本文主要描述了爬蟲在研招網上的使用,請使用者不要頻繁去運行代碼,對服務器造成壓力,否則后果自負,同時希望該代碼可以幫助正在考研學子們可以篩選出自己喜歡的學校,
1.首先登陸研招網資訊通過專業代碼查詢研招網上的專業代碼,
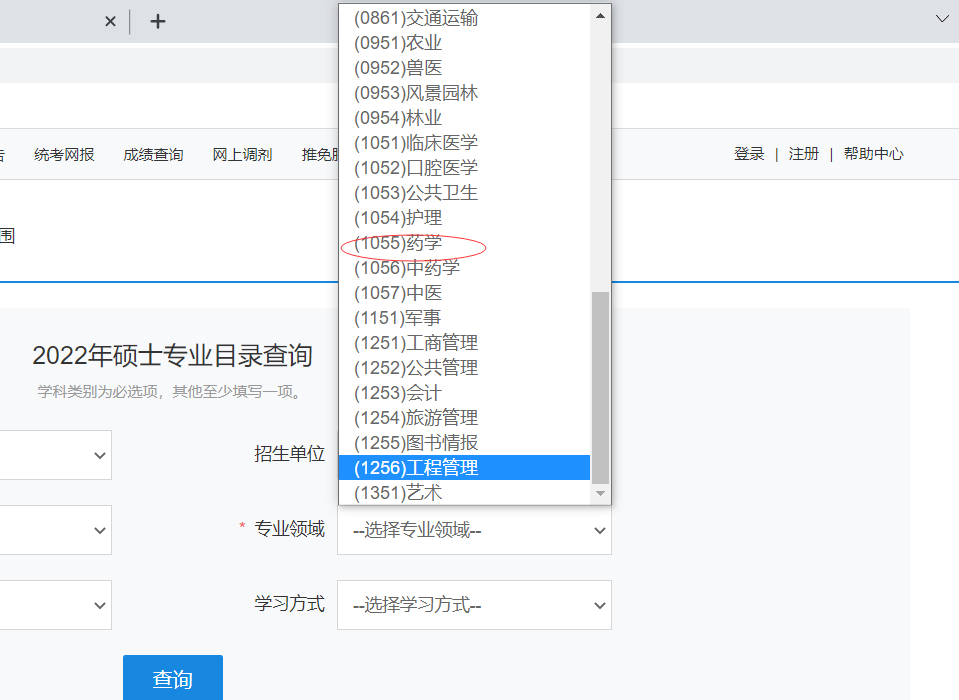
2.更改代碼中學校的代碼
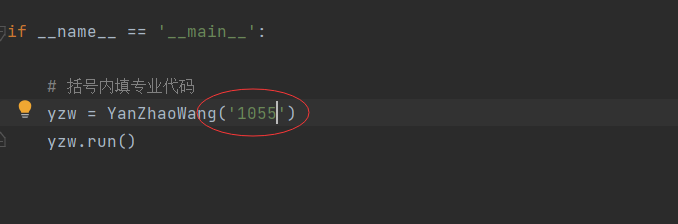
3.運行程式,代碼附在下方,運行結束后會自動生成一個文本txt,你想要的資訊就在里面,
import requests
from lxml import etree
import re
data =https://www.cnblogs.com/guiyan/p/{"ssdm":"","dwmc":"","mldm":"zyxw","mlmc":"","yjxkdm":"","zymc":"","xxfs":"","pageno":""
}
class UniversityInfo:
def __init__(self):
# 招生單位、考試方式、院系所、專業、學習方式、研究方向、指導老師、擬招人數、備注、政治、外語、業務課一、業務課二
self.EnrollmentUnit = ""
self.ExaminationMethod = ""
self.CollegesDepartments = ""
self.Major = ""
self.learningStyle = ""
self.ResearchDirection = ""
self.Instructor = ""
self.Number = ""
self.Remarks = ""
self.Politics = ""
self.English = ""
self.BusinessClass1 = ""
self.BusinessClass2 = ""
class YanZhaoWang:
def __init__(self,code):
self.url = "https://yz.chsi.com.cn/zsml/queryAction.do?ssdm&dwmc&mldm=zyxw&mlmc&yjxkdm={}&zymc&xxfs&pageno={}".format(code)
self.data = https://www.cnblogs.com/guiyan/p/data
self.data["yjxkdm"]=code
self.page = 1
self.schoolUrl = []
self.facultyUrl = []
self.schoolInfo = []
def GetFacultyUrl(self):
for i in self.schoolUrl:
response = requests.post("https://yz.chsi.com.cn"+i).text
response = etree.HTML(response)
url = response.xpath('//table/tbody//td[8]/a/@href')
for i in url:
print(i)
self.facultyUrl.append(i)
def GetSchoolInfo(self):
for i in self.facultyUrl:
response = requests.post("https://yz.chsi.com.cn/"+i).text
response = etree.HTML(response)
schoolinfo = UniversityInfo()
schoolinfo.EnrollmentUnit = response.xpath('//table[@]/tbody/tr[1]/td[2]/text()')[0]
schoolinfo.ExaminationMethod = response.xpath('//table[@]/tbody/tr[1]/td[4]/text()')[0]
schoolinfo.CollegesDepartments = response.xpath('//table[@]/tbody/tr[2]/td[2]/text()')[0]
schoolinfo.Major = response.xpath('//table[@]/tbody/tr[2]/td[4]/text()')[0]
schoolinfo.learningStyle = response.xpath('//table[@]/tbody/tr[3]/td[2]/text()')[0]
