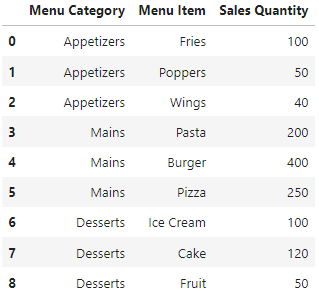
我有以下熊貓資料框:
# Create DataFrame
import pandas as pd
data = {'Menu Category': ['Appetizers', 'Appetizers', 'Appetizers', 'Mains', 'Mains',
'Mains', 'Desserts', 'Desserts', 'Desserts'],
'Menu Item': ['Fries', 'Poppers', 'Wings', 'Pasta', 'Burger', 'Pizza',
'Ice Cream', 'Cake', 'Fruit'],
'Sales Quantity': [100, 50, 40, 200, 400, 250, 100, 120, 50],
}
df = pd.DataFrame(data)
df
我想添加兩列。1)顯示每個專案代表的選單的百分比數量(整個選單是這個資料集),以及 2)顯示專案所屬的選單類別的百分比數量(比如Sale Quantity確實Fries代表Appetizers組的百分比,即(100/190) * 100)。
我知道如何獲得提到的第一列:
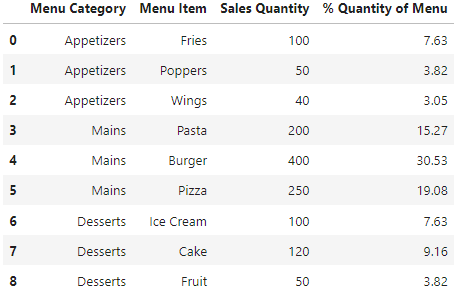
# Add % Quantity of Menu Column
percent_menu_qty = []
for i in df['Sales Quantity']:
i = round(i/df['Sales Quantity'].sum() * 100, 2)
percent_menu_qty.append(i)
df['% Quantity of Menu'] = percent_menu_qty
df
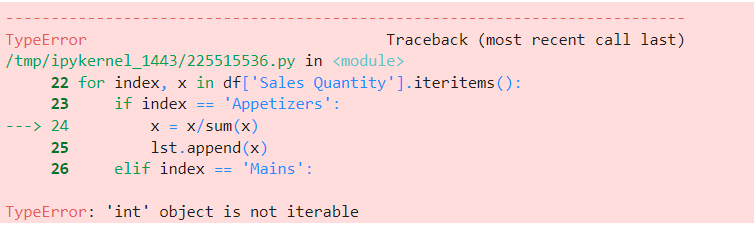
我不知道該怎么做是第二個。我嘗試設定Menu Category為索引并執行以下操作:
# Add % Quantity of Menu Category Column
df = df.set_index('Menu Category')
lst = []
for index, x in df['Sales Quantity'].iteritems():
if index == 'Appetizers':
x = x/sum(x)
lst.append(x)
elif index == 'Mains':
x = x/sum(x)
lst.append(x)
elif index == 'Desserts':
x =x/sum(x)
lst.append(x)
lst
我知道我需要以某種方式為每個設定一個條件,Menu Category然后index == 'a certain menu category value'將數量除以該選單類別的總和。到目前為止,我還無法弄清楚。
uj5u.com熱心網友回復:
首先,我要稱贊您逐行使用綜合。我仍然不時使用它們,因為我認為回圈更容易讓其他人閱讀和理解原理是什么,而無需運行代碼本身。
但是呀。對于這個解決方案,我創建了一對一對,讓我解釋一下每個是什么。
df['% Quantity of Menu'] = ((df['Sales Quantity']/df['Sales Quantity'].sum())*100).round(2)
對于您的第一個問題,不是逐行回圈,而是將列值除以標量值(這是列的總和df['Sales Quantity'].sum()),然后將比率乘以 100 的百分比,然后在 2 個小數點處四舍五入。
df['%Qty of Menu Category'] = ((df['Sales Quantity']/df.groupby(['Menu Category'])['Sales Quantity'].transform('sum'))*100).round(2)
所以,對于第二個問題,我們需要將列值除以每個對應類別的總和,而不是整列。因此,我們使用 groupby 為每個 category 獲取值df.groupby(['Menu Category'])['Sales Quantity'].transform('sum'),然后通過替換代碼部分來執行與第一個相同的操作。在這里,為什么我們使用df.groupby(['Menu Category'])['Sales Quantity'].transform('sum')而不是df.groupby(['Menu Category'])['Sales Quantity'].sum()?因為對于一個系列的劃分可以用一個標量或一系列相同的維度來完成,而前一種方式給了我們相同維度的系列。
df['Sales Quantity']
0 100
1 50
2 40
3 200
4 400
5 250
6 100
7 120
8 50
Name: Sales Quantity, dtype: int64
df.groupby(['Menu Category'])['Sales Quantity'].transform('sum')
0 190
1 190
2 190
3 850
4 850
5 850
6 270
7 270
8 270
Name: Sales Quantity, dtype: int64
df.groupby(['Menu Category'])['Sales Quantity'].sum()
Menu Category
Appetizers 190
Desserts 270
Mains 850
Name: Sales Quantity, dtype: int64
uj5u.com熱心網友回復:
我認為您正在尋找groupby transformsum以獲得“類別”總和;然后將每個“銷售數量”除以它們的“類別”總和。這為我們提供了每個選單項在其選單類別中的份額。
您還可以div對第一列使用矢量化方法而不是回圈:
df['%Qty of Menu'] = df['Sales Quantity'].div(df['Sales Quantity'].sum()).mul(100).round(2)
df['%Qty of Menu Cat'] = df.groupby('Menu Category')['Sales Quantity'].transform('sum').rdiv(df['Sales Quantity']).mul(100).round(2)
輸出:
Menu Category Menu Item Sales Quantity %Qty of Menu %Qty of Menu Cat
0 Appetizers Fries 100 7.63 52.63
1 Appetizers Poppers 50 3.82 26.32
2 Appetizers Wings 40 3.05 21.05
3 Mains Pasta 200 15.27 23.53
4 Mains Burger 400 30.53 47.06
5 Mains Pizza 250 19.08 29.41
6 Desserts Ice Cream 100 7.63 37.04
7 Desserts Cake 120 9.16 44.44
8 Desserts Fruit 50 3.82 18.52
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/437655.html
標籤:Python 熊猫 数据框 for循环 熊猫-groupby