定義
正則運算式(Regular Expression)
用某種模式去匹配一類字串的公式,主要用來描述字串匹配的工具,
匹配
文本或字符存在不止一個部分滿足給定的正則運算式,這是每一個這樣的部分都被稱為一個匹配,
匹配分為以下三種型別:
- 形容詞性的匹配
即一個字串匹配一個正則運算式 - 名詞性的匹配
即在文本或字串里匹配正則運算式 - 名詞性的匹配
即字串中滿足給定的正則運算式的一部分
元字符
元字符(Metacharacter)是一類非常特殊的字符,它能夠匹配一個位置或字符集合中的一個字符,元字符可以分為兩種型別
- 匹配位置的元字符
- 匹配字符的元字符
元字符只能匹配一個字符位置,也就是一個匹配的單位是一個字符,而不是一個字串
匹配位置的元字符
| 字符 | 說明 |
|---|---|
^ |
匹配行開始 |
$ |
匹配行結束 |
\b |
匹配單詞的開始或結束 不支持中文 |
測驗
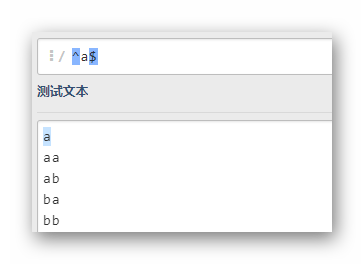
^a
匹配第一個字母為a的一行
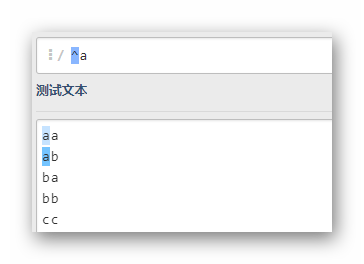
a$
匹配最后一個字母為a的一行
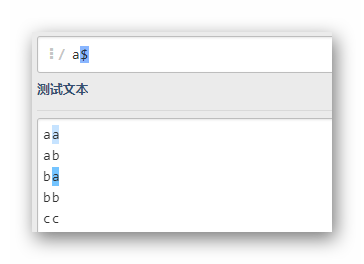
^a$
匹配只有一個字母a的一行
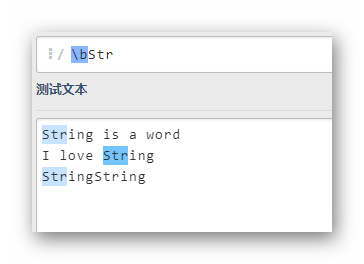
\bStr
匹配以Str為開頭的單詞
ing\b
匹配以ing為結尾的單詞
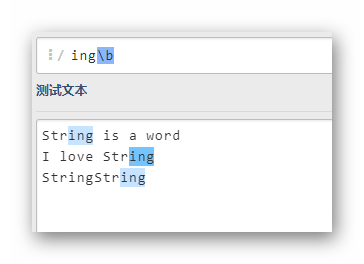
\bString\b
僅匹配String這個單詞
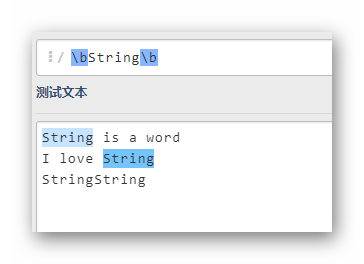
\b字符如何識別哪個是單詞呢?
以標點符號或空格分隔的字串將被識別為單詞,而且 \b只能用于英文,不能用于中文
匹配字符的元字符
元字符都是按照單個字符進行匹配
| 字符 | 說明 |
|---|---|
. (點號) |
匹配除換行符之外的任意字符 |
\w |
匹配任意單詞字符(字母,數字,下劃線) |
\W |
匹配任意非單詞字符 |
\s |
匹配任意空白字符(空格,制表符,換行符,中文全角空格) |
\S |
匹配任意非空白字符 |
\d |
匹配任意數字 0~9的任意一個數字 |
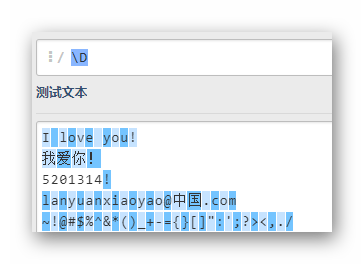
\D |
匹配任意非數字 |
測驗
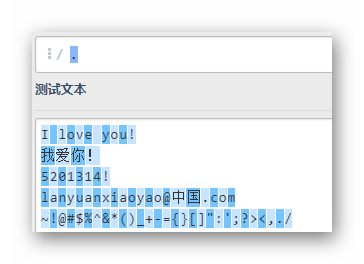
.
