下面列出了所有集合的類圖:
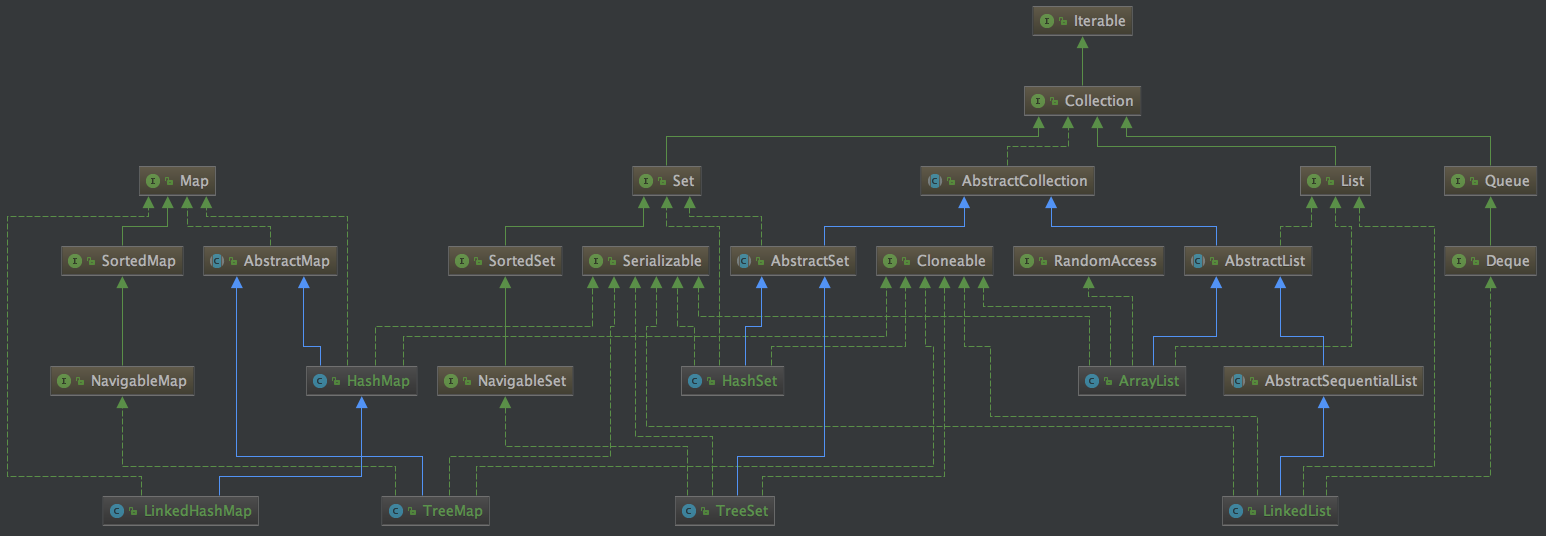
- 每個介面做的事情非常明確,比如 Serializable,只負責序列化,Cloneable 只負責拷貝,Map 只負責定義 Map 的介面,整個圖看起來雖然介面眾多,但職責都很清晰;
- 復雜功能通過介面的繼承來實作,比如 ArrayList 通過實作了 Serializable、Cloneable、RandomAccess、AbstractList、List 等介面,從而擁有了序列化、拷貝、對陣列各種操作定義等各種功能;
- 上述類圖只能看見繼承的關系,組合的關系還看不出來,比如說 Set 組合封裝 Map 的底層能力等,
上述設計的最大好處是,每個介面能力職責單一,眾多的介面變成了介面能力的積累,假設我們想再實作一個資料結構類,我們就可以從這些已有的能力介面中,挑選出能滿足需求的能力介面,進行一些簡單的組裝,從而加快開發速度,
這種思想在平時的作業中也經常被使用,我們會把一些通用的代碼塊抽象出來,沉淀成代碼塊池,碰到不同的場景的時候,我們就從代碼塊池中,把我們需要的代碼塊提取出來,進行簡單的編排和組裝,從而實作我們需要的場景功能,
1.迭代器
1.1 Itrable
- 實作了Itrable介面就能進行迭代(遍歷)操作,頂級介面Collection實作了Iterable
- 遍歷的手段有兩種,但需要具體類自行實作
- 迭代器Iterator,可以實作多個Iterator進行多種方法的迭代(前序,后序…)
- forEach方法,一般由具體子類重寫該方法
public interface Iterable<T> {
Iterator<T> iterator()
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
default Spliterator<T> spliterator() {
return Spliterators.spliteratorUnknownSize(iterator(), 0);
}
}
1.1.1 Iterator介面
常由內部類實作,構造方法回傳,一般用于要對集合進行洗掉的情景
- 迭代器是一種設計模式,封裝了對集合的遍歷,使得不用了解集合的內部細節,就可以用同樣的方式遍歷不同的集合
- 迭代器不允許使用集合方法進行集合增刪,但是可以對集合的元素操作(如set()),還可以使用迭代器的remove()
- 不能使用集合的 put 和 remove 方法
- 可用于集合元素屬性的修改:set方法
- remove操作:是Iterator的remove方法
這里特別注意一點,一定要在next()后使用,比如洗掉第一個元素,要先next然后才能remove
public interface Iterator<E> {
// 每次next之前,先呼叫此方法探測是否迭代到終點
boolean hasNext();
// 回傳當前迭代元素 ,同時,迭代游標后移
E next();
/*洗掉最近一次已近迭代出出去的那個元素,
只有當next執行完后,才能呼叫remove函式,
比如你要洗掉第一個元素,不能直接呼叫 remove() 而要先next一下( );
在沒有先呼叫next 就呼叫remove方法是會拋出例外的,
這個和MySQL中的ResultSet很類似
*/
void remove()
{
throw new UnsupportedOperationException("remove");
}
}
- 迭代器的使用:
// iterator是集合的自己Iterator構造方法
Iterator it = list.iterator();
while(it.hasNext) {
it.next();
}
1.1.2 增強for回圈
本質是對Iterator的簡化與封裝,一般用于只遍歷集合的情況
- 增強for回圈:
- 可以用于集合中元素屬性值的修改:set方法
