一、變數
1.按資料型別分類
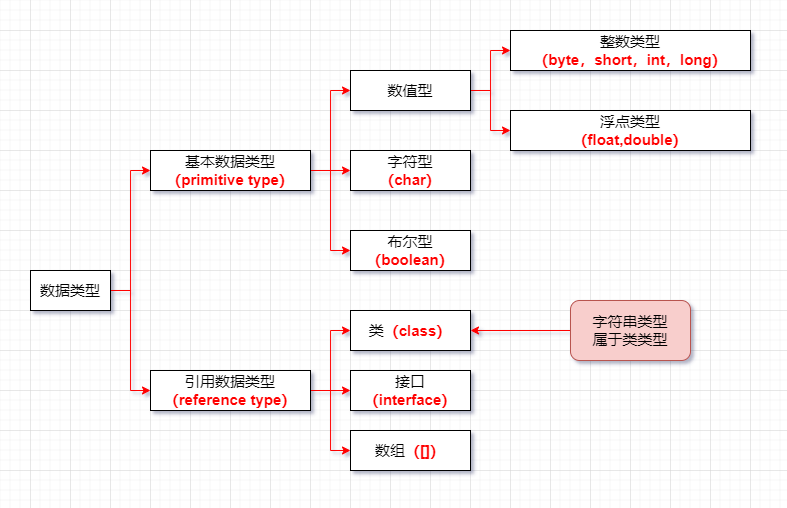
詳細說明:
- 整型:byte(1位元組=8bit) \ short(2位元組) \ int(4位元組) \ long(8位元組)
byte范圍:-128 ~ 127
宣告long型變數,必須以"l"或"L"結尾
通常,定義整型變數時,使用int型,
整型的常量,默認型別是:int型
- 浮點型:float(4位元組) \ double(8位元組)
浮點型,表示帶小數點的數值
float表示數值的范圍比long還大
定義float型別變數時,變數要以"f"或"F"結尾
通常,定義浮點型變數時,使用double型,
浮點型的常量,默認型別為:double
- 字符型:char (1字符=2位元組)
定義char型變數,通常使用一對'',內部只能寫一個字符
表示方式:1.宣告一個字符 2.轉義字符 3.直接使用 Unicode 值來表示字符型常量
- 布爾型:boolean
只能取兩個值之一:true 、 false
常常在條件判斷、回圈結構中使用
2.按宣告的位置分類
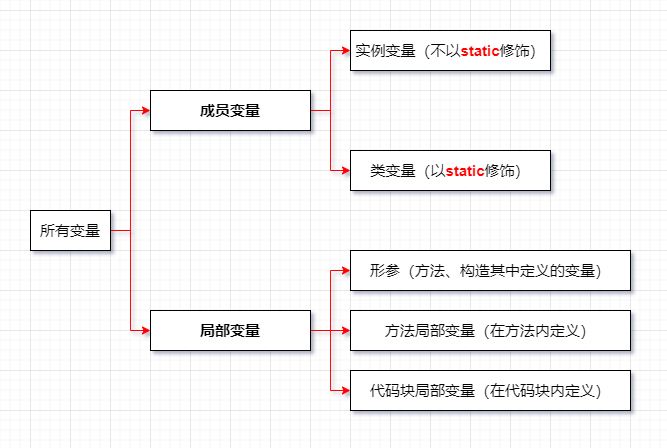
3.定義變數的格式
- 資料型別 變數名 = 變數值;
- 資料型別 變數名;
- 變數名 = 變數值;
變數使用的注意點:
-
變數必須先宣告,后使用
-
變數都定義在其作用域內,在作用域內,它是有效的,換句話說,出了作用域,就失效了
-
同一個作用域內,不可以宣告兩個同名的變數
4.基本資料型別變數間運算規則
涉及到的基本資料型別:除了boolean之外的其他7種,自動型別轉換(只涉及7種基本資料型別),
結論:當容量小的資料型別的變數與容量大的資料型別的變數做運算時,結果自動提升為容量大的資料型別,
byte 、char 、short --> int --> long --> float --> double
特別的:當 byte、char、short 三種型別的變數做運算時,結果為int型,
說明:此時的容量大小指的是,表示數的范圍的大和小,比如:float容量要大于long的容量
強制型別轉換(只涉及7種基本資料型別):自動型別提升運算的逆運算,
-
需要使用強轉符:()
-
注意點:強制型別轉換,可能導致精度損失,
String 與8種基本資料型別間的運算
-
String 屬于參考資料型別,翻譯為:字串
-
宣告 String 型別變數時,使用一對""
-
String 可以和8種基本資料型別變數做運算,且運算只能是連接運算:+
-
運算的結果仍然是 String 型別
避免:
String s = 123;//編譯錯誤
String s1 = "123";
int i = (int)s1;//編譯錯誤
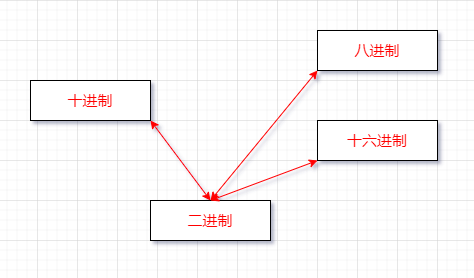
5.進制
1.編程中涉及的進制及表示方式
-
二進制(bianary):0,1 , 滿 2 進 1. 以 0b 或 0B開頭
-
十進制(decimal):0-9,滿10進1
-
八進制(octal):0-7,滿8進1,以數字0開頭
-
十六進值(hex):0-9及A-F,滿16進1. 以0x或0X開頭表示,此處的A-F不區分大小寫,
-
如:0x21AF + 1 =0X21B0
2.二進制的使用說明
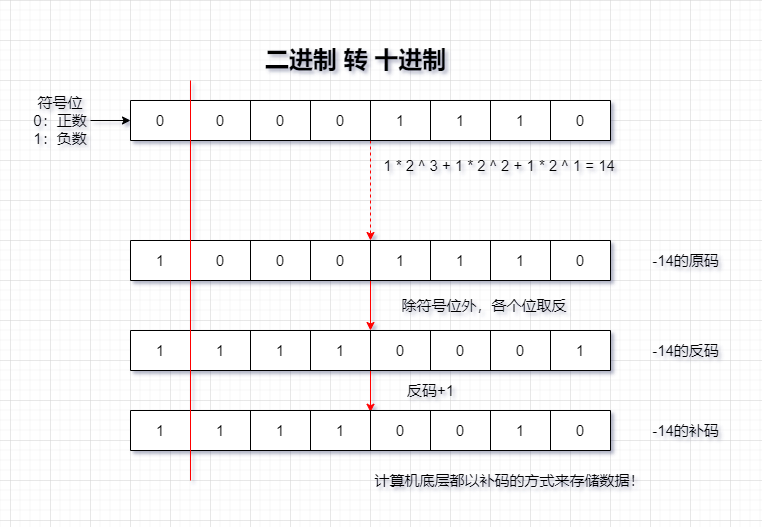
計算機底層的存盤方式:所有數字在計算機底層都以二進制形式存在,
二進制資料的存盤方式:所有的數值,不管正負,底層都以補碼的方式存盤,
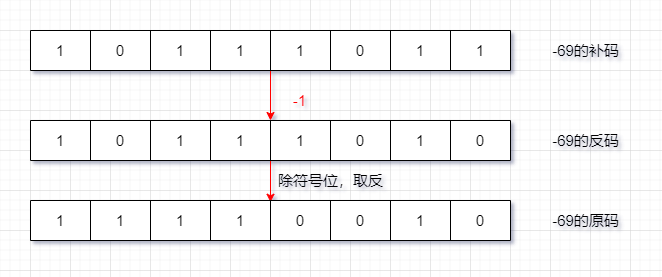
原碼、反碼、補碼的說明:
正數:三碼合一
負數:
原 碼 : 直 接 將 一 個 數 值 換 成 二 進 制 數 , 最 高 位 是 符 號 位
負 數 的 反 碼 : 是 對 原 碼 按 位 取 反 , 只 是 最 高 位 ( 符 號 位 ) 確 定 為 1 ,
負 數 的 補 碼 : 其 反 碼 加 1 ,
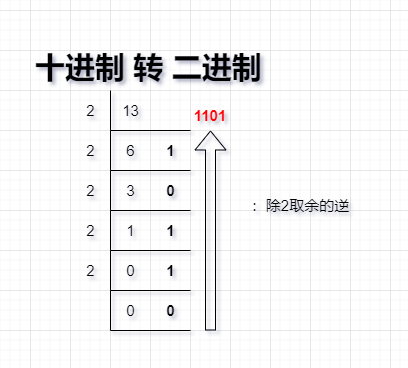
3.進制間的轉換
圖示二進制轉換為十進制:

圖示十進制轉換為二進制:
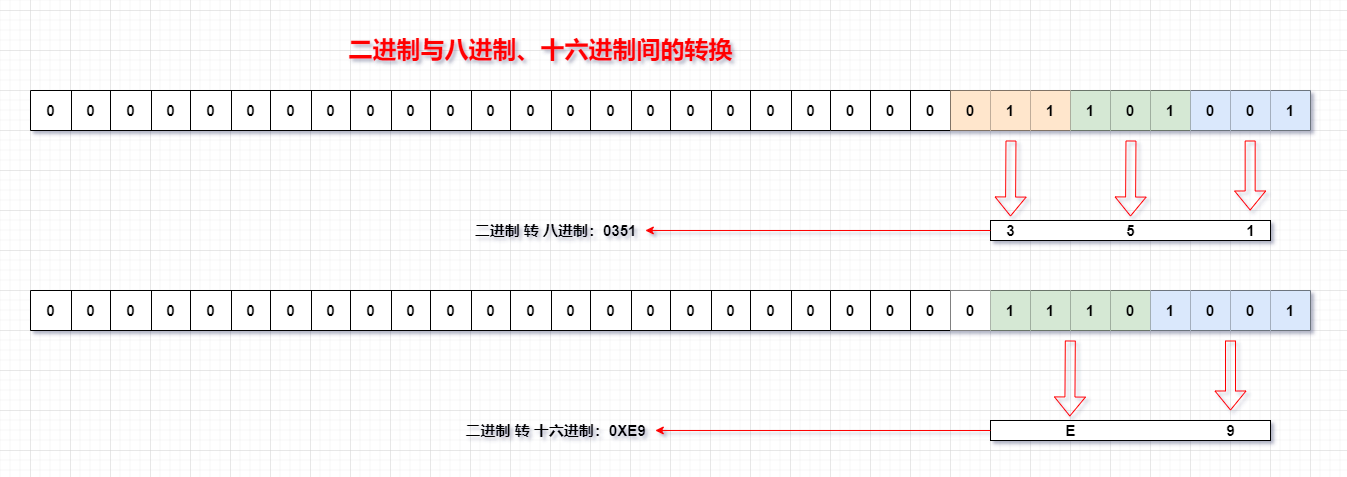
