《Java面試題系列》:一個長知識又很有意思的專欄,深入挖掘、分析原始碼、匯總原理、圖文結合,打造公眾號系列文章,面試與否均可提升Level,歡迎持續關注【程式新視界】,本篇為第4篇,
核心問題:重寫了equals方法,為什么還要重寫hashCode方法?
這不僅僅是一道面試題,而且是關系到我們的代碼是否健壯和正確的問題,在前面兩篇文章涉及到了equals方法的底層講解:《說說==和equals的區別?你的回答可能是錯誤的》和《Integer等號判斷的內幕,你可能不知道?》,
本篇文章,帶大家從底層來分析一下hashcode方法重寫的意義以及如何實作,
回顧equals方法
我們先回顧一下Object的equals方法實作,并簡單匯總一下使用equals方法的規律,
public boolean equals(Object obj) {
return (this == obj);
}
通過上面Object的源代碼,可以得出一個結論:如果一個類未重寫equals方法,那么本質上通過“==”和equals方法比較的效果是一樣的,都是比較兩個物件的的記憶體地址,
前面兩篇文章講到String和Integer在比較時的區別,關鍵點也是它們對equals方法的實作,
面試時總結一下就是:默認情況下,從Object類繼承的equals方法與“==”完全等價,比較的都是物件的記憶體地址,但我們可以重寫equals方法,使其按照需要進行比較,如String類重寫了equals方法,比較的是字符的序列,而不再是記憶體地址,
與hashCode方法的關系
那么equals方法與hashCode方法又有什么關系呢?我們來看Object上equals方法的一段注釋,
Note that it is generally necessary to override the hashCode method whenever this method is overridden, so as to maintain the general contract for the hashCode method, which states that equal objects must have equal hash codes.
大致意思是:當重寫equals方法后有必要將hashCode方法也重寫,這樣做才能保證不違背hashCode方法中“相同物件必須有相同哈希值”的約定,
此處只是提醒了我們重寫hashCode方法的必要性,那其中提到的hashCode方法設計約定又是什么呢?相關的內容定義在hashCode方法的注解部分,
hashCode方法約定
關于hashCode方法的約定原文比較多,大家直接看原始碼即可看到,這里匯總一下,共三條:
(1)如果物件在使用equals方法中進行比較的引數沒有修改,那么多次呼叫一個物件的hashCode()方法回傳的哈希值應該是相同的,
(2)如果兩個物件通過equals方法比較是相等的,那么要求這兩個物件的hashCode方法回傳的值也應該是相等的,
(3)如果兩個物件通過equals方法比較是不同的,那么也不要求這兩個物件的hashCode方法回傳的值是不相同的,但是我們應該知道對于不同物件產生不同的哈希值對于哈希表(HashMap等)能夠提高性能,
其實,看到這里我們了解了hashCode的實作規約,但還是不清楚為什么實作equals方法需要重寫hashCode方法,但我們可以得出一條規律:hashCode方法實際上必須要完成的一件事情就是,為equals方法認定為相同的物件回傳相同的哈希值,
其實在上面規約中提到了哈希表,這也正是hashCode方法運用的場景之一,也是我們為什么要重寫的核心,
hashCode應用場景
如果了解HashMap的資料結構,就會知道它用到“鍵物件”的哈希碼,當我們呼叫put方法或者get方法對Map容器進行操作時,都是根據鍵物件的哈希碼來計算存盤位置的,如果我們對哈希碼的獲取沒有相關保證,就可能會得不到預期的結果,
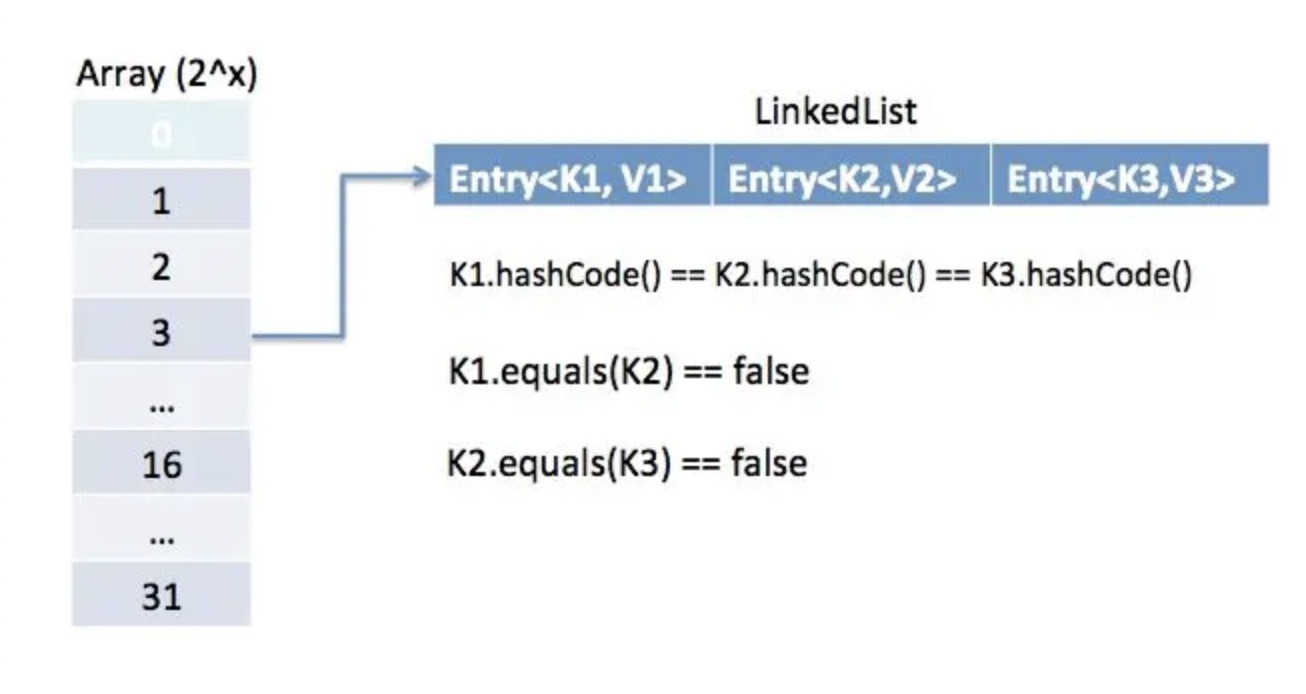
而物件的哈希碼的獲取正是通過hashCode方法獲取的,如果自定義的類中沒有實作該方法,則會采用Object中的hashCode()方法,
在Object中該方法是一個本地方法,會回傳一個int型別的哈希值,可以通過將物件的內部地址轉換為整數來實作的,但是Java中沒有強制要求通過該方式實作,
