Mysql高級-day01
MySQL高級課程簡介
| 序號 | Day01 | Day02 | Day03 | Day04 |
|---|---|---|---|---|
| 1 | Linux系統安裝MySQL | 體系結構 | 應用優化 | MySQL 常用工具 |
| 2 | 索引 | 存盤引擎 | 查詢快取優化 | MySQL 日志 |
| 3 | 視圖 | 優化SQL步驟 | 記憶體管理及優化 | MySQL 主從復制 |
| 4 | 存盤程序和函式 | 索引使用 | MySQL鎖問題 | 綜合案例 |
| 5 | 觸發器 | SQL優化 | 常用SQL技巧 |
1. Linux 系統安裝MySQL
1.1 下載Linux 安裝包
https://dev.mysql.com/downloads/mysql/5.7.html#downloads
1.2 安裝MySQL
1). 卸載 centos 中預安裝的 mysql
rpm -qa | grep -i mysql
rpm -e mysql-libs-5.1.71-1.el6.x86_64 --nodeps
2). 上傳 mysql 的安裝包
alt + p -------> put E:/test/MySQL-5.6.22-1.el6.i686.rpm-bundle.tar
3). 解壓 mysql 的安裝包
mkdir mysql
tar -xvf MySQL-5.6.22-1.el6.i686.rpm-bundle.tar -C /root/mysql
4). 安裝依賴包
yum -y install libaio.so.1 libgcc_s.so.1 libstdc++.so.6 libncurses.so.5 --setopt=protected_multilib=false
yum update libstdc++-4.4.7-4.el6.x86_64
5). 安裝 mysql-client
rpm -ivh MySQL-client-5.6.22-1.el6.i686.rpm
6). 安裝 mysql-server
rpm -ivh MySQL-server-5.6.22-1.el6.i686.rpm
1.3 啟動 MySQL 服務
service mysql start
service mysql stop
service mysql status
service mysql restart
1.4 登錄MySQL
mysql 安裝完成之后, 會自動生成一個隨機的密碼, 并且保存在一個密碼檔案中 : /root/.mysql_secret
mysql -u root -p
登錄之后, 修改密碼 :
set password = password('itcast');
授權遠程訪問 :
grant all privileges on *.* to 'root' @'%' identified by 'itcast';
flush privileges;
2. 索引
2.1 索引概述
MySQL官方對索引的定義為:索引(index)是幫助MySQL高效獲取資料的資料結構(有序),在資料之外,資料庫系統還維護者滿足特定查找演算法的資料結構,這些資料結構以某種方式參考(指向)資料, 這樣就可以在這些資料結構上實作高級查找演算法,這種資料結構就是索引,如下面的示意圖所示 :
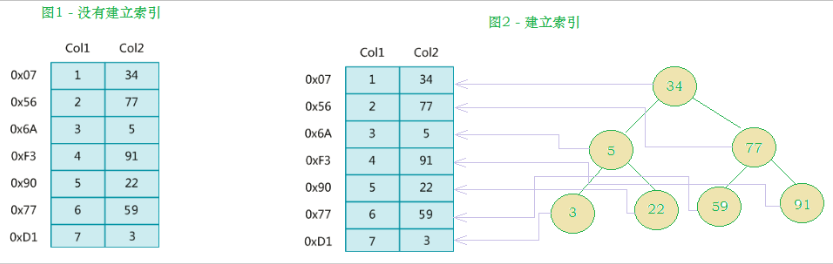
左邊是資料表,一共有兩列七條記錄,最左邊的是資料記錄的物理地址(注意邏輯上相鄰的記錄在磁盤上也并不是一定物理相鄰的),為了加快Col2的查找,可以維護一個右邊所示的二叉查找樹,每個節點分別包含索引鍵值和一個指向對應資料記錄物理地址的指標,這樣就可以運用二叉查找快速獲取到相應資料,