全部字符匹配
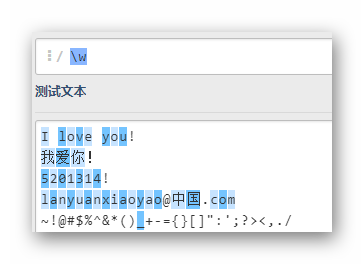
\w
匹配了全部的單詞字符,除了下劃線之外的標點符號和漢字都被排除在外
\W
匹配結果和\w剛好相反,注意那個下劃線是屬于單詞字符的
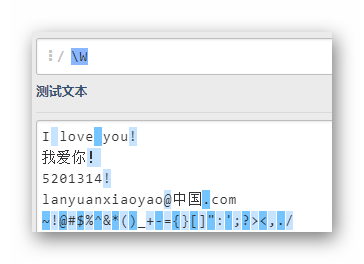
\s
有2個空格被匹配,注意!這里總共有6個符號被匹配了,除了兩個空格還有1~4行末的換行符
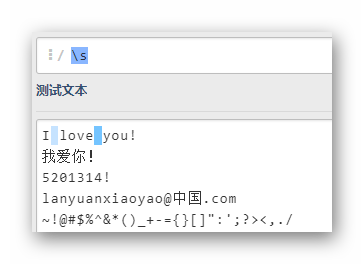
\S
除了2個空格和4個換行符,其余字符全部匹配
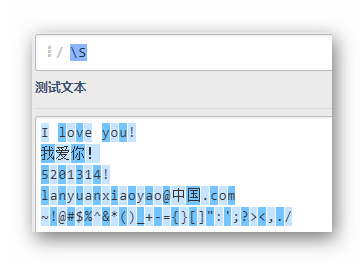
\d
匹配所有的數字
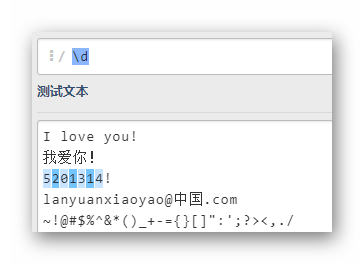
\D
匹配所有數字之外的字符
元字符組合
僅僅是元字符就可以自由組合來實作不同的匹配效果
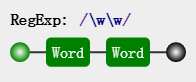
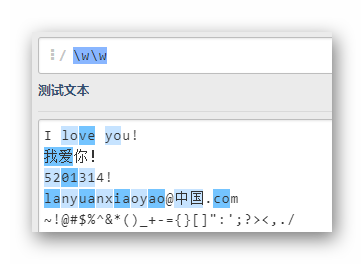
\w\w
匹配連續的兩個單詞字符
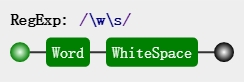
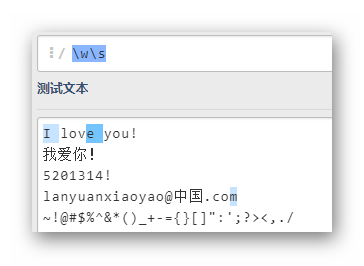
\w\s
注意第三行最后匹配的m是和行末的換行符一起匹配成功的
文字匹配
字符類
字符類是一個字符集合,如果該字符集合中的任何一個字符被匹配,則它會找到該匹配項,
[]
字符類使用中括號作為標志,字符集合寫在中括號里面,意為匹配中括號中的任意一個字符\-
當\-符號不是第一個字符的時候表示定義字符的范圍,例如[1-3]表示[123],[a-z]表示匹配任意小寫字母,如果\-放在第一位,那就僅表示自己,這個范圍的順序和兩個字符間的內容是按照ASCII表的順序決定的,例如[9-1]是違反ASCII表順序的一個運算式,這會報錯^
如果放在字符類第一個,表示該字符類的否定,[^123]表示匹配1、2、3之外的所有數字- 元字符在字符類中不做任何特殊處理,僅僅表示他們自身
測驗
[aeiou]
匹配元音字母[a-z]
匹配從小寫字母a到z之間的所有字母[^aeiou]
匹配元音字母之外的所有字符(包括任意符號)[^a-z]
匹配小寫字母a到z之間的所有字母之外的所有字符[0-9]
匹配從0到9之間的任意一個數字[ao-u]
匹配a和o到u之間的所有字母,可以看到只要在連個字符之間使用連接符-就會判斷為一個區間[!-?]
