1、什么是 MongoDB
MongoDB 是一個基于分布式檔案存盤的資料庫,由 C++ 語言撰寫,旨在為 WEB 應用提供可擴展的高性能資料存盤解決方案,MongoDB 是一個介于關系資料庫和非關系資料庫之間的產品,是非關系資料庫當中功能最豐富,最像關系資料庫的,
MongoDB 將資料存盤為一個檔案,資料結構由鍵值(key=>value)對組成,MongoDB 檔案類似于 JSON 物件,欄位值可以包含其他檔案,陣列及檔案陣列,
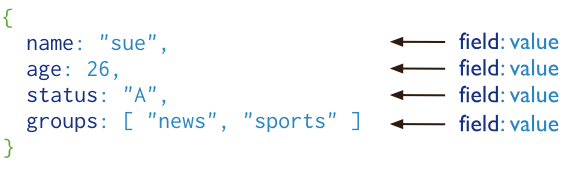
2、MongoDB 概念
2.1、資料庫
MongoDB 的單個實體可以容納多個獨立的資料庫,每個資料庫都有自己的集合和權限,
資料庫通過名字來標識;資料庫名為 UTF-8 字串,需滿足以下條件:
- 不能是空字串(""),
- 不得含有 ' '(空格)、.、$、/、\ 和 \0 (空字符),
- 應全部小寫,
- 最多 64 位元組,
內置資料庫:
- admin:管理資料庫,將一個用戶添加到這個資料庫,則這個用戶自動繼承所有資料庫的權限,一些特定的服務器端命令也只能從這個資料庫運行,比如關閉服務器,
- local:這個資料永遠不會被復制,可以用來存盤限于本地單臺服務器的集合,
- config:當 MongoDB 使用分片時,config 資料庫用于保存分片的相關資訊,
2.2、檔案(Document)
檔案是一組鍵值(key-value)對(即 BSON),MongoDB 的檔案不需要設定相同的欄位,并且相同的欄位不需要相同的資料型別,這與關系型資料庫有很大的區別,也是 MongoDB 非常突出的特點,一個簡單的檔案例子如下:
{"name":"李白", "age":30}
檔案有如下特性:
- 檔案中的鍵/值對是有序的,
- 檔案中的值不僅可以是在雙引號里面的字串,還可以是其他幾種資料型別(甚至可以是整個嵌入的檔案),
- MongoDB 區分型別和大小寫,
- MongoDB 的檔案不能有重復的鍵,
- 檔案的鍵是字串,除了少數例外情況,鍵可以使用任意 UTF-8 字符,
檔案鍵命名規范:
- 鍵不能含有\0 (空字符),這個字符用來表示鍵的結尾,
- .和$有特別的意義,只有在特定環境下才能使用,
- 以下劃線"_"開頭的鍵是保留的(不是嚴格要求的),
2.3、集合
集合就是檔案組,類似于關系資料庫中的表,集合沒有固定的結構,可以插入不同格式和型別的資料,但通常情況下我們插入集合的資料都會有一定的關聯性,
比如,我們可以將以下不同資料結構的檔案插入到同一集合中:
{"name":"杜甫", "age":29}
{"name":"李白", "age":30}
{"name":"白居易", "age":31, "height":175}
集合名的命名規范:
- 集合名不能是空字串"",
- 集合名不能含有\0字符(空字符),這個字符表示集合名的結尾,
- 集合名字不能含有保留字符;集合名中不要有$,
Capped collections 是固定大小的集合,當達到最大值時,它會自動覆寫最早的檔案,和標準的集合不同,你必須要顯式的創建一個 capped collection,指定一個集合的大小,單位是位元組,固定集合的資料存盤空間值提前分配的,固定集合不能洗掉一個檔案,可以使用 drop() 方法洗掉整個集合,
2.4、MondoDB 和 RDBMS 的對比
| RDBMS 術語/概念 | MongoDB 術語/概念 | 解釋/說明 |
|---|---|---|
