我已經花了太多時間試圖弄清楚這一點——所以是時候尋求幫助了。我正在嘗試使用 lmfit 將兩個對數正態(a 和 c)以及這兩個對數正態(a c)的總和擬合到大小分布。模式 a 以 x=0.2 為中心,y=1,模式 c 以 x=1.2 為中心,y=<<<1。有許多大小分布 (>200),它們都略有不同,并從外部回圈傳遞到以下代碼。對于這個例子,我提供了一個真實的分布并且沒有包含回圈。希望我的代碼有足夠的注釋,以便理解我想要實作的目標。
我一定缺少對 lmfit 的一些基本理解(劇透警告——我的數學也不是很好),因為我有兩個問題:
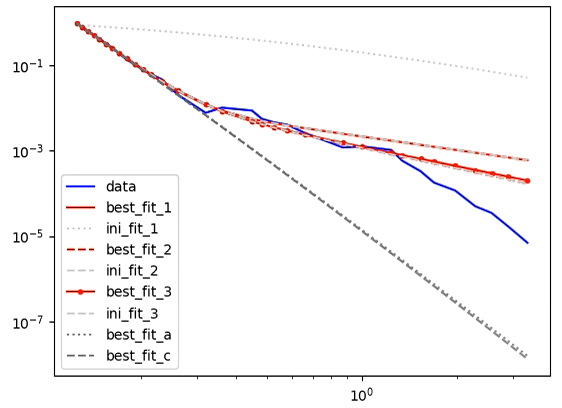
- 擬合(a、c 和 a c)不能準確地表示資料。注意擬合(紅色實線)如何偏離資料(藍色實線)。我認為這與初始猜測引數有關。我已經嘗試了很多,但無法很好地適應。
- 使用“新”最佳擬合值(結果 2、結果 3)重新運行模型似乎根本不會顯著改善擬合。為什么?
使用提供的 x 和 y 資料的示例結果:
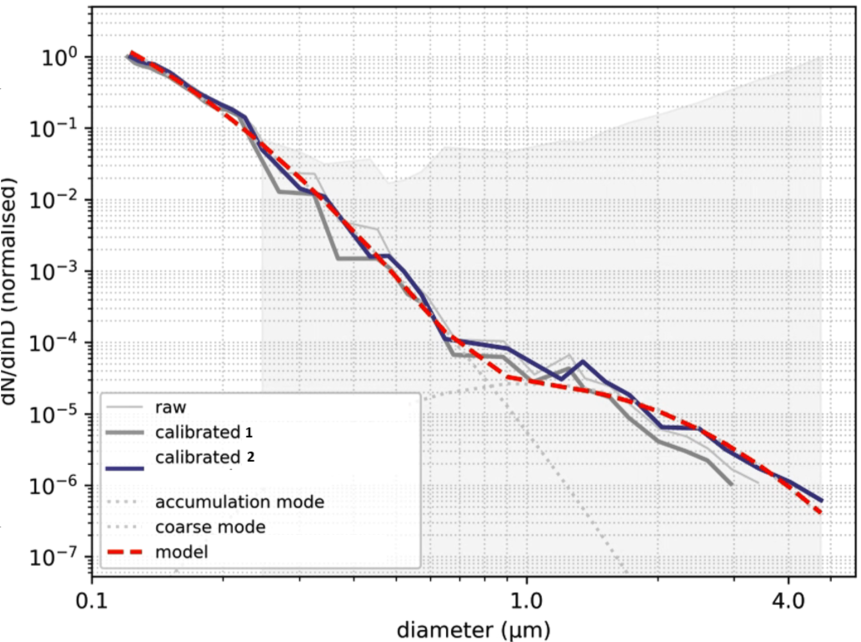
這是我之前制作的一個,顯示了我所追求的擬合型別(使用較舊的 mpfit 模塊生成,使用與下面提供的資料不同的資料并使用唯一的初始最佳猜測引數(不在回圈中)。請原諒圖例格式,我不得不洗掉某些資訊):
非常感謝任何幫助。這是帶有示例分布的代碼:
from lmfit import models
import matplotlib.pyplot as plt
import numpy as np
# real life data example
y = np.array([1.000000, 0.754712, 0.610303, 0.527856, 0.412125, 0.329689, 0.255756, 0.184424, 0.136819,
0.102316, 0.078763, 0.060896, 0.047118, 0.020297, 0.007714, 0.010202, 0.008710, 0.005579,
0.004644, 0.004043, 0.002618, 0.001194, 0.001263, 0.001043, 0.000584, 0.000330, 0.000179,
0.000117, 0.000050, 0.000035, 0.000017, 0.000007])
x = np.array([0.124980, 0.130042, 0.135712, 0.141490, 0.147659, 0.154711, 0.162421, 0.170855, 0.180262,
0.191324, 0.203064, 0.215738, 0.232411, 0.261810, 0.320252, 0.360761, 0.448802, 0.482528,
0.525526, 0.581518, 0.658988, 0.870114, 1.001815, 1.238899, 1.341285, 1.535134, 1.691963,
1.973359, 2.285620, 2.572177, 2.900414, 3.342739])
# create the joint model using prefixes for each mode
model = (models.LognormalModel(prefix='p1_')
models.LognormalModel(prefix='p2_'))
# add some best guesses for the model parameters
params = model.make_params(p1_center=0.1, p1_sigma=2, p1_amplitude=1,
p2_center=1, p2_sigma=2, p2_amplitude=0.000000000000001)
# bound those best guesses
# params['p1_amplitude'].min = 0.0
# params['p1_amplitude'].max = 1e5
# params['p1_sigma'].min = 1.01
# params['p1_sigma'].max = 5
# params['p1_center'].min = 0.01
# params['p1_center'].max = 1.0
#
# params['p2_amplitude'].min = 0.0
# params['p2_amplitude'].max = 1
# params['p2_sigma'].min = 1.01
# params['p2_sigma'].max = 10
# params['p2_center'].min = 1.0
# params['p2_center'].max = 3
# actually fit the model
result = model.fit(y, params, x=x)
