博客主頁(4條訊息) 小吳_小吳有想法_CSDN博客-筆記,java,leetcode領域博主
歡迎關注
點贊
收藏和留言
天道酬勤,勤能補拙,和小吳一起加油吧
17歲大一新生,水平有限,懇請各位大佬指點,不勝感激!
- 🍊這里有一點路線小伙伴可以參考一下哈(4條訊息) JAVA實作客戶資訊管理系統以及給大一寒假學生的建議_小吳-CSDN博客
- 參考書籍《演算法4》,學習視頻:黑馬程式員Java資料結構與演算法黑馬程式員Java資料結構與java演算法,全網資料最全資料結構+演算法教程,154張java資料結構圖_嗶哩嗶哩_bilibili 尚硅谷Java資料結構與java演算法(Java資料結構與演算法)_嗶哩嗶哩_bilibili
目錄
冒泡排序(Bubble Sort )
圖解
代碼實作
時間復雜度分析
選擇排序
圖解
代碼實作
時間復雜度分析
插入排序
圖解
代碼實作
時間復雜度分析
希爾排序
圖解
代碼實作
時間復雜度的探討筆記
歸并排序
圖解
代碼實作
時間復雜度分析
快速排序
圖解
代碼實作
時間復雜度分析
基數排序
圖解
?
代碼實作
時間復雜度分析
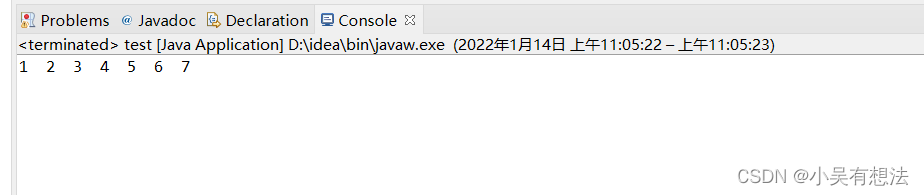
冒泡排序(Bubble Sort )
排序前:{3,4,5,6,7,2,1}
排序后:{1,2,3,4,5,6,7}
圖解

原理:
- 比較相鄰的元素,如果前一個元素比后一個元素大,就交換這兩個元素的位置
- 對每一對相鄰的元素做同樣的作業,從開始第一對元素到結尾的最后一對元素,最終最后位置的元素就是最大值
代碼實作
public static void main(String[] args)
{
int t=0;
int[] a= {3,4,5,6,7,2,1};
for(int i=0;i<a.length-1;i++)
{
for(int j=0;j<a.length-i-1;j++)
{
if(a[j]>a[j+1])
{
t=a[j];
a[j]=a[j+1];
a[j+1]=t;
}
}
}
for(int i=0;i<a.length;i++)
{
System.out.print(a[i]+" ");
}
}
時間復雜度分析
分析內回圈體的執行次數,在最壞的情況下,也就是加入要排序的元素為{7,6,5,4,3,2,1}逆序,那么:
- 元素的比較次數為:(N-1)+(N-2)+(N-3)+...+2+1=N^2/2-N/2;
- 元素的交換次數為:(N-1)+(N-2)+(N-3)+...+2+1=N^2/2-N/2;
- 總執行次數為:N^2-N;
- 故時間復雜度為O(N^2);
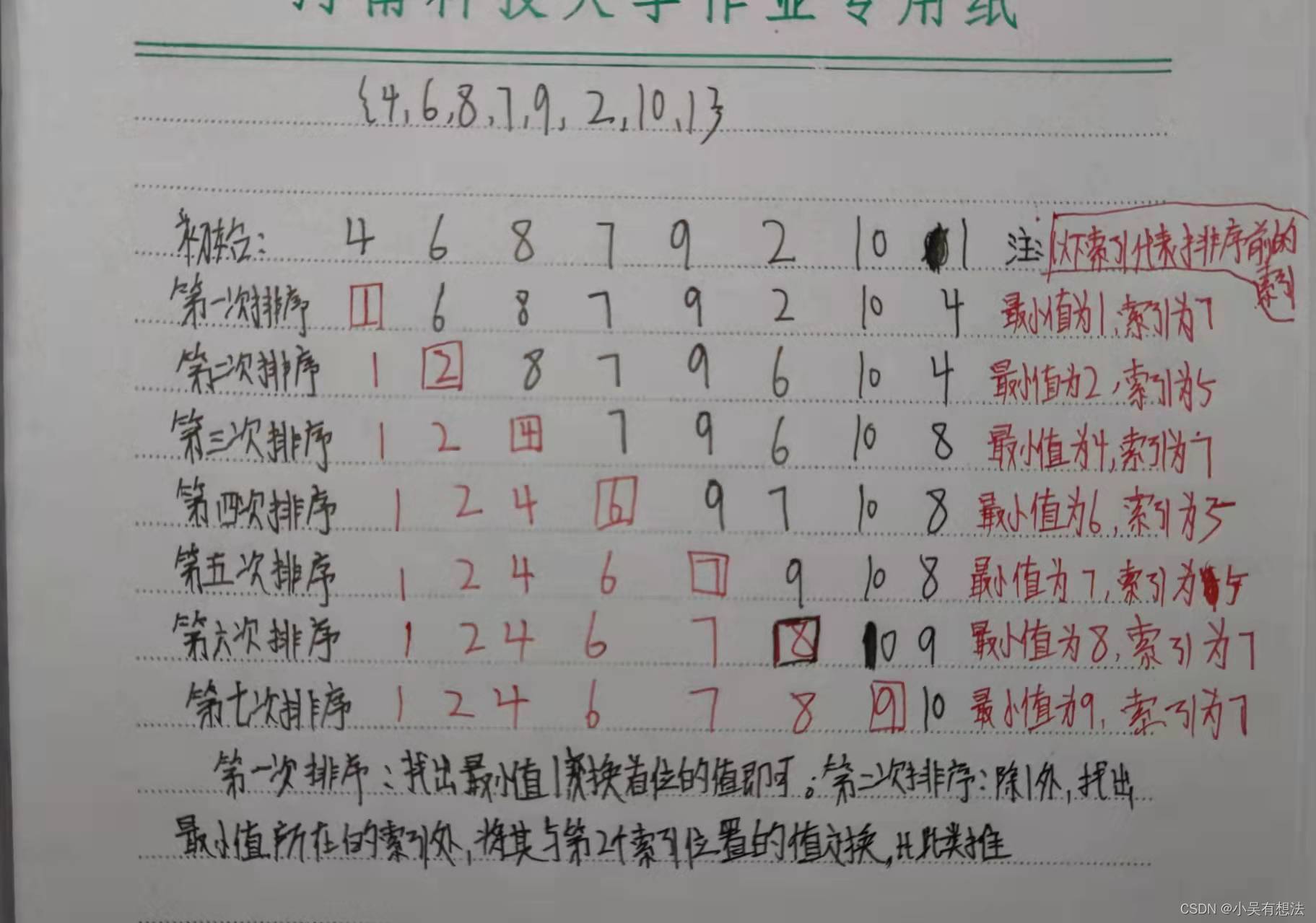
選擇排序
排序前:{4,6,8,7,9,2,10,1}
排序后:{1,2,4,6,7,8,9,10}
圖解
原理:
- 每一次遍歷程序中,都假定第一個索引處的元素是最小值,和其他索引處的值依次進行比較,如果當前索引處的值大于其他某個索引處的值,則假定其他某個索引處的值為最小值,最后可以找到最小值所在的索引
- 交換第一個索引處和最小值所在索引處的值
代碼實作
import java.util.Arrays;
public class test{
//對陣列a中的元素進行排序
public static void sort(Comparable [] a)