二進制與八進制、十六進制間的轉換:
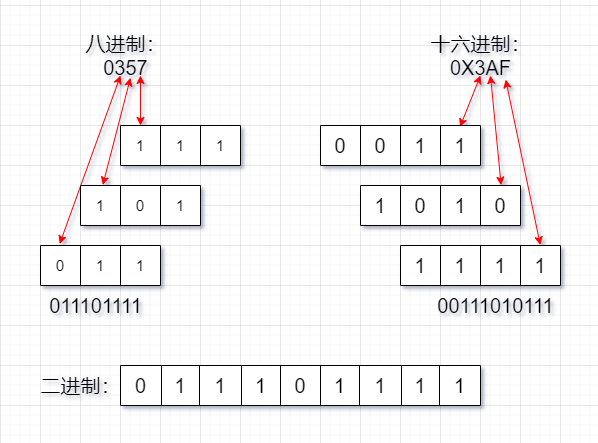
對應圖示:
6.Scanner類的使用
/*
如何從鍵盤獲取不同型別的變數:需要使用Scanner類
具體實作步驟:
1.導包:import java.util.Scanner;
2.Scanner的實體化:Scanner scan = new Scanner(System.in);
3.呼叫Scanner類的相關方法(next() / nextXxx()),來獲取指定型別的變數
注意:
需要根據相應的方法,來輸入指定型別的值,如果輸入的資料型別與要求的型別不匹配時,會報例外:InputMisMatchException
導致程式終止,
*/
//1.導包:import java.util.Scanner;
import java.util.Scanner;
class ScannerTest{
public static void main(String[] args){
//2.Scanner的實體化
Scanner scan = new Scanner(System.in);
//3.呼叫Scanner類的相關方法
System.out.println("請輸入你的姓名:");
String name = scan.next();
System.out.println(name);
System.out.println("請輸入你的芳齡:");
int age = scan.nextInt();
System.out.println(age);
System.out.println("請輸入你的體重:");
double weight = scan.nextDouble();
System.out.println(weight);
System.out.println("你是否相中我了呢?(true/false)");
boolean isLove = scan.nextBoolean();
System.out.println(isLove);
//對于char型的獲取,Scanner沒有提供相關的方法,只能獲取一個字串
System.out.println("請輸入你的性別:(男/女)");
String gender = scan.next();//"男"
char genderChar = gender.charAt(0);//獲取索引為0位置上的字符
System.out.println(genderChar);
}
}
二、關鍵字與識別符號
1.java關鍵字的使用
定義:被Java語言賦予了特殊含義,用做專門用途的字串(單詞)
特點:關鍵字中所字母都為小寫
| 用于定義資料型別的關鍵字: | ||||
|---|---|---|---|---|
| class | interface | enum | byte | short |
| int | long | float | double | char |
| boolean | void | |||
| 用于定義流程控制的關鍵字: | ||||
| if | else | switch | case | default |
| while | do | for | break | continue |
| return | ||||
| 用于定義訪問權限修飾符的關鍵字: | ||||
| private | protected | public |
| 用于定義類,函式,變數修飾符的關鍵字: | ||||
|---|---|---|---|---|
| abstract | final | static | synchronized | |
| 用于定義類與類之間的關鍵字: | ||||
| extends | implements | |||
| 用于定義建立實體及參考實體,判斷實體的關鍵字 | ||||
| new | this | super | instanceof | |
| 用于例外處理的關鍵字: | ||||
| try | catch | finally | throw | throws |
| 用于包的關鍵字 | ||||
| package | import | |||
| 其它修飾符關鍵字 | ||||
