Go語言中的并發編程——并發是編程里面一個非常重要的概念,Go語言在語言層面天生支持并發,這也是Go語言流行的一個很重要的原因,
并發與并行
并發:同一時間段內執行多個任務(你在用微信和兩個女朋友聊天),
并行:同一時刻執行多個任務(你和你朋友都在用微信和女朋友聊天),
Go語言的并發通過goroutine實作,goroutine類似于執行緒,屬于用戶態的執行緒,我們可以根據需要創建成千上萬個goroutine并發作業,goroutine是由Go語言的運行時(runtime)調度完成,而執行緒是由作業系統調度完成,
Go語言還提供channel在多個goroutine間進行通信,goroutine和channel是 Go 語言秉承的 CSP(Communicating Sequential Process)并發模式的重要實作基礎,
goroutine
在java/c++中我們要實作并發編程的時候,我們通常需要自己維護一個執行緒池,并且需要自己去包裝一個又一個的任務,同時需要自己去調度執行緒執行任務并維護背景關系切換,這一切通常會耗費程式員大量的心智,那么能不能有一種機制,程式員只需要定義很多個任務,讓系統去幫助我們把這些任務分配到CPU上實作并發執行呢?
Go語言中的goroutine就是這樣一種機制,goroutine的概念類似于執行緒,但 goroutine是由Go的運行時(runtime)調度和管理的,Go程式會智能地將 goroutine 中的任務合理地分配給每個CPU,Go語言之所以被稱為現代化的編程語言,就是因為它在語言層面已經內置了調度和背景關系切換的機制,
在Go語言編程中你不需要去自己寫行程、執行緒、協程,你的技能包里只有一個技能–goroutine,當你需要讓某個任務并發執行的時候,你只需要把這個任務包裝成一個函式,開啟一個goroutine去執行這個函式就可以了,就是這么簡單粗暴,
使用goroutine
Go語言中使用goroutine非常簡單,只需要在呼叫函式的時候在前面加上go關鍵字,就可以為一個函式創建一個goroutine,
一個goroutine必定對應一個函式,可以創建多個goroutine去執行相同的函式,
啟動單個goroutine
啟動goroutine的方式非常簡單,只需要在呼叫的函式(普通函式和匿名函式)前面加上一個go關鍵字,
舉個例子如下:
func hello() {
fmt.Println("Hello Goroutine!")
}
func main() {
hello()
fmt.Println("main goroutine done!")
}
這個示例中hello函式和下面的陳述句是串行的,執行的結果是列印完Hello Goroutine!后列印main goroutine done!,
接下來我們在呼叫hello函式前面加上關鍵字go,也就是啟動一個goroutine去執行hello這個函式,
func main() {
go hello() // 啟動另外一個goroutine去執行hello函式
fmt.Println("main goroutine done!")
}
這一次的執行結果只列印了main goroutine done!,并沒有列印Hello Goroutine!,為什么呢?
在程式啟動時,Go程式就會為main()函式創建一個默認的goroutine,
當main()函式回傳的時候該goroutine就結束了,所有在main()函式中啟動的goroutine會一同結束,main函式所在的goroutine就像是權利的游戲中的夜王,其他的goroutine都是異鬼,夜王一死它轉化的那些異鬼也就全部GG了,
所以我們要想辦法讓main函式等一等hello函式,最簡單粗暴的方式就是time.Sleep了,
func main() {
go hello() // 啟動另外一個goroutine去執行hello函式
fmt.Println("main goroutine done!")