| database | database | 資料庫 |
| table | collection | 資料庫表/集合 |
| row | document | 資料記錄行/檔案 |
| column | field | 資料欄位/域 |
| index | index | 索引 |
| table joins | $lookup | |
| primary key | primary key | 主鍵,MongoDB 自動將 _id 欄位設定為主鍵 |
| transaction | transaction | |
| group by | aggregation |
2.5、MondoDB 資料型別
| 資料型別 | 對應數字標識 | 別名 | 描述 | |
|---|---|---|---|---|
| Double | 1 | double | 雙精度浮點值, | |
| String | 2 | string | 字串,在 MongoDB 中,UTF-8 編碼的字串才是合法的, | |
| Object | 3 | object | 用于內嵌檔案 | |
| Array | 4 | array | 陣列 | |
| Binary data | 5 | binData | 二進制資料 | |
| Undefined | 6 | undefined | 已過時 | |
| ObjectId | 7 | objectId | 物件 ID | |
| Boolean | 8 | bool | 布林值 | |
| Date | 9 | date | 日期 | |
| Null | 10 | null | 空值 | |
| Regular Expression | 11 | regex | 正則運算式 | |
| DBPointer | 12 | dbPointer | 已過時 | |
| JavaScript | 13 | javascript | JavaScript 代碼 | |
| Symbol | 14 | symbol | 符號,已過時 | |
| JavaScript code with scope | 15 | javascriptWithScope | 已過時 | |
| 32-bit integer | 16 | int | 整形 | |
| Timestamp | 17 | timestamp | 時間戳 | |
| 64-bit integer | 18 | long | 長整型 | |
| Decimal128 | 19 | decimal | 浮點型,3.4 中新增 | |
| Min key | -1 | minKey | 最小 key,主要是內部使用 | |
| Max key | 127 | maxKey | 最大 key,主要是內部使用 |
下面介紹幾個重要的資料型別,
2.5.1、ObjectId
ObjectId 類似唯一主鍵,可以很快的生成和排序,包含 12 bytes:
- 前 4 個位元組表示 unix 時間戳,格林尼治時間 UTC 時間,比北京時間晚 8 小時
- 接下來的 3 個位元組是機器標識碼
- 緊接的兩個位元組由行程 id 組成 PID
- 最后三個位元組是亂數

MongoDB 中的檔案必須有一個 _id 鍵,這個鍵的值可以是任何型別,默認是 ObjectId 物件,由于 ObjectId 中保存了創建的時間戳,所以不需要為檔案保存時間戳欄位,可以通過 getTimestamp 函式來獲取檔案的創建時間:
> var newObject = ObjectId() > newObject.getTimestamp() ISODate("2022-01-07T01:45:50Z")
2.5.2、字串
字串都是 UTF-8 編碼,
2.5.3、時間戳
時間戳型別用于 MongoDB 內部使用,與普通的日期型別不相關;時間戳值是一個 64 位的值:
- 前32位是一個 time_t 值(與 Unix 新紀元相差的秒數)
- 后32位是在某秒中操作的一個遞增的序數
在單個 mongod 實體中,時間戳值通常是唯一的,
2.5.4、日期
表示當前距離 Unix 新紀元(1970年1月1日)的毫秒數,日期型別是有符號的,負數表示 1970 年之前的日期,
> var mydate1 = new Date() > mydate1 ISODate("2022-01-07T02:26:33.011Z") > > var mydate2 = ISODate() > mydate2 ISODate("2022-01-07T02:26:47.088Z")
3、MongoDB 架構模式
3.1、單機模式
該模式只安裝一個節點,一般用于測驗學習,
3.2、Master-Slave 模式
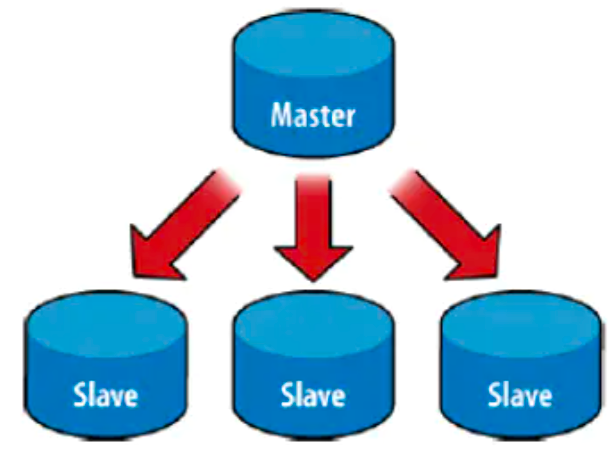
主從架構一般用于備份或者做讀寫分離,一般有一主一從設計和一主多從設計,由兩種角色構成:
主(Master):可讀可寫,當資料有修改的時候,會將 oplog 同步到所有的 Salve 上去,
從(Slave):只讀,從 Master 同步資料,
注:新版的 MongoDB 已經不支持這種模式了,
3.3、Replica Set 模式
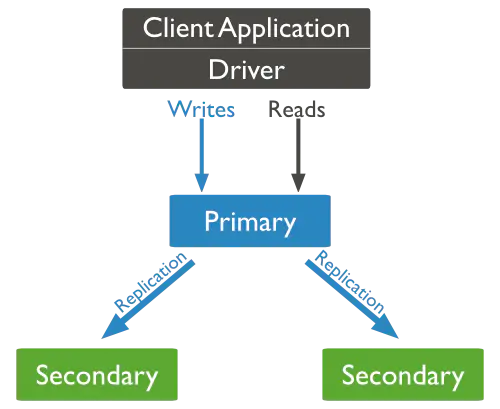
Replica Set 提供了資料的冗余備份,在多個服務器上存盤資料副本,提高了資料的可用性, 保證了資料的安全性,Replica Set 包含三類角色:
(1)主節點(Primary)
接收所有的寫請求,然后把修改同步到所有 Secondary,一個 Replica Set 只能有一個 Primary 節點,當 Primary 掛掉后,其他 Secondary 或者 Arbiter 節點會重新選舉一個主節點,默認讀請求也發到Primary 節點處理,如果需要發到 Secondary 可修改下客戶端的連接配置,
(2)副本節點(Secondary)
與主節點保持同樣的資料集,當主節點掛掉的時候,參與選主,
(3)仲裁者(Arbiter)
不保存資料,不參與選主,只進行選主投票,使用 Arbiter 可以減輕資料存盤的硬體需求,
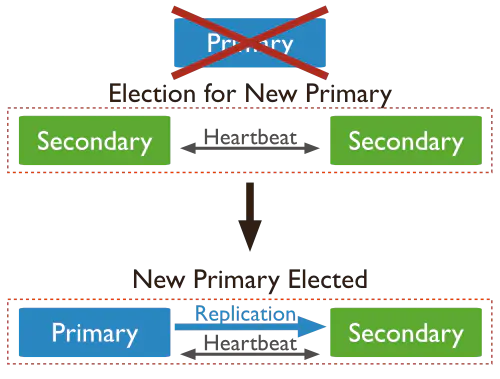
Replica Set 中 Secondary 宕機,不受影響,若 Primary 宕機,會重新選主:
3.3、Sharding 模式
3.3.1、分片架構
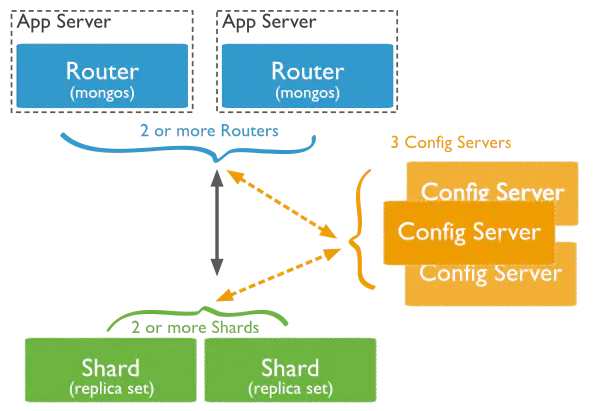
在 MongoDB 中存在另一種集群,就是分片技術,通過在多臺機器上分片存盤資料,可以滿足 MongoDB 資料量大量增長的需求,分片技術中包含的組件:
A.資料分片(Shards):用來存資料,可以是一個單獨的mongod實體,也可以是一個副本集,生產環境下 Shard 一般是一個Replica Set,防止該資料片的單點故障,
