匹配,
如果 加上 re.S 則是將 所有的字串 將?個整體進?匹配,findall將所有匹配到的結果封裝到?個 list 中,然后我們寫了?個遍歷 item_list 的?個?法 printOnePage() , ok 程式寫到這,我們再?次執??下,
Power@PowerMac ~$ python duanzi_spider.py我們第??的全部段?,不包含其他資訊全部的列印了出來,
你會發現段?中有很多 <p> , </p> 很是不舒服,實際上這個是 html 的?種段落的標簽,
在瀏覽器上看不出來,但是如果按照?本列印會有 <p> 出現,那么我們只需要把我們不希望的內容去掉即可了,
我們可以如下簡單修改?下 printOnePage().
def printOnePage(self, item_list, page): """ """ @brief 處理得到的段?串列 @param item_list 得到的段?串列 @param page 處理第?? print "******* 第 %d ? 爬取完畢...*******" %page for item in item_list: print "================" item = item.replace("<p>", "").replace("</p>", "").repl ace("<br />", "") print item
后面還有保存和顯示資料,如果需要專案完整資料和全套爬蟲視頻教程,請點此處,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/40971.html
標籤:Python