time.Sleep(time.Second)
}
執行上面的代碼你會發現,這一次先列印main goroutine done!,然后緊接著列印Hello Goroutine!,
首先為什么會先列印main goroutine done!是因為我們在創建新的goroutine的時候需要花費一些時間,而此時main函式所在的goroutine是繼續執行的,
啟動多個goroutine
在Go語言中實作并發就是這樣簡單,我們還可以啟動多個goroutine,讓我們再來一個例子: (這里使用了sync.WaitGroup來實作goroutine的同步)
var wg sync.WaitGroup
func hello(i int) {
defer wg.Done() // goroutine結束就登記-1
fmt.Println("Hello Goroutine!", i)
}
func main() {
for i := 0; i < 10; i++ {
wg.Add(1) // 啟動一個goroutine就登記+1
go hello(i)
}
wg.Wait() // 等待所有登記的goroutine都結束
}
多次執行上面的代碼,會發現每次列印的數字的順序都不一致,這是因為10個goroutine是并發執行的,而goroutine的調度是隨機的,
goroutine與執行緒
可增長的堆疊
OS執行緒(作業系統執行緒)一般都有固定的堆疊記憶體(通常為2MB),一個goroutine的堆疊在其生命周期開始時只有很小的堆疊(典型情況下2KB),goroutine的堆疊不是固定的,他可以按需增大和縮小,goroutine的堆疊大小限制可以達到1GB,雖然極少會用到這個大,所以在Go語言中一次創建十萬左右的goroutine也是可以的,
goroutine調度
GPM是Go語言運行時(runtime)層面的實作,是go語言自己實作的一套調度系統,區別于作業系統調度OS執行緒,
G很好理解,就是個goroutine的,里面除了存放本goroutine資訊外 還有與所在P的系結等資訊,P管理著一組goroutine佇列,P里面會存盤當前goroutine運行的背景關系環境(函式指標,堆疊地址及地址邊界),P會對自己管理的goroutine佇列做一些調度(比如把占用CPU時間較長的goroutine暫停、運行后續的goroutine等等)當自己的佇列消費完了就去全域佇列里取,如果全域佇列里也消費完了會去其他P的佇列里搶任務,M(machine)是Go運行時(runtime)對作業系統內核執行緒的虛擬, M與內核執行緒一般是一一映射的關系, 一個groutine最終是要放到M上執行的;
P與M一般也是一一對應的,他們關系是: P管理著一組G掛載在M上運行,當一個G長久阻塞在一個M上時,runtime會新建一個M,阻塞G所在的P會把其他的G 掛載在新建的M上,當舊的G阻塞完成或者認為其已經死掉時 回收舊的M,
P的個數是通過runtime.GOMAXPROCS設定(最大256),Go1.5版本之后默認為物理執行緒數, 在并發量大的時候會增加一些P和M,但不會太多,切換太頻繁的話得不償失,
單從執行緒調度講,Go語言相比起其他語言的優勢在于OS執行緒是由OS內核來調度的,goroutine則是由Go運行時(runtime)自己的調度器調度的,這個調度器使用一個稱為m:n調度的技術(復用/調度m個goroutine到n個OS執行緒), 其一大特點是goroutine的調度是在用戶態下完成的, 不涉及內核態與用戶態之間的頻繁切換,包括記憶體的分配與釋放,都是在用戶態維護著一塊大的記憶體池, 不直接呼叫系統的malloc函式(除非記憶體池需要改變),成本比調度OS執行緒低很多, 另一方面充分利用了多核的硬體資源,近似的把若干goroutine均分在物理執行緒上, 再加上本身goroutine的超輕量,以上種種保證了go調度方面的性能,
點我了解更多
GOMAXPROCS
Go運行時的調度器使用GOMAXPROCS引數來確定需要使用多少個OS執行緒來同時執行Go代碼,默認值是機器上的CPU核心數,例如在一個8核心的機器上,調度器會把Go代碼同時調度到8個OS執行緒上(GOMAXPROCS是m:n調度中的n),
Go語言中可以通過runtime.GOMAXPROCS()函式設定當前程式并發時占用的CPU邏輯核心數,
Go1.5版本之前,默認使用的是單核心執行,Go1.5版本之后,默認使用全部的CPU邏輯核心數,
我們可以通過將任務分配到不同的CPU邏輯核心上實作并行的效果,這里舉個例子:
func a() {
for i := 1; i < 10; i++ {
fmt.Println("A:", i)
}
}
func b() {
for i := 1; i < 10; i++ {
fmt.Println("B:", i)
}
}
func main() {
runtime.GOMAXPROCS(1)
go a()
go b()
