一.概述
dubbo是一款經典的rpc框架,用來遠程呼叫服務的,
dubbo的作用:
- 面向介面的遠程方法呼叫
- 智能容錯和負載均衡
- 服務自動注冊和發現,
- 自定義序列化協議
Dubbo 架構中的核心角色有哪些?
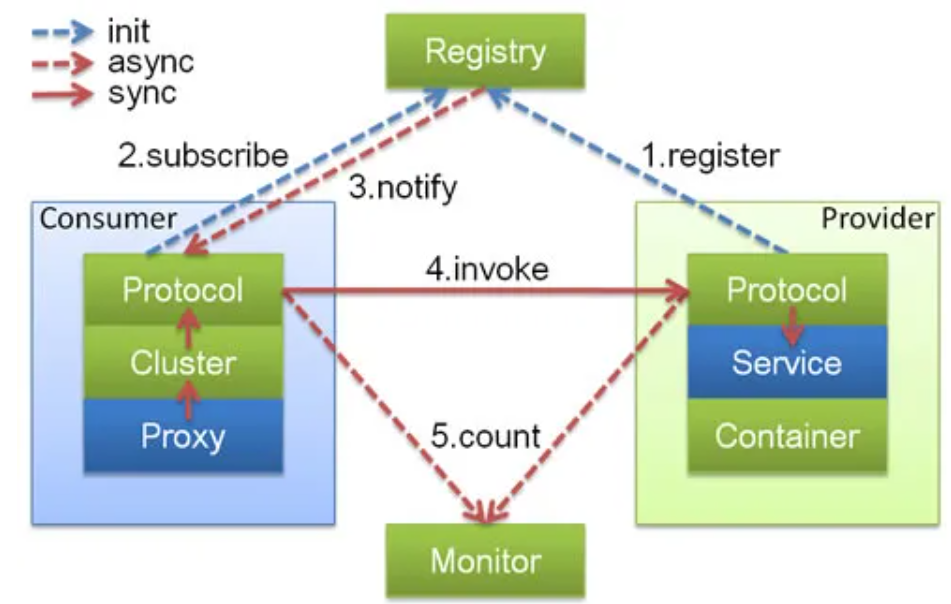
- Container: 服務運行容器,負責加載、運行服務提供者,必須,
- Provider: 暴露服務的服務提供方,會向注冊中心注冊自己提供的服務,必須,
- Consumer: 呼叫遠程服務的服務消費方,會向注冊中心訂閱自己所需的服務,必須,
- Registry: 服務注冊與發現的注冊中心,注冊中心會回傳服務提供者地址串列給消費者,非必須,
- Monitor: 統計服務的呼叫次數和呼叫時間的監控中心,服務消費者和提供者會定時發送統計資料到監控中心,非必須,
Dubbo 中的 Invoker 概念了解么?