B.路由(Routers):前端路由,客戶端由此接入,讓整個集群看上去像單一資料庫,應用可以透明使用,路由為 mongos實體,一個 Sharding 集群,可以有一個 mongos,也可以有多 mongos 以減輕客戶端請求的壓力,
C.配置服務器(Config Servers):保存集群的元資料資訊(路由、分片),它也是一個副本集,
Sharding 分片技術高可用的架構圖如下:
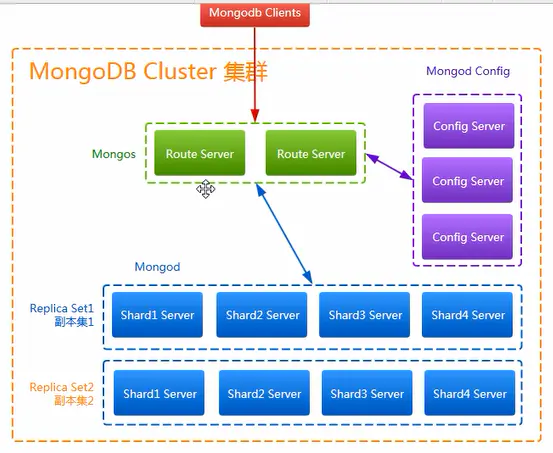
3.3.2、分片演算法
基于分片切分后的資料塊稱為 chunk,一個分片后的集合會包含多個 chunk,每個 chunk 位于哪個分片(Shard) 記錄在 Config Server(配置服務器)上,Mongos 在操作分片集合時,會自動根據分片鍵找到對應的 chunk,并向該 chunk 所在的分片發起操作請求,
資料是根據分片策略來進行切分的,分片策略由分片鍵(ShardKey)+分片演算法(ShardStrategy)組成,MongoDB 支持兩種分片策略:
- 范圍分片
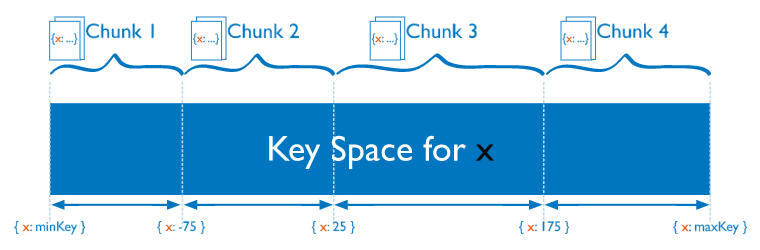
如上圖所示,假設集合根據 x 欄位來分片,x 的取值范圍為[minKey, maxKey],將整個取值范圍劃分為多個 chunk,每個 chunk(默認配置為64MB)包含其中一小段的資料:如 Chunk1 包含 x 的取值在[minKey, -75)的所有檔案,而 Chunk2 包含x取值在 [-75, 25) 之間的所有檔案,Chunk3、Chunk4 依次類推,
范圍分片能很好的滿足范圍查詢的需求,比如想查詢 x 的值在[-30, 10]之間的所有檔案,這時 Mongos 直接能將請求路由到 Chunk2,就能查詢出所有符合條件的檔案, 范圍分片的缺點在于,如果 ShardKey 有明顯遞增(或者遞減)趨勢,則新插入的檔案多會分布到同一個 chunk,無法擴展寫的能力,比如使用 _id 作為 ShardKey,而 MongoDB 自動生成的 id 高位是時間戳,是持續遞增的,
- 哈希分片
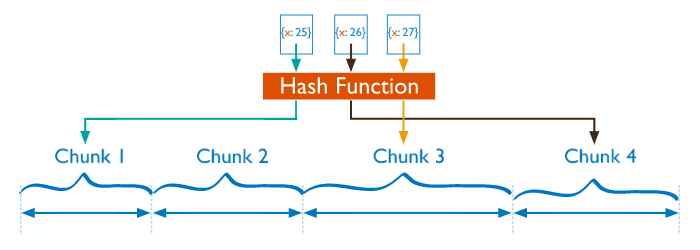
Hash 分片是根據用戶的 ShardKey 先計算出 hash 值(64bit整型),再根據 hash 值按照范圍分片的策略將檔案分布到不同的 chunk,由于 hash 值的計算是隨機的,因此 Hash 分片具有很好的離散性,可以將資料隨機分發到不同的 chunk 上, Hash 分片可以充分的擴展寫能力,彌補了范圍分片的不足,但不能高效的服務范圍查詢,所有的范圍查詢要查詢多個 chunk 才能找出滿足條件的檔案,
3.3.3、分片均衡
資料是分布在不同的 chunk上的,而 chunk 則會分配到不同的分片上,那么如何保證分片上的資料(chunk) 是均衡的?有如下兩種情況:
A. 全預分配,chunk 的數量和 shard 都是預先定義好的,比如 10 個shard,存盤 1000 個 chunk,那么每個 shard 分別擁有100個 chunk,此時集群已經是均衡的狀態(這里假定),
B. 非預分配,這種情況則比較復雜,一般當一個 chunk 太大時會產生分裂(split),不斷分裂的結果會導致不均衡;或者動態擴容增加分片時,也會出現不均衡的狀態, 這種不均衡的狀態由集群均衡器進行檢測,一旦發現了不均衡則執行 chunk 資料的搬遷達到均衡,
MongoDB 的資料均衡器運行于 Primary Config Server(配置服務器的主節點)上,而該節點也同時會控制 Chunk 資料的搬遷,