{
for(int i=0;i<a.length-1;i++)
{
int min=i;//定義一個變數,記錄最小元素所在位置的索引,默認為參與選擇排序的第一個元素所在的位置
for(int j=i+1;j<a.length;j++)//從已經選擇出來了的數后面開始挑選
{
if(greater(a[min],a[j]))//需要比較最小元素索引min處的值和j索引處的值
{
min=j;
}
exch(a,i,min);
}
}
}
private static boolean greater(Comparable a,Comparable b)//比較a元素是否大于b元素
{
return a.compareTo(b)>0;
}
private static void exch(Comparable[] a,int i,int j)//陣列元素i和j交換位置
{
Comparable t;
t=a[i];
a[i]=a[j];
a[j]=t;
}
public static void main(String[] args)
{
Integer []a= {4,6,8,7,9,2,10,1};
test.sort(a);
System.out.print(Arrays.toString(a));
}
}

時間復雜度分析
元素的比較次數為:(N-1)+(N-2)+(N-3)+...+2+1=N^2/2-N/2;
資料的交換次數為:N-1(最外層的for回圈執行幾次,就發生幾次交換);
總執行次數:N^2/2+N/2-1;
時間復雜度:O(N^2);
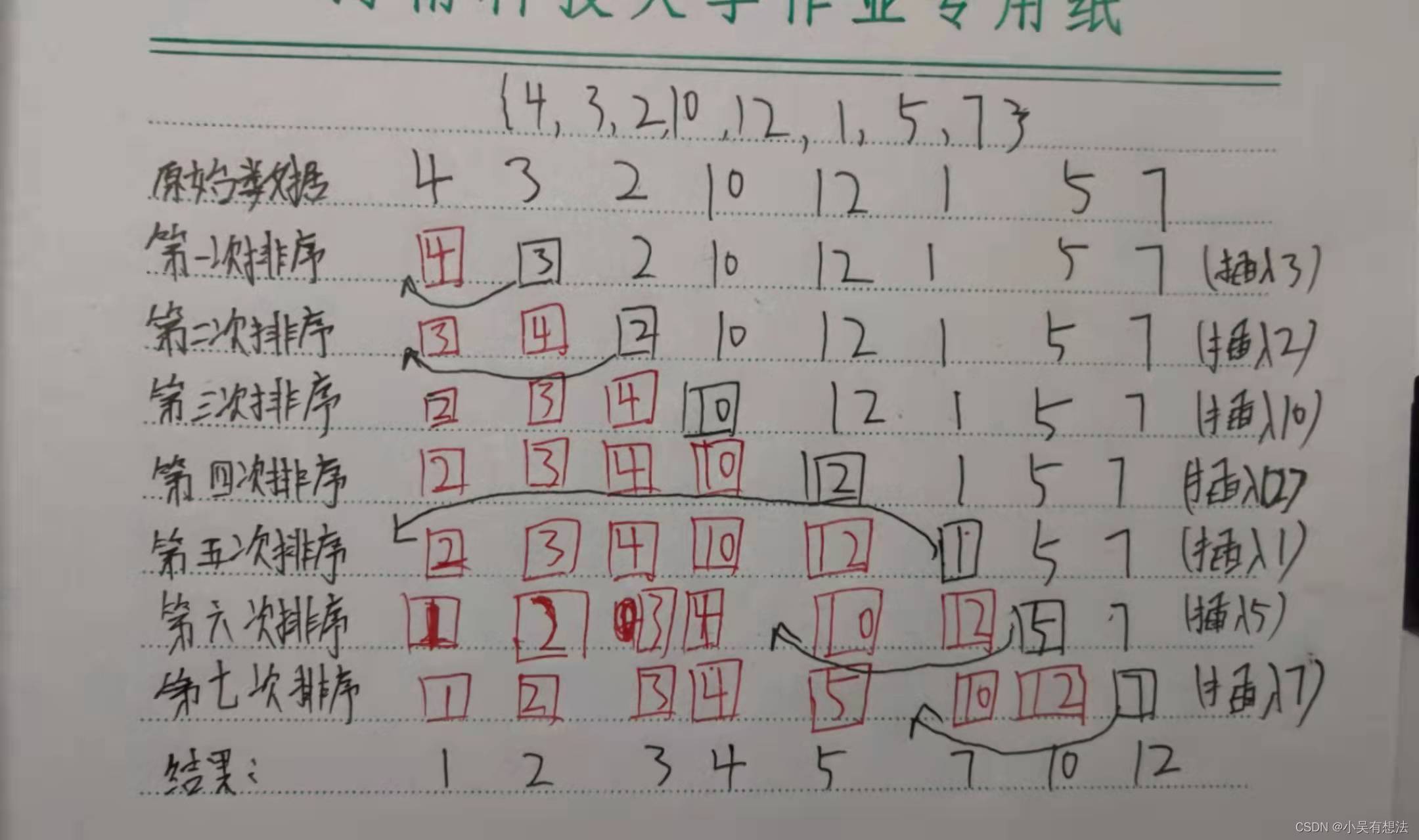
插入排序
排序前:{4,3,2,10,12,1,5,7}
排序后:{1,2,3,4,5,7,10,12}
圖解
原理:
- 把所有的元素分為兩組,已經排序的和未排序的
- 找到未排序組中的第一個元素,向已經排序的組中插入
- 倒敘遍歷已經排序的元素,依次和待插入的元素進行比較,直到找到一個元素小于等于待插入元素,那么就把待插入元素放到這個位置,其他的元素向后移動一位
代碼實作
import java.util.Arrays;
public class test{
//對陣列a中的元素進行排序
public static void sort(Comparable [] a)
{
for(int i=1;i<a.length;i++)
{
for(int j=i;j>0;j--)//比較索引j處的值和j-1處的值,如果索引j-1處的值比索引j處的值大,則交換資料
//如果不大的話,退出回圈即可
{
if(greater(a[j-1],a[j]))
{
exch(a,j-1,j);
}else
break;
}
}
}
private static boolean greater(Comparable a,Comparable b)//比較a元素是否大于b元素
{
return a.compareTo(b)>0;
}
private static void exch(Comparable[] a,int i,int j)//陣列元素i和j交換位置
{
Comparable t;
t=a[i];
a[i]=a[j];
a[j]=t;
}
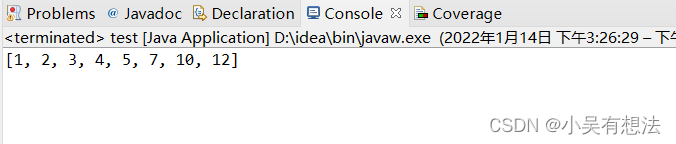