time.Sleep(time.Second)
}
兩個任務只有一個邏輯核心,此時是做完一個任務再做另一個任務, 將邏輯核心數設為2,此時兩個任務并行執行,代碼如下,
func a() {
for i := 1; i < 10; i++ {
fmt.Println("A:", i)
}
}
func b() {
for i := 1; i < 10; i++ {
fmt.Println("B:", i)
}
}
func main() {
runtime.GOMAXPROCS(2)
go a()
go b()
time.Sleep(time.Second)
}
Go語言中的作業系統執行緒和goroutine的關系:
- 一個作業系統執行緒對應用戶態多個goroutine,
- go程式可以同時使用多個作業系統執行緒,
- goroutine和OS執行緒是多對多的關系,即m:n,
channel
單純地將函式并發執行是沒有意義的,函式與函式間需要交換資料才能體現并發執行函式的意義,
雖然可以使用共享記憶體進行資料交換,但是共享記憶體在不同的goroutine中容易發生競態問題,為了保證資料交換的正確性,必須使用互斥量對記憶體進行加鎖,這種做法勢必造成性能問題,
Go語言的并發模型是CSP(Communicating Sequential Processes),提倡通過通信共享記憶體而不是通過共享記憶體而實作通信,
如果說goroutine是Go程式并發的執行體,channel就是它們之間的連接,channel是可以讓一個goroutine發送特定值到另一個goroutine的通信機制,
Go 語言中的通道(channel)是一種特殊的型別,通道像一個傳送帶或者佇列,總是遵循先入先出(First In First Out)的規則,保證收發資料的順序,每一個通道都是一個具體型別的導管,也就是宣告channel的時候需要為其指定元素型別,
channel型別
channel是一種型別,一種參考型別,宣告通道型別的格式如下:
var 變數 chan 元素型別
舉幾個例子:
var ch1 chan int // 宣告一個傳遞整型的通道 var ch2 chan bool // 宣告一個傳遞布爾型的通道 var ch3 chan []int // 宣告一個傳遞int切片的通道
創建channel
通道是參考型別,通道型別的空值是nil,
var ch chan int fmt.Println(ch) // <nil>
宣告的通道后需要使用make函式初始化之后才能使用,
創建channel的格式如下:
make(chan 元素型別, [緩沖大小])
channel的緩沖大小是可選的,
舉幾個例子:
ch4 := make(chan int) ch5 := make(chan bool) ch6 := make(chan []int)
channel操作
通道有發送(send)、接收(receive)和關閉(close)三種操作,
發送和接收都使用<-符號,
現在我們先使用以下陳述句定義一個通道:
ch := make(chan int)
發送
將一個值發送到通道中,
ch <- 10 // 把10發送到ch中
接收
從一個通道中接收值,
x := <- ch // 從ch中接收值并賦值給變數x <-ch // 從ch中接收值,忽略結果
關閉
我們通過呼叫內置的close函式來關閉通道,
close(ch)
關于關閉通道需要注意的事情是,只有在通知接收方goroutine所有的資料都發送完畢的時候才需要關閉通道,通道是可以被垃圾回識訓制回收的,它和關閉檔案是不一樣的,在結束操作之后關閉檔案是必須要做的,但關閉通道不是必須的,
關閉后的通道有以下特點:
- 對一個關閉的通道再發送值就會導致panic,
- 對一個關閉的通道進行接識訓一直獲取值直到通道為空,
- 對一個關閉的并且沒有值的通道執行接收操作會得到對應型別的零值,
- 關閉一個已經關閉的通道會導致panic,
無緩沖的通道
無緩沖的通道又稱為阻塞的通道,我們來看一下下面的代碼:
func main() {
ch := make(chan int)
ch <- 10
fmt.Println("發送成功")
}
上面這段代碼能夠通過編譯,但是執行的時候會出現以下錯誤:
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan send]:
main.main()
.../src/github.com/Q1mi/studygo/day06/channel02/main.go:8 +0x54
為什么會出現deadlock錯誤呢?
因為我們使用ch := make(chan int)創建的是無緩沖的通道,無緩沖的通道只有在有人接收值的時候才能發送值,就像你住的小區沒有快遞柜和代收點,快遞員給你打電話必須要把這個物品送到你的手中,簡單來說就是無緩沖的通道必須有接收才能發送,
上面的代碼會阻塞在ch <- 10這一行代碼形成死鎖,那如何解決這個問題呢?
