一、現象
服務部署后記憶體總體呈上升趨勢
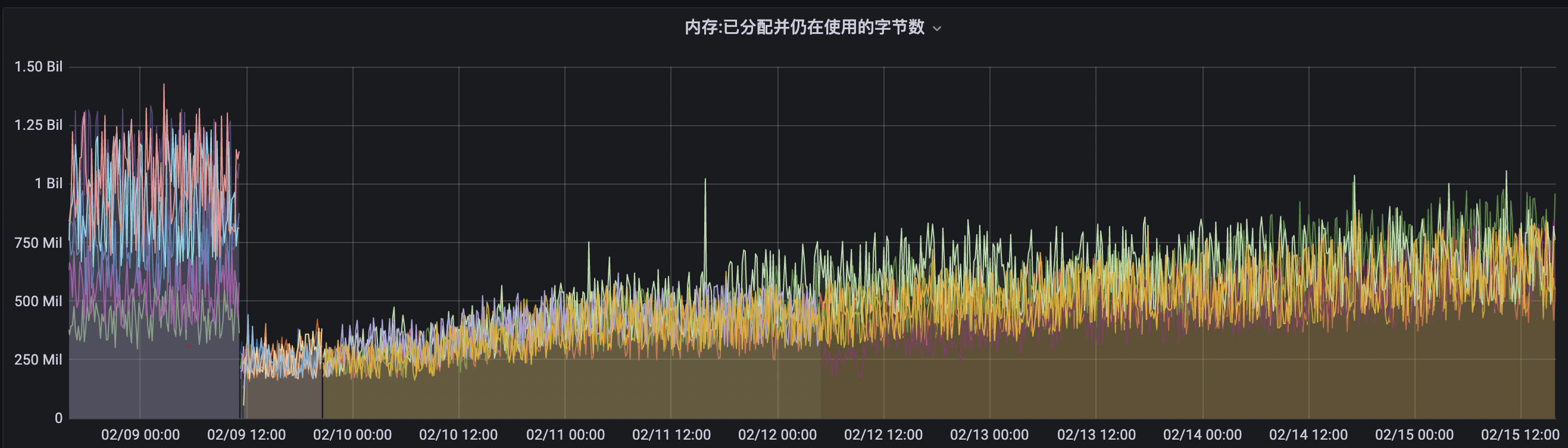
二、排查程序
通過go tool pprof收集了三天記憶體資料
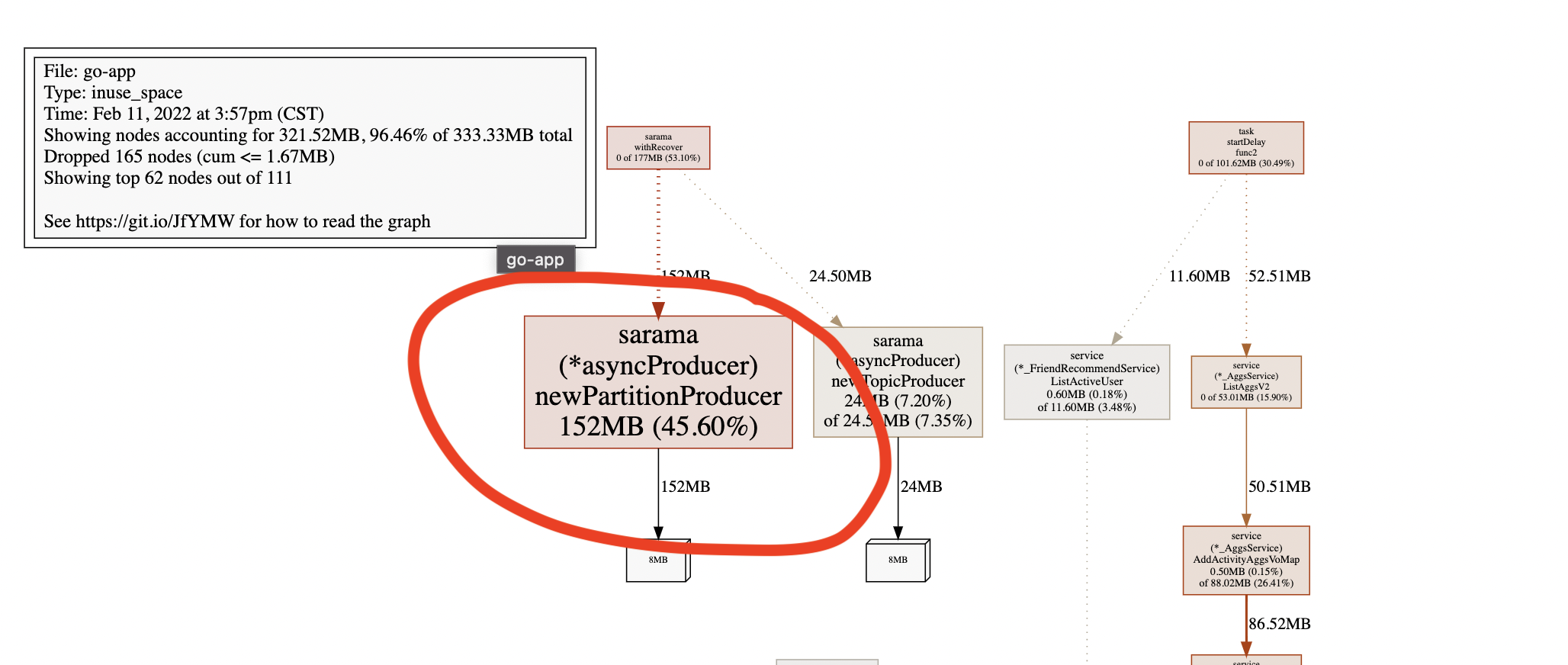
2月11號資料:
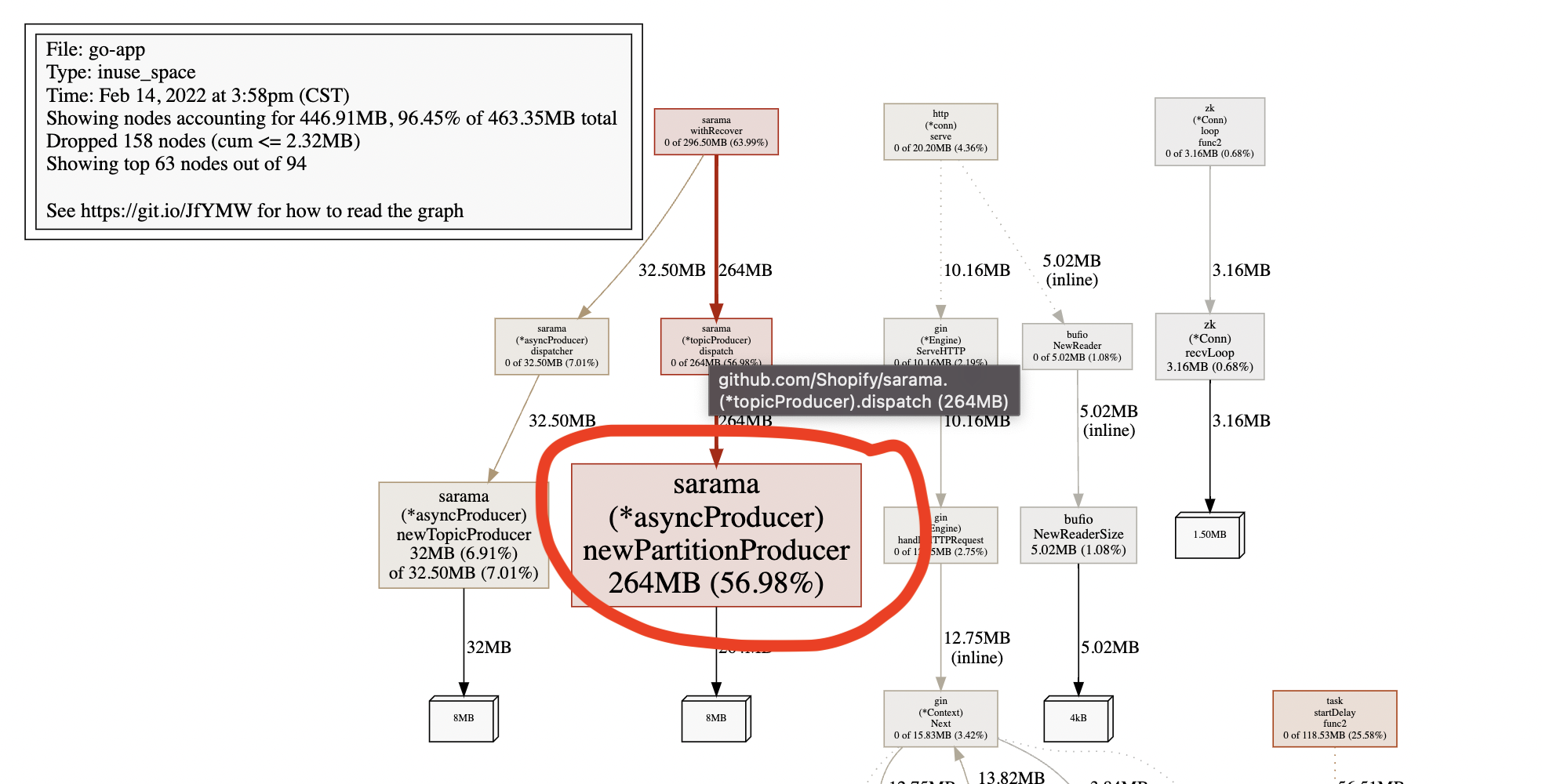
2月14號資料:
2月15號資料:
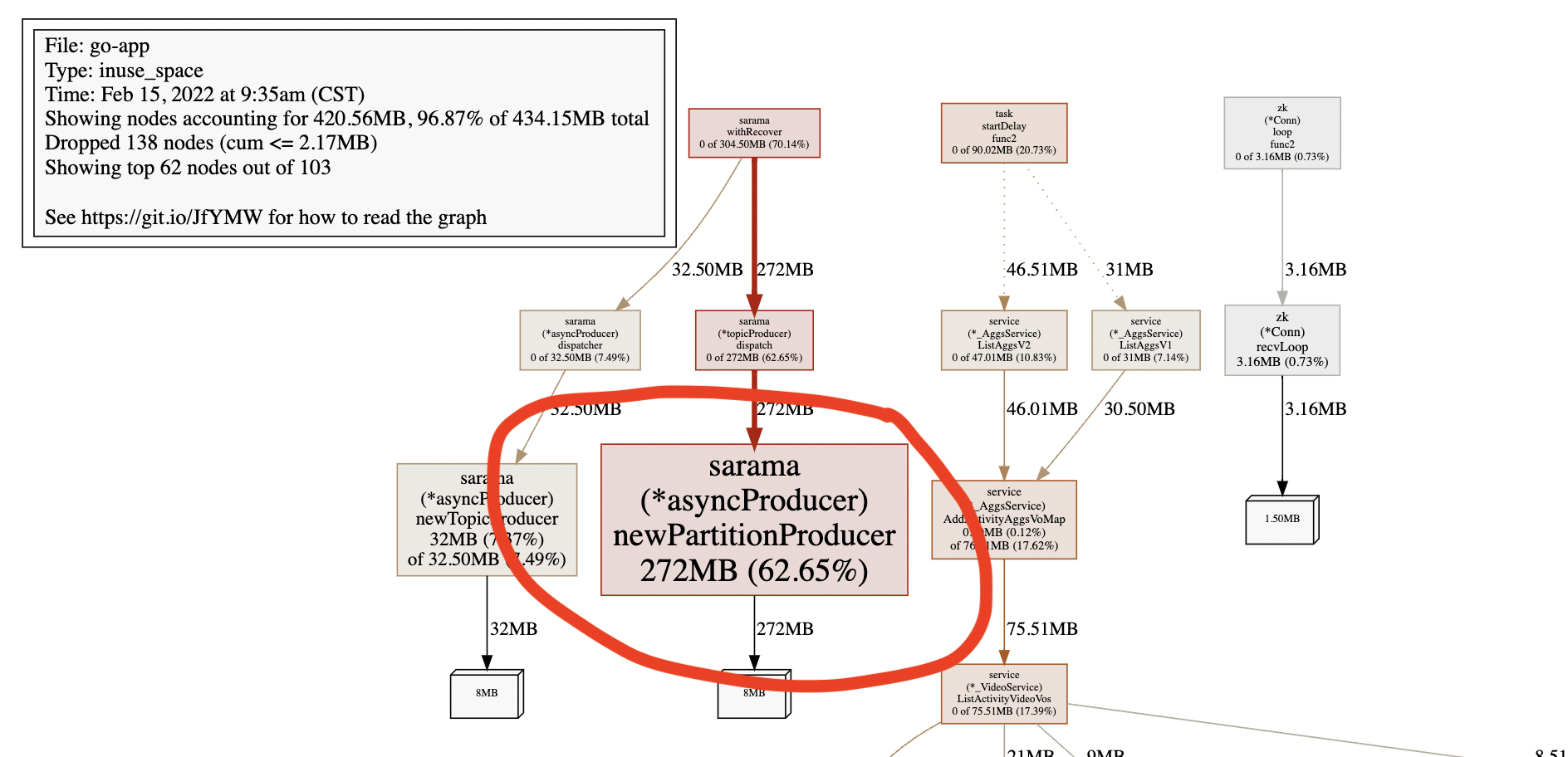