| native | strictfp | transient | volatile | assert |
| 用于定義資料型別值的字面值 | ||||
| true | false | null |
2.保留字
現Java版本尚未使用,但以后版本可能會作為關鍵字使用,
具體哪些保留字:goto 、const
注意:自己命名識別符號時要避免使用這些保留字
3.識別符號的使用
定義:凡是自己可以起名字的地方都叫識別符號,
涉及到的結構:
包名、類名、介面名、變數名、方法名、常量名
規則:(必須要遵守,否則,編譯不通過)
由 26 個 英 文 字 母 大 小 寫 , 0 . 9 , 一 或 $ 組 成
數 字 不 可 以 開 頭 ,
不 可 以 使 用 關 鍵 字 和 保 留 字 , 但 能 包 含 關 鍵 字 和 保 留 字 ,
Java 中 嚴 格 區 分 大 小 寫 , 長 度 無 限 制,
標 識 符 不 能 包 含 空 格 ,
規范:(可以不遵守,不影響編譯和運行,但是我要求自己遵守)
包名:多單詞組成時所有字母都小寫, xxxyyyzzz
類名、接囗名:多單詞組成時,所有單詞的首字母大寫:XxxYyyZzz
變數名、方法名:多單詞組成時,第一個單詞首字母小寫,第二個單詞開始每個
單詞首字母大寫:xxxYyyZzz
常量名:所有字毋都大寫:多單詞時每個單詞厙下劃線連接:XXX_YYY_ZZZ
注意:
在命名時,為了提高閱讀性,要盡量意義,“見名知意”,
4.代碼整潔之道
整理人:尚硅谷 - 宋紅康
第2章 有意義的命名
2.1 介紹
軟體中隨處可見命名,我們給變數、函式、引數、類和包命名,我們給源代碼及源代碼所在目錄命名,
這么多命名要做,不妨做好它,下文列出了取個好名字的幾條簡單規則,
2.2 名副其實,見名知意
變數名太隨意,haha、list1、ok、theList 這些都沒啥意義
2.3 避免誤導
包含List、import、java等類名、關鍵字或特殊字;
字母o與數字0,字母l與數字1等
提防使用不同之處較小的名稱,比如:XYZControllerForEfficientHandlingOfStrings與XYZControllerForEfficientStorageOfStrings
2.4 做有意義的區分
反面教材,變數名:a1、a2、a3
避免冗余,不要出現Variable、表欄位中避免出現table、字串避免出現nameString,直接name就行,知道是字串型別
再比如:定義了兩個類:Customer類和CustomerObject類,如何區分?
定義了三個方法:getActiveAccount()、getActiveAccounts()、getActiveAccountInfo(),如何區分?
2.5 使用讀得出來的名稱
不要使用自己拼湊出來的單詞,比如:xsxm(學生姓名);genymdhms(生成日期,年、月、日、時、分、秒)
所謂的駝峰命名法,盡量使用完整的單詞
2.6 使用可搜索的名稱
一些常量,最好不直接使用數字,而指定一個變數名,這個變數名可以便于搜索到.
比如:找MAX_CLASSES_PER_STUDENT很容易,但想找數字7就麻煩了,
2.7 避免使用編碼
2.7.1 匈牙利語標記法
即變數名表明該變數資料型別的小寫字母開始,例如,szCmdLine的前綴sz表示“以零結束的字串”,
2.7.2 成員前綴
避免使用前綴,但是Android中一個比較好的喜歡用m表示私有等,個人感覺比較好
2.7.3 介面和實作
作者不喜歡把介面使用I來開頭,實作也希望只是在后面添加Imp
2.8 避免思維映射
比如傳統上慣用單字母名稱做回圈計數器,所以就不要給一些非計數器的變數命名為:i、j、k等
2.9 類名
類名與物件名應該是名詞與名詞短語,如Customer、WikiPage、Account和AddressParser,避免使用Data或Info這樣的類名,
不能使動詞,比如:Manage、Process
2.10 方法名
方法名應當是動詞或者動詞短語,如postPayment、deletePage或save
2.11 別扮可愛
有的變數名叫haha、banana
別用eatMyShorts()表示abort()
2.12 每個概念對應一個詞
專案中同時出現controllers與managers,為什么不統一使用其中一種?