一般來說索引本身也很大,不可能全部存盤在記憶體中,因此索引往往以索引檔案的形式存盤在磁盤上,索引是資料庫中用來提高性能的最常用的工具,
2.2 索引優勢劣勢
優勢
1) 類似于書籍的目錄索引,提高資料檢索的效率,降低資料庫的IO成本,
2) 通過索引列對資料進行排序,降低資料排序的成本,降低CPU的消耗,
劣勢
1) 實際上索引也是一張表,該表中保存了主鍵與索引欄位,并指向物體類的記錄,所以索引列也是要占用空間的,
2) 雖然索引大大提高了查詢效率,同時卻也降低更新表的速度,如對表進行INSERT、UPDATE、DELETE,因為更新表時,MySQL 不僅要保存資料,還要保存一下索引檔案每次更新添加了索引列的欄位,都會調整因為更新所帶來的鍵值變化后的索引資訊,
2.3 索引結構
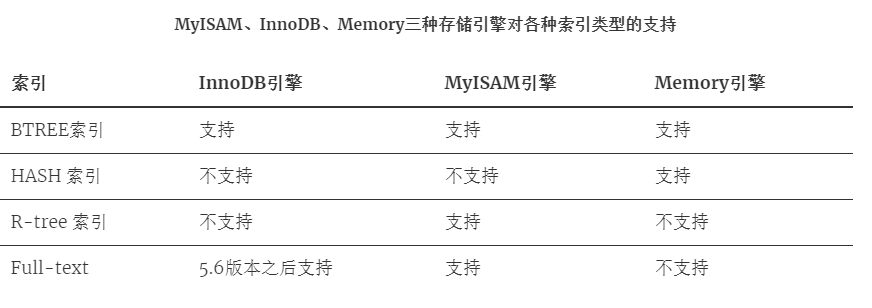
索引是在MySQL的存盤引擎層中實作的,而不是在服務器層實作的,所以每種存盤引擎的索引都不一定完全相同,也不是所有的存盤引擎都支持所有的索引型別的,MySQL目前提供了以下4種索引:
- BTREE 索引 : 最常見的索引型別,大部分索引都支持 B 樹索引,
- HASH 索引:只有Memory引擎支持 , 使用場景簡單 ,
- R-tree 索引(空間索引):空間索引是MyISAM引擎的一個特殊索引型別,主要用于地理空間資料型別,通常使用較少,不做特別介紹,
- Full-text (全文索引) :全文索引也是MyISAM的一個特殊索引型別,主要用于全文索引,InnoDB從Mysql5.6版本開始支持全文索引,
我們平常所說的索引,如果沒有特別指明,都是指B+樹(多路搜索樹,并不一定是二叉的)結構組織的索引,其中聚集索引、復合索引、前綴索引、唯一索引默認都是使用 B+tree 索引,統稱為 索引,
2.3.1 BTREE 結構
BTree又叫多路平衡搜索樹,一顆m叉的BTree特性如下:
- 樹中每個節點最多包含m個孩子,
- 除根節點與葉子節點外,每個節點至少有[ceil(m/2)]個孩子,
- 若根節點不是葉子節點,則至少有兩個孩子,
- 所有的葉子節點都在同一層,
- 每個非葉子節點由n個key與n+1個指標組成,其中[ceil(m/2)-1] <= n <= m-1
以5叉BTree為例,key的數量:公式推導[ceil(m/2)-1] <= n <= m-1,所以 2 <= n <=4 ,當n>4時,中間節點分裂到父節點,兩邊節點分裂,
插入 C N G A H E K Q M F W L T Z D P R X Y S 資料為例,
演變程序如下:
1). 插入前4個字母 C N G A
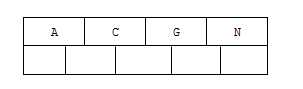
2). 插入H,n>4,中間元素G字母向上分裂到新的節點
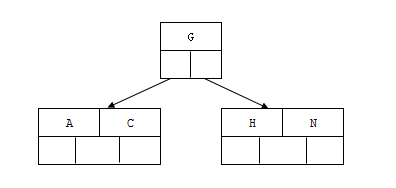
3). 插入E,K,Q不需要分裂
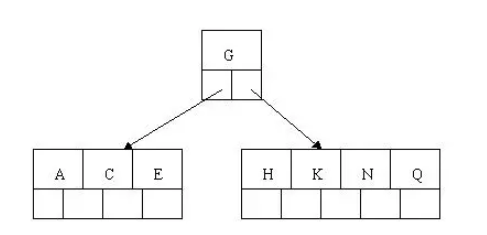
4). 插入M,中間元素M字母向上分裂到父節點G
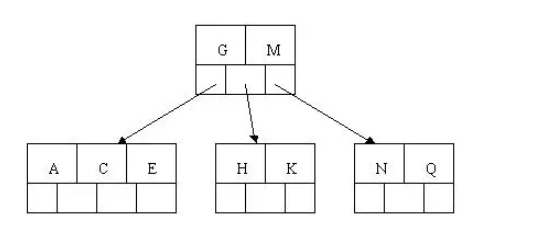
5). 插入F,W,L,T不需要分裂
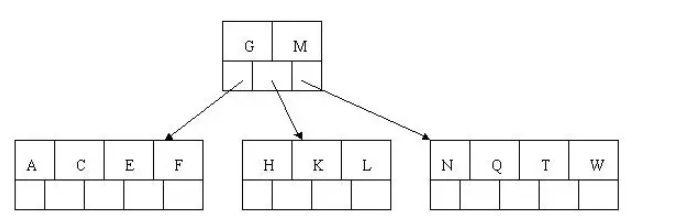
6). 插入Z,中間元素T向上分裂到父節點中
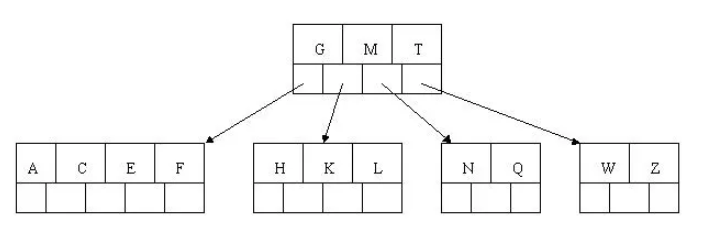
7). 插入D,中間元素D向上分裂到父節點中,然后插入P,R,X,Y不需要分裂
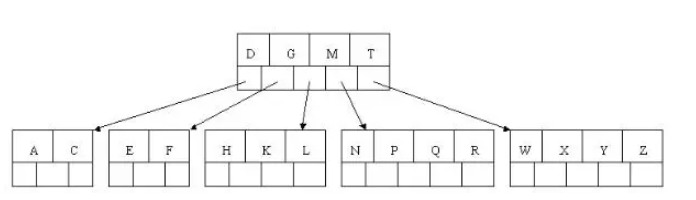
