我有一個帶有自定義缺失值的資料集,即字符“\?”,但缺失值的單元格還包含空格字符數不一致的空格。在我的示例圖片中,在第 11 行,它可能有 3 個空格或 4 個空格。
所以我的想法是str.strip()對每個單元格應用該函式以將其識別為缺失值并將其洗掉,但它仍然不被識別為缺失值。
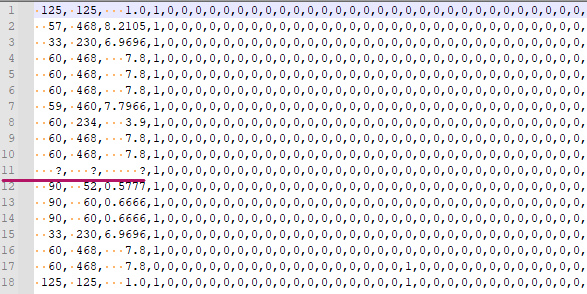
df = pd.read_csv('full_name', header=None, na_values=['?'])
df = df.apply(lambda x: x.str.strip() if x.dtype== 'object' else x)
df.dropna(axis=0, inplace=True, how='any')
df.head(20)]
解決這個問題的有效方法是什么?
uj5u.com熱心網友回復:
dropna丟棄 NaN 值。由于您的 NaN 實際上是?,您可以replace使用 NaN 并使用它們dropna:
df = df.replace('?', np.nan).dropna()
mask他們并使用dropna:
df = df.mask(df.eq('?')).dropna()
或者只是過濾掉這些行,只選擇沒有任何行的行?:
df = df[df.ne('?').all(axis=1)]
uj5u.com熱心網友回復:
采用:
df = pd.DataFrame({'test': [1,2, ' ? ', ' ? ']})
df[~df['test'].str.contains('\?', na=False)]
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/438119.html
上一篇:OCR:將單詞保存在CSV檔案中