對于那些會用到你代碼的程式員,一以貫之的命名法簡直就是天降福音,
2.13 別用雙關語
有時可能使用add并不合適,比例insert、append,add表示完整的新添加的含義,
2.14 使用解決方案領域名稱
看代碼的都是程式員,所以盡量用那些計算機科學術語、演算法名、模式名、數學術語,
依據問題所涉領域來命名不算是聰明的做法,
2.15 使用源自所涉問題領域的名稱
如果不能用程式員熟悉的術語來給手頭的作業命名,就采用從所涉問題領域而來的名稱吧,
至少,負責維護代碼的程式員就能去請教領域專家了,
2.16 添加有意義的語境
可以把相關的變數放到一個類中,使用這個類來表明語境,
2.17 不要添加沒用的語境
名字中帶有專案的縮寫,這樣完全沒有必要,比如有一個名為“加油站豪華版”(Gas Station Deluxe)的專案,
在其中給每個類添加GSD前綴就不是什么好策略,
2.18 最后的話
取好名字最難的地方在于需要良好的描述技巧和共有文化背景,
三、回圈
1.回圈結構的四要素
① 初始化條件
② 回圈條件 --->是boolean型別
③ 回圈體
④ 迭代條件
說明:通常情況下,回圈結束都是因為②中回圈條件回傳false了,
2.三種回圈結構
for回圈結構
for(①;②;④){
③
}
執行程序:① - ② - ③ - ④ - ② - ③ - ④ - ... - ②
while回圈結構
①
while(②){
③;
④;
}
執行程序:① - ② - ③ - ④ - ② - ③ - ④ - ... - ②
說明:寫while回圈千萬小心不要丟了迭代條件,一旦丟了,就可能導致死回圈!
do-while回圈結構
①
do{
③;
④;
}while(②);
執行程序:① - ③ - ④ - ② - ③ - ④ - ... - ②
說明:
-
do-while回圈至少會執行一次回圈體!
-
開發中,使用for和while更多一些,較少使用do-while
-
“無限回圈”結構: while(true) 或 for(;??
總結
如何結束一個回圈結構?
方式一:當回圈條件是false時
方式二:在回圈體中,執行break
for和while回圈總結:
-
開發中,基本上我們都會從for、while中進行選擇,實作回圈結構,
-
for回圈和while回圈是可以相互轉換的!
-
我們寫程式,要避免出現死回圈,
區別:for回圈和while回圈的初始化條件部分的作用范圍不同,
3.嵌套回圈
嵌套回圈:將一個回圈結構A宣告在另一個回圈結構B的回圈體中,就構成了嵌套回圈
內層回圈:回圈結構A
外層回圈:回圈結構B
說明:
① 內層回圈結構遍歷一遍,只相當于外層回圈回圈體執行了一次
② 假設外層回圈需要執行m次,內層回圈需要執行n次,此時內層回圈的回圈體一共執行了m * n次
③ 外層回圈控制行數,內層回圈控制列數
【典型練習】
//練習一:
/*
******
******
******
******
*/
for(int j = 1;j <= 4;j++ ){
for(int i = 1;i <= 6;i++){
System.out.print('*');
}
System.out.println();
}
//練習二:
/* i(行號) j(*的個數)
* 1 1
** 2 2
*** 3 3
**** 4 4
***** 5 5
*/
for(int i = 1;i <= 5;i++){//控制行數
for(int j = 1;j <= i;j++){//控制列數
System.out.print("*");
}
System.out.println();
}
//練習三:九九乘法表
//練習四:100以內的質數
補充:衡量一個功能代碼的優劣:
-
正確性
-
可讀性
-
健壯性
-
高效率與低存盤:時間復雜度 、空間復雜度 (衡量演算法的好壞)
如何理解流程控制的練習:流程控制結構的使用 + 演算法邏輯,
4.分支結構
1.if-else條件判斷結構
結構一:
if(條件運算式){
執行運算式
}
結構二:二選一
if(條件運算式){
執行運算式1
}else{
執行運算式2
}
結構三:n選一
if(條件運算式){
執行運算式1
}else if(條件運算式){
執行運算式2
}else if(條件運算式){
執行運算式3
}
...
else{
執行運算式n
}
說明:
-
else 結構是可選的,
-
if-else結構是可以相互嵌套的,
-
如果if-else結構中的執行陳述句只有一行時,對應的一對{}可以省略的,但是,不建議大家省略,
-
針對于條件運算式:
如果多個條件運算式之間是“互斥”關系(或沒有交集的關系),哪個判斷和執行陳述句宣告在上面還是下面,無所謂,
如果多個條件運算式之間有交集的關系,需要根據實際情況,考慮清楚應該將哪個結構宣告在上面,
如果多個條件運算式之間有包含的關系,通常情況下,需要將范圍小的宣告在范圍大的上面,否則,范圍小的就沒機會執行了,
2.switch-case選擇結構
switch(運算式){
case 常量1:
執行陳述句1;
//break;
case 常量2:
執行陳述句2;
//break;
...
