我在 python 控制臺上檢索文本失敗。Python/Selenium 認為它是空白的,因此會顯示Failed to obtain text(顯示在結果影像中)。
蟒蛇代碼:
import pytest
from selenium import webdriver
from selenium.webdriver.common.by import By
#Feature: Joke Generator Button
#Scenario: Click button to move onto next jokes.
def test_joke():
#Given the website is displayed with the instruction and button
b=webdriver.Chrome()
b.get("https://elated-benz-84557d.netlify.app/#")
b.implicitly_wait(10)
#When the user clicked on the button
l=b.find_element(By.ID,"next")
l.click()
#Then the joke gets generated
m=b.find_element(By.XPATH,"//*[@id='p']").text
if m == "":
print("Failed to obtain text.")
else:
print(f"The text is: {m}")
b.quit()
test_joke()
結果如下:
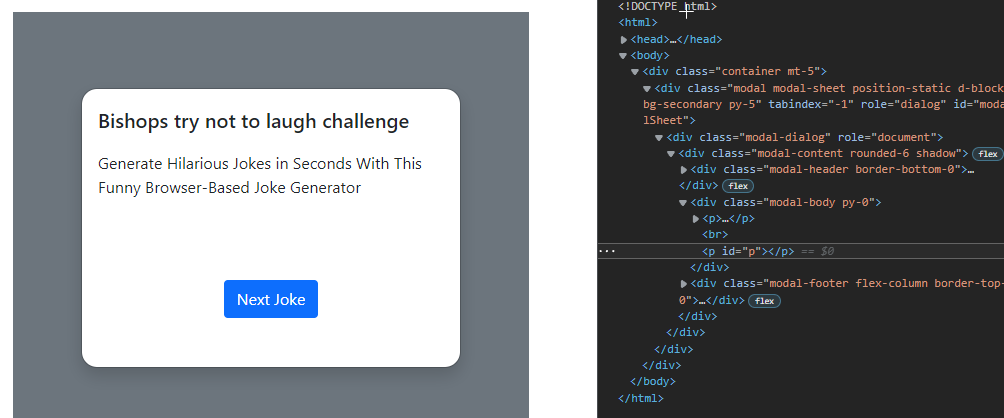
該網站是一個簡單的笑話生成器,在單擊按鈕之前最初不會顯示任何笑話。單擊它后,會生成一個笑話。除了代碼中顯示的 XPATH 之外,我還嘗試使用(By.ID, "p"),并且得到了相同的失敗結果。
以下是點擊按鈕生成笑話前后的網頁圖片及其各自的源代碼。HTML 中突出顯示的是我選擇文本定位器的位置,id="p"。
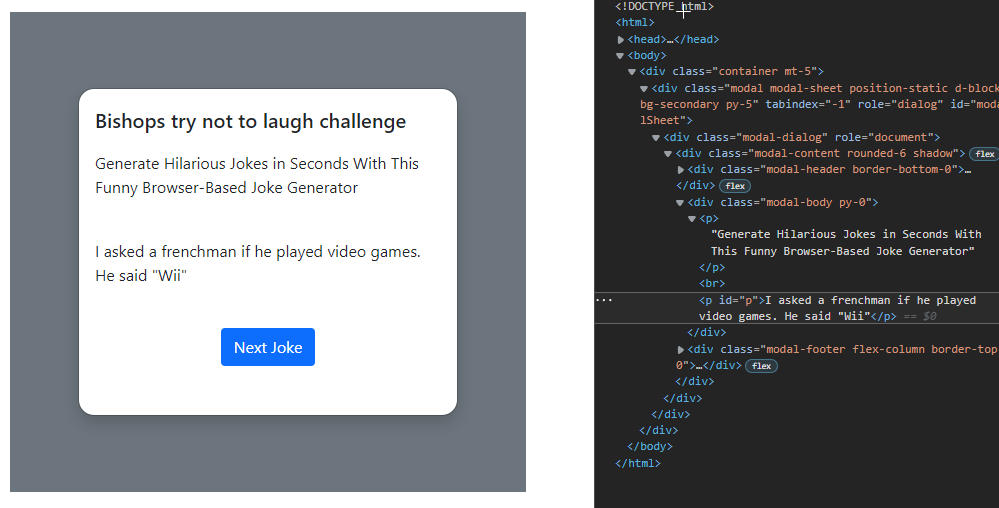
任何幫助深表感謝。如果您有任何問題,請隨時提問。
uj5u.com熱心網友回復:
單擊Next Joke那里的按鈕后,需要一些時間來生成一個新的笑話并呈現它。您必須等待文本在該元素內可見。
您implicitly_wait在代碼中使用。這將等待元素存在。更好的方法是使用預期條件顯式等待等待元素可見性、可點擊性等。這些是 Web 元素更成熟的狀態,只是元素存在于頁面上,而元素可能仍未完全呈現等。
請嘗試類似下列的:
import pytest
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
#Feature: Joke Generator Button
#Scenario: Click button to move onto next jokes.
def test_joke():
#Given the website is displayed with the instruction and button
b=webdriver.Chrome()
wait = WebDriverWait(b, 20)
b.get("https://elated-benz-84557d.netlify.app/#")
#When the user clicked on the button
wait.until(EC.visibility_of_element_located((By.ID, "next"))).click()
#Then the joke gets generated
m = wait.until(EC.visibility_of_element_located((By.XPATH, "//*[@id='p']"))).text
if m == "":
print("Failed to obtain text.")
else:
print(f"The text is: {m}")
b.quit()
test_joke()
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/434326.html
上一篇:ImportError:無法從“selenium”匯入名稱“wedriver”
下一篇:檢索串列中指定屬性名稱的所有值?