8). 最后插入S,NPQR節點n>5,中間節點Q向上分裂,但分裂后父節點DGMT的n>5,中間節點M向上分裂
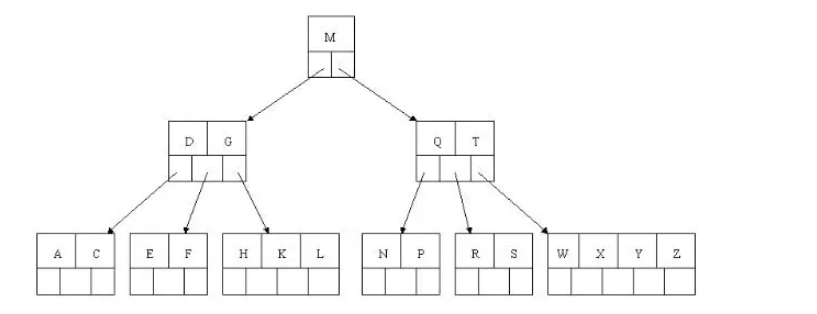
到此,該BTREE樹就已經構建完成了, BTREE樹 和 二叉樹 相比, 查詢資料的效率更高, 因為對于相同的資料量來說,BTREE的層級結構比二叉樹小,因此搜索速度快,
2.3.3 B+TREE 結構
B+Tree為BTree的變種,B+Tree與BTree的區別為:
1). n叉B+Tree最多含有n個key,而BTree最多含有n-1個key,
2). B+Tree的葉子節點保存所有的key資訊,依key大小順序排列,
3). 所有的非葉子節點都可以看作是key的索引部分,
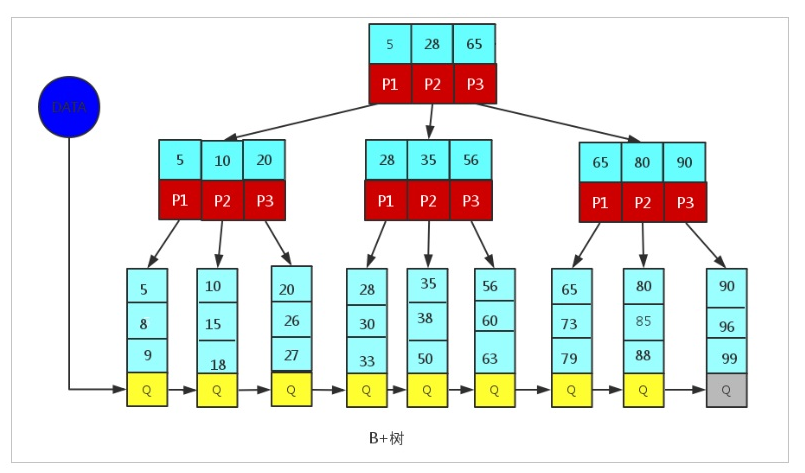
由于B+Tree只有葉子節點保存key資訊,查詢任何key都要從root走到葉子,所以B+Tree的查詢效率更加穩定,
2.3.3 MySQL中的B+Tree
MySql索引資料結構對經典的B+Tree進行了優化,在原B+Tree的基礎上,增加一個指向相鄰葉子節點的鏈表指標,就形成了帶有順序指標的B+Tree,提高區間訪問的性能,
MySQL中的 B+Tree 索引結構示意圖:
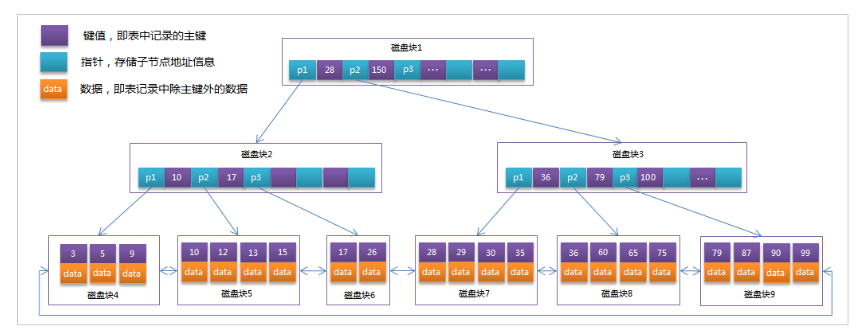
2.4 索引分類
1) 單值索引 :即一個索引只包含單個列,一個表可以有多個單列索引
2) 唯一索引 :索引列的值必須唯一,但允許有空值
3) 復合索引 :即一個索引包含多個列
2.5 索引語法
索引在創建表的時候,可以同時創建, 也可以隨時增加新的索引,
準備環境:
create database demo_01 default charset=utf8mb4;
use demo_01;
CREATE TABLE `city` (
`city_id` int(11) NOT NULL AUTO_INCREMENT,
`city_name` varchar(50) NOT NULL,
`country_id` int(11) NOT NULL,
PRIMARY KEY (`city_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `country` (
`country_id` int(11) NOT NULL AUTO_INCREMENT,
`country_name` varchar(100) NOT NULL,
PRIMARY KEY (`country_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into `city` (`city_id`, `city_name`, `country_id`) values(1,'西安',1);
insert into `city` (`city_id`, `city_name`, `country_id`) values(2,'NewYork',2);
insert into `city` (`city_id`, `city_name`, `country_id`) values(3,'北京',1);
insert into `city` (`city_id`, `city_name`, `country_id`) values(4,'上海',1);
insert into `country` (`country_id`, `country_name`) values(1,'China');
insert into `country` (`country_id`, `country_name`) values(2,'America');
