假設我有一個資料框:
df = data.frame(var = c("a", "a", "b", "b", "c", "c", "a", "a", "b", "b", "c", "c", "a", "a", "b", "b", "c", "c"),
source = c("ref", "ref", "ref", "ref", "ref", "ref", "source1", "source1", "source1", "source1", "source1", "source1", "source2", "source2", "source2", "source2", "source2", "source2"),
value = c(2.5, 1, 3.5, 1.6, 2.2, 3.1, 2, 1.2, 1.8, 0.4, 1.4, 1.3, 3, 2.8, 4, 3.6, 2.9, 3.8))
> df
var source value
1 a ref 2.5
2 a ref 1.0
3 b ref 3.5
4 b ref 1.6
5 c ref 2.2
6 c ref 3.1
7 a source1 2.0
8 a source1 1.2
9 b source1 1.8
10 b source1 0.4
11 c source1 1.4
12 c source1 1.3
13 a source2 3.0
14 a source2 2.8
15 b source2 4.0
16 b source2 3.6
17 c source2 2.9
18 c source2 3.8
我想value為每個var/source對生成密度圖。這適用于:
library(tidyverse)
library(ggplot2)
df %>%
ggplot(aes(x = value))
geom_density(aes(y = ..density.., fill = source), adjust = 1, alpha = 0.5)
facet_grid(source ~ var, scales = "fixed")
theme_bw()
生產:
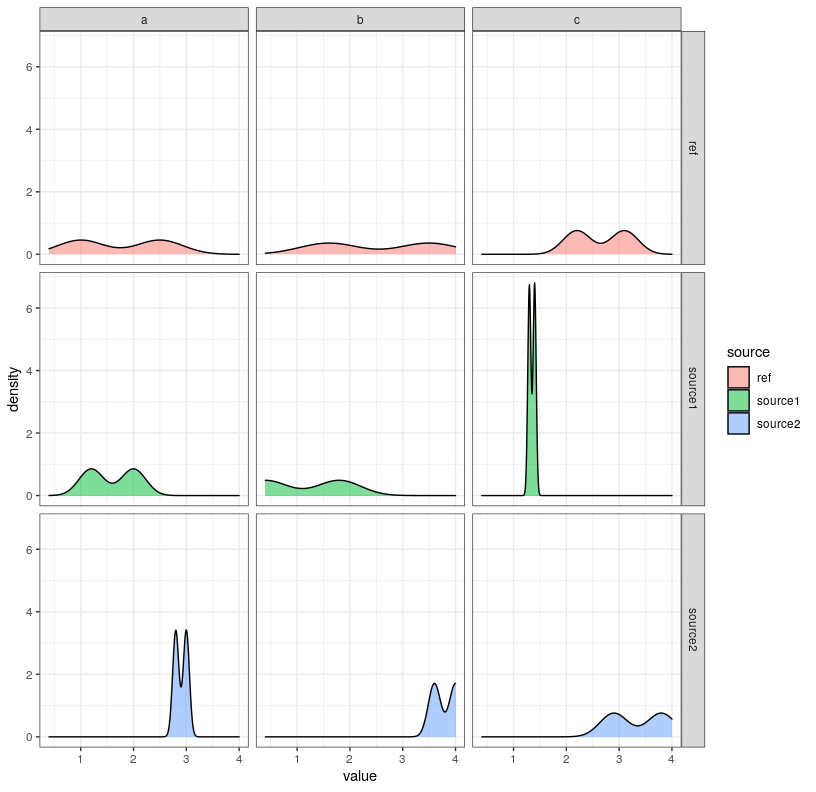
但是,基于這個例子,我真正想要的是只有兩行,對應于source1并source2根據來自的值在每個圖中添加另一條密度曲線ref。
我試圖在這篇文章之后找到解決方案,但沒有成功。換句話說,我希望網格中的每個圖都將值的分布ref作為參考,并且在圖例中不考慮該ref組。
非常感謝任何幫助。謝謝你。
uj5u.com熱心網友回復:
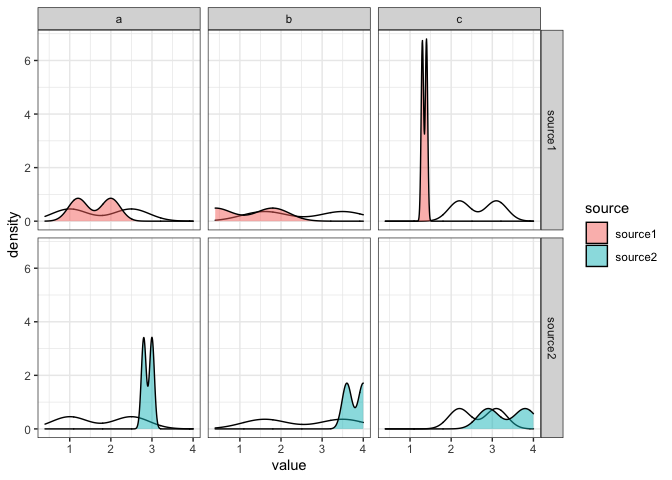
一種選擇是將您的資料框一分為二,一個包含參考值,一個包含其他值。對于包含參考值的 df,我們還必須洗掉該source列。然后利用兩個geom_density. 從圖例中洗掉參考并不是什么大問題。只需洗掉填充 aes 并設定所需的填充顏色(如果有)作為引數。在下面的代碼中,我簡單地設定了fill=NA.
library(ggplot2)
df1 <- df[df$source == "ref", -2]
df2 <- df[!df$source == "ref", ]
ggplot(mapping = aes(x = value))
geom_density(data = df1, aes(y = ..density..), fill = NA, adjust = 1, alpha = 0.5)
geom_density(data = df2, aes(y = ..density.., fill = source), adjust = 1, alpha = 0.5)
facet_grid(source ~ var, scales = "fixed")
theme_bw()
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/414680.html
標籤:
上一篇:命名的R-chunk不能被參考