- 但不能對集合新增或者洗掉:modCount控制
- demo:
// ArrayList.forEach()
@Override
public void forEach(Consumer<? super E> action) {
// 判斷非空
Objects.requireNonNull(action);
// modCount的原始值被拷貝
final int expectedModCount = modCount;
final E[] elementData = (E[]) this.elementData;
final int size = this.size;
// 每次回圈都會判斷陣列有沒有被修改,一旦被修改,停止回圈
for (int i=0; modCount == expectedModCount && i < size; i++) {
// 執行回圈內容,action 代表我們要干的事情
action.accept(elementData[i]);
}
// 陣列如果被修改了,拋例外
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
1.1.2 forEach方法
本質是對for回圈的封裝,配合lamada使用,一般用于修改集合物件屬性的情景
// ArrayList.forEach()
@Override
public void forEach(Consumer<? super E> action) {
// 判斷非空
Objects.requireNonNull(action);
// modCount的原始值被拷貝
final int expectedModCount = modCount;
final E[] elementData = (E[]) this.elementData;
final int size = this.size;
// 每次回圈都會判斷陣列有沒有被修改,一旦被修改,停止回圈
for (int i=0; modCount == expectedModCount && i < size; i++) {
// 執行回圈內容,action 代表我們要干的事情
action.accept(elementData[i]);
}
// 陣列如果被修改了,拋例外
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
- 因為在Iterable介面中default修飾,所以必須自身實作而子類不一定要重寫,在jdk8時所有集合都實作了forEach方法
- forEach:
- 修改物件屬性:通過set方法
- 不能進行增刪操作:modCount
- demo:
list.forEach(l -> {
l.setName("zs");
l.setAge(18);
})
2.2 Map的迭代
map并未實作Itrable介面,但仍可進行迭代
-
通過set的Iterator進行迭代
-
最高層Map介面定了forEach方法
1.2.1 Set.iterator
eg. 這里列出 EntrySet & EntryIterator
final class EntrySet extends AbstractSet<Map.Entry<K,V>> {
public final Iterator<Map.Entry<K,V>> iterator() {
return new EntryIterator();
}
}
final class EntryIterator extends HashIterator
implements Iterator<Map.Entry<K,V>> {
public final Map.Entry<K,V> next() { return nextNode(); }
}
使用示例:
Iterator<Map.Entry<String,String>> it = map.entrySet().iterator