我們使用sarama客戶端連接kafka,可以看到newPartitionProducer持續增長,可定位到是kafka的問題,而newPartitionProducer是磁區生產者,因此查看磁區相關的資料,
最近增加的topic:ai_face_process_topic,這個是AI換臉的,每生成一個視頻都要通過Kafka中轉訊息到視頻處理服務器,
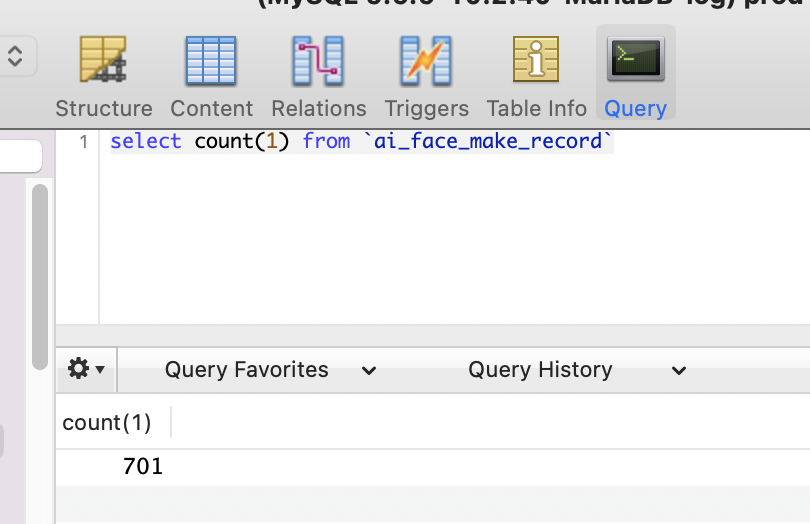
查閱資料庫看視頻生成記錄,2022.1.25上線到今天2022.2.15一共20天,只增長了701個視頻,平均每天35個視頻,
