一、執行緒概念的引入
行程
之前我們已經了解了作業系統中行程的概念,程式并不能單獨運行,只有將程式裝載到記憶體中,系統為它分配資源才能運行,而這種執行的程式就稱之為行程,程式和行程的區別就在于:程式是指令的集合,它是行程運行的靜態描述文本;行程是程式的一次執行活動,屬于動態概念,在多道編程中,我們允許多個程式同時加載到記憶體中,在作業系統的調度下,可以實作并發地執行,正是這樣的設計,大大提高了CPU的利用率,行程的出現讓每個用戶感覺到自己獨享CPU,因此,行程就是為了在CPU上實作多道編程而提出的,
有了行程為什么要有執行緒
行程有很多優點,它提供了多道編程,讓我們感覺我們每個人都擁有自己的CPU和其他資源,可以提高計算機的利用率,很多人就不理解了,既然行程這么優秀,為什么還要執行緒呢?其實,仔細觀察就會發現行程還是有很多缺陷的,主要體現在兩點上:
- 行程只能在一個時間干一件事,如果想同時干兩件事或多件事,行程就無能為力了,
- 行程在執行的程序中如果阻塞,例如等待輸入,整個行程就會掛起,即使行程中有些作業不依賴于輸入的資料,也將無法執行,
如果這兩個缺點理解比較困難的話,舉個現實的例子也許你就清楚了:如果把我們上課的程序看成一個行程的話,那么我們要做的是耳朵聽老師講課,手上還要記筆記,腦子還要思考問題,這樣才能高效的完成聽課的任務,而如果只提供行程這個機制的話,上面這三件事將不能同時執行,同一時間只能做一件事,聽的時候就不能記筆記,也不能用腦子思考,這是其一;如果老師在黑板上寫演算程序,我們開始記筆記,而老師突然有一步推不下去了,阻塞住了,他在那邊思考著,而我們呢,也不能干其他事,即使你想趁此時思考一下剛才沒聽懂的一個問題都不行,這是其二,
現在你應該明白了行程的缺陷了,而解決的辦法很簡單,我們完全可以讓聽、寫、思三個獨立的程序,并行起來,這樣很明顯可以提高聽課的效率,而實際的作業系統中,也同樣引入了這種類似的機制——執行緒,
執行緒的出現
60年代,在OS中能擁有資源和獨立運行的基本單位是行程,然而隨著計算機技術的發展,行程出現了很多弊端,一是由于行程是資源擁有者,創建、撤消與切換存在較大的時空開銷,因此需要引入輕型行程;二是由于對稱多處理機(SMP)出現,可以滿足多個運行單位,而多個行程并行開銷過大,
因此在80年代,出現了能獨立運行的基本單位——執行緒(Threads),
注意:行程是資源分配的最小單位,執行緒是CPU調度的最小單位,每一個行程中至少有一個執行緒
二、行程和執行緒的關系
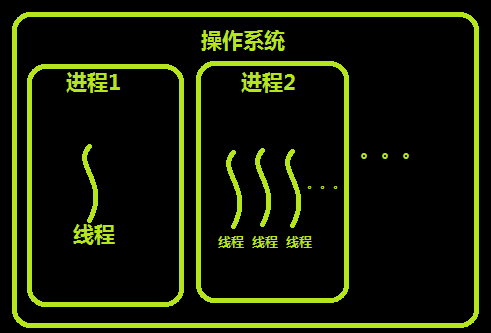
執行緒與行程的區別可以歸納為以下4點:
1)地址空間和其它資源(如打開檔案):行程間相互獨立,同一行程的各執行緒間共享,某行程內的執行緒在其它行程不可見,
2)通信:行程間通信IPC,執行緒間可以直接讀寫行程資料段(如全域變數)來進行通信——需要行程同步和互斥手段的輔助,以保證資料的一致性,
3)調度和切換:執行緒背景關系切換比行程背景關系切換要快得多,
4)在多執行緒作業系統中,行程不是一個可執行的物體,
ps:通過漫畫了解執行緒進城
三、執行緒的特點