一種方法是啟用一個goroutine去接收值,例如:
func recv(c chan int) {
ret := <-c
fmt.Println("接收成功", ret)
}
func main() {
ch := make(chan int)
go recv(ch) // 啟用goroutine從通道接收值
ch <- 10
fmt.Println("發送成功")
}
無緩沖通道上的發送操作會阻塞,直到另一個goroutine在該通道上執行接收操作,這時值才能發送成功,兩個goroutine將繼續執行,相反,如果接收操作先執行,接收方的goroutine將阻塞,直到另一個goroutine在該通道上發送一個值,
使用無緩沖通道進行通信將導致發送和接收的goroutine同步化,因此,無緩沖通道也被稱為同步通道,
有緩沖的通道
解決上面問題的方法還有一種就是使用有緩沖區的通道,我們可以在使用make函式初始化通道的時候為其指定通道的容量,例如:
func main() {
ch := make(chan int, 1) // 創建一個容量為1的有緩沖區通道
ch <- 10
fmt.Println("發送成功")
}
只要通道的容量大于零,那么該通道就是有緩沖的通道,通道的容量表示通道中能存放元素的數量,就像你小區的快遞柜只有那么個多格子,格子滿了就裝不下了,就阻塞了,等到別人取走一個快遞員就能往里面放一個,
我們可以使用內置的len函式獲取通道內元素的數量,使用cap函式獲取通道的容量,雖然我們很少會這么做,
for range從通道回圈取值
當向通道中發送完資料時,我們可以通過close函式來關閉通道,
當通道被關閉時,再往該通道發送值會引發panic,從該通道里接收的值一直都是型別零值,那如何判斷一個通道是否被關閉了呢?
我們來看下面這個例子:
// channel 練習
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
// 開啟goroutine將0~100的數發送到ch1中
go func() {
for i := 0; i < 100; i++ {
ch1 <- i
}
close(ch1)
}()
// 開啟goroutine從ch1中接收值,并將該值的平方發送到ch2中
go func() {
for {
i, ok := <-ch1 // 通道關閉后再取值ok=false
if !ok {
break
}
ch2 <- i * i
}
close(ch2)
}()
// 在主goroutine中從ch2中接收值列印
for i := range ch2 { // 通道關閉后會退出for range回圈
fmt.Println(i)
}
}
從上面的例子中我們看到有兩種方式在接收值的時候判斷該通道是否被關閉,不過我們通常使用的是for range的方式,使用for range遍歷通道,當通道被關閉的時候就會退出for range,
單向通道
有的時候我們會將通道作為引數在多個任務函式間傳遞,很多時候我們在不同的任務函式中使用通道都會對其進行限制,比如限制通道在函式中只能發送或只能接收,
Go語言中提供了單向通道來處理這種情況,例如,我們把上面的例子改造如下:
func counter(out chan<- int) {
for i := 0; i < 100; i++ {
out <- i
}
close(out)
}