但這個topic有64個磁區,這是因為視頻生成程序比較耗時,當時考慮到需要提高并發量,所以需要磁區數比較多,
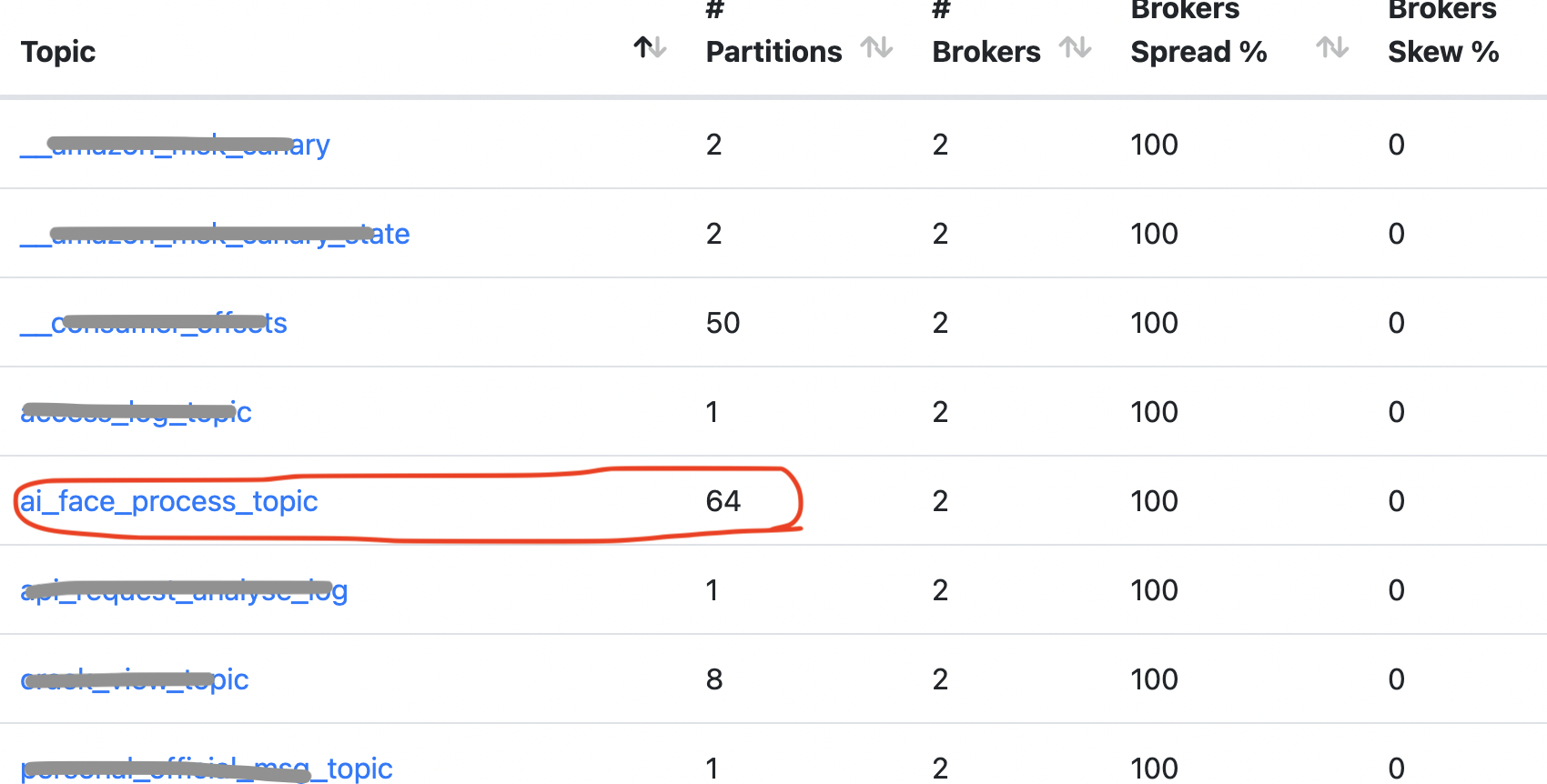
查看sarama客戶端的API代碼,給每個磁區發訊息時會判斷這個磁區的handler是否存在,不存在則創建,
sarama創建partition handler的關鍵代碼:
handler := tp.handlers[msg.Partition]
if handler == nil {
handler = tp.parent.newPartitionProducer(msg.Topic, msg.Partition)