public static void main(String[] args)
{
Integer []a= {4,6,8,7,9,2,10,1};
test.sort(a);
System.out.print(Arrays.toString(a));
}
}
時間復雜度分析
分析內回圈體的執行次數,在最壞的情況下,也就是待排序的元素為{12,10,7,5,4,3,2,1},那么:
- 比較次數為:(N-1)+(N-2)+(N-3)+...+2+1=N^2/2-N/2;
- 交換次數為:(N-1)+(N-2)+(N-3)+...+2+1=N^2/2-N/2;
- 總執行次數:N^2-N;
- 故時間復雜度為:O(N^2);
希爾排序
《演算法4》:
對于大規模亂序陣列插入排序很慢,因為它只會交換相鄰的元素,因此元素只能一點一點地從陣列的一端移動到另一端,例如,如果主鍵最小的元素正好在陣列的盡頭,要講它挪到正確的位置就需要N-1次移動,希爾排序為了加快速度簡單地改進了插入排序,交換不相鄰的元素以對陣列的區域進行排序,并最終用插入排序將區域有序的陣列排序
希爾排序的思想是使陣列中任意間隔為h的元素都是有序的,這樣的陣列被稱為h有序陣列,換句話說,一個h有序陣列就是h個互相獨立的有序陣列編織在一起組成的一個陣列,在進行排序時,如果h很大,我們就能將元素移動到很遠的地方,為實作更小的h有序陣列創造方便,用這種方式,對于任意以1結尾的h序列,我們都能夠進行陣列排序,這就是希爾排序

排序前:{9,1,2,5,7,4,8,6,3,4}
排序后:{1,2,3,4,4,5,6,7,8,9}
圖解
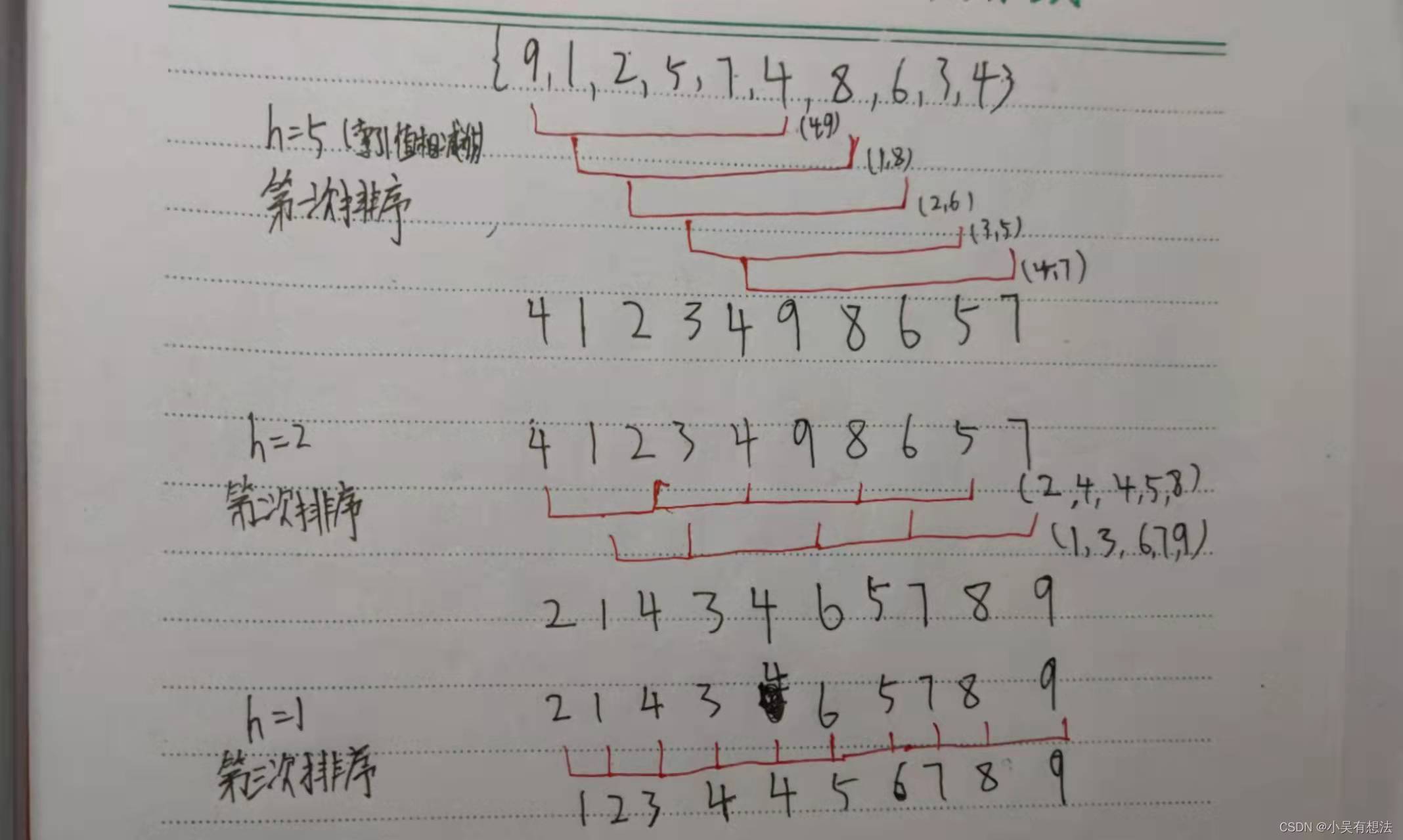
原理:
- 選定一個增長量h,按照增長量h作為資料分組的依據,對資料進行分組;
- 對分好組的每一組資料完成插入排序;
- 減小增長量,最小減為1,重復第二部步操作
代碼實作
import java.util.Arrays;
public class test{
//對陣列a中的元素進行排序
public static void sort(Comparable [] a)
{
int N=a.length;
int h=1;
//確定增長量h的最大值
while(h<N/2)
{
h=h*2+1;
}
while(h>=1)//當增長量h小于1,排序結束
{
//1.找到待插入的元素
for(int i=h;i<N;i++)
{
//2.將待插入的元素插入到有序陣列中
for(int j=i;j>=h;j-=h)
{ //待插入的元素是a[j],比較a[j]和它前面的a[j-h]
if(greater(a[j-h],a[j]))//如果a[j-h]大,交換元素
{
exch(a,j-h,j);//因為前面都插入排序好了,只需要比較a[j]前面的那個a[j-h]即可咯
}
else
{
break;//說明待插入元素已經找到了合適的位置,結束回圈
}
}
}
h=h/2;//減小h的值
}
}
private static boolean greater(Comparable a,Comparable b)//比較a元素是否大于b元素
{
return a.compareTo(b)>0;
}
private static void exch(Comparable[] a,int i,int j)//陣列元素i和j交換位置
{
Comparable t;