schoolinfo.ResearchDirection = response.xpath('//table[@]/tbody/tr[3]/td[4]/text()')[0]
schoolinfo.Instructor = response.xpath('//table[@]/tbody/tr[4]/td[2]/text()')
schoolinfo.Number = response.xpath('//table[@]/tbody/tr[4]/td[4]/text()')[0]
schoolinfo.Remarks = response.xpath('//table[@]/tbody/tr[5]/text()')[0]
table = response.xpath('//tbody[@]')
for i in table:
schoolinfo.Politics = i.xpath('tr/td[1]/text()')[0]
schoolinfo.English = i.xpath('tr/td[2]/text()')[0]
schoolinfo.BusinessClass1 = i.xpath('tr/td[3]/text()')[0]
schoolinfo.BusinessClass1 = i.xpath('tr/td[4]/text()')[0]
self.schoolInfo.append(schoolinfo)
def GetSchoolUrl(self,url):
response = requests.post(url).text
response = etree.HTML(response)
page = response.xpath('//li[@]/a/@onclick')
url = response.xpath('//*[@id="form3"]/a/@href')
for i in url:
self.schoolUrl.append(i)
print(page)
if page!=[]:
self.page += 1
self.GetSchoolUrl(self.url.format(self.page))
def WriteSchool(self):
with open("./text.txt",'a',encoding="utf-8")as f:
for i in self.schoolInfo:
print(i.EnrollmentUnit)
f.write(self.Tostring(i.EnrollmentUnit)+"\t"+self.Tostring(i.ExaminationMethod)+"\t"+self.Tostring(i.CollegesDepartments)+"\t"+self.Tostring(i.Major)+"\t"+self.Tostring(i.learningStyle)+"\t"+self.Tostring(i.ResearchDirection)+"\t"+self.Tostring(i.Instructor)+"\t"+self.Tostring(i.Number)+"\t"+self.Tostring(i.Remarks)+"\t"+self.Tostring(i.Politics)+"\t"+self.Tostring(i.English)+"\t"+self.Tostring(i.BusinessClass1)+'\t'+self.Tostring(i.BusinessClass2)+'\n')
def Tostring(self,str):
str ="".join(str)
return re.sub("[\t\r\n]+","",str)
def run(self):
self.GetSchoolUrl(self.url.format(self.page))
self.GetFacultyUrl()
self.GetSchoolInfo()
self.WriteSchool()
if __name__ == '__main__':
# 括號內填專業代碼
yzw = YanZhaoWang('1055')
yzw.run()
代碼詳細解釋
代碼運行程序中需要requests、lxml、re庫
學校介紹是有UniversityInfo類以字典形式儲存的
YanZhaoWang類主要負責實作代碼的主要邏輯
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/438613.html
標籤:Python
上一篇:java中的列舉