匹配從!到?之間的任意一個符號,可以看到因為是按照ASCII表順序來判斷-連接的字符集合,所以這樣寫也是沒有問題的[a^-]
匹配字符a、^和-三個字符,只要^符號不在第一位,-符號不在兩個字符中間,那么它們就只表示自身a[no]
匹配字串an或ao,這是字符類和元字符的組合
字符轉義
之前介紹的元字符非常好用,但是這又引出了一個問題,如果我們想在正常的運算式里面使用元字符本身這個符號怎么辦呢?難道每次都要寫在字符類里面嗎?
當然不,這里就引出了我們的字符轉義
正則運算式定義了一些特殊的元字符,如^、$、.等,由于這些字符在正則運算式中被解釋成其他指定的含義,如果需要匹配這些字符,則需要使用字符轉義來解決這個問題,轉義字符使用符號\(反斜杠),它可以取消這些字符(如^、$、.等)在運算式中具有的特殊意義,
.
匹配字符.*
匹配字符*\
匹配字符\www\.lanyuanxiaoyao\.com
匹配字串www\.lanyuanxiaoyao\.com,網址中的dot符號也是需要轉義的
常用轉義字符
| 字符或運算式 | 說明 |
|---|---|
\a |
響鈴(警報) \u0007 |
\b |
在正則運算式中,表示單詞的邊界;如果在字符類中,則表示退格符\u0008 |
\t |
制表符\u0009 |
\r |
回車符\u000D |
\v |
垂直制表符\u000B |
\f |
換頁符\u000C |
\n |
換行符\u000A |
\e |
回退(ESC)符\u001B |
\040 |
將ASCII字符匹配為八進制數(最多3位) |
\x20 |
使用十六進制表示,形式與ASCII字符匹配 |
\cC |
ASCII控制字符,如Ctrl-C |
\u0020 |
使用十六進制表示形式(恰好4位)與Unicode字符匹配 |
限定符
這是一個重要的知識點
限定符用于指定允許特定字符或字符集自身重復出現的次數,
| 字符或運算式 | 說明 |
|---|---|
{n} |
重復n次 |
{n,} |
重復至少n次 |
{n,m} |
重復至少n次,最多m次 |
* |
重復至少0次,等同于{0,} |
+ |
重復至少1次,等同于{1,} |
? |
重復0次或1次,等同于{0,1} |
\*? |
盡可能少地使用重復的第1個匹配 |
+? |
盡可能少地使用重復但至少使用1次 |
?? |
使用0次重復(如果有可能)或1次重復 |
{n}? |
等同于{n} |
{n,}? |
盡可能少地使用重復,但至少使用1次 |
{n,m}? |
介于n次和m次之間,盡可能少地使用重復 |
測驗
a{3}
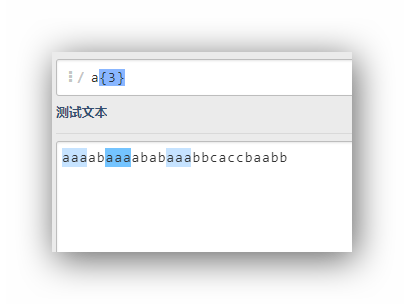
a{2,}
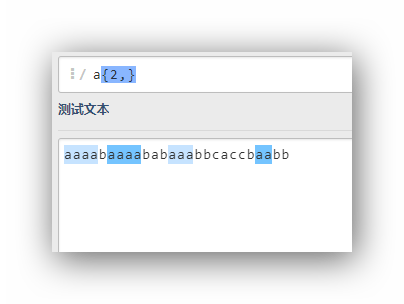
a{2,3}
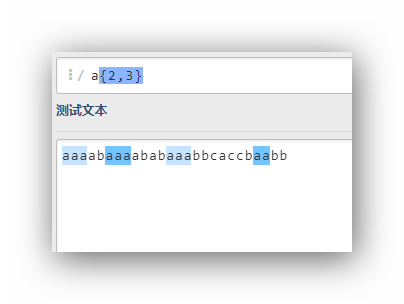
ab+
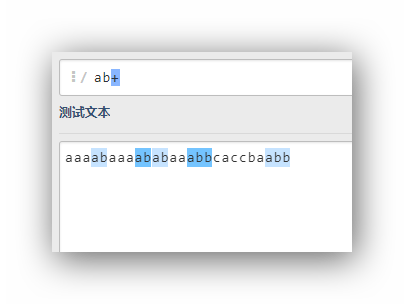
ab?