-
Invoker是 Dubbo 領域模型中非常重要的一個概念,你如果閱讀過 Dubbo 原始碼的話,你會無數次看到這玩意,就比如下面我要說的負載均衡這塊的原始碼中就有大量Invoker的身影, -
簡單來說,
Invoker就是 Dubbo 對遠程呼叫的抽象,分為2種:- 服務提供
Invoker - 服務消費
Invoker
- 服務提供
- 我們需要呼叫一個遠程方法,我們需要動態代理來屏蔽遠程呼叫的細節吧!我們屏蔽掉的這些細節就依賴對應的
Invoker實作,Invoker實作了真正的遠程服務呼叫
Dobbo的分層架構(作業原理)
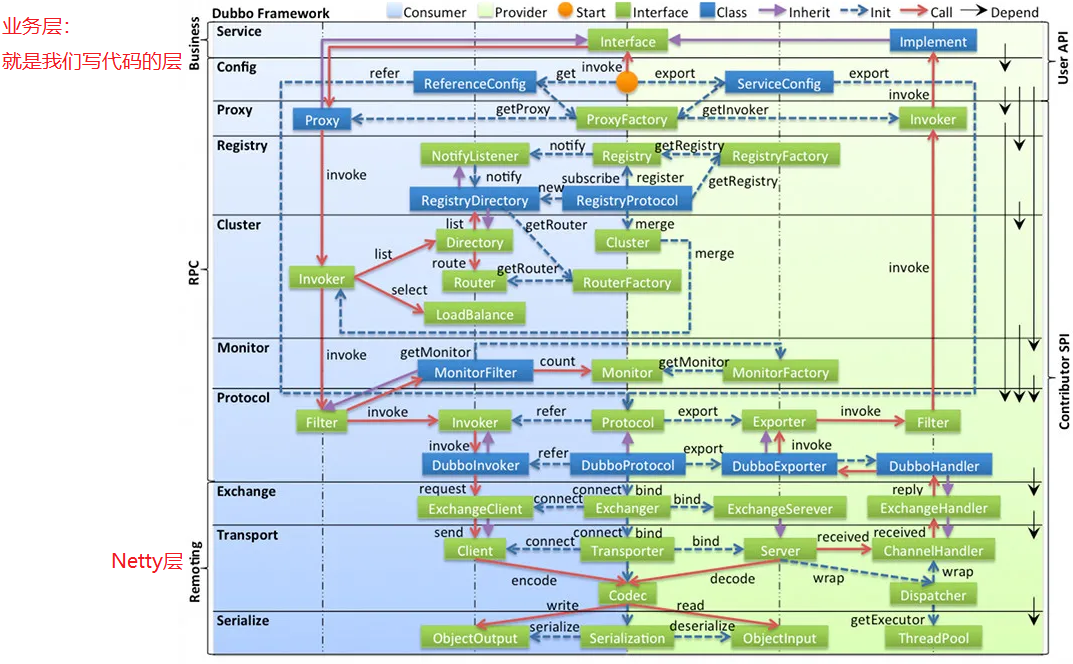
- Service業務層:就是我們寫代碼的層,我們使用rpc只需要關注該層就行,主要是定義介面和實作類,
- config 配置層:Dubbo 相關的配置,支持代碼配置,同時也支持基于 Spring 來做配置,以
ServiceConfig,ReferenceConfig為中心 - proxy 服務代理層:呼叫遠程方法像呼叫本地的方法一樣簡單的一個關鍵,真實呼叫程序依賴代理類,以
ServiceProxy為中心, - registry 注冊中心層:封裝服務地址的注冊與發現,
- cluster 路由層:封裝多個提供者的路由及負載均衡,并橋接注冊中心,以
Invoker為中心, - monitor 監控層:RPC 呼叫次數和呼叫時間監控,以
Statistics為中心, - protocol 遠程呼叫層:封裝 RPC 呼叫,以
Invocation,Result為中心, - exchange 資訊交換層:封裝請求回應模式,同步轉異步,以
Request,Response為中心, - transport 網路傳輸層:抽象 mina 和 netty 為統一介面,以
Message為中心, - serialize 資料序列化層 :對需要在網路傳輸的資料進行序列化,
二.SPI
Dubbo 的 SPI 機制了解么?
- SPI(Service Provider Interface) 機制被大量用在開源專案中(比如Dubbo,SpringBoot...),它可以幫助我們進行功能擴展,
- SPI 的具體原理是這樣的:我們將介面的實作類放在組態檔中,我們在程式運行程序中讀取組態檔,通過反射加載實作類,這樣,我們可以在運行的時候,動態替換介面的實作類,
- 一些配置類就可以使用SPI進行加載,如果我們需要進行擴展,就自定義類放在指定檔案夾下,
- Java 本身就提供了 SPI 機制的實作,不過,Dubbo 沒有直接用,而是對 Java 原生的 SPI 機制進行了增強,以便更好滿足自己的需求,
為什么 Dubbo 不用 JDK 的 SPI,而是要自己實作?