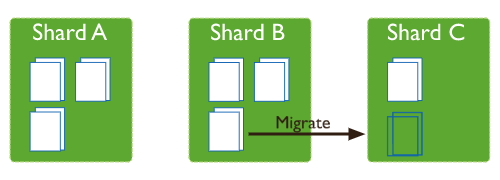
對于資料的不均衡是根據兩個分片上的 Chunk 個數差異來判定的,閾值對應表如下:
| Number of Chunks | Migration Threshold |
|---|---|
| Fewer than 20 | 2 |
| 20-79 | 4 |
| 80 and greater | 8 |
MongoDB 的資料遷移對集群性能存在一定影響,這點無法避免,目前的規避手段只能是將均衡時間放到業務閑時段,
4、MongoDB 用戶管理
在 MongoDB 里面用戶是屬于資料庫的,不同的資料庫可以擁有不同的用戶,用戶通過角色來控制權限,角色也是與資料庫關聯的;設定角色時需要同時設定對應的資料庫,MongoDB 中內置了一些角色:
1.Database User Roles(資料庫用戶角色)
Read:允許從指定資料庫讀資料
readWrite:允許從指定資料庫讀寫資料
2.Database Administration Roles(資料庫管理角色)
dbAdmin:資料庫管理功能
dbOwner: 該角色是 readWrite, dbAdmin 和 userAdmin 三個角色的集合
userAdmin:在當前資料庫上創建、修改角色和用戶
3.Cluster Administration Roles(集群管理角色)
clusterAdmin:該角色是 clusterManager, clusterMonitor 和 hostManager 三個角色的集合
clusterManager:提供管理和監視的權限
clusterMonitor:提供只讀的監視的權限
hostManager:提供監視和管理服務器的權限
4.Backup and Restoration Roles(備份恢復角色)
backup:備份
restore:還原資料
5.All-Database Roles(針對所有資料庫的角色,除了 local 和 config 資料庫)
readAnyDatabase:從所有資料(除了 local 和 config)讀取資料
readWriteAnyDatabase:從所有資料(除了 local 和 config)讀寫取資料
userAdminAnyDatabase:對所有資料(除了 local 和 config)提供與 userAdmin 一樣的權限
dbAdminAnyDatabase:對所有資料(除了 local 和 config)提供與 dbAdmin 一樣的權限
6.Superuser Roles(超級角色)
root:擁有任何資料庫的任何權限
7.Internal Role
__system:對資料庫中的任何物件具有任何操作的權限
創建用戶方法如下:
db.createUser({ user: 'test', pwd: '123456', roles:[{ role: 'readWrite', db: 'test' }] })
如需啟用權限認證,可在 MongoDB 啟動時增加 --auth 引數,
參考:
https://www.runoob.com/mongodb/mongodb-tutorial.html
https://www.cnblogs.com/littleatp/p/11675233.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/428444.html
標籤:Java
上一篇:java中的代碼塊(初始化塊)