我想通過以下方式總結一個時間序列的資料:
- 類別 -(1. 低,2. 中等,3. 強,4. 極端)。
- 每個類別運行的開始和結束時間。
下圖顯示了資料片段和所需的輸出。
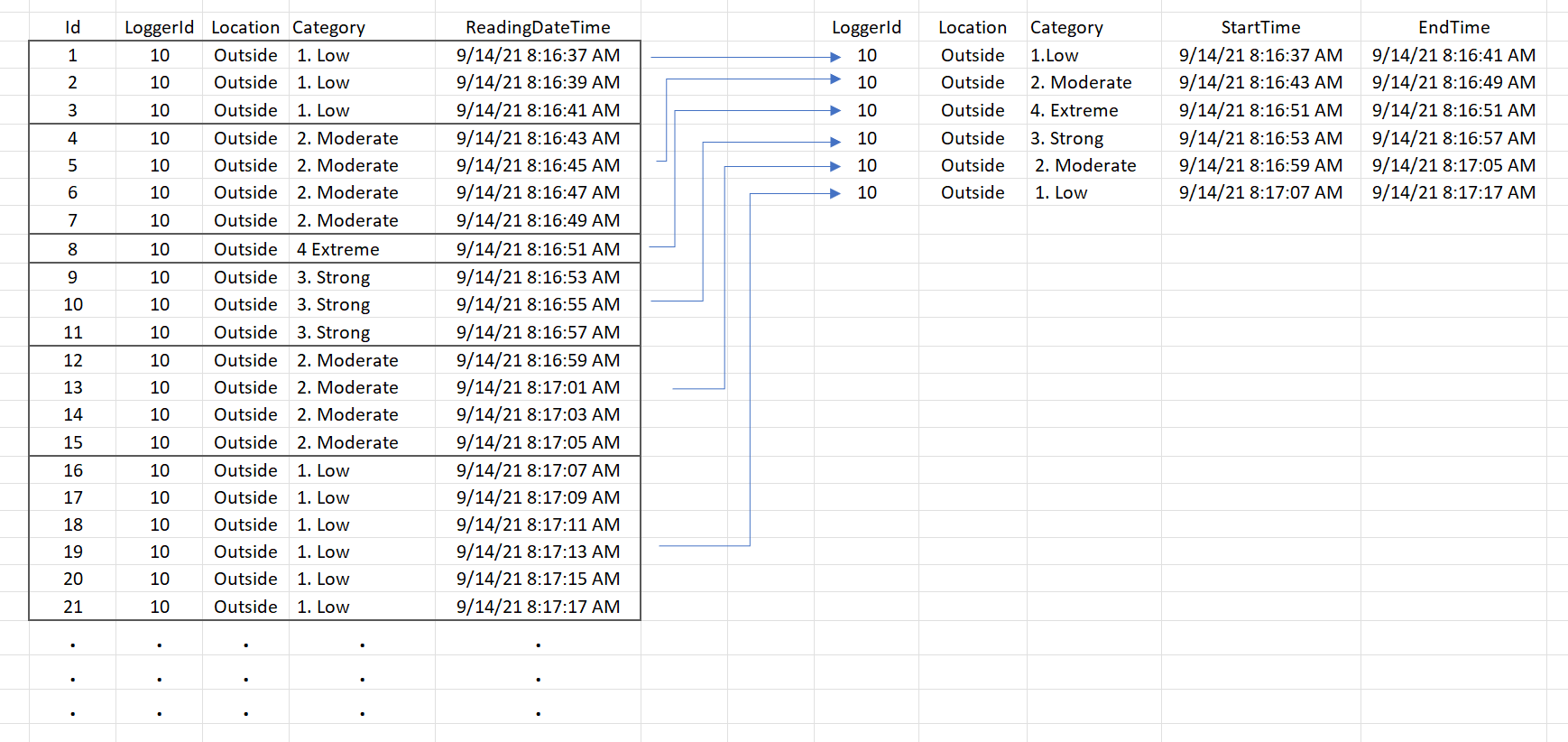
由于
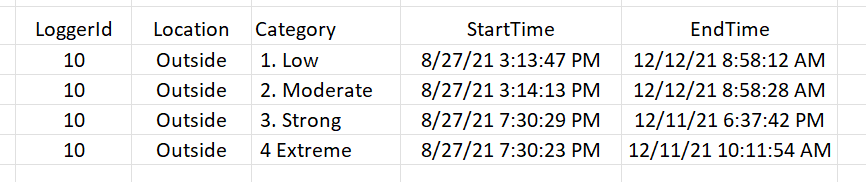
Categories(1. 低、2. 中等、3. 強、4. 極端)在整個時間軸中重復出現,如下所示的方法會將整個表格的和值SELECT匯總為四行。MINMAXReadingDateTimeReadingDateTime低類別中所有讀數的最小值和最大值。ReadingDateTime中等類別中所有讀數的最小值和最大值。ReadingDateTime強類別中所有讀數的最小值和最大值。ReadingDateTime極端類別中所有讀數的最小值和最大值。
SELECT..