insert into `country` (`country_id`, `country_name`) values(3,'Japan');
insert into `country` (`country_id`, `country_name`) values(4,'UK');
2.5.1 創建索引
語法 :
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name
[USING index_type]
ON tbl_name(index_col_name,...)
index_col_name : column_name[(length)][ASC | DESC]
示例 : 為city表中的city_name欄位創建索引 ;

?
?
2.5.2 查看索引
語法:
show index from table_name;
示例:查看city表中的索引資訊;
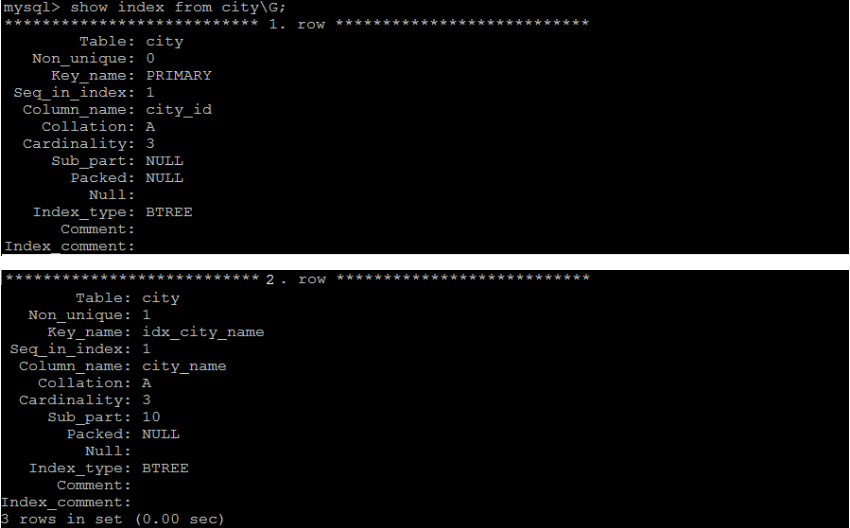
2.5.3 洗掉索引
語法 :
DROP INDEX index_name ON tbl_name;
示例 : 想要洗掉city表上的索引idx_city_name,可以操作如下:

2.5.4 ALTER命令
1). alter table tb_name add primary key(column_list);
該陳述句添加一個主鍵,這意味著索引值必須是唯一的,且不能為NULL
2). alter table tb_name add unique index_name(column_list);
這條陳述句創建索引的值必須是唯一的(除了NULL外,NULL可能會出現多次)
3). alter table tb_name add index index_name(column_list);
添加普通索引, 索引值可以出現多次,
4). alter table tb_name add fulltext index_name(column_list);
該陳述句指定了索引為FULLTEXT, 用于全文索引
2.6 索引設計原則
? 索引的設計可以遵循一些已有的原則,創建索引的時候請盡量考慮符合這些原則,便于提升索引的使用效率,更高效的使用索引,
-
對查詢頻次較高,且資料量比較大的表建立索引,
-
索引欄位的選擇,最佳候選列應當從where子句的條件中提取,如果where子句中的組合比較多,那么應當挑選最常用、過濾效果最好的列的組合,
-
使用唯一索引,區分度越高,使用索引的效率越高,
-
索引可以有效的提升查詢資料的效率,但索引數量不是多多益善,索引越多,維護索引的代價自然也就水漲船高,對于插入、更新、洗掉等DML操作比較頻繁的表來說,索引過多,會引入相當高的維護代價,降低DML操作的效率,增加相應操作的時間消耗,另外索引過多的話,MySQL也會犯選擇困難病,雖然最終仍然會找到一個可用的索引,但無疑提高了選擇的代價,
-
使用短索引,索引創建之后也是使用硬碟來存盤的,因此提升索引訪問的I/O效率,也可以提升總體的訪問效率,假如構成索引的欄位總長度比較短,那么在給定大小的存盤塊內可以存盤更多的索引值,相應的可以有效的提升MySQL訪問索引的I/O效率,
-
利用最左前綴,N個列組合而成的組合索引,那么相當于是創建了N個索引,如果查詢時where子句中使用了組成該索引的前幾個欄位,那么這條查詢SQL可以利用組合索引來提升查詢效率,
創建復合索引: CREATE INDEX idx_name_email_status ON tb_seller(NAME,email,STATUS); 就相當于 對name 創建索引 ; 對name , email 創建了索引 ; 對name , email, status 創建了索引 ;