在多執行緒的作業系統中,通常是在一個行程中包括多個執行緒,每個執行緒都是作為利用CPU的基本單位,是花費最小開銷的物體,執行緒具有以下屬性,
1)輕型物體
執行緒中的物體基本上不擁有系統資源,只是有一點必不可少的、能保證獨立運行的資源,
執行緒的物體包括程式、資料和TCB,執行緒是動態概念,它的動態特性由執行緒控制塊TCB(Thread Control Block)描述,
TCB包括以下資訊:
(1)執行緒狀態,
(2)當執行緒不運行時,被保存的現場資源,
(3)一組執行堆疊,
(4)存放每個執行緒的區域變數主存區,
(5)訪問同一個行程中的主存和其它資源,
用于指示被執行指令序列的程式計數器、保留區域變數、少數狀態引數和回傳地址等的一組暫存器和堆疊,
2)獨立調度和分派的基本單位,
在多執行緒OS中,執行緒是能獨立運行的基本單位,因而也是獨立調度和分派的基本單位,由于執行緒很“輕”,故執行緒的切換非常迅速且開銷小(在同一行程中的),
3)共享行程資源,
執行緒在同一行程中的各個執行緒,都可以共享該行程所擁有的資源,這首先表現在:所有執行緒都具有相同的行程id,這意味著,執行緒可以訪問該行程的每一個記憶體資源;此外,還可以訪問行程所擁有的已打開檔案、定時器、信號量機構等,由于同一個行程內的執行緒共享記憶體和檔案,所以執行緒之間互相通信不必呼叫內核,
4)可并發執行,
在一個行程中的多個執行緒之間,可以并發執行,甚至允許在一個行程中所有執行緒都能并發執行;同樣,不同行程中的執行緒也能并發執行,充分利用和發揮了處理機與外圍設備并行作業的能力,
四、使用執行緒的實際場景
開啟一個字處理軟體行程,該行程肯定需要辦不止一件事情,比如監聽鍵盤輸入,處理文字,定時自動將文字保存到硬碟,這三個任務操作的都是同一塊資料,因而不能用多行程,只能在一個行程里并發地開啟三個執行緒,如果是單執行緒,那就只能是,鍵盤輸入時,不能處理文字和自動保存,自動保存時又不能輸入和處理文字,
記憶體中的執行緒
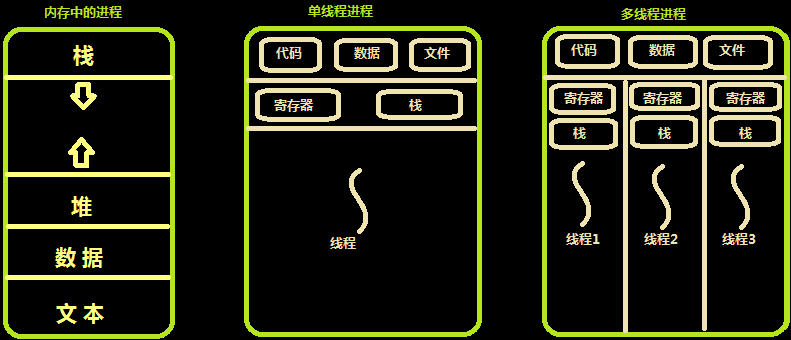
多個執行緒共享同一個行程的地址空間中的資源,是對一臺計算機上多個行程的模擬,有時也稱執行緒為輕量級的行程,
而對一臺計算機上多個行程,則共享物理記憶體、磁盤、列印機等其他物理資源,多執行緒的運行也多行程的運行類似,是cpu在多個執行緒之間的快速切換,
不同的行程之間是充滿敵意的,彼此是搶占、競爭cpu的關系,如果迅雷會和QQ搶資源,而同一個行程是由一個程式員的程式創建,所以同一行程內的執行緒是合作關系,一個執行緒可以訪問另外一個執行緒的記憶體地址,大家都是共享的,一個執行緒干死了另外一個執行緒的記憶體,那純屬程式員腦子有問題,
類似于行程,每個執行緒也有自己的堆疊,不同于行程,執行緒庫無法利用時鐘中斷強制執行緒讓出CPU,可以呼叫thread_yield運行執行緒自動放棄cpu,讓另外一個執行緒運行,
執行緒通常是有益的,但是帶來了不小程式設計難度,執行緒的問題是:
1. 父行程有多個執行緒,那么開啟的子執行緒是否需要同樣多的執行緒
2. 在同一個行程中,如果一個執行緒關閉了檔案,而另外一個執行緒正準備往該檔案內寫內容呢?
