在講到使用hash還是string存盤的選擇前,先了解Redis的hash和string結構,
以下資料引自老錢的Redis深度歷險,
string
string和hash都是Redis的一種資料結構,string結構常用來快取用戶資訊,通常將用戶資訊結構體使用JSON序列化成字串,然后將序列化后的字串存入Redis進行快取,
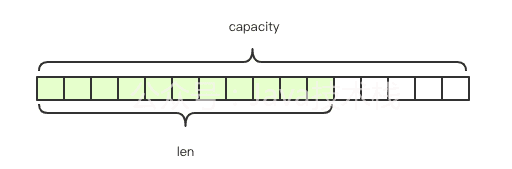
Redis的字串是動態字串,可以修改,內部結構類似于Java的ArrayList,采用預分配冗余空間的方式來減少記憶體的頻繁分配,如上圖鎖實,內部為當前字串實際分配的空間capacity,一般高于實際字串長度len,使用的指令有set, get, mset, mget等
hash
Redis的hash相當于Java的HashMap,內部結構實作與HashMap一致,即陣列+鏈表結構
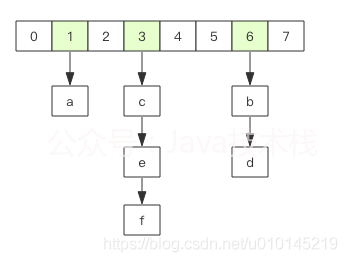
不過Redis的hash的值只能是字串,rehash方式不一樣,為了提高性能,Redis保留新舊兩個hash結構,采用漸進式rehash策略,查詢時會同事查詢兩個hash結構,在后續的定時任務中以及hash操作指令中,循序漸進將舊hash的內容遷移到xinhash中,直至完全取代舊hash,hash移除最后一個元素后會自動被洗掉,記憶體被回收,
前面說到string適合存盤用戶資訊,而hash結構也可以存盤用戶資訊,不過是對每個欄位單獨存盤,因此可以在查詢時獲取部分欄位的資訊,節省網路流量,
因此就引出了這篇文章,存盤結構體資訊是用hash還是string?
以下資訊出自StackOverflow Redis strings vs Redis hashes to represent JSON: efficiency?
I want to store a JSON payload into redis. There's really 2 ways I can do this:
1. One using a simple string keys and values.
key:user, value:payload (the entire JSON blob which can be 100-200 KB)
SET user:1 payload
2. Using hashes
HSET user:1 username "someone"
HSET user:1 location "NY"
HSET user:1 bio "STRING WITH OVER 100 lines"
Keep in mind that if I use a hash, the value length isn't predictable. They're not all short such as the bio example above.
Which is more memory efficient? Using string keys and values, or using a hash?
該用戶也是同樣的疑問,因為值的長度是不確定的,所以不知道采用string還是hash存盤更有效率
這個問題底下有個開發者回答的非常好,這里翻譯出來供大家一起學習討論,如果有更好的方案,歡迎提出來 首先,答者建議參考redis官方的記憶體優化的文章:https://redis.io/topics/memory-optimization,用來理解官方的開發者是記憶體優化方面基于什么考慮,
之后,答者列出了四個方案并給出了各個方案的利弊
1. 存盤整個物件,其中JSON序列化過的字串作為key
INCR id:users
SET user:{id} '{"name":"Fred","age":25}'
SADD users {id}
- 優勢:可以認為是“最佳實踐”,因為每個物件都是全特性的key,JSON決議特別塊,尤其是一次性查詢很多個欄位的時候
- 劣勢:如果只查詢一個欄位,速度就顯得比較慢了
2. 在hash中存盤每個物件的屬性
INCR id:users
HMSET user:{id} name "Fred" age 25
SADD users {id}
- 優勢:這也可以認為是最佳時間,每個物件都是一個全特性的key,不需要決議JSON字串
- 劣勢:如果要查詢物件的全部欄位會比較慢,嵌套型別的物件(即物件里面還包著物件)無法輕易存盤
3. 將物件轉化為JSON字串,用hash結構存盤
INCR id:users
HMSET users {id} '{"name":"Fred","age":25}'
這個方案可以僅用兩個key,不需要很多key,但是沒法對每個用戶物件設定TTL(Time to Live,剩余生存時間),因為物件僅僅是hash中的一個欄位,而不是全特性的key
- 優勢:JSON決議很快,尤其是一次查詢多個欄位時,對主key的命名空間污染更少
- 劣勢:如果要存盤很多物件,那么記憶體使用和方案1相當,當只需要查詢一個欄位時,會比方案2速度慢,答者不認為這是一個“最佳實踐”
4. 存盤物件的每個屬性作為單獨的key
INCR id:users
SET user:{id}:name "Fred"
SET user:{id}:age 25
SADD users {id}
根據上面的文章,即redis記憶體優化,這個方案不推薦(除非物件的屬性需要專門設定TTL或者別的設定)
- 優勢:物件的屬性是全特征key,對于應用來說比較好處理
- 劣勢:慢,記憶體消耗更大,不是一個“最佳實踐”,對主key的命名空間有很大污染
總的來說,方案4是最不推薦的,方案1和方案2非常相似,也很常見,答者更推薦方案1,因為這個方案允許存盤更復雜的物件(也就是說物件可以有很多層嵌套),方案3通常用在對命名空間比較有要求的場景下,比如說不想要太多key,不關心TTL等引數,
參考資料
《Redis深度歷險》
https://juejin.im/book/5afc2e5f6fb9a07a9b362527/section/5afc2e5f51882542714ff291
https://stackoverflow.com/questions/16375188/redis-strings-vs-redis-hashes-to-represent-json-efficiency
原文鏈接:https://blog.csdn.net/u010145219/article/details/99427693
著作權宣告:本文為CSDN博主「布魯斯1990」的原創文章,遵循CC 4.0 BY-SA著作權協議,轉載請附上原文出處鏈接及本宣告,
近期熱文推薦:
1.1,000+ 道 Java面試題及答案整理(2022最新版)
2.勁爆!Java 協程要來了,,,
3.Spring Boot 2.x 教程,太全了!
4.別再寫滿屏的爆爆爆炸類了,試試裝飾器模式,這才是優雅的方式!!
5.《Java開發手冊(嵩山版)》最新發布,速速下載!
覺得不錯,別忘了隨手點贊+轉發哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/440346.html
標籤:Java
下一篇:Spring的介面集合注入功能