3. 視圖
3.1 視圖概述
? 視圖(View)是一種虛擬存在的表,視圖并不在資料庫中實際存在,行和列資料來自定義視圖的查詢中使用的表,并且是在使用視圖時動態生成的,通俗的講,視圖就是一條SELECT陳述句執行后回傳的結果集,所以我們在創建視圖的時候,主要的作業就落在創建這條SQL查詢陳述句上,
視圖相對于普通的表的優勢主要包括以下幾項,
- 簡單:使用視圖的用戶完全不需要關心后面對應的表的結構、關聯條件和篩選條件,對用戶來說已經是過濾好的復合條件的結果集,
- 安全:使用視圖的用戶只能訪問他們被允許查詢的結果集,對表的權限管理并不能限制到某個行某個列,但是通過視圖就可以簡單的實作,
- 資料獨立:一旦視圖的結構確定了,可以屏蔽表結構變化對用戶的影響,源表增加列對視圖沒有影響;源表修改列名,則可以通過修改視圖來解決,不會造成對訪問者的影響,
3.2 創建或者修改視圖
創建視圖的語法為:
CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]
VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION]
修改視圖的語法為:
ALTER [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]
VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION]
選項 :
WITH [CASCADED | LOCAL] CHECK OPTION 決定了是否允許更新資料使記錄不再滿足視圖的條件,
LOCAL : 只要滿足本視圖的條件就可以更新,
CASCADED : 必須滿足所有針對該視圖的所有視圖的條件才可以更新, 默認值.
示例 , 創建city_country_view視圖 , 執行如下SQL :
create or replace view city_country_view
as
select t.*,c.country_name from country c , city t where c.country_id = t.country_id;
查詢視圖 :

3.3 查看視圖
? 從 MySQL 5.1 版本開始,使用 SHOW TABLES 命令的時候不僅顯示表的名字,同時也會顯示視圖的名字,而不存在單獨顯示視圖的 SHOW VIEWS 命令,

同樣,在使用 SHOW TABLE STATUS 命令的時候,不但可以顯示表的資訊,同時也可以顯示視圖的資訊,
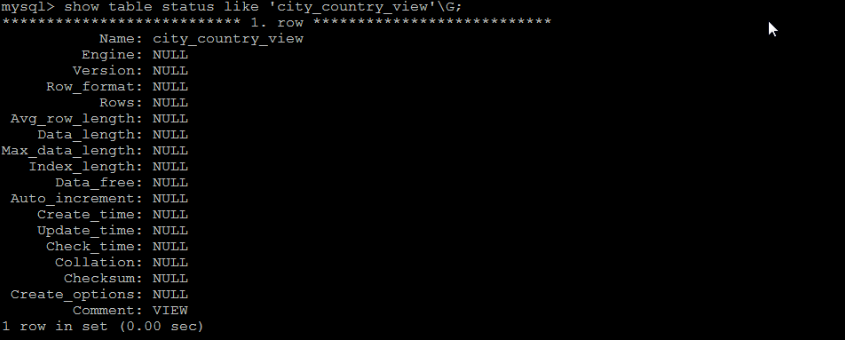
如果需要查詢某個視圖的定義,可以使用 SHOW CREATE VIEW 命令進行查看 :

3.4 洗掉視圖
語法 :
DROP VIEW [IF EXISTS] view_name [, view_name] ...[RESTRICT | CASCADE]
示例 , 洗掉視圖city_country_view :
DROP VIEW city_country_view ;
4. 存盤程序和函式
4.1 存盤程序和函式概述
? 存盤程序和函式是 事先經過編譯并存盤在資料庫中的一段 SQL 陳述句的集合,呼叫存盤程序和函式可以簡化應用開發人員的很多作業,減少資料在資料庫和應用服務器之間的傳輸,對于提高資料處理的效率是有好處的,
? 存盤程序和函式的區別在于函式必須有回傳值,而存盤程序沒有,
? 函式 : 是一個有回傳值的程序 ;
? 程序 : 是一個沒有回傳值的函式 ;
4.2 創建存盤程序
CREATE PROCEDURE procedure_name ([proc_parameter[,...]])