因此,在多執行緒的代碼中,需要更多的心思來設計程式的邏輯、保護程式的資料,
五、用戶級執行緒和內核級執行緒(了解)
執行緒的實作可以分為兩類:用戶級執行緒(User-Level Thread)和內核線執行緒(Kernel-Level Thread),后者又稱為內核支持的執行緒或輕量級行程,在多執行緒作業系統中,各個系統的實作方式并不相同,在有的系統中實作了用戶級執行緒,有的系統中實作了內核級執行緒,
用戶級執行緒
內核的切換由用戶態程式自己控制內核切換,不需要內核干涉,少了進出內核態的消耗,但不能很好的利用多核Cpu,
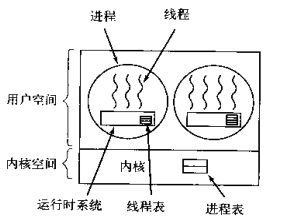
在用戶空間模擬作業系統對行程的調度,來呼叫一個行程中的執行緒,每個行程中都會有一個運行時系統,用來調度執行緒,此時當該行程獲取cpu時,行程內再調度出一個執行緒去執行,同一時刻只有一個執行緒執行,
內核級執行緒
內核級執行緒:切換由內核控制,當執行緒進行切換的時候,由用戶態轉化為內核態,切換完畢要從內核態回傳用戶態;可以很好的利用smp,即利用多核cpu,windows執行緒就是這樣的,

用戶級與內核級執行緒的對比
- 內核支持執行緒是OS內核可感知的,而用戶級執行緒是OS內核不可感知的,
- 用戶級執行緒的創建、撤消和調度不需要OS內核的支持,是在語言(如Java)這一級處理的;而內核支持執行緒的創建、撤消和調度都需OS內核提供支持,而且與行程的創建、撤消和調度大體是相同的,
- 用戶級執行緒執行系統呼叫指令時將導致其所屬行程被中斷,而內核支持執行緒執行系統呼叫指令時,只導致該執行緒被中斷,
- 在只有用戶級執行緒的系統內,CPU調度還是以行程為單位,處于運行狀態的行程中的多個執行緒,由用戶程式控制執行緒的輪換運行;在有內核支持執行緒的系統內,CPU調度則以執行緒為單位,由OS的執行緒調度程式負責執行緒的調度,
- 用戶級執行緒的程式物體是運行在用戶態下的程式,而內核支持執行緒的程式物體則是可以運行在任何狀態下的程式,
內核級執行緒
優點:當有多個處理機時,一個行程的多個執行緒可以同時執行,
缺點:由內核進行調度,
用戶級執行緒
優點:
執行緒的調度不需要內核直接參與,控制簡單,
可以在不支持執行緒的作業系統中實作,
創建和銷毀執行緒、執行緒切換代價等執行緒管理的代價比內核執行緒少得多,
允許每個行程定制自己的調度演算法,執行緒管理比較靈活,
執行緒能夠利用的表空間和堆疊空間比內核級執行緒多,
同一行程中只能同時有一個執行緒在運行,如果有一個執行緒使用了系統呼叫而阻塞,那么整個行程都會被掛起,另外,頁面失效也會產生同樣的問題,
缺點:
資源調度按照行程進行,多個處理機下,同一個行程中的執行緒只能在同一個處理機下分時復用
混合實作
用戶級與內核級的多路復用,內核同一調度內核執行緒,每個內核執行緒對應n個用戶執行緒
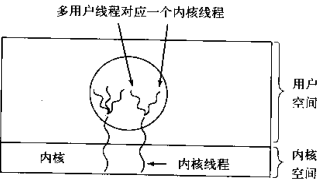
Linux作業系統的NPTL:
歷史
在內核2.6以前的調度物體都是行程,內核并沒有真正支持執行緒,它是能過一個系統呼叫clone()來實作的,這個呼叫創建了一份呼叫行程的拷貝,跟fork()不同的是,這份行程拷貝完全共享了呼叫行程的地址空間,LinuxThread就是通過這個系統呼叫來提供執行緒在內核級的支持的(許多以前的執行緒實作都完全是在用戶態,內核根本不知道執行緒的存在),非常不幸的是,這種方法有相當多的地方沒有遵循POSIX標準,特別是在信號處理,調度,行程間通信原語等方面,
很顯然,為了改進LinuxThread必須得到內核的支持,并且需要重寫執行緒庫,為了實作這個需求,開始有兩個相互競爭的專案:IBM啟動的NGTP(Next Generation POSIX Threads)專案,以及Redhat公司的NPTL,在2003年的年中,IBM放棄了NGTP,也就是大約那時,Redhat發布了最初的NPTL,
NPTL最開始在redhat linux 9里發布,現在從RHEL3起內核2.6起都支持NPTL,并且完全成了GNU C庫的一部分,
設計
NPTL使用了跟LinuxThread相同的辦法,在內核里面執行緒仍然被當作是一個行程,并且仍然使用了clone()系統呼叫(在NPTL庫里呼叫),但是,NPTL需要內核級的特殊支持來實作,比如需要掛起然后再喚醒執行緒的執行緒同步原語futex.