t=a[i];
a[i]=a[j];
a[j]=t;
}
public static void main(String[] args)
{
Integer []a= {9,1,2,5,7,4,8,6,3,4};
test.sort(a);
System.out.print(Arrays.toString(a));
}
}
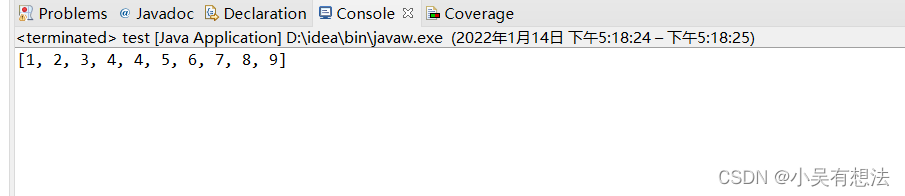
時間復雜度的探討筆記
希爾排序中增長量h并沒有固定的規則,研究希爾排序性能需要的數學論證也超出了我使用的《演算法4》這本書的范圍,對于中等大小的陣列它的運行時間是可以接受的,它的代碼量很小,且不需要使用額外的記憶體空間,如果需要解決一個排序問題而又沒有系統排序函式可用,可用先用希爾排序,然后再考慮是否值得將它替換為更加復雜的排序演算法,
歸并排序
遞回排序演算法:歸并排序,要將一個陣列排序,可以先(遞回地)將它分成兩半分別排序,然后將結果歸并起來,歸并排序能夠保證將任意長度為N的陣列排序所需時間和NlogN成正比;它的主要缺點則是它所需的額外空間和N成正比,
排序前:{7,4,5,8,1,3,6,2}
排序后:{1,2,3,4,5,6,7,8}
圖解
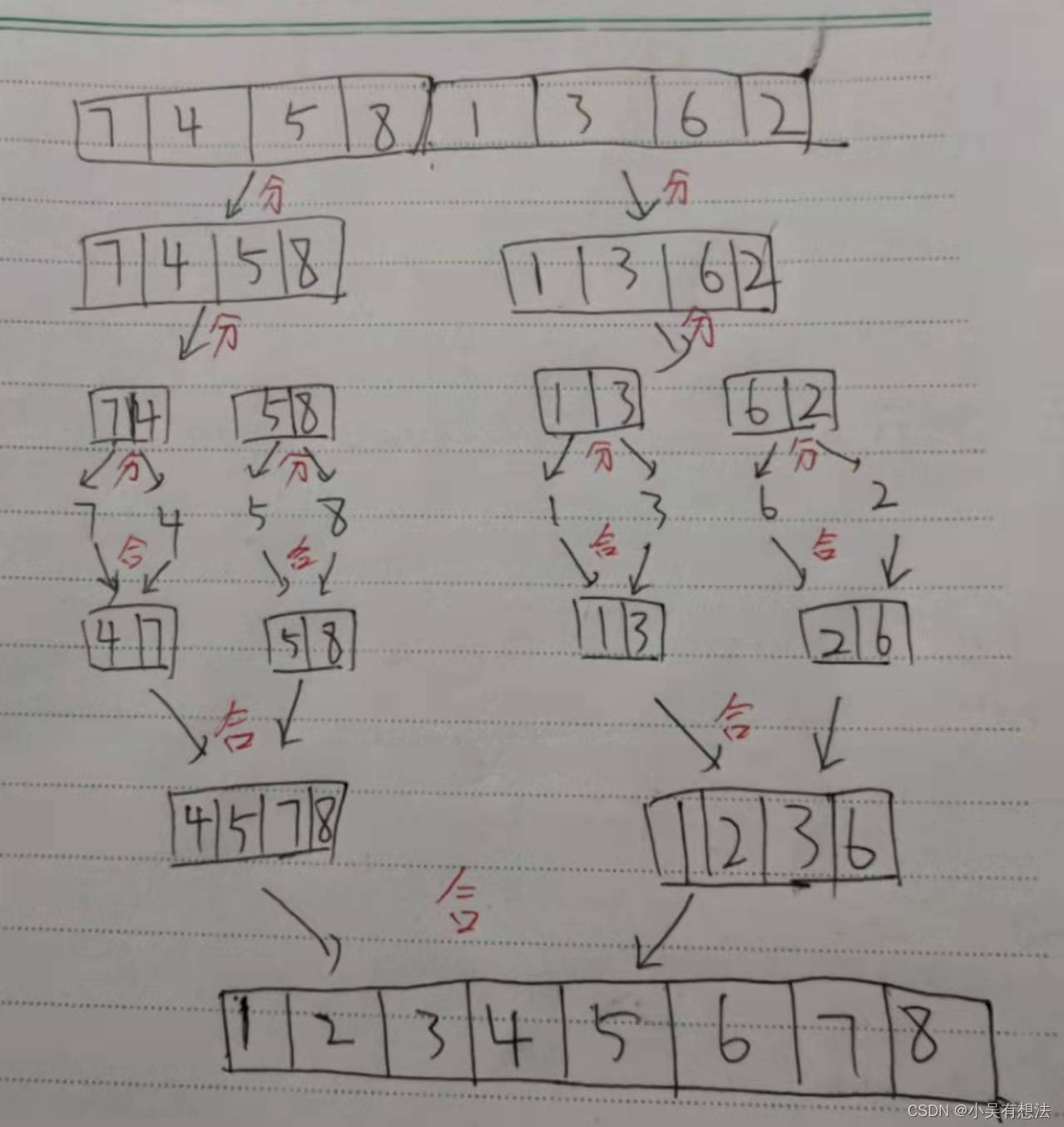
原理:
- 盡可能一組資料拆分成兩個元素相等的子組,并對每一個子組繼續拆分,直到拆分后的每個子組的元素個數都是1為止
- 將相鄰的兩個子組進行合并成一個有序的大組
- 不斷的重復步驟2,直到最終只有一個組為止
代碼實作
import java.util.Arrays;
public class test{
//歸并所需要的輔助陣列
private static Comparable[] assist;
//對陣列a中的元素進行排序
public static void sort(Comparable [] a)
{
//1.初始化輔助陣列assist
assist=new Comparable[a.length];
//2.定義一個lo變數和一個hi變數,分別記錄陣列中的最小索引和最大索引
int lo=0;
int hi=a.length-1;
//3.呼叫sort多載方法完成陣列a中,從索引lo到索引hi的元素的排序
sort(a,lo,hi);
}
public static void merge(Comparable[] a,int lo,int mid,int hi)
{
//定義三個指標
int i=lo;
int p1=lo;
int p2=mid+1;
//遍歷,移動p1指標和p2指標,比較對應索引處的值,找出小的那個,放到輔助陣列對應索引位置
while(p1<=mid&&p2<=hi)
{//比較對應索引處的值
if(greater(a[p1],a[p2]))
{
assist[i++]=a[p1++];
}else
{
assist[i++]=a[p2++];
}
}
//遍歷,如果p1的指標沒有走完,那么順序移動p1指標,把對應的元素放到輔助陣列的對應索引處
while(p1<=mid)
{
assist[i++]=a[p1++];
}
//遍歷,如果p2的指標沒有走完,那么順序移動p2指標,把對應的元素放到輔助陣列的對應索引處
while(p2<=hi)
{
assist[i++]=a[p2++];
}
//把輔助陣列中的元素拷貝到原陣列中