begin
-- SQL陳述句
end ;
示例 :
delimiter $
create procedure pro_test1()
begin
select 'Hello Mysql' ;
end$
delimiter ;
知識小貼士
DELIMITER
? 該關鍵字用來宣告SQL陳述句的分隔符 , 告訴 MySQL 解釋器,該段命令是否已經結束了,mysql是否可以執行了,默認情況下,delimiter是分號;,在命令列客戶端中,如果有一行命令以分號結束,那么回車后,mysql將會執行該命令,
4.3 呼叫存盤程序
call procedure_name() ;
4.4 查看存盤程序
-- 查詢db_name資料庫中的所有的存盤程序
select name from mysql.proc where db='db_name';
-- 查詢存盤程序的狀態資訊
show procedure status;
-- 查詢某個存盤程序的定義
show create procedure test.pro_test1 \G;
4.5 洗掉存盤程序
DROP PROCEDURE [IF EXISTS] sp_name ;
4.6 語法
存盤程序是可以編程的,意味著可以使用變數,運算式,控制結構 , 來完成比較復雜的功能,
4.6.1 變數
- DECLARE
通過 DECLARE 可以定義一個區域變數,該變數的作用范圍只能在 BEGIN…END 塊中,
DECLARE var_name[,...] type [DEFAULT value]
示例 :
delimiter $
create procedure pro_test2()
begin
declare num int default 5;
select num+ 10;
end$
delimiter ;
- SET
直接賦值使用 SET,可以賦常量或者賦運算式,具體語法如下:
SET var_name = expr [, var_name = expr] ...
示例 :
DELIMITER $
CREATE PROCEDURE pro_test3()
BEGIN
DECLARE NAME VARCHAR(20);
SET NAME = 'MYSQL';
SELECT NAME ;
END$
DELIMITER ;
也可以通過select ... into 方式進行賦值操作 :
DELIMITER $
CREATE PROCEDURE pro_test5()
BEGIN
declare countnum int;
select count(*) into countnum from city;
select countnum;
END$
DELIMITER ;
4.6.2 if條件判斷
語法結構 :
if search_condition then statement_list
[elseif search_condition then statement_list] ...
[else statement_list]
end if;
需求:
根據定義的身高變數,判定當前身高的所屬的身材型別
180 及以上 ----------> 身材高挑
170 - 180 ---------> 標準身材
170 以下 ----------> 一般身材
示例 :
delimiter $
create procedure pro_test6()
begin
declare height int default 175;
declare description varchar(50);
if height >= 180 then
set description = '身材高挑';
elseif height >= 170 and height < 180 then
set description = '標準身材';
else
set description = '一般身材';
end if;
select description ;
end$
delimiter ;
呼叫結果為 :

4.6.3 傳遞引數
語法格式 :
create procedure procedure_name([in/out/inout] 引數名 引數型別)
...
IN : 該引數可以作為輸入,也就是需要呼叫方傳入值 , 默認
OUT: 該引數作為輸出,也就是該引數可以作為回傳值
INOUT: 既可以作為輸入引數,也可以作為輸出引數
IN - 輸入
需求 :
根據定義的身高變數,判定當前身高的所屬的身材型別
示例 :
delimiter $
create procedure pro_test5(in height int)
begin
declare description varchar(50) default '';
if height >= 180 then
set description='身材高挑';
elseif height >= 170 and height < 180 then
set description='標準身材';
else
set description='一般身材';
end if;
select concat('身高 ', height , '對應的身材型別為:',description);
end$
delimiter ;
OUT-輸出
需求 :
根據傳入的身高變數,獲取當前身高的所屬的身材型別
示例:
create procedure pro_test5(in height int , out description varchar(100))
begin
if height >= 180 then
set description='身材高挑';
elseif height >= 170 and height < 180 then
set description='標準身材';
else
set description='一般身材';
end if;
end$
呼叫:
call pro_test5(168, @description)$
select @description$
小知識
@description : 這種變數要在變數名稱前面加上“@”符號,叫做用戶會話變數,代表整個會話程序他都是有作用的,這個類似于全域變數一樣,
@@global.sort_buffer_size : 這種在變數前加上 "@@" 符號, 叫做 系統變數
4.6.4 case結構
語法結構 :
方式一 :
CASE case_value
WHEN when_value THEN statement_list
[WHEN when_value THEN statement_list] ...