NPTL也是一個1*1的執行緒庫,就是說,當你使用pthread_create()呼叫創建一個執行緒后,在內核里就相應創建了一個調度物體,在linux里就是一個新行程,這個方法最大可能的簡化了執行緒的實作,
除NPTL的1*1模型外還有一個m*n模型,通常這種模型的用戶執行緒數會比內核的調度物體多,在這種實作里,執行緒庫本身必須去處理可能存在的調度,這樣在執行緒庫內部的背景關系切換通常都會相當的快,因為它避免了系統呼叫轉到內核態,然而這種模型增加了執行緒實作的復雜性,并可能出現諸如優先級反轉的問題,此外,用戶態的調度如何跟內核態的調度進行協調也是很難讓人滿意,
六、執行緒和Python
理論知識
全域解釋器鎖GIL
Python代碼的執行由Python虛擬機(也叫解釋器主回圈)來控制,Python在設計之初就考慮到要在主回圈中,同時只有一個執行緒在執行,雖然 Python 解釋器中可以“運行”多個執行緒,但在任意時刻只有一個執行緒在解釋器中運行,
對Python虛擬機的訪問由全域解釋器鎖(GIL)來控制,正是這個鎖能保證同一時刻只有一個執行緒在運行,
在多執行緒環境中,Python 虛擬機按以下方式執行:
a、設定 GIL;
b、切換到一個執行緒去運行;
c、運行指定數量的位元組碼指令或者執行緒主動讓出控制(可以呼叫 time.sleep(0));
d、把執行緒設定為睡眠狀態;
e、解鎖 GIL;
d、再次重復以上所有步驟,
在呼叫外部代碼(如 C/C++擴展函式)的時候,GIL將會被鎖定,直到這個函式結束為止(由于在這期間沒有Python的位元組碼被運行,所以不會做執行緒切換)撰寫擴展的程式員可以主動解鎖GIL,
Python執行緒模塊的選擇
Python提供了幾個用于多執行緒編程的模塊,包括thread、threading和Queue等,thread和threading模塊允許程式員創建和管理執行緒,thread模塊提供了基本的執行緒和鎖的支持,threading提供了更高級別、功能更強的執行緒管理的功能,Queue模塊允許用戶創建一個可以用于多個執行緒之間共享資料的佇列資料結構,
避免使用thread模塊,因為更高級別的threading模塊更為先進,對執行緒的支持更為完善,而且使用thread模塊里的屬性有可能會與threading出現沖突;其次低級別的thread模塊的同步原語很少(實際上只有一個),而threading模塊則有很多;再者,thread模塊中當主執行緒結束時,所有的執行緒都會被強制結束掉,沒有警告也不會有正常的清除作業,至少threading模塊能確保重要的子執行緒退出后行程才退出,
thread模塊不支持守護執行緒,當主執行緒退出時,所有的子執行緒不論它們是否還在作業,都會被強行退出,而threading模塊支持守護執行緒,守護執行緒一般是一個等待客戶請求的服務器,如果沒有客戶提出請求它就在那等著,如果設定一個執行緒為守護執行緒,就表示這個執行緒是不重要的,在行程退出的時候,不用等待這個執行緒退出,
threading模塊
multiprocess模塊的完全模仿了threading模塊的介面,二者在使用層面,有很大的相似性,因而不再詳細介紹(官方鏈接)
執行緒的創建Threading.Thread類
執行緒的創建
第一種方式:
from threading import Thread
import time
def sayhi(name):
time.sleep(2)
print('%s say hello' %name)
if __name__ == '__main__':
t=Thread(target=sayhi,args=('egon',))
t.start()
print('主執行緒')
第二種方式:
from threading import Thread
import time
class Sayhi(Thread):
def __init__(self,name):
super().__init__()
self.name=name
def run(self):
time.sleep(2)
print('%s say hello' % self.name)
if __name__ == '__main__':
t = Sayhi('egon')
t.start()
print('主執行緒')
多執行緒與多行程
pid的比較:
from threading import Thread
from multiprocessing import Process
import os
def work():
print('hello',os.getpid())
if __name__ == '__main__':
#part1:在主行程下開啟多個執行緒,每個執行緒都跟主行程的pid一樣
t1=Thread(target=work)
t2=Thread(target=work)
t1.start()
t2.start()
print('主執行緒/主行程pid',os.getpid())
#part2:開多個行程,每個行程都有不同的pid
p1=Process(target=work)
p2=Process(target=work)
p1.start()
p2.start()
print('主執行緒/主行程pid',os.getpid())
開啟效率的較量:
from threading import Thread
from multiprocessing import Process
import os
def work():
print('hello')
if __name__ == '__main__':
#在主行程下開啟執行緒
t=Thread(target=work)
t.start()
print('主執行緒/主行程')
'''
列印結果:
hello
主執行緒/主行程
'''
#在主行程下開啟子行程
t=Process(target=work)
t.start()
print('主執行緒/主行程')
'''
列印結果:
主執行緒/主行程
hello
'''
記憶體資料的共享問題:
from threading import Thread
from multiprocessing import Process
import os
def work():
global n
n=0
if __name__ == '__main__':