func squarer(out chan<- int, in <-chan int) {
for i := range in {
out <- i * i
}
close(out)
}
func printer(in <-chan int) {
for i := range in {
fmt.Println(i)
}
}
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
go counter(ch1)
go squarer(ch2, ch1)
printer(ch2)
}
其中,
chan<- int是一個只寫單向通道(只能對其寫入int型別值),可以對其執行發送操作但是不能執行接收操作;<-chan int是一個只讀單向通道(只能從其讀取int型別值),可以對其執行接收操作但是不能執行發送操作,
在函式傳參及任何賦值操作中可以將雙向通道轉換為單向通道,但反過來是不可以的,
通道總結
channel常見的例外總結,如下圖:
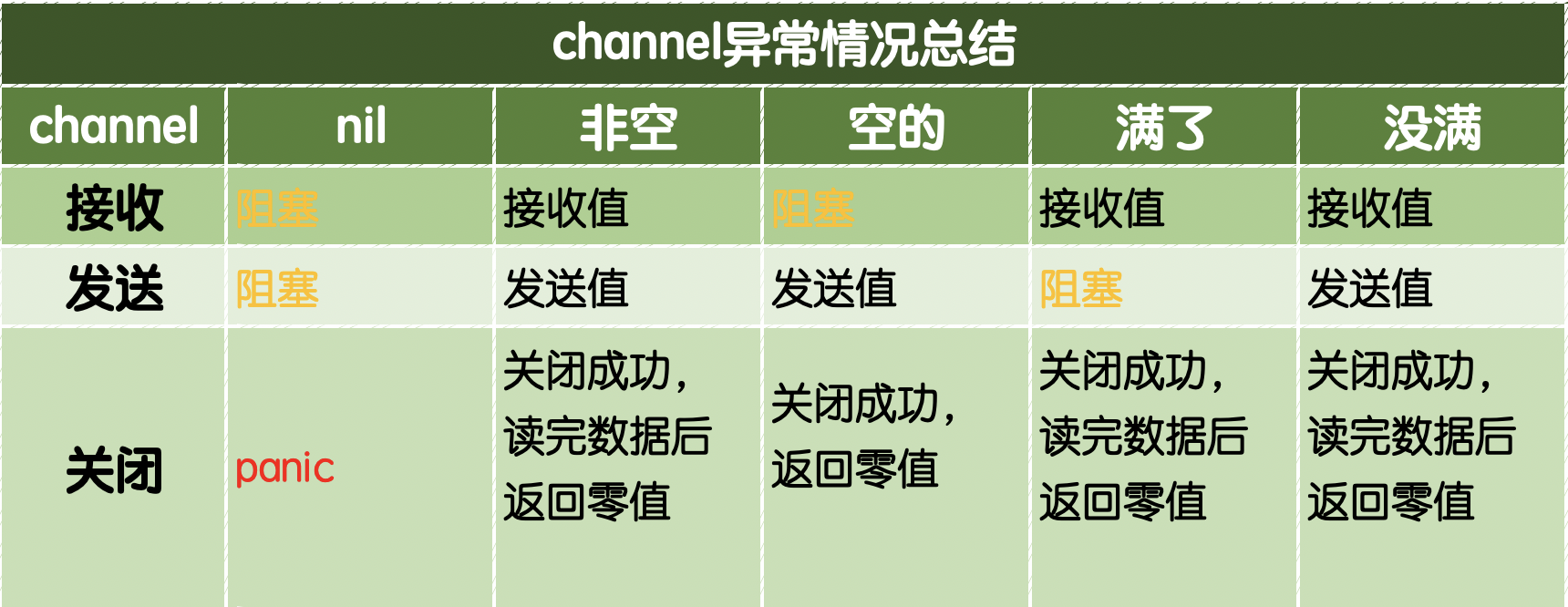
關閉已經關閉的channel也會引發panic,
func worker(id int, jobs <-chan int, results chan<- int) {
for j := range jobs {
fmt.Printf("worker:%d start job:%d\n", id, j)
time.Sleep(time.Second)
fmt.Printf("worker:%d end job:%d\n", id, j)
results <- j * 2
}
}
func main() {
jobs := make(chan int, 100)
results := make(chan int, 100)
// 開啟3個goroutine
for w := 1; w <= 3; w++ {
go worker(w, jobs, results)
}
// 5個任務
for j := 1; j <= 5; j++ {
jobs <- j
}
close(jobs)
// 輸出結果
for a := 1; a <= 5; a++ {
<-results
}
}
worker pool(goroutine池)
在作業中我們通常會使用可以指定啟動的goroutine數量–worker pool模式,控制goroutine的數量,防止goroutine泄漏和暴漲,
一個簡易的work pool示例代碼如下:
select多路復用
在某些場景下我們需要同時從多個通道接收資料,通道在接收資料時,如果沒有資料可以接收將會發生阻塞,你也許會寫出如下代碼使用遍歷的方式來實作:
for{
// 嘗試從ch1接收值
data, ok := <-ch1
// 嘗試從ch2接收值
data, ok := <-ch2
…
}
這種方式雖然可以實作從多個通道接收值的需求,但是運行性能會差很多,為了應對這種場景,Go內置了select關鍵字,可以同時回應多個通道的操作,
select的使用類似于switch陳述句,它有一系列case分支和一個默認的分支,每個case會對應一個通道的通信(接識訓發送)程序,select會一直等待,直到某個case的通信操作完成時,就會執行case分支對應的陳述句,具體格式如下:
select{
case <-ch1:
...
case data := <-ch2:
...
case ch3<-data:
...