while (it.hasNext()) {
Map.Entry<String,String> me = it.next();
// 獲取key
me.getkey();
// 獲取value
me.getValue();
}
1.2.2 Map.forEach
Map中定義的forEach,default修飾,實際上也是呼叫entrySet
default void forEach(BiConsumer<? super K, ? super V> action) {
Objects.requireNonNull(action);
for (Map.Entry<K, V> entry : entrySet()) {
K k;
V v;
try {
k = entry.getKey();
v = entry.getValue();
} catch(IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
action.accept(k, v);
}
}
HashMap的forEach
@Override
public void forEach(BiConsumer<? super K, ? super V> action) {
Node<K,V>[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e.key, e.value);
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
2.批量操作
2.1 批量新增
下面列出 ArrayList.addAll 方法的原始碼:
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
int numNew = a.length;
// 確保容量充足,整個程序只會擴容一次
ensureCapacityInternal(size + numNew);
// 進行陣列的拷貝
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}
我們可以看到,整個批量新增的程序中,只擴容了一次,HashMap 的 putAll 方法也是如此,整個新增程序只會擴容一次,大大縮短了批量新增的時間,提高了性能,
所以當碰到集合批量拷貝,批量新增場景,要提高新增性能的時候 ,就可以從目標集合初始化方面入手,
這里也提醒了我們,在容器初始化的時候,最好能給容器賦上初始值,這樣可以防止在 put 的程序中不斷的擴容,從而縮短時間,上章 HashSet 的原始碼演示了給 HashMap 賦初始值的公式為:取括號內兩者的最大值(期望的值/0.75+1,默認值 16),
使用示例:
在 List 和 Map 大量資料新增的時候,我們不要使用 for 回圈 + add/put 方法新增,這樣子會有很大的擴容成本,我們應該盡量使用 addAll 和 putAll 方法進行新增,下面以 ArrayList 為例寫了一個 demo 如下,演示了兩種方案的性能對比:
@Test
public void testBatchInsert(){
// 準備拷貝資料
ArrayList<Integer> list = new ArrayList<>();
for(int i=0;i<3000000;i++){
list.add(i);
}
// for 回圈 + add
ArrayList<Integer> list2 = new ArrayList<>();
long start1 = System.currentTimeMillis();
for(int i=0;i<list.size();i++){
list2.add(list.get(i));
}
log.info("單個 for 回圈新增 300 w 個,耗時{}",System.currentTimeMillis()-start1);