[ELSE statement_list]
END CASE;
方式二 :
CASE
WHEN search_condition THEN statement_list
[WHEN search_condition THEN statement_list] ...
[ELSE statement_list]
END CASE;
需求:
給定一個月份, 然后計算出所在的季度
示例 :
delimiter $
create procedure pro_test9(month int)
begin
declare result varchar(20);
case
when month >= 1 and month <=3 then
set result = '第一季度';
when month >= 4 and month <=6 then
set result = '第二季度';
when month >= 7 and month <=9 then
set result = '第三季度';
when month >= 10 and month <=12 then
set result = '第四季度';
end case;
select concat('您輸入的月份為 :', month , ' , 該月份為 : ' , result) as content ;
end$
delimiter ;
4.6.5 while回圈
語法結構:
while search_condition do
statement_list
end while;
需求:
計算從1加到n的值
示例 :
delimiter $
create procedure pro_test8(n int)
begin
declare total int default 0;
declare num int default 1;
while num<=n do
set total = total + num;
set num = num + 1;
end while;
select total;
end$
delimiter ;
4.6.6 repeat結構
有條件的回圈控制陳述句, 當滿足條件的時候退出回圈 ,while 是滿足條件才執行,repeat 是滿足條件就退出回圈,
語法結構 :
REPEAT
statement_list
UNTIL search_condition
END REPEAT;
需求:
計算從1加到n的值
示例 :
delimiter $
create procedure pro_test10(n int)
begin
declare total int default 0;
repeat
set total = total + n;
set n = n - 1;
until n=0
end repeat;
select total ;
end$
delimiter ;
4.6.7 loop陳述句
LOOP 實作簡單的回圈,退出回圈的條件需要使用其他的陳述句定義,通常可以使用 LEAVE 陳述句實作,具體語法如下:
[begin_label:] LOOP
statement_list
END LOOP [end_label]
如果不在 statement_list 中增加退出回圈的陳述句,那么 LOOP 陳述句可以用來實作簡單的死回圈,
4.6.8 leave陳述句
用來從標注的流程構造中退出,通常和 BEGIN ... END 或者回圈一起使用,下面是一個使用 LOOP 和 LEAVE 的簡單例子 , 退出回圈:
delimiter $
CREATE PROCEDURE pro_test11(n int)
BEGIN
declare total int default 0;
ins: LOOP
IF n <= 0 then
leave ins;
END IF;
set total = total + n;
set n = n - 1;
END LOOP ins;
select total;
END$
delimiter ;
4.6.9 游標/游標
游標是用來存盤查詢結果集的資料型別 , 在存盤程序和函式中可以使用游標對結果集進行回圈的處理,游標的使用包括游標的宣告、OPEN、FETCH 和 CLOSE,其語法分別如下,
宣告游標:
DECLARE cursor_name CURSOR FOR select_statement ;
OPEN 游標:
OPEN cursor_name ;
FETCH 游標:
FETCH cursor_name INTO var_name [, var_name] ...
CLOSE 游標:
CLOSE cursor_name ;
示例 :
初始化腳本:
create table emp(
id int(11) not null auto_increment ,
name varchar(50) not null comment '姓名',
age int(11) comment '年齡',
salary int(11) comment '薪水',
primary key(`id`)
)engine=innodb default charset=utf8 ;
insert into emp(id,name,age,salary) values(null,'金毛獅王',55,3800),(null,'白眉鷹王',60,4000),(null,'青翼蝠王',38,2800),(null,'紫衫龍王',42,1800);
-- 查詢emp表中資料, 并逐行獲取進行展示
create procedure pro_test11()
begin
declare e_id int(11);
declare e_name varchar(50);
declare e_age int(11);
declare e_salary int(11);
declare emp_result cursor for select * from emp;
open emp_result;
fetch emp_result into e_id,e_name,e_age,e_salary;
select concat('id=',e_id , ', name=',e_name, ', age=', e_age, ', 薪資為: ',e_salary);
fetch emp_result into e_id,e_name,e_age,e_salary;
select concat('id=',e_id , ', name=',e_name, ', age=', e_age, ', 薪資為: ',e_salary);
fetch emp_result into e_id,e_name,e_age,e_salary;
select concat('id=',e_id , ', name=',e_name, ', age=', e_age, ', 薪資為: ',e_salary);
fetch emp_result into e_id,e_name,e_age,e_salary;
select concat('id=',e_id , ', name=',e_name, ', age=', e_age, ', 薪資為: ',e_salary);
fetch emp_result into e_id,e_name,e_age,e_salary;
select concat('id=',e_id , ', name=',e_name, ', age=', e_age, ', 薪資為: ',e_salary);
close emp_result;
end$
通過回圈結構 , 獲取游標中的資料 :
DELIMITER $
create procedure pro_test12()
begin
DECLARE id int(11);
DECLARE name varchar(50);
DECLARE age int(11);
DECLARE salary int(11);
DECLARE has_data int default 1;
DECLARE emp_result CURSOR FOR select * from emp;
DECLARE EXIT HANDLER FOR NOT FOUND set has_data = https://www.cnblogs.com/lovelywcc/p/0;
open emp_result;
repeat
fetch emp_result into id , name , age , salary;
select concat('id為',id, ', name 為' ,name , ', age為 ' ,age , ', 薪水為: ', salary);
until has_data = https://www.cnblogs.com/lovelywcc/p/0
end repeat;
close emp_result;
end$
DELIMITER ;
4.7 存盤函式
語法結構:
CREATE FUNCTION function_name([param type ... ])
RETURNS type
BEGIN
...