default:
執行陳述句n;
//break;
}
說明:
- 根據switch運算式中的值,依次匹配各個case中的常量,一旦匹配成功,則進入相應case結構中,呼叫其執行陳述句,
當呼叫完執行陳述句以后,則仍然繼續向下執行其他case結構中的執行陳述句,直到遇到break關鍵字或此switch-case結構
末尾結束為止,
-
break,可以使用在switch-case結構中,表示一旦執行到此關鍵字,就跳出switch-case結構
-
switch結構中的運算式,只能是如下的6種資料型別之一:
byte 、short、char、int、列舉型別(JDK5.0新增)、String型別(JDK7.0新增)
-
case 之后只能宣告常量,不能宣告范圍,
-
break關鍵字是可選的,
-
default:相當于if-else結構中的else,default結構是可選的,而且位置是靈活的,
-
如果switch-case結構中的多個case的執行陳述句相同,則可以考慮進行合并,
-
break在switch-case中是可選的
5.break和continue關鍵字的使用
| 關鍵字 | 使用范圍 | 回圈中使用的作用(不同點) | 相同點 |
|---|---|---|---|
| break: switch-case | 回圈結構中 | 結束當前回圈 | 關鍵字后面不能宣告執行陳述句 |
| continue: | 回圈結構中 | 結束當次回圈 | 關鍵字后面不能宣告執行陳述句 |
補充:帶標簽的break和continue的使用,
四、運算子
1.算術運算子
+ - + - * / % (前)++ (后)++ (前)-- (后)-- +
【典型代碼】
//除號:/
int num1 = 12;
int num2 = 5;
int result1 = num1 / num2;
System.out.println(result1);//2
// %:取余運算
//結果的符號與被模數的符號相同
//開發中,經常使用%來判斷能否被除盡的情況,
int m1 = 12;
int n1 = 5;
System.out.println("m1 % n1 = " + m1 % n1);
int m2 = -12;
int n2 = 5;
System.out.println("m2 % n2 = " + m2 % n2);
int m3 = 12;
int n3 = -5;
System.out.println("m3 % n3 = " + m3 % n3);
int m4 = -12;
int n4 = -5;
System.out.println("m4 % n4 = " + m4 % n4);
//(前)++ :先自增1,后運算
//(后)++ :先運算,后自增1
int a1 = 10;
int b1 = ++a1;
System.out.println("a1 = " + a1 + ",b1 = " + b1);
int a2 = 10;
int b2 = a2++;
System.out.println("a2 = " + a2 + ",b2 = " + b2);
int a3 = 10;
++a3;//a3++;
int b3 = a3;
//(前)-- :先自減1,后運算
//(后)-- :先運算,后自減1
int a4 = 10;
int b4 = a4--;//int b4 = --a4;
System.out.println("a4 = " + a4 + ",b4 = " + b4);
特別說明
-
(前)++ :先自增1,后運算
-
(后)++ :先運算,后自增1
-
(前)-- :先自減1,后運算
-
(后)-- :先運算,后自減1
-
連接符:+:只能使用在String與其他資料型別變數之間使用,
2.賦值運算子
= += -= *= /= %=
【典型代碼】
int i2,j2;
//連續賦值
i2 = j2 = 10;
//***************
int i3 = 10,j3 = 20;
int num1 = 10;
num1 += 2;//num1 = num1 + 2;
System.out.println(num1);//12
int num2 = 12;
num2 %= 5;//num2 = num2 % 5;
System.out.println(num2);
short s1 = 10;
//s1 = s1 + 2;//編譯失敗
s1 += 2;//結論:不會改變變數本身的資料型別
System.out.println(s1);
特別說明
- 運算的結果不會改變變數本身的資料型別
//開發中,如果希望變數實作+2的操作,有幾種方法?(前提:int num = 10;)
num = num + 2;//方式一
num += 2; //方式二(推薦)
//開發中,如果希望變數實作+1的操作,有幾種方法?(前提:int num = 10;)
num = num + 1;//方式一
num += 1;//方式二
num++;//方式三(推薦)
3.比較運算子
(關系運算子): == != > < >= <= instanceof
【典型代碼】
int i = 10;
int j = 20;
System.out.println(i == j);//false
System.out.println(i = j);//20
boolean b1 = true;
boolean b2 = false;
System.out.println(b2 == b1);//false
System.out.println(b2 = b1);//true
特別說明
-
比較運算子的結果是boolean型別
-
> < >= <=:只能使用在數值型別的資料之間, -
== 和 !=: 不僅可以使用在數值型別資料之間,還可以使用在其他參考型別變數之間,Account acct1 = new Account(1000); Account acct2 = new Account(1000); boolean b1 = (acct1 == acct2);//比較兩個Account是否是同一個賬戶, boolean b2 = (acct1 != acct2);//
4.邏輯運算子
& && | || ! ^
//區分& 與 &&
//相同點1:& 與 && 的運算結果相同
//相同點2:當符號左邊是true時,二者都會執行符號右邊的運算
//不同點:當符號左邊是false時,&繼續執行符號右邊的運算,&&不再執行符號右邊的運算,
//開發中,推薦使用&&
boolean b1 = true;
b1 = false;
int num1 = 10;
if(b1 & (num1++ > 0)){
System.out.println("我現在在北京");
}else{
System.out.println("我現在在南京");
}
System.out.println("num1 = " + num1);
boolean b2 = true;
b2 = false;
int num2 = 10;
if(b2 && (num2++ > 0)){
System.out.println("我現在在北京");
}else{
System.out.println("我現在在南京");
}
System.out.println("num2 = " + num2);
// 區分:| 與 ||
//相同點1:| 與 || 的運算結果相同
//相同點2:當符號左邊是false時,二者都會執行符號右邊的運算
//不同點3:當符號左邊是true時,|繼續執行符號右邊的運算,而||不再執行符號右邊的運算
//開發中,推薦使用||
boolean b3 = false;
b3 = true;
int num3 = 10;
if(b3 | (num3++ > 0)){
System.out.println("我現在在北京");
}else{
System.out.println("我現在在南京");
}
System.out.println("num3 = " + num3);
boolean b4 = false;
b4 = true;
int num4 = 10;
if(b4 || (num4++ > 0)){
System.out.println("我現在在北京");
}else{
System.out.println("我現在在南京");
}
System.out.println("num4 = " + num4);
特別說明
- 邏輯運算子操作的都是boolean型別的變數,而且結果也是boolean型別
5.位運算子
<< >> >>> & | ^ ~
【典型代碼】
int i = 21;
i = -21;
System.out.println("i << 2 :" + (i << 2));
System.out.println("i << 3 :" + (i << 3));
System.out.println("i << 27 :" + (i << 27));
int m = 12;
int n = 5;
System.out.println("m & n :" + (m & n));
System.out.println("m | n :" + (m | n));
System.out.println("m ^ n :" + (m ^ n));
面試題:你能否寫出最高效的2 * 8的實作方式?