for(int m=lo;m<=hi;m++)
{
a[m]=assist[m];
}
}
public static void sort(Comparable[] a,int lo,int hi)
{
if(hi<=lo)
{
return;//安全檢驗
}
//從lo到hi之間的資料分為2個陣列
int mid=lo+(hi-lo)/2;
//分別對每一組資料進行排序
sort(a,lo,mid);
sort(a,mid+1,hi);
//再把兩個陣列進行歸并
merge(a,lo,mid,hi); //遞回,分而治之,當遞回到只有一個元素的時候,終止遞回
}
private static boolean greater(Comparable a,Comparable b)//比較a元素是否大于b元素
{
return a.compareTo(b)<0;
}
private static void exch(Comparable[] a,int i,int j)//陣列元素i和j交換位置
{
Comparable t;
t=a[i];
a[i]=a[j];
a[j]=t;
}
public static void main(String[] args)
{
Integer []a= {7, 4, 5, 8, 1, 3, 6, 2};
test.sort(a);
System.out.print(Arrays.toString(a));
}
}
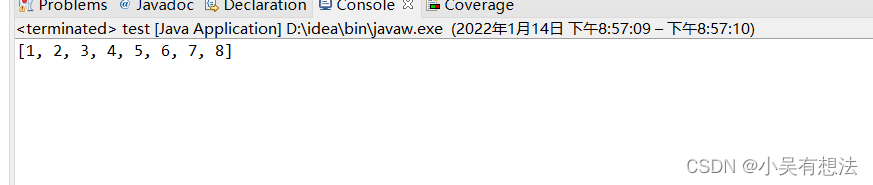
時間復雜度分析
設資料規模大小為N,運行時間為T(N),當把N分為兩半,則處理大小為N/2的子陣列花費時間為T(N/2),合并花費時間與資料規模成正比:N,所以T(N)=2*T(N/2)+N
最終得時間復雜度為O(NlogN)
快速排序
快速排序是一種分治的排序演算法,它將一個陣列分成兩個子陣列,將兩部分獨立地排序,快速排序和歸并排序是互補的:歸并排序將陣列分成兩個子陣列分別排序,并將有序的子陣列歸并以將整個陣列排序;而快速排序將陣列排序的方式則是當兩個子陣列都有序時整個陣列也就自然you
排序前:{6,1,2,7,9,3,4,5,8}
排序后:{1,2,3,4,5,6,7,8,9}
圖解
原理:
- 首先設定一個分界值,通過分界值將陣列分成左右兩部分
- 將大于或等于分界值的資料放到陣列的右邊,小于分界值的資料放到陣列的左邊,此時左邊部分中各元素都小于或等于分界值,而右邊部分中各元素都大于或等于分界值
- 然后,左邊和右邊的資料可以獨立排序,對于左側的陣列資料,又可以取一個分界值,將該部分資料分成左右兩部分,同樣在左邊放置較小值,右邊放置較大值,右側的陣列資料也可以做類似處理
- 重復上述程序,可以看出,這是一個遞回定義,通過遞回將左側部分排序好后,再遞回排好右側部分的順序,當左側和右側兩個部分的資料排完序后,整個陣列的排序也就完成了


代碼實作
import java.util.Arrays;
public class test{
//對陣列a中的元素進行排序
public static void sort(Comparable [] a)
{
//定義一個lo變數和一個hi變數,分別記錄陣列中的最小索引和最大索引
int lo=0;
int hi=a.length-1;
//呼叫sort方法完成陣列a中,從索引lo到索引hi的元素的排序