END;
案例 :
定義一個存盤程序, 請求滿足條件的總記錄數 ;
delimiter $
create function count_city(countryId int)
returns int
begin
declare cnum int ;
select count(*) into cnum from city where country_id = countryId;
return cnum;
end$
delimiter ;
呼叫:
select count_city(1);
select count_city(2);
5. 觸發器
5.1 介紹
觸發器是與表有關的資料庫物件,指在 insert/update/delete 之前或之后,觸發并執行觸發器中定義的SQL陳述句集合,觸發器的這種特性可以協助應用在資料庫端確保資料的完整性 , 日志記錄 , 資料校驗等操作 ,
使用別名 OLD 和 NEW 來參考觸發器中發生變化的記錄內容,這與其他的資料庫是相似的,現在觸發器還只支持行級觸發,不支持陳述句級觸發,
| 觸發器型別 | NEW 和 OLD的使用 |
|---|---|
| INSERT 型觸發器 | NEW 表示將要或者已經新增的資料 |
| UPDATE 型觸發器 | OLD 表示修改之前的資料 , NEW 表示將要或已經修改后的資料 |
| DELETE 型觸發器 | OLD 表示將要或者已經洗掉的資料 |
5.2 創建觸發器
語法結構 :
create trigger trigger_name
before/after insert/update/delete
on tbl_name
[ for each row ] -- 行級觸發器
begin
trigger_stmt ;
end;
示例
需求
通過觸發器記錄 emp 表的資料變更日志 , 包含增加, 修改 , 洗掉 ;
首先創建一張日志表 :
create table emp_logs(
id int(11) not null auto_increment,
operation varchar(20) not null comment '操作型別, insert/update/delete',
operate_time datetime not null comment '操作時間',
operate_id int(11) not null comment '操作表的ID',
operate_params varchar(500) comment '操作引數',
primary key(`id`)
)engine=innodb default charset=utf8;
創建 insert 型觸發器,完成插入資料時的日志記錄 :
DELIMITER $
create trigger emp_logs_insert_trigger
after insert
on emp
for each row
begin
insert into emp_logs (id,operation,operate_time,operate_id,operate_params) values(null,'insert',now(),new.id,concat('插入后(id:',new.id,', name:',new.name,', age:',new.age,', salary:',new.salary,')'));
end $
DELIMITER ;
創建 update 型觸發器,完成更新資料時的日志記錄 :
DELIMITER $
create trigger emp_logs_update_trigger
after update
on emp
for each row
begin
insert into emp_logs (id,operation,operate_time,operate_id,operate_params) values(null,'update',now(),new.id,concat('修改前(id:',old.id,', name:',old.name,', age:',old.age,', salary:',old.salary,') , 修改后(id',new.id, 'name:',new.name,', age:',new.age,', salary:',new.salary,')'));
end $
DELIMITER ;
創建delete 行的觸發器 , 完成洗掉資料時的日志記錄 :
DELIMITER $
create trigger emp_logs_delete_trigger
after delete
on emp
for each row
begin
insert into emp_logs (id,operation,operate_time,operate_id,operate_params) values(null,'delete',now(),old.id,concat('洗掉前(id:',old.id,', name:',old.name,', age:',old.age,', salary:',old.salary,')'));
end $
DELIMITER ;
測驗:
insert into emp(id,name,age,salary) values(null, '光明左使',30,3500);
insert into emp(id,name,age,salary) values(null, '光明右使',33,3200);
update emp set age = 39 where id = 3;
delete from emp where id = 5;
5.3 洗掉觸發器
語法結構 :
drop trigger [schema_name.]trigger_name
如果沒有指定 schema_name,默認為當前資料庫 ,
5.4 查看觸發器
可以通過執行 SHOW TRIGGERS 命令查看觸發器的狀態、語法等資訊,
語法結構 :
show triggers ;
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/41971.html
標籤:Java