# n=100
# p=Process(target=work)
# p.start()
# p.join()
# print('主',n) #毫無疑問子行程p已經將自己的全域的n改成了0,但改的僅僅是它自己的,查看父行程的n仍然為100
n=1
t=Thread(target=work)
t.start()
t.join()
print('主',n) #查看結果為0,因為同一行程內的執行緒之間共享行程內的資料
練習 :多執行緒實作socket
服務端:
#_*_coding:utf-8_*_
#!/usr/bin/env python
import multiprocessing
import threading
import socket
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
s.bind(('127.0.0.1',8080))
s.listen(5)
def action(conn):
while True:
data=https://www.cnblogs.com/JZjuechen/p/conn.recv(1024)
print(data)
conn.send(data.upper())
if __name__ =='__main__':
while True:
conn,addr=s.accept()
p=threading.Thread(target=action,args=(conn,))
p.start()
客戶端:
#_*_coding:utf-8_*_
#!/usr/bin/env python
import socket
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
s.connect(('127.0.0.1',8080))
while True:
msg=input('>>: ').strip()
if not msg:continue
s.send(msg.encode('utf-8'))
data=https://www.cnblogs.com/JZjuechen/p/s.recv(1024)
print(data)
Thread類的其他方法
Thread實體物件的方法
# isAlive(): 回傳執行緒是否活動的,
# getName(): 回傳執行緒名,
# setName(): 設定執行緒名,
threading模塊提供的一些方法:
# threading.currentThread(): 回傳當前的執行緒變數,
# threading.enumerate(): 回傳一個包含正在運行的執行緒的list,正在運行指執行緒啟動后、結束前,不包括啟動前和終止后的執行緒,
# threading.activeCount(): 回傳正在運行的執行緒數量,與len(threading.enumerate())有相同的結果,
代碼示例:
from threading import Thread
import threading
from multiprocessing import Process
import os
def work():
import time
time.sleep(3)
print(threading.current_thread().getName())
if __name__ == '__main__':
#在主行程下開啟執行緒
t=Thread(target=work)
t.start()
print(threading.current_thread().getName())
print(threading.current_thread()) #主執行緒
print(threading.enumerate()) #連同主執行緒在內有兩個運行的執行緒
print(threading.active_count())
print('主執行緒/主行程')
'''
列印結果:
MainThread
<_MainThread(MainThread, started 140735268892672)>
[<_MainThread(MainThread, started 140735268892672)>, <Thread(Thread-1, started 123145307557888)>]
主執行緒/主行程
Thread-1
'''
join()方法:
from threading import Thread
import time
def sayhi(name):
time.sleep(2)
print('%s say hello' %name)
if __name__ == '__main__':
t=Thread(target=sayhi,args=('egon',))
t.start()
t.join()
print('主執行緒')
print(t.is_alive())
'''
egon say hello
主執行緒
False
'''
守護執行緒
無論是行程還是執行緒,都遵循:守護xx會等待主xx運行完畢后被銷毀,需要強調的是:運行完畢并非終止運行
1.對主行程來說,運行完畢指的是主行程代碼運行完畢
2.對主執行緒來說,運行完畢指的是主執行緒所在的行程內所有非守護執行緒統統運行完畢,主執行緒才算運行完畢
主行程在其代碼結束后就已經算運行完畢了(守護行程在此時就被回收),然后主行程會一直等非守護的子行程都運行完畢后回收子行程的資源(否則會產生僵尸行程),才會結束,
主執行緒在其他非守護執行緒運行完畢后才算運行完畢(守護執行緒在此時就被回收),因為主執行緒的結束意味著行程的結束,行程整體的資源都將被回收,而行程必須保證非守護執行緒都運行完畢后才能結束,
守護執行緒示例1:
from threading import Thread
import time
def sayhi(name):
time.sleep(2)
print('%s say hello' %name)
if __name__ == '__main__':
t=Thread(target=sayhi,args=('egon',))
t.setDaemon(True) #必須在t.start()之前設定
t.start()
print('主執行緒')
print(t.is_alive())
'''
主執行緒
True
'''
守護執行緒示例2:
from threading import Thread
import time
def foo():
print(123)
time.sleep(1)
print("end123")
def bar():
print(456)
time.sleep(3)
print("end456")
t1=Thread(target=foo)
t2=Thread(target=bar)
t1.daemon=True
t1.start()
t2.start()
print("main-------")
鎖與GIL
同步鎖
多個執行緒搶占資源的情況:
from threading import Thread
import os,time
def work():
global n
temp=n
time.sleep(0.1)
n=temp-1
if __name__ == '__main__':
n=100
l=[]
for i in range(100):
p=Thread(target=work)
l.append(p)
p.start()
for p in l:
p.join()
print(n) # 結果可能為99
執行緒鎖的基本用法:
import threading
R=threading.Lock()
R.acquire()
'''
對公共資料的操作
'''
R.release()
同步鎖的參考:
from threading import Thread,Lock
import os,time
def work():
global n
lock.acquire()
temp=n
time.sleep(0.1)
n=temp-1
lock.release()
if __name__ == '__main__':
lock=Lock()
n=100
l=[]
for i in range(100):
p=Thread(target=work)
l.append(p)
p.start()
for p in l:
p.join()
print(n) #結果肯定為0,由原來的并發執行變成串行,犧牲了執行效率保證了資料安全
互斥鎖與join的區別
#不加鎖:并發執行,速度快,資料不安全
from threading import current_thread,Thread,Lock
import os,time
def task():
global n
print('%s is running' %current_thread().getName())
temp=n
time.sleep(0.5)
n=temp-1
if __name__ == '__main__':
n=100
lock=Lock()
threads=[]
start_time=time.time()
for i in range(100):
t=Thread(target=task)
threads.append(t)
t.start()
for t in threads:
t.join()
stop_time=time.time()
print('主:%s n:%s' %(stop_time-start_time,n))
'''
Thread-1 is running
Thread-2 is running
......
Thread-100 is running
主:0.5216062068939209 n:99
'''
#不加鎖:未加鎖部分并發執行,加鎖部分串行執行,速度慢,資料安全
from threading import current_thread,Thread,Lock
import os,time
def task():
#未加鎖的代碼并發運行
time.sleep(3)
print('%s start to run' %current_thread().getName())
global n
#加鎖的代碼串行運行
lock.acquire()
temp=n
time.sleep(0.5)
n=temp-1
lock.release()
if __name__ == '__main__':
n=100
lock=Lock()
threads=[]
start_time=time.time()
for i in range(100):
t=Thread(target=task)
threads.append(t)
t.start()
for t in threads:
t.join()
stop_time=time.time()
print('主:%s n:%s' %(stop_time-start_time,n))
'''
Thread-1 is running
Thread-2 is running
......
Thread-100 is running
主:53.294203758239746 n:0
'''
#有的人可能有疑問:既然加鎖會讓運行變成串行,那么我在start之后立即使用join,就不用加鎖了啊,也是串行的效果啊
#沒錯:在start之后立刻使用jion,肯定會將100個任務的執行變成串行,毫無疑問,最終n的結果也肯定是0,是安全的,但問題是
#start后立即join:任務內的所有代碼都是串行執行的,而加鎖,只是加鎖的部分即修改共享資料的部分是串行的
#單從保證資料安全方面,二者都可以實作,但很明顯是加鎖的效率更高.
from threading import current_thread,Thread,Lock
import os,time
def task():
time.sleep(3)
print('%s start to run' %current_thread().getName())
global n
temp=n
time.sleep(0.5)
n=temp-1
if __name__ == '__main__':
n=100
lock=Lock()
start_time=time.time()
for i in range(100):
t=Thread(target=task)
t.start()
t.join()
stop_time=time.time()
print('主:%s n:%s' %(stop_time-start_time,n))
'''
Thread-1 start to run
Thread-2 start to run
......