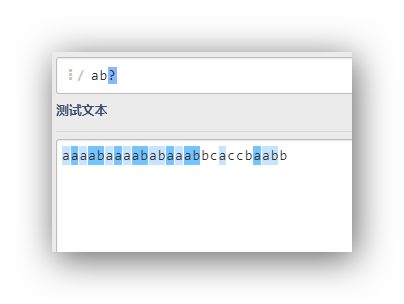
ab*
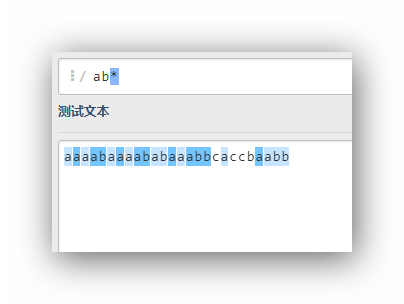
ab+?
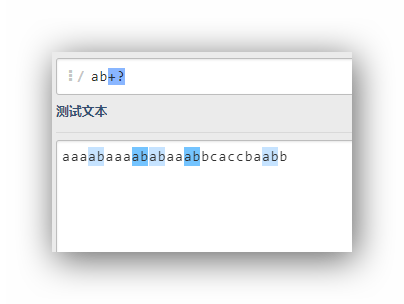
ab??
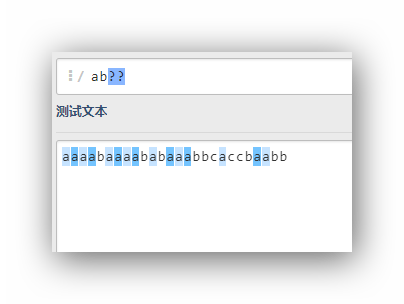
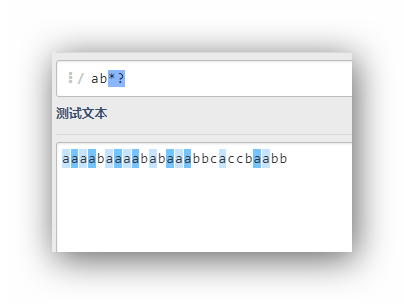
ab*?
貪婪模式與懶惰模式
如果在限定符*、+、?、{n}、{n,}和{n,m}之后再添加一個字符 ? ,則表示 盡可能少地重復字符?之前的限定符號的重復次數,這種匹配方式稱為懶惰匹配,與之相對的,如果沒有字符 ? ,僅僅使用單個限定符*、+、?、{n}、{n,}和{n,m}的匹配,就稱為貪婪匹配,
看起來好像很復雜,但是理解歷來并不難,即懶惰匹配模式只匹配最短符合運算式的字串,貪婪匹配模式只匹配最長符合運算式的字串,
這里的貪婪模式和懶惰模式在不同的教程或者說明里面都有不同的叫法,所以可以理解意思就行了,大同小異
測驗
- 貪婪模式
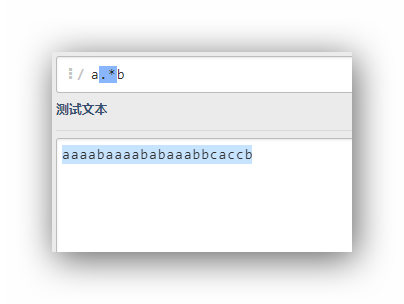
a.*b
可以看到這里只有一個匹配,就是整個字串,因為這是最長的匹配
- 懶惰模式
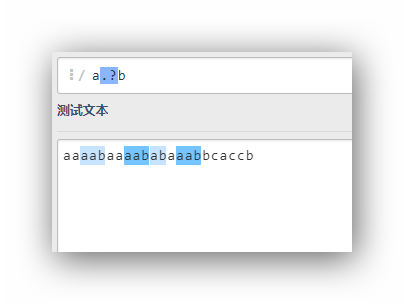
a.?b
這里一旦發現一個匹配立刻就完成當前的匹配,然后從下一個字符開始新的匹配,所以這里會有4個匹配
字符的運算
替換
替換使用字符|來表示,表示如果某一個字串匹配了運算式中字符|左邊或者右邊的規則,那么這個字串就匹配了這個運算式
|表示“或”的意思,這個符號和代碼中的“邏輯或”相同,比較好理解
匹配是根據左邊優先的原則,即從左往右,當左邊的運算式不滿足的時候,才會去嘗試右邊的運算式
測驗
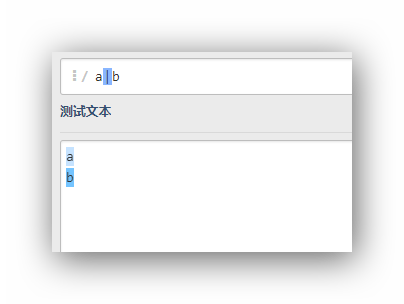
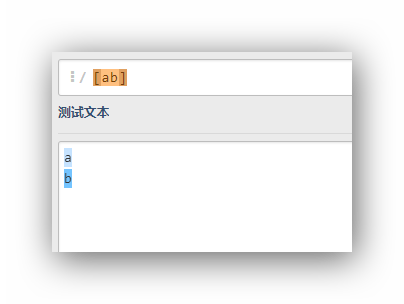
a|b
可以看到不管是字符a還是b都可以匹配這個運算式,它等同于[ab]
分組