答案:2 << 3 或 8 << 1
特別說明
-
位運算子操作的都是整型的資料
-
<<:在一定范圍內,每向左移1位,相當于 * 2 -
>>:在一定范圍內,每向右移1位,相當于 / 2
典型題目
- 交換兩個變數的值,
- 實作60的二進制到十六進制的轉換,
非(~)運算
非運算即取反運算,在二進制中1變0,0變1
110110進行非運算后為
001001即1001
6.三元運算子
(條件運算式)? 運算式1 : 運算式2
【典型代碼】
//獲取兩個整數的較大值
int m = 12;
int n = 5;
int max = (m > n)? m : n;
特別說明
-
條件運算式的結果為boolean型別
-
根據條件運算式真或假,決定執行運算式1,還是運算式2.
- 如果運算式為true,則執行運算式1,
- 如果運算式為false,則執行運算式2,
-
運算式1 和運算式2要求是一致的,
-
三元運算子可以嵌套使用
凡是可以使用三元運算子的地方,都可以改寫為if-else,反之,不成立,
如果程式既可以使用三元運算子,又可以使用if-else結構,那么優先選擇三元運算子,原因:簡潔、執行效率高,
五、陣列
1.一維陣列
-
陣列的理解:陣列(Array),是多個相同型別資料一定順序排列的集合,并使用一個名字命名,并通過編號的方式對這些資料進行統一管理,
-
陣列相關的概念:陣列名,元素,角標、下標、索引,陣列的長度:元素的個數
-
陣列的特點
-
陣列是序排列的
-
陣列屬于參考資料型別的變數,陣列的元素,既可以是基本資料型別,也可以是參考資料型別
-
創建陣列物件會在記憶體中開辟一整塊連續的空間
-
陣列的長度一旦確定,就不能修改,
-
-
陣列的分類
- 照維數:一維陣列、二維陣列、...
- 照陣列元素的型別:基本資料型別元素的陣列、參考資料型別元素的陣列
資料結構
- 資料與資料之間的邏輯關系:集合、一對一、一對多、多對多
資料的存盤結構
-
線性表:順序表(比如:陣列)、鏈表、堆疊、佇列
-
樹形結構:二叉樹
-
圖形結構:
演算法
排序演算法:
搜索演算法:
1.一維陣列的宣告與初始化
正確的方式:
int num;//宣告
num = 10;//初始化
int id = 1001;//宣告 + 初始化
int[] ids;//宣告
//1.1 靜態初始化:陣列的初始化和陣列元素的賦值操作同時進行
ids = new int[]{1001,1002,1003,1004};
//1.2動態初始化:陣列的初始化和陣列元素的賦值操作分開進行
String[] names = new String[5];
int[] arr4 = {1,2,3,4,5};//型別推斷
錯誤的方式:
int[] arr1 = new int[];
int[5] arr2 = new int[5];
int[] arr3 = new int[3]{1,2,3};
2.一維陣列元素的參考
通過角標的方式呼叫,
//陣列的角標(或索引從0開始的,到陣列的長度-1結束,
names[0] = "Gogo";
names[1] = "Tony";
names[2] = "Jenny";
names[3] = "Paul";
names[4] = "Mike";//charAt(0)
3.陣列的屬性:length
System.out.println(names.length);//5
System.out.println(ids.length);
說明:
陣列一旦初始化,其長度就是確定的,arr.length
陣列長度一旦確定,就不可修改,
4.一維陣列的遍歷
for(int i = 0;i < names.length;i++){
System.out.println(names[i]);
}
5.一維陣列元素的默認初始化值
-
陣列元素是整型:0
-
陣列元素是浮點型:0.0
-
陣列元素是char型:0或'\u0000',而非'0'
-
陣列元素是boolean型:false
-
陣列元素是參考資料型別:null
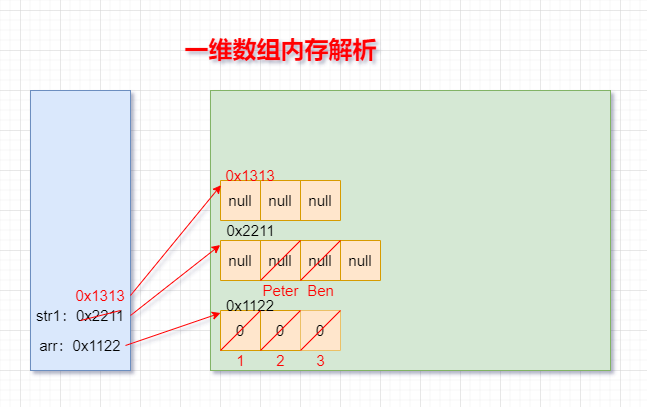
6.一維陣列的記憶體決議
int arr = new int[]{1,2,3};
String[] str1 = new String[4];
str1[1] = "Peter";
str1[2] = "Ben";
str1 = new String[3];
System.out.println(str[1]);//null
2.二維陣列
1.如何理解二維陣列?