// 批量新增
ArrayList<Integer> list3 = new ArrayList<>();
long start2 = System.currentTimeMillis();
list3.addAll(list);
log.info("批量新增 300 w 個,耗時{}",System.currentTimeMillis()-start2);
}
最后列印出來的日志為:
16:52:59.865 [main] INFO demo.one.ArrayListDemo - 單個 for 回圈新增 300 w 個,耗時1518
16:52:59.880 [main] INFO demo.one.ArrayListDemo - 批量新增 300 w 個,耗時8
可以看到,批量新增方法性能是單個新增方法性能的 189 倍,主要原因在于批量新增,只會擴容一次,大大縮短了運行時間,而單個新增,每次到達擴容閥值時,都會進行擴容,在整個程序中就會不斷的擴容,浪費了很多時間
2.2 批量洗掉
批量洗掉 ArrayList 提供了 removeAll 的方法,HashMap 沒有提供批量洗掉的方法,我們一起來看下 removeAll 的原始碼實作,是如何提高性能的:
// 批量洗掉,removeAll 方法底層呼叫的是 batchRemove 方法
// complement 引數默認是 false,false 的意思是陣列中不包含 c 中資料的節點往頭移動
// true 意思是陣列中包含 c 中資料的節點往頭移動,這個是根據你要洗掉資料和原陣列大小的比例來決定的
// 如果你要洗掉的資料很多,選擇 false 性能更好,當然 removeAll 方法默認就是 false,
private boolean batchRemove(Collection<?> c, boolean complement) {
final Object[] elementData = this.elementData;
// r 表示當前回圈的位置、w 位置之前都是不需要被洗掉的資料,w 位置之后都是需要被洗掉的資料
int r = 0, w = 0;
boolean modified = false;
try {
// 從 0 位置開始判斷,當前陣列中元素是不是要被洗掉的元素,不是的話移到陣列頭
for (; r < size; r++)
if (c.contains(elementData[r]) == complement)
elementData[w++] = elementData[r];
} finally {
// r 和 size 不等,說明在 try 程序中發生了例外,在 r 處斷開
// 把 r 位置之后的陣列移動到 w 位置之后(r 位置之后的陣列資料都是沒有判斷過的資料,這樣不會影響沒有判斷
// 的資料,判斷過的資料可以被洗掉)
if (r != size) {
System.arraycopy(elementData, r,
elementData, w,
size - r);
w += size - r;
}
// w != size 說明陣列中是有資料需要被洗掉的
// 如果 w、size 相等,說明沒有資料需要被洗掉
if (w != size) {
// w 之后都是需要洗掉的資料,賦值為空,幫助 gc,
for (int i = w; i < size; i++)
elementData[i] = null;
modCount += size - w;
size = w;
modified = true;
}
}
return modified;
}
我們看到 ArrayList 在批量洗掉時,如果程式執行正常,只有一次 for 回圈,如果程式執行例外,才會加一次拷貝,而單個 remove 方法,每次執行的時候都會進行陣列的拷貝(當洗掉的元素正好是陣列最后一個元素時除外),當陣列越大,需要洗掉的資料越多時,批量洗掉的性能會越差,所以在 ArrayList 批量洗掉時,強烈建議使用 removeAll 方法進行洗掉,