- 因為 Java SPI 在查找擴展實作類的時候遍歷 SPI 的組態檔并且將實作類全部實體化,假設一個實作類初始化程序比較消耗資源且耗時,但是你的代碼里面又用不上它,這就產生了資源的浪費,
- 因此 Dubbo 就自己實作了一個 SPI,給每個實作類配了個名字,通過名字去檔案里面找到對應的實作類全限定名然后加載實體化,按需加載,
如果想深入研究Java SPI:請看一位大佬寫的文章:SPI原始碼分析
如何擴展 Dubbo 中的默認實作?
- 比如說我們想要實作自己的負載均衡策略,我們創建對應的實作類
XxxLoadBalance實作LoadBalance介面或者AbstractLoadBalance類, - 我們將這個是實作類的路徑寫入到
resources目錄下的META-INF/dubbo/org.apache.dubbo.rpc.cluster.LoadBalance檔案中即可,
public class XxxLoadBalance implements LoadBalance { public <T> Invoker<T> select(List<Invoker<T>> invokers, Invocation invocation) throws RpcException { // ... } }
三.Dubbo 的負載均衡策略
- RandomLoadBalance:隨機,隨機的選擇一個,是Dubbo的默認負載均衡策略,(加權/不加權)
- RoundRobinLoadBalance:輪詢,輪詢選擇一個,(加權/不加權)
- LeastActiveLoadBalance:最少活躍數,每個服務維護一個活躍數計數器,當A機器開始處理請求,該計數器加1,此時A還未處理完成,若處理完畢則計數器減1,而B機器接受到請求后很快處理完畢,那么A,B的活躍數分別是1,0,當又產生了一個新的請求,則選擇B機器去執行(B活躍數最小),這樣使慢的機器A收到少的請求,
- ConsistentHashLoadBalance:一致性哈希,相同引數的請求總是落在同一臺機器上,
四.服務暴露,服務參考,服務呼叫程序
服務暴露:生成代理類,將資訊注冊到ZK
- 組裝URL:Spring IOC 容器重繪完畢之后,會根據配置引數組裝成 URL, 然后根據 URL 的引數來進行代理類的生成,
- 生成代理類:會通過
proxyFactory.getInvoker,利用 javassist 來進行動態代理,封裝真的實作類, - 根據協議生成暴露物件(exporter):通過 URL 引數選擇對應的協議來進行 protocol.export,默認是 Dubbo 協議,