陣列屬于參考資料型別
陣列的元素也可以是參考資料型別
一個一維陣列A的元素如果還是一個一維陣列型別的,則,此陣列A稱為二維陣列,
2.二維陣列的宣告與初始化
正確的方式:
int[] arr = new int[]{1,2,3};//一維陣列
//靜態初始化
int[][] arr1 = new int[][]{{1,2,3},{4,5},{6,7,8}};
//動態初始化1
String[][] arr2 = new String[3][2];
//動態初始化2
String[][] arr3 = new String[3][];
//也是正確的寫法:
int[] arr4[] = new int[][]{{1,2,3},{4,5,9,10},{6,7,8}};
int[] arr5[] = {{1,2,3},{4,5},{6,7,8}};//型別推斷
錯誤的方式:
String[][] arr4 = new String[][4];
String[4][3] arr5 = new String[][];
int[][] arr6 = new int[4][3]{{1,2,3},{4,5},{6,7,8}};
3.如何呼叫二維陣列元素
System.out.println(arr1[0][1]);//2
System.out.println(arr2[1][1]);//null
arr3[1] = new String[4];
System.out.println(arr3[1][0]);
System.out.println(arr3[0]);//
4.二維陣列的屬性
System.out.println(arr4.length);//3
System.out.println(arr4[0].length);//3
System.out.println(arr4[1].length);//4
5.遍歷二維陣列元素
for(int i = 0;i < arr4.length;i++){
for(int j = 0;j < arr4[i].length;j++){
System.out.print(arr4[i][j] + " ");
}
System.out.println();
}
6.二維陣列元素的默認初始化值
規定:二維陣列分為外層陣列的元素,內層陣列的元素
int[][] arr = new int[4][3];
外層元素:arr[0],arr[1]等
內層元素:arr[0][0],arr[1][2]等
陣列元素的默認初始化值
針對于初始化方式一:比如:int[][] arr = new int[4][3];
外層元素的初始化值為:地址值
內層元素的初始化值為:與一維陣列初始化情況相同
針對于初始化方式二:比如:int[][] arr = new int[4][];
外層元素的初始化值為:null
內層元素的初始化值為:不能呼叫,否則報錯,
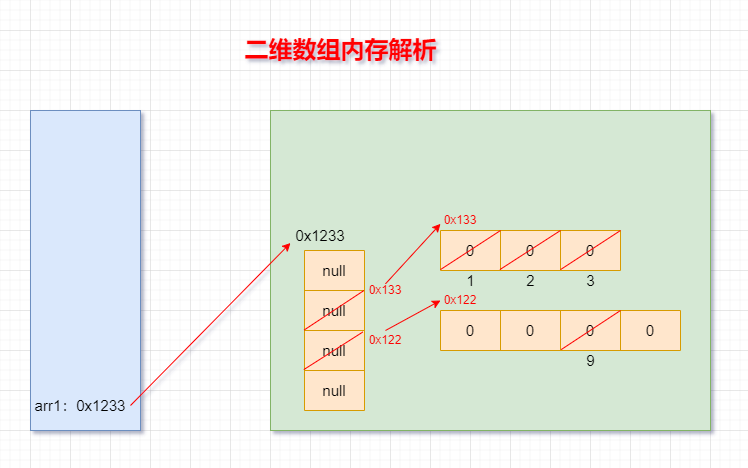
7.二維陣列的記憶體結構
int[][] arr1 = new int[4][];
arr[1] = new int[]{1,2,3};
arr1[2] = new int[4];
arr[2][2] = 9;
3.陣列常見的例外
1.陣列角標越界例外
ArrayIndexOutOfBoundsException
int[] arr = new int[]{1,2,3,4,5};
for(int i = 0;i <= arr.length;i++){
System.out.println(arr[i]);
}
System.out.println(arr[-2]);
System.out.println("hello");
2.空指標例外
NullPointerException
//情況一:
//int[] arr1 = new int[]{1,2,3};
//arr1 = null;
//System.out.println(arr1[0]);
//情況二:
//int[][] arr2 = new int[4][];
//System.out.println(arr2[0][0]);
//情況:
String[] arr3 = new String[]{"AA","BB","CC"};
arr3[0] = null;
System.out.println(arr3[0].toString());
小知識:一旦程式出現例外,未處理時,就終止執行,
4.陣列常見演算法
1.陣列的創建與元素賦值
楊輝三角(二維陣列)、回形數(二維陣列)、6個數,1-30之間隨機生成且不重復,
2.針對于數值型的陣列
最大值、最小值、總和、平均數等
3.陣列的賦值與復制
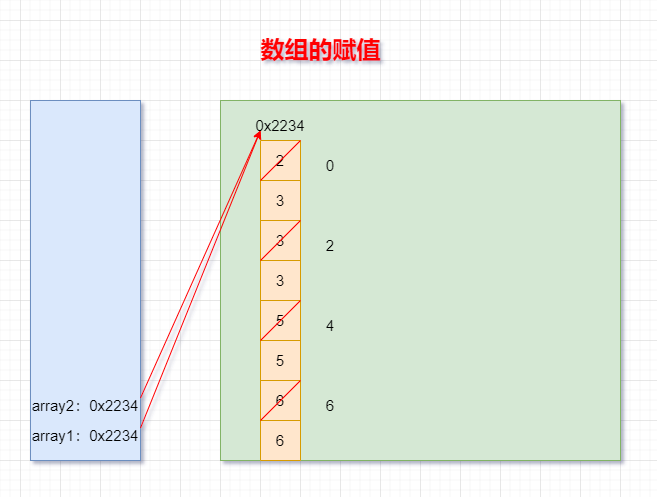
int[] array1,array2;
array1 = new int[]{2,3,3,3,5,5,6,6};
array2 = array1;
for(int i = 0; i < array2.length; i++){
if(i % 2 == 0){
array2[i] = i;
}
}
賦值:array2 = array1;
如何理解:將array1保存的陣列的地址值賦給了array2,使得array1和array2共同指向堆空間中的同一個陣列物體,
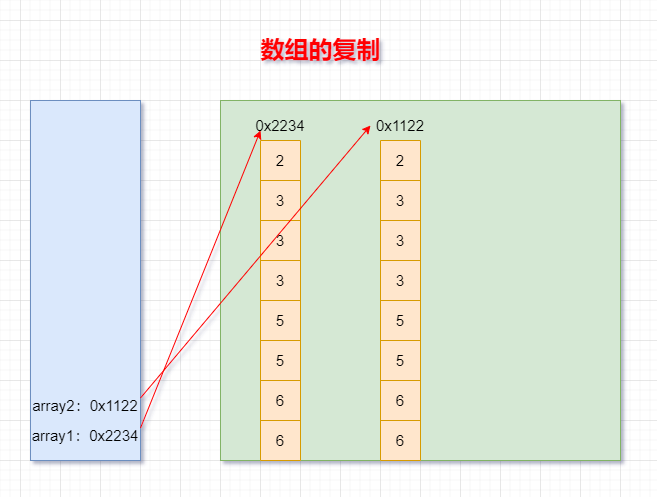
復制:
array2 = new int[array1.length];
for(int i = 0;i < array2.length;i++){
array2[i] = array1[i];
}