3.執行緒安全問題
我們說集合都是非執行緒安全的,這里說的非執行緒安全指的是集合類作為共享變數,被多執行緒讀寫的時候,才是不安全的,如果要實作執行緒安全的集合,在類注釋中,JDK 統一推薦我們使用 Collections.synchronized* 類, Collections 幫我們實作了 List、Set、Map 對應的執行緒安全的方法, 如下圖:
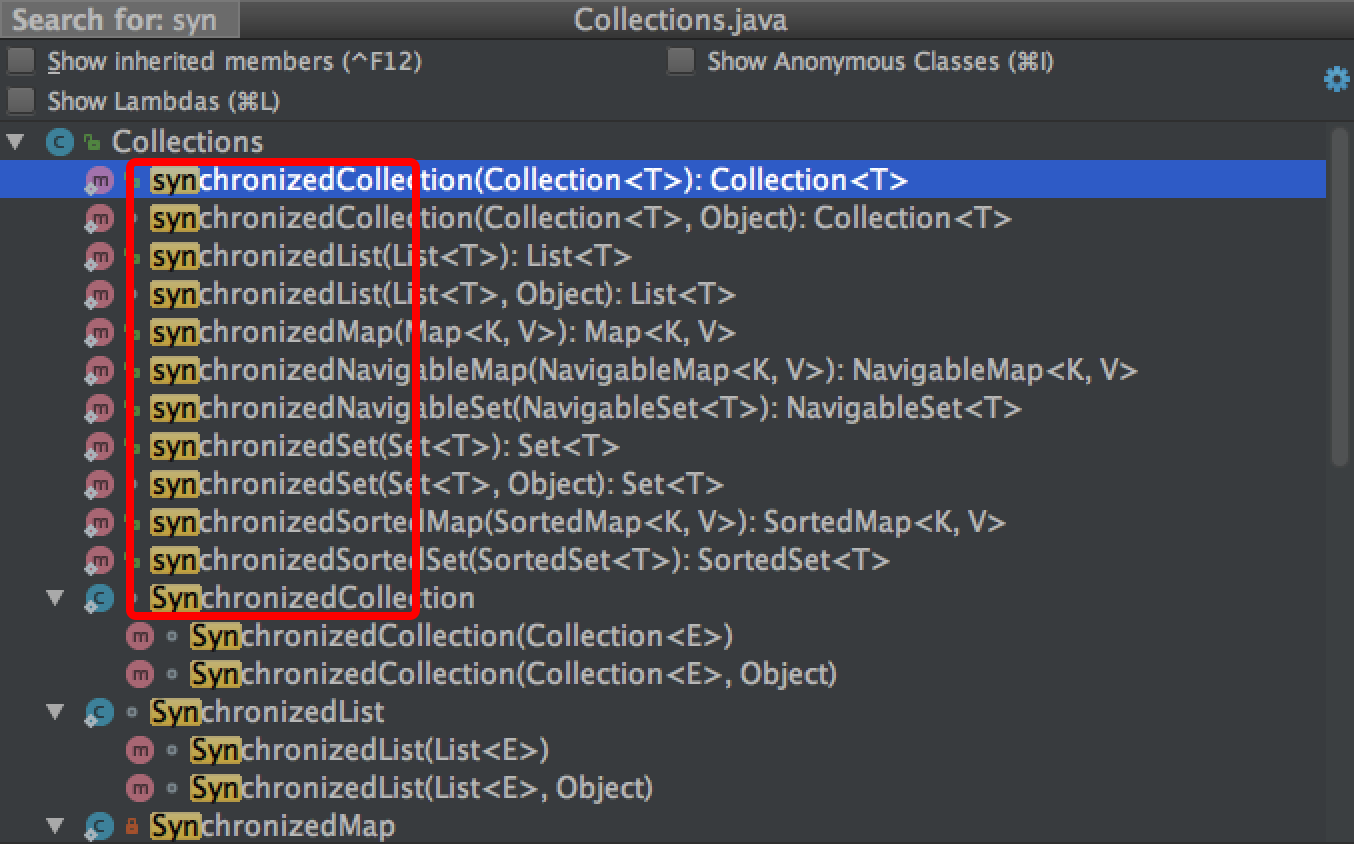
圖中實作了各種集合型別的執行緒安全的方法,我們以 synchronizedList 為例,從原始碼上來看下,Collections 是如何實作執行緒安全的:
// mutex 就是我們需要鎖住的物件
final Object mutex;
// 這些synchronized~~都是Collections的靜態內部類
static class SynchronizedList<E> extends SynchronizedCollection<E> implements List<E> {
private static final long serialVersionUID = -7754090372962971524L;
// 通過組合的方式,傳入需要保證執行緒安全的類(List)
// Collection.synchronizedList(list)
final List<E> list;
SynchronizedList(List<E> list, Object mutex) {
super(list, mutex);
this.list = list;
}
// 我們可以看到,List 的所有操作都使用了 synchronized 關鍵字,來進行加鎖
// synchronized 是一種悲觀鎖,能夠保證同一時刻,只能有一個執行緒能夠獲得鎖
public E get(int index) {
synchronized (mutex) {return list.get(index);}
}
public E set(int index, E element) {
synchronized (mutex) {return list.set(index, element);}
}
public void add(int index, E element) {
synchronized (mutex) {list.add(index, element);}
}
…………
}
從原始碼中我們可以看到 Collections 是通過 synchronized 關鍵字給 List 操作陣列的方法加上鎖,來實作執行緒安全的,
4.兩點注意
在文章的最后,再提出使用集合時的兩點注意:
-
重寫equals & hashcode
當集合的元素是自定義類時,自定義類強制實作 equals 和 hashCode 方法,并且兩個都要實作,因為在集合中,除了 TreeMap 和 TreeSet 是通過比較器比較元素大小外,其余的集合類在判斷索引位置和相等時,都會使用到 equals 和 hashCode 方法,這個在之前的原始碼決議中,我們有說到,所以當集合的元素是自定義類時,我們強烈建議覆寫 equals 和 hashCode 方法,我們可以直接使用 IDEA 工具覆寫這兩個方法,非常方便 -
迭代洗掉
所有集合類,在 for 回圈進行洗掉時,如果直接使用集合類的 remove 方法進行洗掉,都會快速失敗,報 ConcurrentModificationException 的錯誤,所以在任意回圈洗掉的場景下,都建議使用迭代器進行洗掉;
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/41687.html
標籤:java