MIN(ReadingDateTime)
,MAX(ReadingDateTime)
FROM CurrentLogger
GROUP BY LoggerId
,Category
ORDER BY LoggerId
,ReadingDateTime
例如:
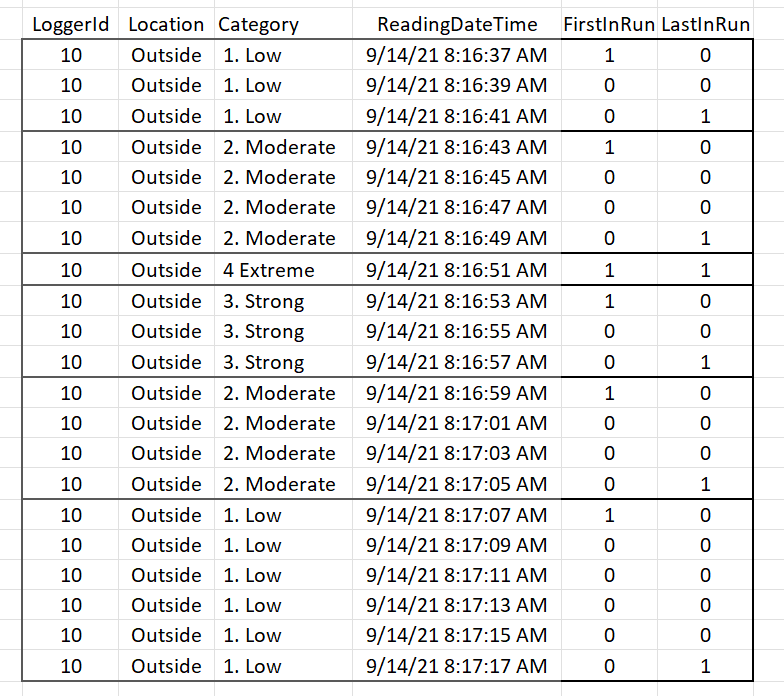
I have one approach, but I am sure there is a much better way. I mark the start and end of runs of Categories by using the SQL LAG and LEAD functions.
SELECT LoggerId
,Location
,Category
,dBDateTime
,FirstInRun = IIF(LAG(dBCategory,1,0) OVER(ORDER BY InstrumentId, dBDateTime)<>dBCategory,1,0)
,LastInRun = IIF(LEAD(dBCategory,1,0) OVER(ORDER BY InstrumentId, dBDateTime)<>dBCategory,1,0)
FROM CurrentLogger
ORDER BY InstrumentId
,dBDateTime
The output is below:
There are several ugly and slow ways to roll this up to the desired output.
My question is:
- Before rolling this up to the desired output, is there a far more obvious way to get the start and end times for each of the consecutive categorical runs?
uj5u.com熱心網友回復:
一種匯總方法是使用 ROW_NUMBER() 函式來創建您的組,然后獲取每個組的 MIN/MAX 日期。考慮以下:
CREATE TABLE #CurrentLogger(LoggerID int, Location varchar(20),Category varchar(20),ReadingDateTime datetime)
INSERT INTO #CurrentLogger VALUES
(10,'OutSide','1. Low','9/14/21 8:16:37 AM'),
(10,'OutSide','1. Low','9/14/21 8:16:39 AM'),
(10,'OutSide','1. Low','9/14/21 8:16:41 AM'),
(10,'OutSide','2. Moderate','9/14/21 8:16:43 AM'),
(10,'OutSide','2. Moderate','9/14/21 8:16:45 AM'),
(10,'OutSide','2. Moderate','9/14/21 8:16:47 AM'),
(10,'OutSide','2. Moderate','9/14/21 8:16:49 AM'),
(10,'OutSide','4. Extreme','9/14/21 8:16:51 AM'),
(10,'OutSide','3. Strong','9/14/21 8:16:53 AM'),
(10,'OutSide','3. Strong','9/14/21 8:16:55 AM'),
(10,'OutSide','3. Strong','9/14/21 8:16:57 AM'),
(10,'OutSide','2. Moderate','9/14/21 8:16:59 AM'),
(10,'OutSide','2. Moderate','9/14/21 8:17:01 AM'),
(10,'OutSide','2. Moderate','9/14/21 8:17:03 AM'),
(10,'OutSide','2. Moderate','9/14/21 8:17:05 AM'),
(10,'OutSide','1. Low','9/14/21 8:17:07 AM'),
(10,'OutSide','1. Low','9/14/21 8:17:09 AM'),
(10,'OutSide','1. Low','9/14/21 8:17:11 AM'),
(10,'OutSide','1. Low','9/14/21 8:17:13 AM'),
(10,'OutSide','1. Low','9/14/21 8:17:15 AM'),
(10,'OutSide','1. Low','9/14/21 8:17:17 AM');
WITH CTE AS
(
SELECT *,
ROW_NUMBER() OVER(PARTITION BY LoggerID ORDER BY ReadingDateTime)
- ROW_NUMBER() OVER(PARTITION BY LoggerID,Location,Category ORDER BY ReadingDateTime) Grp
FROM #CurrentLogger
)
SELECT LoggerID,Location,Category, MIN(ReadingDateTime) StartDate, MAX(ReadingDateTime) EndDate
FROM CTE
GROUP BY Grp,LoggerID,Location,Category
ORDER BY StartDate
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/425379.html
上一篇:獲取給定日期的最后一個星期三
下一篇:從父級別的節點檢索值