如何理解:我們通過new的方式,給array2在堆空間中新開辟了陣列的空間,將array1陣列中的元素值一個一個的賦值到array2陣列中,
4.陣列元素的反轉
//方法一:
for(int i = 0;i < arr.length / 2;i++){
String temp = arr[i];
arr[i] = arr[arr.length - i -1];
arr[arr.length - i -1] = temp;
}
//方法二:
for(int i = 0,j = arr.length - 1;i < j;i++,j--){
String temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
5.陣列中指定元素的查找:搜索、檢索
線性查找:
實作思路:通過遍歷的方式,一個一個的資料進行比較、查找,
適用性:具有普遍適用性,
二分法查找:
實作思路:每次比較中間值,折半的方式檢索,
適用性:(前提:陣列必須有序)
6.陣列的排序演算法
十大內部排序演算法
- 選擇排序
- 直接選擇排序
- 堆排序
- 交換排序
- 冒泡排序
- 快速排序
- 插入排序
- 直接插入排序
- 折半插入排序
- Shell排序
- 歸并排序
- 桶式排序
- 基數排序
理解:
-
衡量排序演算法的優劣:時間復雜度、空間復雜度、穩定性
-
排序的分類:內部排序 與 外部排序(需要借助于磁盤)
-
不同排序演算法的時間復雜度
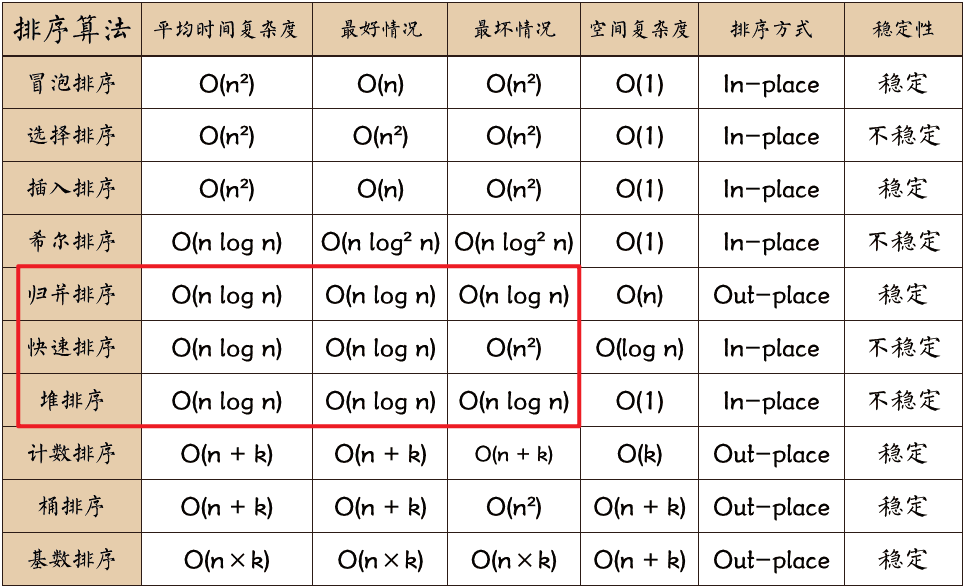
-
手寫冒泡排序
int[] arr = new int[]{43,32,76,-98,0,64,33,-21,32,99}; //冒泡排序 for (int i = 0; i < arr.length - 1; i++) { for (int j = 0; j < arr.length - 1 - i; j++) { if (arr[j] > arr[j + 1]) { int temp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = temp; } } }
5.Arrays工具類的使用
Arrays定義在java.util包下,Arrays提供了很多操作陣列的方法,
使用
//1.boolean equals(int[] a,int[] b):判斷兩個陣列是否相等,
int[] arr1 = new int[]{1,2,3,4};
int[] arr2 = new int[]{1,3,2,4};
boolean isEquals = Arrays.equals(arr1, arr2);
System.out.println(isEquals);
//2.String toString(int[] a):輸出陣列資訊,
System.out.println(Arrays.toString(arr1));
//3.void fill(int[] a,int val):將指定值填充到陣列之中,
Arrays.fill(arr1,10);
System.out.println(Arrays.toString(arr1));
//4.void sort(int[] a):對陣列進行排序,
Arrays.sort(arr2);
System.out.println(Arrays.toString(arr2));
//5.int binarySearch(int[] a,int key)
int[] arr3 = new int[]{-98,-34,2,34,54,66,79,105,210,333};
int index = Arrays.binarySearch(arr3, 210);
if (index >= 0) {
System.out.println(index);
} else {
System.out.println("未找到");
}
六、注釋與API檔案
1.注釋(comment)
單行注釋://
多行注釋:/* */
檔案注釋:/** */
作用:
-
對所寫的程式進行解釋說明,增強可讀性,方便自己,方便別人,
-
除錯所寫的代碼,
特點:
-
單行注釋和多行注釋,注釋了的內容不參與編譯,換句話說,編譯以后生成的.class結尾的位元組碼檔案中不包含注釋掉的資訊
-
注釋內容可以被JDK提供的工具 javadoc 所決議,生成一套以網頁檔案形式體現的該程式的說明檔案,
-
多行注釋不可以嵌套使用
2.Java API 檔案:
API:application programming interface,習慣上:將語言提供的類別庫,都稱為api,
API檔案:針對于提供的類別庫如何使用,給的一個說明書,類似于《新華字典》,
3.良好的編程風格
正確的注釋和注釋風格
-
使用檔案注釋來注釋整個類或整個方法
-
如果注釋方法中的某一個步驟,使用單行或多行注釋,
正確的縮進和空白
-
使用一次Tab操作,實作縮進
-
運算子兩邊習慣性加一個空格,比如:2 + 4 * 5,
塊的風格
Java API 源代碼選擇了行尾風格
//行尾風格
public class Test{
public static void main(String[] args){
System.out.println("Block Style!");
}
}
//次行風格
public class Test
{
public static void main(String[] args)
{
System.out.println("Block Style!");
}
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/426383.html
標籤:其他
下一篇:Stylelint跳過整個檔案夾