sort(a,lo,hi);
}
//對陣列a中,從索引lo到索引hi之間的元素進行分組,并回傳分組界限對應的索引
public static int partition(Comparable[] a,int lo,int hi)
{
//確定分界值
Comparable key=a[lo];
//定義兩個指標,分別指向待切分元素的最小索引處和最大索引處的下一個位置
int left=lo;
int right=hi+1;
//切分
while(true) {
//先從右往左掃描,移動rigth指標,找到一個比分界值小的元素,停止
while(greater(key,a[--right]))
{
if(right==lo)//右指標掃描到最左邊了
{
break;
}
}
//再從左往右掃描,移動left指標,找到一個比分界值大的元素,停止
while(greater(a[++left],key))
{
if(left==hi)//掃描到最右邊了
{
break;
}
}
//判斷left>=right,如果是,則證明元素掃描完畢,結束回圈,如果不是,則交換元素即可
if(left>=right)//掃描完畢,結束掃描
{
break;
}else
{
exch(a,left,right);
}
}
exch(a,lo,right);//
return right;
}
//對陣列a中從索引lo到索引hi之間的元素進行排序
public static void sort(Comparable[] a,int lo,int hi)
{
if(hi<=lo)
{
return ;
}
//需要對陣列中lo索引到hi索引處的元素進行分組(左子組和右子組)
int partition=partition(a,lo,hi);//回傳的是分組的分界值所在的索引,分界值位置變換后的索引
//讓左子組有序
sort(a,lo,partition-1);//結束索引為分界值前一個索引
//讓右子組有序
sort(a,partition+1,hi);//起始索引為分界值后一個索引
}
private static boolean greater(Comparable a,Comparable b)//比較a元素是否大于b元素
{
return a.compareTo(b)<0;
}
private static void exch(Comparable[] a,int i,int j)//陣列元素i和j交換位置
{
Comparable t;
t=a[i];
a[i]=a[j];
a[j]=t;
}
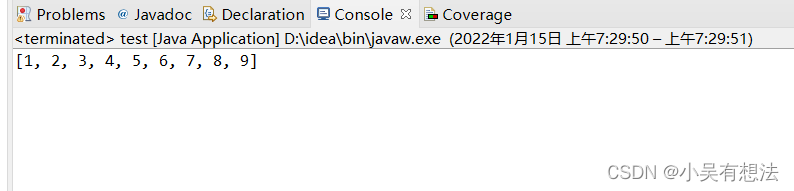
public static void main(String[] args)
{
Integer []a= {6,1,2,7,9,3,4,5,8};
test.sort(a);
System.out.print(Arrays.toString(a));
}
}
時間復雜度分析
快速排序的一次切分從兩頭開始交替搜索,直到left和right重合,因此,一次切分演算法的時間復雜度為O(N),但整個快速排序的時間復雜度和切分的次數相關
最優情況:每一次切分選擇的基本數字剛好將當前序列等分,時間復雜度為O(NlogN)
最壞情況:每一次切分選擇的基準數字是當前序列中的最大數或最小數,這使得每一次切分都會有一個子組,那么總共就得切分N次,所以最壞情況下時間復雜度是O(N^2)