- 自適應:代理類會根據 Invoker 里面的 URL 引數得知具體的協議,然后通過 Dubbo SPI 機制選擇對應的實作類進行 export,
- 注冊到ZK:將 export 得到的 exporter 存入一個 Map 中,供之后的遠程呼叫查找,然后會向注冊中心注冊提供者的資訊,
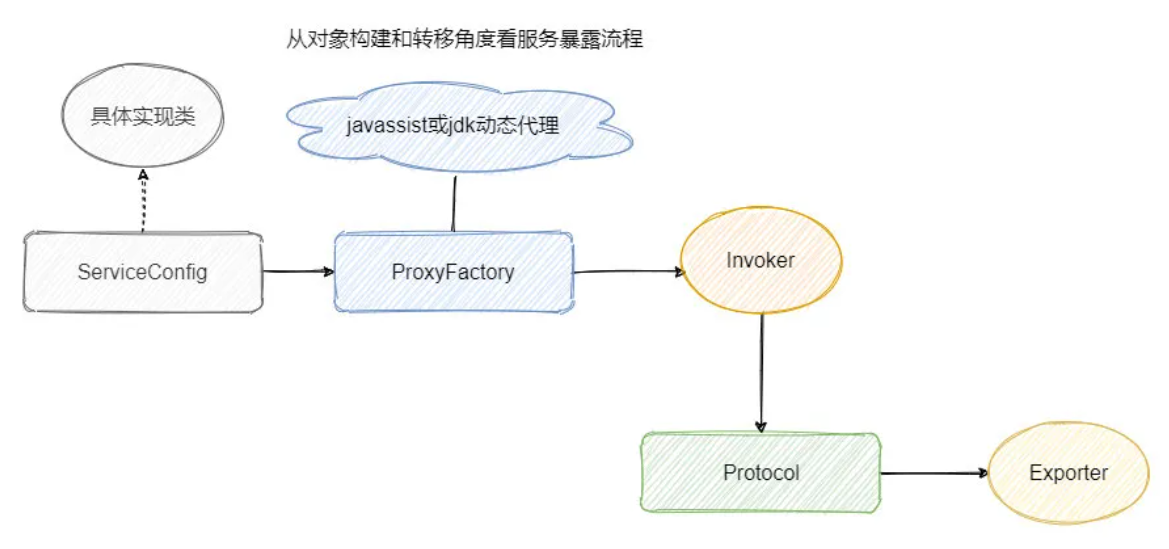
想要深究原始碼的小伙伴可以看一位大佬寫的文章:服務暴露原始碼分析,
服務參考:獲取遠程呼叫的類,生成代理類,可以看作服務參考的逆程序,
- 組裝URL:會根據配置引陣列裝成 URL, 然后根據 URL 的引數來進行代理類的生成,(2種時機)
- 餓漢式:餓漢式是通過實作 Spring 的
InitializingBean介面中的afterPropertiesSet方法,容器通過呼叫ReferenceBean的afterPropertiesSet方法時引入服務,(在Spring啟動時,給所有的屬性注入實作類,包含遠程和本地的實作類) - 懶漢式:只有當這個服務被注入到其他類中時啟動引入流程,也就是說用到了才會開始服務引入,
- 在應用的Spring Context初始化完成事件時觸發,掃描所有的Bean,將Bean中帶有@Reference注解的field獲取到,然后創建field型別的代理物件,創建完成后,將代理物件set給此field,后續就通過該代理物件創建服務端連接,并發起呼叫,(dubbo默認)
- 餓漢式:餓漢式是通過實作 Spring 的
- 從ZK中獲取需要的服務提供者的資訊:得到Map,
- 根據協議決議傳過來的exporter:
- 協議的不同,獲取的路徑也不同:本地,直接,從ZK,
- 生成代理類:供消費者使用Netty進行遠程呼叫,invoker,
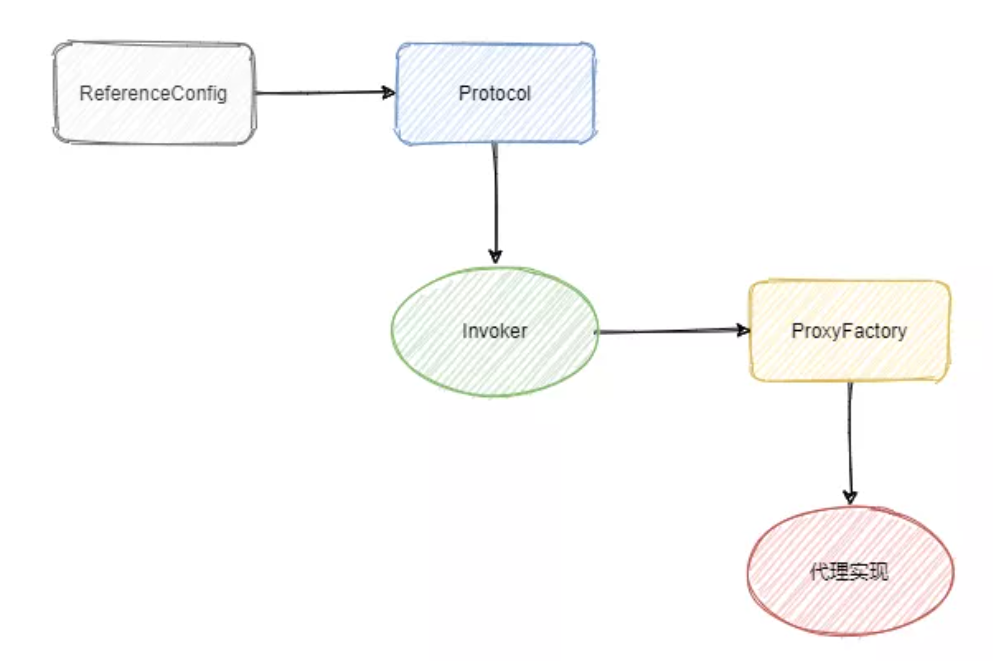
想要深究原始碼的小伙伴可以看一位大佬寫的文章:服務參考原始碼分析,
服務呼叫:
- 服務呼叫是在生成代理物件后,使用Netty,生成Netty Client進行遠程呼叫,Netty Server通過反射回傳呼叫結果,
- 在呼叫之前,就會進行智能容錯和負載均衡,
- 首先客戶端呼叫介面的某個方法,實際呼叫的是代理類,代理類會通過 cluster 從 directory(invoker的集合) 中獲取一堆 invokers(如果有一堆的話),然后進行 router 的過濾(其中看配置也會添加 mockInvoker 用于服務降級),然后再通過 SPI 得到 loadBalance 進行一波負載均衡,
補充:cluster 是什么?