default:
默認操作
}
舉個小例子來演示下select的使用:
func main() {
ch := make(chan int, 1)
for i := 0; i < 10; i++ {
select {
case x := <-ch:
fmt.Println(x)
case ch <- i:
}
}
}
使用select陳述句能提高代碼的可讀性,
- 可處理一個或多個channel的發送/接收操作,
- 如果多個
case同時滿足,select會隨機選擇一個, - 對于沒有
case的select{}會一直等待,可用于阻塞main函式,
并發安全和鎖
有時候在Go代碼中可能會存在多個goroutine同時操作一個資源(臨界區),這種情況會發生競態問題(資料競態),類比現實生活中的例子有十字路口被各個方向的的汽車競爭;還有火車上的衛生間被車廂里的人競爭,
舉個例子:
var x int64
var wg sync.WaitGroup
func add() {
for i := 0; i < 5000; i++ {
x = x + 1
}
wg.Done()
}
func main() {
wg.Add(2)
go add()
go add()
wg.Wait()
fmt.Println(x)
}
上面的代碼中我們開啟了兩個goroutine去累加變數x的值,這兩個goroutine在訪問和修改x變數的時候就會存在資料競爭,導致最后的結果與期待的不符,
互斥鎖
互斥鎖是一種常用的控制共享資源訪問的方法,它能夠保證同時只有一個goroutine可以訪問共享資源,Go語言中使用sync包的Mutex型別來實作互斥鎖, 使用互斥鎖來修復上面代碼的問題:
var x int64
var wg sync.WaitGroup
var lock sync.Mutex
func add() {
for i := 0; i < 5000; i++ {
lock.Lock() // 加鎖
x = x + 1
lock.Unlock() // 解鎖
}
wg.Done()
}
func main() {
wg.Add(2)
go add()
go add()
wg.Wait()
fmt.Println(x)
}
使用互斥鎖能夠保證同一時間有且只有一個goroutine進入臨界區,其他的goroutine則在等待鎖;當互斥鎖釋放后,等待的goroutine才可以獲取鎖進入臨界區,多個goroutine同時等待一個鎖時,喚醒的策略是隨機的,
讀寫互斥鎖
互斥鎖是完全互斥的,但是有很多實際的場景下是讀多寫少的,當我們并發的去讀取一個資源不涉及資源修改的時候是沒有必要加鎖的,這種場景下使用讀寫鎖是更好的一種選擇,讀寫鎖在Go語言中使用sync包中的RWMutex型別,
讀寫鎖分為兩種:讀鎖和寫鎖,當一個goroutine獲取讀鎖之后,其他的goroutine如果是獲取讀鎖會繼續獲得鎖,如果是獲取寫鎖就會等待;當一個goroutine獲取寫鎖之后,其他的goroutine無論是獲取讀鎖還是寫鎖都會等待,
讀寫鎖示例:
var (
x int64
wg sync.WaitGroup
lock sync.Mutex
rwlock sync.RWMutex
)
func write() {
// lock.Lock() // 加互斥鎖
rwlock.Lock() // 加寫鎖
x = x + 1
time.Sleep(10 * time.Millisecond) // 假設讀操作耗時10毫秒
rwlock.Unlock() // 解寫鎖
// lock.Unlock() // 解互斥鎖
wg.Done()
}
func read() {
// lock.Lock() // 加互斥鎖
rwlock.RLock() // 加讀鎖
time.Sleep(time.Millisecond) // 假設讀操作耗時1毫秒
rwlock.RUnlock() // 解讀鎖
// lock.Unlock() // 解互斥鎖
wg.Done()
}
func main() {
start := time.Now()
for i := 0; i < 10; i++ {
wg.Add(1)
go write()
}
for i := 0; i < 1000; i++ {
wg.Add(1)
go read()
}
wg.Wait()
end := time.Now()
fmt.Println(end.Sub(start))
}
需要注意的是讀寫鎖非常適合讀多寫少的場景,如果讀和寫的操作差別不大,讀寫鎖的優勢就發揮不出來,
sync.WaitGroup
在代碼中生硬的使用time.Sleep肯定是不合適的,Go語言中可以使用sync.WaitGroup來實作并發任務的同步, sync.WaitGroup有以下幾個方法:
| 方法名 | 功能 |
|---|---|
| (wg * WaitGroup) Add(delta int) | 計數器+delta |
| (wg *WaitGroup) Done() | 計數器-1 |
| (wg *WaitGroup) Wait() | 阻塞直到計數器變為0 |
sync.WaitGroup內部維護著一個計數器,計數器的值可以增加和減少,例如當我們啟動了N 個并發任務時,就將計數器值增加N,每個任務完成時通過呼叫Done()方法將計數器減1,通過呼叫Wait()來等待并發任務執行完,當計數器值為0時,表示所有并發任務已經完成,
我們利用sync.WaitGroup將上面的代碼優化一下:
var wg sync.WaitGroup
func hello() {
defer wg.Done()
fmt.Println("Hello Goroutine!")