tp.handlers[msg.Partition] = handler
}
|
且創建后需要手動close,否則記憶體一直占用,這是官方說明:
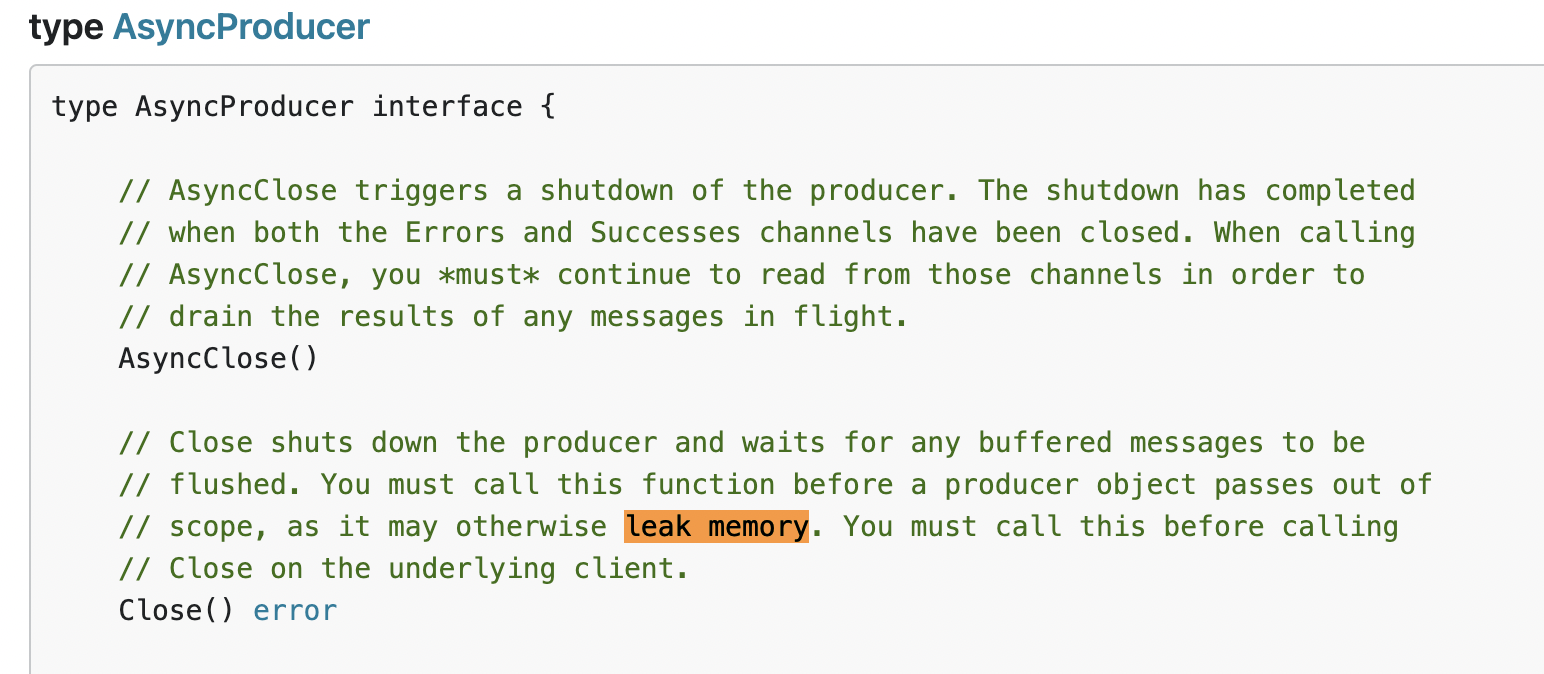
而我們使用sarama客戶端的producer是全域的,一直不會close,所以會一直占用記憶體,
再看看我們使用sarama的partitioner是NewRandomPartitioner,即每條訊息隨機匹配到partition,
這樣,按照每天三十多的視頻生成量,出現前幾天新增分配二三十個handler,逐漸減少,直到分配完64個handler,
我們設定了ChannelBufferSize = 1024 * 1024,newPartitionProducer使用64位指標的帶緩沖channel快取訊息,因此每個handler會分配8MB記憶體,也就出現了上面的記憶體資料:152MB,264MB,172MB,
三、結論與優化
記憶體增長幾天穩定后則不會繼續增長,
其他磁區數比較多的topic沒有觀察到記憶體持續增長情況是因為資料量比較大,服務啟動沒多久就分配完了每個磁區的handler,
優化:
單個AI換臉視頻處理服務耗時較長,決定了我們需要比較大的并發量,所以后面磁區數還可能增加,而64個磁區已經使每個服務占用64*8=504MB記憶體,嚴重影響擴展性,
因此后面ai_face_process_topic考慮遷移到redis做訊息中轉,
四、參考鏈接
sarama API
githup sarama memory leak問題
kafka memory leak問題
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/424860.html
標籤:Go