平均情況下的時間復雜度:O(NlogN)
基數排序
通過鍵值的各個位的值,將要排序的元素分配至某些桶中,達到排序的作用,
基數排序是效率高的穩定性排序演算法,是桶排序的擴展,
圖解


代碼實作
這時1,2,3輪分開寫的情況,我們可以發現規律,第一輪是a[i]/1%10,第二輪是a[i]/10%10,第三輪是a[i]/100%10
import java.util.Arrays;
public class test{
//對陣列a中的元素進行排序
//第一輪處理個位
public static void sort(int [] a)
{
//定義一個二維陣列,每個桶就是一個一維陣列
int [][] arr= new int [10][a.length];//為了防止放置資料的時候資料溢位,用a.length,前面那個10代表0——9,10個一位陣列
//記錄每個桶中實際存放了多少個資料,我們定義一個一維陣列來記錄各個桶的每次放入的資料個數
int [] b=new int[10];//記錄10個桶
//第一步(針對元素的個位數進行處理)
for(int i=0;i<a.length;i++)
{
int n=a[i]%10;
//放入到對應的桶中
arr[n][b[n]]=a[i];
b[n]++;//代表這個桶里的資料增加了
}
//按照這個桶的順序(一維陣列的下標以此取出資料,放入原來陣列)
int index=0;
//遍歷每一桶,并將桶中的資料放入到原陣列
for(int j=0;j<b.length;j++)
{
//如果桶中有資料
if(b[j]!=0)//回圈該桶,即下標為j的一維陣列
{
for(int m=0;m<b[j];m++)
{
a[index++]=arr[j][m];
}
}
//第一輪處理后,需要將原來代表桶里的資料個數的值清0,否則會影響下一輪
b[j]=0;
}
//第二輪,處理十位數
for(int i=0;i<a.length;i++)
{
int n=a[i]/10%10;
//放入到對應的桶中
arr[n][b[n]]=a[i];
b[n]++;//代表這個桶里的資料增加了
}
//按照這個桶的順序(一維陣列的下標以此取出資料,放入原來陣列)
index=0;
//遍歷每一桶,并將桶中的資料放入到原陣列
for(int j=0;j<b.length;j++)
{
//如果桶中有資料
if(b[j]!=0)//回圈該桶,即下標為j的一維陣列
{
for(int m=0;m<b[j];m++)
{
a[index++]=arr[j][m];
}
}
b[j]=0;
}
//第三輪,處理百位數
for(int i=0;i<a.length;i++)
{
int n=a[i]/100%10;
//放入到對應的桶中
arr[n][b[n]]=a[i];
b[n]++;//代表這個桶里的資料增加了
}
//按照這個桶的順序(一維陣列的下標以此取出資料,放入原來陣列)
index=0;
//遍歷每一桶,并將桶中的資料放入到原陣列
for(int j=0;j<b.length;j++)
{
//如果桶中有資料
if(b[j]!=0)//回圈該桶,即下標為j的一維陣列
{
for(int m=0;m<b[j];m++)
{
a[index++]=arr[j][m];
}
}
}
}