}
func main() {
wg.Add(1)
go hello() // 啟動另外一個goroutine去執行hello函式
fmt.Println("main goroutine done!")
wg.Wait()
}
需要注意sync.WaitGroup是一個結構體,傳遞的時候要傳遞指標,
sync.Once
說在前面的話:這是一個進階知識點,
在編程的很多場景下我們需要確保某些操作在高并發的場景下只執行一次,例如只加載一次組態檔、只關閉一次通道等,
Go語言中的sync包中提供了一個針對只執行一次場景的解決方案–sync.Once,
sync.Once只有一個Do方法,其簽名如下:
func (o *Once) Do(f func()) {}
備注:如果要執行的函式f需要傳遞引數就需要搭配閉包來使用,
加載組態檔示例
延遲一個開銷很大的初始化操作到真正用到它的時候再執行是一個很好的實踐,因為預先初始化一個變數(比如在init函式中完成初始化)會增加程式的啟動耗時,而且有可能實際執行程序中這個變數沒有用上,那么這個初始化操作就不是必須要做的,我們來看一個例子:
var icons map[string]image.Image
func loadIcons() {
icons = map[string]image.Image{
"left": loadIcon("left.png"),
"up": loadIcon("up.png"),
"right": loadIcon("right.png"),
"down": loadIcon("down.png"),
}
}
// Icon 被多個goroutine呼叫時不是并發安全的
func Icon(name string) image.Image {
if icons == nil {
loadIcons()
}
return icons[name]
}
多個goroutine并發呼叫Icon函式時不是并發安全的,現代的編譯器和CPU可能會在保證每個goroutine都滿足串行一致的基礎上自由地重排訪問記憶體的順序,loadIcons函式可能會被重排為以下結果:
func loadIcons() {
icons = make(map[string]image.Image)
icons["left"] = loadIcon("left.png")
icons["up"] = loadIcon("up.png")
icons["right"] = loadIcon("right.png")
icons["down"] = loadIcon("down.png")
}
在這種情況下就會出現即使判斷了icons不是nil也不意味著變數初始化完成了,考慮到這種情況,我們能想到的辦法就是添加互斥鎖,保證初始化icons的時候不會被其他的goroutine操作,但是這樣做又會引發性能問題,
使用sync.Once改造的示例代碼如下:
var icons map[string]image.Image
var loadIconsOnce sync.Once
func loadIcons() {
icons = map[string]image.Image{
"left": loadIcon("left.png"),
"up": loadIcon("up.png"),
"right": loadIcon("right.png"),
"down": loadIcon("down.png"),
}
}
// Icon 是并發安全的
func Icon(name string) image.Image {
loadIconsOnce.Do(loadIcons)
return icons[name]
}
并發安全的單例模式
下面是借助sync.Once實作的并發安全的單例模式:
package singleton
import (
"sync"
)
type singleton struct {}
var instance *singleton
var once sync.Once
func GetInstance() *singleton {
once.Do(func() {
instance = &singleton{}
})
return instance
}
sync.Once其實內部包含一個互斥鎖和一個布林值,互斥鎖保證布林值和資料的安全,而布林值用來記錄初始化是否完成,這樣設計就能保證初始化操作的時候是并發安全的并且初始化操作也不會被執行多次,
sync.Map
Go語言中內置的map不是并發安全的,請看下面的示例:
var m = make(map[string]int)
func get(key string) int {
return m[key]
}
func set(key string, value int) {
m[key] = value
}
func main() {
wg := sync.WaitGroup{}
for i := 0; i < 20; i++ {
wg.Add(1)
go func(n int) {
key := strconv.Itoa(n)
set(key, n)
fmt.Printf("k=:%v,v:=%v\n", key, get(key))
wg.Done()
}(i)
}
wg.Wait()
}
上面的代碼開啟少量幾個goroutine的時候可能沒什么問題,當并發多了之后執行上面的代碼就會報fatal error: concurrent map writes錯誤,
像這種場景下就需要為map加鎖來保證并發的安全性了,Go語言的sync包中提供了一個開箱即用的并發安全版map–sync.Map,開箱即用表示不用像內置的map一樣使用make函式初始化就能直接使用,同時sync.Map內置了諸如Store、Load、LoadOrStore、Delete、Range等操作方法,
var m = sync.Map{}
func main() {
wg := sync.WaitGroup{}
for i := 0; i < 20; i++ {
wg.Add(1)
go func(n int) {
key := strconv.Itoa(n)
m.Store(key, n)
value, _ := m.Load(key)
fmt.Printf("k=:%v,v:=%v\n", key, value)
wg.Done()
}(i)
}
wg.Wait()
}
原子操作
代碼中的加鎖操作因為涉及內核態的背景關系切換會比較耗時、代價比較高,針對基本資料型別我們還可以使用原子操作來保證并發安全,因為原子操作是Go語言提供的方法它在用戶態就可以完成,因此性能比加鎖操作更好,Go語言中原子操作由內置的標準庫sync/atomic提供,
atomic包
| 方法 | 解釋 |
|---|---|