分組又被稱為子運算式,即把一個正則運算式的全部或部分分成一個或多個組,分組使用()來表示,括號中的運算式就是一個組,一個組就是一個整體
要注意和字符類[]區分開來,[123]是表示匹配字符1或2或3,而(123)就是匹配123這個字串
反向參考
組號
當一個正則運算式被分組之后,默認從左到右每一個分組都會自動被賦予一個組號,以左括號(為分界從1開始自增,第一個組的組號是1,第二個組的組號是2,以此類推,在后面的運算式,使用\組號的方式來參考前面的組,例如\b(\w)\1\b這個運算式中,后面的\1就是對前面(\w)組的參考
自定義組號
分組不止會自動使用數字作為組號,還可以手動命名,形式為(?<name>),(?<word>\w)和(?'word'\w)都是把\w+匹配到的字母保存到名為word的分組,自定義命名的分組使用\k<name>的方式使用 ,如\b(?<word>\w)\k<word>\b是匹配連續的相同的兩個字母的單詞
反向參考
提供了查找重復字符組的簡便方法,可以認為是再次匹配同一個字符組的快捷指令
反向參考參考的是前面的運算式匹配到的字串,而不是前面的運算式
例如,\b(\w)\1\b 這個運算式中的\1表示的是前面\w匹配到的字符,前面匹配到字母a那么\1處也必須替換為字母a,而不是任意一個字母 所以這個運算式匹配的是兩個完全相同的字母 而如果是\b(\w)\w\b 則是表示兩個允許不相同的字母
| 字符 | 說明 |
|---|---|
(expression) |
匹配字串expression,并將匹配到的文本保存到自動命名的分組里 |
(?<name>expression) |
匹配字串expression,并將匹配的文本以name進行命名,該名稱不能包含標點符號,不能以數字開頭 |
(?:expression) |
匹配字串expression,不保存匹配的文明,也不給此組分配組號 |
(?=expression) |
匹配字串expression前面的位置 |
(?!expression) |
匹配后面不是字串expression的位置 |
(?<=expression) |
匹配字串expression后面的位置 |
(?<!expression) |