- 一個中間層,為消費者屏蔽了服務提供者的情況,簡化了消費者的使用,
- 它可以負責選擇哪個invoker回傳給呼叫者,比如選擇一個 invoker ,呼叫出錯了可以換一個等等,
想要深究原始碼的小伙伴可以看一位大佬寫的文章:服務呼叫原始碼分析,
容錯機制:先容錯,再負載均衡,
- 首先在服務引入的時候,將多個遠程呼叫都塞入 Directory 中,然后通過 Cluster 來封裝這個目錄,封裝的同時提供各種容錯功能,比如 FailOver、FailFast 等等,最終暴露給消費者的就是一個 invoker,
- 然后消費者呼叫的時候會目錄里面得到 invoker 串列,當然會經過路由的過濾,得到這些 invokers 之后再由 loadBalance 來進行負載均衡選擇一個 invoker,最終發起呼叫,
dubbo常見的容錯機制
- Failover Cluster(默認)
- 失敗自動切換,當出現失敗,重試其它服務器,
- 通常用于讀操作,但重試會帶來更長延遲,
- Failfast Cluster
- 快速失敗,只發起一次呼叫,失敗立即報錯,
- 通常用于非冪等性的寫操作,比如新增記錄,
- Failsafe Cluster
- 失敗安全,出現例外時,直接忽略,
- 通常用于寫入審計日志等操作,
- Failback Cluster
- 失敗自動恢復,后臺記錄失敗請求,定時重發,
- 通常用于訊息通知操作,
- Forking Cluster
- 并行呼叫多個服務器,只要一個成功即回傳,
- 通常用于實時性要求較高的讀操作,但需要浪費更多服務資源,
想要深究原始碼的小伙伴可以看一位大佬寫的文章:dubbo智能容錯原始碼分析
五.其他小問題
Dubbo 為什么默認用 Javassist?
- 很簡單,就是快,且位元組碼生成方便,
- 其他常見的動態代理: JDK 的動態代理、ASM、cglib,
- ASM 比 Javassist 更快,但是沒有快一個數量級,而Javassist 只需用字串拼接就可以生成位元組碼,而 ASM 需要手工生成,成本較高,比較麻煩,
Dubbo 支持多種序列化方式?
- JDK 自帶的序列化:不支持跨語言呼叫 ;性能差
- JSON:性能差
- ProtoBuf :支持跨語言
- hessian2(默認):支持跨語言
- Protostuff:支持跨語言
- Kryo:新引入的,只支持JAVA
- FST:新引入的,只支持JAVA
寄語:你所看到的驚艷,都曾被平庸歷練
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/423738.html
標籤:Java