public static void main(String[] args)
{
int []a= {53,3,542,748,14,214};
test.sort(a);
System.out.print(Arrays.toString(a));
}
}

所以通過以上的展示我們可以總結規律去處理,找出陣列中的最大值的位數去處理
最終代碼,可以先理解上一段代碼再得出結論,總結,處理起來就方便多了
import java.util.Arrays;
public class test{
//對陣列a中的元素進行排序
//第一輪處理個位
public static void sort(int [] a)
{
//找出最大數的位數
int max=a[0];
for(int i=0;i<a.length;i++)
{
if(a[i]>max)
{
max=a[i];
}
}
int maxlength =(max+"").length();
//定義一個二維陣列,每個桶就是一個一維陣列
int [][] arr= new int [10][a.length];//為了防止放置資料的時候資料溢位,用a.length,前面那個10代表0——9,10個一位陣列
//記錄每個桶中實際存放了多少個資料,我們定義一個一維陣列來記錄各個桶的每次放入的資料個數
int [] b=new int[10];//記錄10個桶
for(int c=0,f=1;c<maxlength;c++,f*=10)
{
//針對每個元素對應的位進行排序,第一次是個位,第二次是十位,第三次是百位
for(int i=0;i<a.length;i++)
{
//取出每個元素對應位的數
int n=a[i]/f%10;
//放入到對應的桶中
arr[n][b[n]]=a[i];
b[n]++;//代表這個桶里的資料增加了
}
//按照這個桶的順序(一維陣列的下標以此取出資料,放入原來陣列)
int index=0;
//遍歷每一桶,并將桶中的資料放入到原陣列
for(int j=0;j<b.length;j++)
{
//如果桶中有資料
if(b[j]!=0)//回圈該桶,即下標為j的一維陣列
{
for(int m=0;m<b[j];m++)
{
a[index++]=arr[j][m];
}
}
//第一輪處理后,需要將原來代表桶里的資料個數的值清0,否則會影響下一輪
b[j]=0;
}
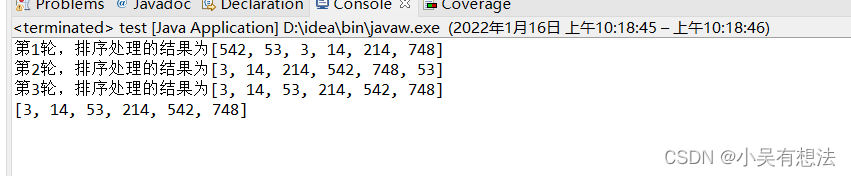
System.out.println("第"+(c+1)+"輪,排序處理的結果為"+Arrays.toString(a));
}
}
public static void main(String[] args)
{
int []a= {53,3,542,748,14,214};
test.sort(a);
System.out.print(Arrays.toString(a));
}
}
時間復雜度分析
基數排序會耗費額外的記憶體空間,當資料過多時,可能出現OutOfMemoryError
如果有負數的陣列,最好不用基數排序
平均時間復雜度:O(n*k) 空間復雜度O(n+k)
學習如逆水行舟,不進則退,和小吳一起加油吧!

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/413403.html
標籤:java