具體實作網路上有不同的說法,有說通過內置地址轉換得來,也有說“OpenJDK8默認hashCode的計算方法是通過和當前執行緒有關的一個亂數+三個確定值,運用Marsaglia's xorshift scheme亂數演算法得到的一個亂數”獲得,
無論默認實作是怎樣的,大多數情況下都無法滿足equals方法相同,同時hashCode結果也相同的條件,比如下面的示例重寫與否差距很大,
public void test1() {
String s = "ok";
StringBuilder sb = new StringBuilder(s);
System.out.println(s.hashCode() + " " + sb.hashCode());
String t = new String("ok");
StringBuilder tb = new StringBuilder(s);
System.out.println(t.hashCode() + " " + tb.hashCode());
}
上面這段代碼列印的結果為:
3548 1833638914
3548 1620303253
String實作了hashCode方法,而StringBuilder并沒有實作,這就導致即使值是一樣的,hashCode也不同,
上個示例中問題還不太明顯,下面我們以HashMap為例,看看如果沒有實作hashCode方法會導致什么嚴重的后果,
@Test
public void test2() {
String hello = "hello";
Map<String, String> map1 = new HashMap<>();
String s1 = new String("key");
String s2 = new String("key");
map1.put(s1, hello);
System.out.println("s1.equals(s2):" + s1.equals(s2));
System.out.println("map1.get(s1):" + map1.get(s1));
System.out.println("map1.get(s2):" + map1.get(s2));
Map<Key, String> map2 = new HashMap<>();
Key k1 = new Key("A");
Key k2 = new Key("A");
map2.put(k1, hello);
System.out.println("k1.equals(k2):" + s1.equals(s2));
System.out.println("map2.get(k1):" + map2.get(k1));
System.out.println("map2.get(k2):" + map2.get(k2));
}
class Key {
private String k;
public Key(String key) {
this.k = key;
}
@Override
public boolean equals(Object obj) {
if (obj instanceof Key) {
Key key = (Key) obj;
return k.equals(key.k);
}
return false;
}
}
實體中定義了內部類Key,其中實作了equals方法,但未實作hashCode方法,存放于Map中的value值都是字串“hello”,
代碼分兩段,第一段演示當Map的key通過實作了hashCode的String時是什么效果;第二段演示了當Map的key通過未實作hashCode方法的Key物件時是什么效果,
執行上述代碼,列印結果如下:
s1.equals(s2):true
map1.get(s1):hello
map1.get(s2):hello
k1.equals(k2):true
map2.get(k1):hello
map2.get(k2):null
分析結果可以看出,對于String作為key的s1和s2來說,通過equals比較相等是自然的,獲得的值也是相同的,但k1和k2通過equals比較是相等,但為什么在Map中獲得的結果卻不一樣?本質上就是因為沒有重寫hashCode方法導致Map在存盤和獲取程序中呼叫hashCode方法獲得的值不一致,
此時在Key類中添加hashCode方法:
@Override
public int hashCode(){