| func LoadInt32(addr *int32) (val int32) func LoadInt64(addr *int64) (val int64) func LoadUint32(addr *uint32) (val uint32) func LoadUint64(addr *uint64) (val uint64) func LoadUintptr(addr *uintptr) (val uintptr) func LoadPointer(addr *unsafe.Pointer) (val unsafe.Pointer) |
讀取操作 |
| func StoreInt32(addr *int32, val int32) func StoreInt64(addr *int64, val int64) func StoreUint32(addr *uint32, val uint32) func StoreUint64(addr *uint64, val uint64) func StoreUintptr(addr *uintptr, val uintptr) func StorePointer(addr *unsafe.Pointer, val unsafe.Pointer) |
寫入操作 |
| func AddInt32(addr *int32, delta int32) (new int32) func AddInt64(addr *int64, delta int64) (new int64) func AddUint32(addr *uint32, delta uint32) (new uint32) func AddUint64(addr *uint64, delta uint64) (new uint64) func AddUintptr(addr *uintptr, delta uintptr) (new uintptr) |
修改操作 |
| func SwapInt32(addr *int32, new int32) (old int32) func SwapInt64(addr *int64, new int64) (old int64) func SwapUint32(addr *uint32, new uint32) (old uint32) func SwapUint64(addr *uint64, new uint64) (old uint64) func SwapUintptr(addr *uintptr, new uintptr) (old uintptr) func SwapPointer(addr *unsafe.Pointer, new unsafe.Pointer) (old unsafe.Pointer) |
交換操作 |
| func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool) func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool) func CompareAndSwapUint32(addr *uint32, old, new uint32) (swapped bool) func CompareAndSwapUint64(addr *uint64, old, new uint64) (swapped bool) func CompareAndSwapUintptr(addr *uintptr, old, new uintptr) (swapped bool) func CompareAndSwapPointer(addr *unsafe.Pointer, old, new unsafe.Pointer) (swapped bool) |
比較并交換操作 |
示例
我們填寫一個示例來比較下互斥鎖和原子操作的性能,
package main
import (
"fmt"
"sync"
"sync/atomic"
"time"
)
type Counter interface {
Inc()
Load() int64
}
// 普通版
type CommonCounter struct {
counter int64
}
func (c CommonCounter) Inc() {
c.counter++
}
func (c CommonCounter) Load() int64 {
return c.counter
}
// 互斥鎖版
type MutexCounter struct {
counter int64
lock sync.Mutex
}
func (m *MutexCounter) Inc() {
m.lock.Lock()
defer m.lock.Unlock()
m.counter++
}
func (m *MutexCounter) Load() int64 {
m.lock.Lock()
defer m.lock.Unlock()
return m.counter
}
// 原子操作版
type AtomicCounter struct {
counter int64
}
func (a *AtomicCounter) Inc() {
atomic.AddInt64(&a.counter, 1)
}
func (a *AtomicCounter) Load() int64 {
return atomic.LoadInt64(&a.counter)
}
func test(c Counter) {
var wg sync.WaitGroup
start := time.Now()
for i := 0; i < 1000; i++ {
wg.Add(1)
go func() {
c.Inc()
wg.Done()
}()
}
wg.Wait()
end := time.Now()
fmt.Println(c.Load(), end.Sub(start))
}
func main() {
c1 := CommonCounter{} // 非并發安全
test(c1)
c2 := MutexCounter{} // 使用互斥鎖實作并發安全
test(&c2)
c3 := AtomicCounter{} // 并發安全且比互斥鎖效率更高
test(&c3)
}
atomic包提供了底層的原子級記憶體操作,對于同步演算法的實作很有用,這些函式必須謹慎地保證正確使用,除了某些特殊的底層應用,使用通道或者sync包的函式/型別實作同步更好,
練習題
- 使用
goroutine和channel實作一個計算int64亂數各位數和的程式,- 開啟一個
goroutine回圈生成int64型別的亂數,發送到jobChan - 開啟24個
goroutine從jobChan中取出亂數計算各位數的和,將結果發送到resultChan - 主
goroutine從resultChan取出結果并列印到終端輸出
- 開啟一個
- 為了保證業務代碼的執行性能將之前寫的日志庫改寫為異步記錄日志方式,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/43075.html
標籤:Go
上一篇:Go語言基礎之網路編程
下一篇:Go語言基礎之反射