我正在使用標準的島和間隙演算法來查找連續值的塊(一或零)。ProductionState 串列示基于連接到機器的傳感器的讀數的生產或不生產的時間段。相關步驟包含在此通用表元素中:
-- Production state islands with unique Id
production_state_03( Timestamp, ProductionState, ProductionStateIslandId ) as
(
select
Timestamp,
ProductionState,
row_number() over ( order by Timestamp ) - row_number() over ( partition by ProductionState order by ProductionState )
from production_state_02
)
結果如下表:
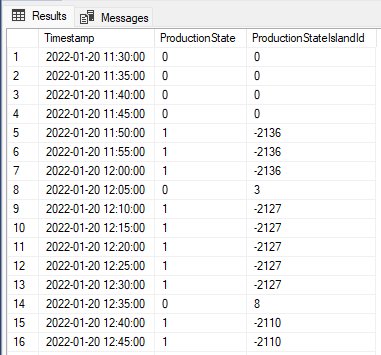
問題是每個島或間隙的 ProductionStateIslandId 不一定是全域唯一的,這會導致后面的分析步驟出錯。是否有不同的方法來計算總是會導致全域唯一 ID 值的島嶼和差距?
uj5u.com熱心網友回復:
第二個 row_number 也應該按時間戳排序。
row_number() over (order by [Timestamp])
- row_number() over (partition by ProductionState
order by [Timestamp])
或者
row_number() over (order by [Timestamp])
row_number() over (partition by ProductionState
order by [Timestamp] DESC)
但這種更正不會使其成為全球獨一無二的。
計算此類排名的另一種方法是對更改標志求和。
production_state_03 ([Timestamp], ProductionState, ProductionStateIslandId) as
(
select [Timestamp], ProductionState
, rnk = SUM(flag) over (order by [Timestamp])
from
(
select [Timestamp], ProductionState
, flag = IIF(ProductionState = LAG(ProductionState) over (order by [Timestamp]), 0, 1)
from production_state_02
) q
)
這個 Gaps-And-Islands 解決方案技巧確實需要一個額外的子查詢,但排名將是連續的。
uj5u.com熱心網友回復:
這東西:
row_number() over ( partition by ProductionState order by ProductionState )
沒有意義。它所做的只是創建一個看似有序的、現實中的亂數。
您的差距是不尋常的,因為它們不是真正的差距,0 值行仍然存在。也許有條件的求和會有所幫助:
row_number() over ( order by Timestamp ) - sum(ProductionState) over (order by Timestamp)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/425353.html