return k.hashCode();
}
再次執行,便可正常獲得對應的值,
s1.equals(s2):true
map1.get(s1):hello
map1.get(s2):hello
k1.equals(k2):true
map2.get(k1):hello
map2.get(k2):hello
通過上面的典型實體演示了不重寫hashCode方法的潛在后果,簡單看一下HashMap中的put方法,
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 通過哈希值來查找底層陣列位于該位置的元素p,如果p不為null,則使用新的鍵值對來覆寫舊的鍵值對
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// (二者哈希值相等)且(二者地址值相等或呼叫equals認定相等),
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 如果底層陣列中存在傳入的Key,那么使用新傳入的覆寫掉查到的
if (e != null) { // existing mapping for key
V oldValue = https://www.cnblogs.com/secbro/p/e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
在上述方法中,put方法在拿到key的第一步就對key物件呼叫了hashCode方法,暫且不看后面的代碼,如果沒有重寫hashCode方法,就無法確保key的hash值一致,后續操作就是兩個key的操作了,
重寫hashCode方法
了解了重寫hashCode方法的重要性,也了解了對應的規約,那么下面我們就聊聊如何優雅的重寫hashCode方法,
首先,如果使用IDEA的話,那么直接使用快捷鍵即可,
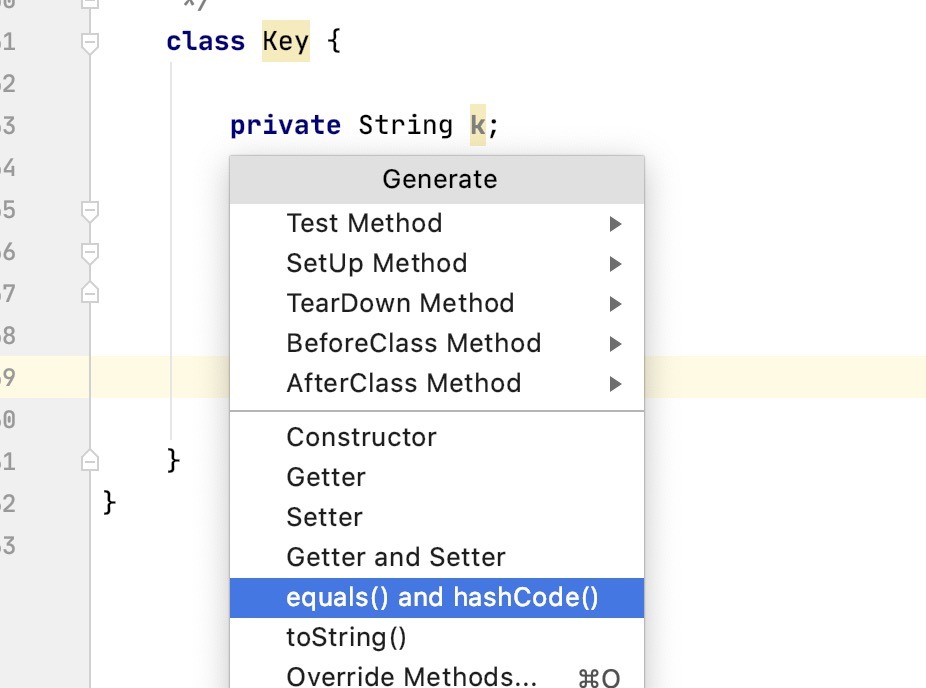
生成的效果如下:
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
Key key = (Key) o;
return Objects.equals(k, key.k);
}
@Override
public int hashCode() {
return Objects.hash(k);
}
根據需要可對生成的方法內部實作進行修改,在上面的實體中用到了java.util.Objects類,它的hash方法的優點是如果引數為null,就只回傳0,否則回傳物件引數呼叫的hashCode的結果,Objects.hash方法原始碼如下:
public static int hash(Object... values) {
return Arrays.hashCode(values);
}
其中Arrays.hashCode方法原始碼如下:
public static int hashCode(Object a[]) {
if (a == null)
return 0;
int result = 1;
for (Object element : a)
result = 31 * result + (element == null ? 0 : element.hashCode());
return result;
}
當然此處只有一個引數,也可以直接使用Objects類hashCode方法:
public static int hashCode(Object o) {
return o != null ? o.hashCode() : 0;
}
如果是多個屬性都參與hash值的情況建議可使用第一個方法,只不過需要注意,在類結構(成員變數)變動時,同步增減方法里面的引數值,
小結
當我們準備面試時,一直在背誦“實作equals方法的同時也要實作hashCode方法”,牢記這些結論并沒有錯,但我們也不能因為匆忙準備面試題,而忘記了這些面試題之所以頻繁出現的原因是什么,當深入探索之后,會發現在那些枯燥的結論背后還有這么多不容忽視的知識點,還有這么多有意思的設計與陷阱,
我是覺得越研究越有意思,越研究越發現自己曾經的無知,你呢?關注一下,期待下一篇文章吧,

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/43130.html
標籤:Java