匹配前面不是字串expression的位置 |
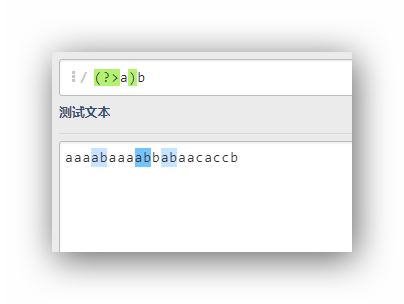
(?>expression) |
只匹配字串expression一次 |
測驗
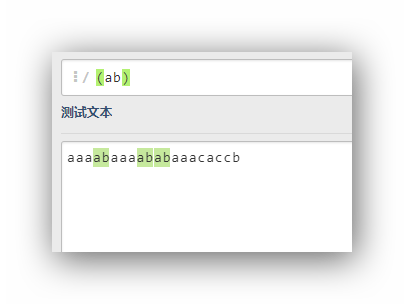
(ab)
ab就是一個整體看待,和單獨的字串ab沒有區別
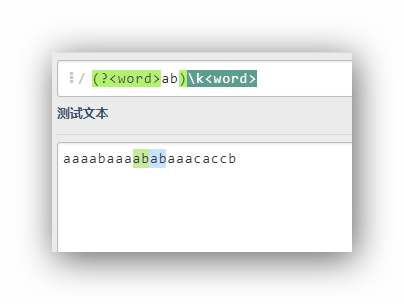
(?<word>ab)\k<word>
把ab這個組命名為word,然后在后面呼叫前面命名的這個組匹配的字符,即這個運算式相當于(ab)ab
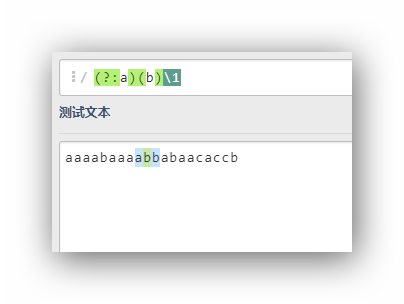
(?:a)(b)\1
前面的組被取消命名,所以自動命名從(b)開始,所以后面的\1匹配的是(b)
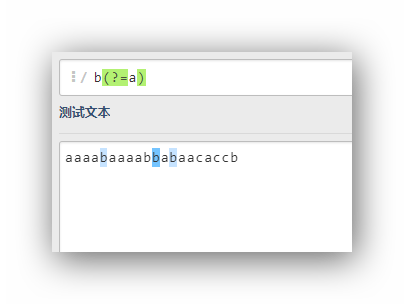
b(?=a)
這個運算式的意思是,匹配字符b,這個字符b的后面緊跟著一個a
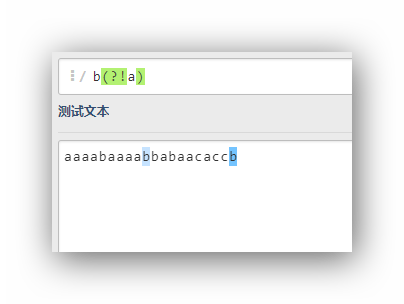
b(?!a)
這個運算式的意思是,匹配字符b,這個字符b的后面不是a
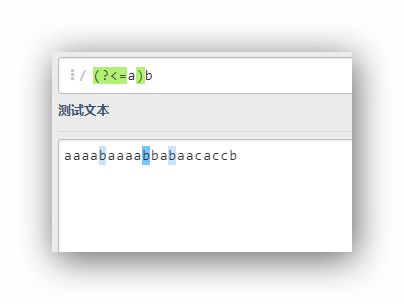
(?<=a)b
這個運算式的意思是,匹配字符b,這個字符b的前面是a
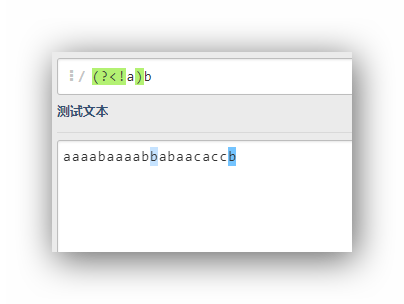
(?<!a)b
這個運算式的意思是,匹配字符b,這個字符b的前面不是a
(?>a)b
參考
- 王蕾. 神奇的匹配 正則運算式求精之旅[M]. 北京:電子工業出版社, 2014.
- 文中使用的正則運算式測驗工具:正則運算式測驗工具在線除錯與分享-Zjmainstay
- 文中使用的正則運算式可視化生成工具:Regulex JavaScript Regular Expression Visualizer.
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/43107.html
標籤:Java
上一篇:Go語言基礎之map