Thread-100 start to run
主:350.6937336921692 n:0 #耗時是多么的恐怖
'''
)
死鎖與遞回鎖
行程也有死鎖與遞回鎖,在行程那里忘記說了,放到這里一切說了額
所謂死鎖: 是指兩個或兩個以上的行程或執行緒在執行程序中,因爭奪資源而造成的一種互相等待的現象,若無外力作用,它們都將無法推進下去,此時稱系統處于死鎖狀態或系統產生了死鎖,這些永遠在互相等待的行程稱為死鎖行程,如下就是死鎖
from threading import Lock as Lock
import time
mutexA=Lock()
mutexA.acquire()
mutexA.acquire()
print(123)
mutexA.release()
mutexA.release()
解決方法,遞回鎖,在Python中為了支持在同一執行緒中多次請求同一資源,python提供了可重入鎖RLock,
這個RLock內部維護著一個Lock和一個counter變數,counter記錄了acquire的次數,從而使得資源可以被多次require,直到一個執行緒所有的acquire都被release,其他的執行緒才能獲得資源,上面的例子如果使用RLock代替Lock,則不會發生死鎖:
遞回鎖RLock
from threading import RLock as Lock
import time
mutexA=Lock()
mutexA.acquire()
mutexA.acquire()
print(123)
mutexA.release()
mutexA.release()
典型問題:科學家吃面
import time
from threading import Thread,Lock
noodle_lock = Lock()
fork_lock = Lock()
def eat1(name):
noodle_lock.acquire()
print('%s 搶到了面條'%name)
fork_lock.acquire()
print('%s 搶到了叉子'%name)
print('%s 吃面'%name)
fork_lock.release()
noodle_lock.release()
def eat2(name):
fork_lock.acquire()
print('%s 搶到了叉子' % name)
time.sleep(1)
noodle_lock.acquire()
print('%s 搶到了面條' % name)
print('%s 吃面' % name)
noodle_lock.release()
fork_lock.release()
for name in ['哪吒','egon','yuan']:
t1 = Thread(target=eat1,args=(name,))
t2 = Thread(target=eat2,args=(name,))
t1.start()
t2.start()
遞回鎖解決死鎖問題:
import time
from threading import Thread,RLock
fork_lock = noodle_lock = RLock()
def eat1(name):
noodle_lock.acquire()
print('%s 搶到了面條'%name)
fork_lock.acquire()
print('%s 搶到了叉子'%name)
print('%s 吃面'%name)
fork_lock.release()
noodle_lock.release()
def eat2(name):
fork_lock.acquire()
print('%s 搶到了叉子' % name)
time.sleep(1)
noodle_lock.acquire()
print('%s 搶到了面條' % name)
print('%s 吃面' % name)
noodle_lock.release()
fork_lock.release()
for name in ['哪吒','egon','yuan']:
t1 = Thread(target=eat1,args=(name,))
t2 = Thread(target=eat2,args=(name,))
t1.start()
t2.start()
執行緒佇列
queue佇列 :使用import queue,用法與行程Queue一樣
先進先出:
import queue
q=queue.Queue()
q.put('first')
q.put('second')
q.put('third')
print(q.get())
print(q.get())
print(q.get())
'''
結果(先進先出):
first
second
third
'''
后進先出:
import queue
q=queue.LifoQueue()
q.put('first')
q.put('second')
q.put('third')
print(q.get())
print(q.get())
print(q.get())
'''
結果(后進先出):
third
second
first
'''
存盤資料時可設定優先級的佇列:
import queue
q=queue.PriorityQueue()
#put進入一個元組,元組的第一個元素是優先級(通常是數字,也可以是非數字之間的比較),數字越小優先級越高
q.put((20,'a'))
q.put((10,'b'))
q.put((30,'c'))
print(q.get())
print(q.get())
print(q.get())
'''
結果(數字越小優先級越高,優先級高的優先出隊):
(10, 'b')
(20, 'a')
(30, 'c')
'''
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/412884.html
標籤:Python