# ====================================
# ================================
# re-run using the best-fit params derived above
params2 = model.make_params(p1_center=result.best_values['p1_center'], p1_sigma=result.best_values['p1_sigma'],
p1_amplitude=result.best_values['p1_amplitude'],
p2_center=result.best_values['p2_center'], p2_sigma=result.best_values['p2_sigma'],
p2_amplitude=result.best_values['p2_amplitude'], )
# re-fit the model
result2 = model.fit(y, params2, x=x)
# ================================
# re-run again using the best-fit params derived above
params3 = model.make_params(p1_center=result2.best_values['p1_center'], p1_sigma=result2.best_values['p1_sigma'],
p1_amplitude=result2.best_values['p1_amplitude'],
p2_center=result2.best_values['p2_center'], p2_sigma=result2.best_values['p2_sigma'],
p2_amplitude=result2.best_values['p2_amplitude'], )
# re-fit the model
result3 = model.fit(y, params3, x=x)
# ================================
# add individual fine and coarse modes using the revised fit parameters
model_a = models.LognormalModel()
params_a = model_a.make_params(center=result3.best_values['p1_center'], sigma=result3.best_values['p1_sigma'],
amplitude=result3.best_values['p1_amplitude'])
result_a = model_a.fit(y, params_a, x=x)
model_c = models.LognormalModel()
params_c = model_c.make_params(center=result3.best_values['p2_center'], sigma=result3.best_values['p2_sigma'],
amplitude=result3.best_values['p2_amplitude'])
result_c = model_c.fit(y, params_c, x=x)
# ====================================
plt.plot(x, y, 'b-', label='data')
plt.plot(x, result.best_fit, 'r-', label='best_fit_1')
plt.plot(x, result.init_fit, 'lightgrey', ls=':', label='ini_fit_1')
plt.plot(x, result2.best_fit, 'r--', label='best_fit_2')
plt.plot(x, result2.init_fit, 'lightgrey', ls='--', label='ini_fit_2')
plt.plot(x, result3.best_fit, 'r.-', label='best_fit_3')
plt.plot(x, result3.init_fit, 'lightgrey', ls='--', label='ini_fit_3')
plt.plot(x, result_a.best_fit, 'grey', ls=':', label='best_fit_a')
plt.plot(x, result_c.best_fit, 'grey', ls='--', label='best_fit_c')
plt.xscale("log")
plt.yscale("log")
plt.legend()
plt.show()
uj5u.com熱心網友回復:
我可以給出三個主要的建議:
- 初始值很重要,并且不應該太遠以至于使模型的某些部分對引數值完全不敏感。您的初始模型相差幾個數量級。
- 總是看合身的結果。這是主要結果——擬合圖是實際數值結果的表示。沒有顯示您列印了適合報告,這很好地表明您沒有查看實際結果。真的,總是看結果。
- 如果您根據資料和模型的圖來判斷擬合的質量,請使用您選擇的資料繪制方式來指導您如何擬合資料。特別是在您的情況下,如果您以對數比例繪制,則將資料的對數擬合到模型的對數:適合“對數空間”。
這樣的搭配可能看起來像這樣:
from lmfit import models, Model
from lmfit.lineshapes import lognormal
import matplotlib.pyplot as plt
import numpy as np
y = np.array([1.000000, 0.754712, 0.610303, 0.527856, 0.412125, 0.329689, 0.255756, 0.184424, 0.136819,
0.102316, 0.078763, 0.060896, 0.047118, 0.020297, 0.007714, 0.010202, 0.008710, 0.005579,
0.004644, 0.004043, 0.002618, 0.001194, 0.001263, 0.001043, 0.000584, 0.000330, 0.000179,
0.000117, 0.000050, 0.000035, 0.000017, 0.000007])
x = np.array([0.124980, 0.130042, 0.135712, 0.141490, 0.147659, 0.154711, 0.162421, 0.170855, 0.180262,
0.191324, 0.203064, 0.215738, 0.232411, 0.261810, 0.320252, 0.360761, 0.448802, 0.482528,
0.525526, 0.581518, 0.658988, 0.870114, 1.001815, 1.238899, 1.341285, 1.535134, 1.691963,
1.973359, 2.285620, 2.572177, 2.900414, 3.342739])
# use a model that is the log of the sum of two log-normal functions
# note to be careful about log(x) for x < 0.
def log_lognormal(x, amp1, cen1, sig1, amp2, cen2, sig2):
comp1 = lognormal(x, amp1, cen1, sig1)
comp2 = lognormal(x, amp2, cen2, sig2)
total = comp1 comp2
total[np.where(total<1.e-99)] = 1.e-99
return np.log(comp1 comp2)
model = Model(log_lognormal)
params = model.make_params(amp1=5.0, cen1=-4, sig1=1,
amp2=0.1, cen2=-1, sig2=1)
# part of making sure that the lognormals are strictly positive
params['amp1'].min = 0
params['amp2'].min = 0
result = model.fit(np.log(y), params, x=x)
print(result.fit_report()) # <-- HERE IS WHERE THE RESULTS ARE!!
# also, make a plot of data and fit
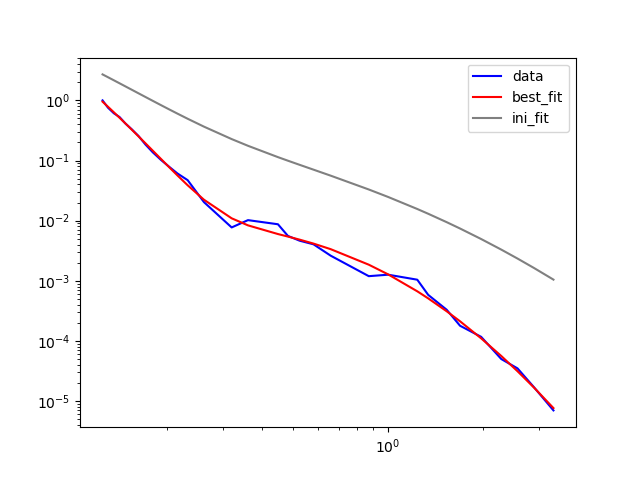
plt.plot(x, y, 'b-', label='data')
plt.plot(x, np.exp(result.best_fit), 'r-', label='best_fit')
plt.plot(x, np.exp(result.init_fit), 'grey', label='ini_fit')
plt.xscale("log")
plt.yscale("log")
plt.legend()
plt.show()
這將列印出來
[[Model]]
Model(log_lognormal)
[[Fit Statistics]]
# fitting method = leastsq
# function evals = 211
# data points = 32
# variables = 6
chi-square = 0.91190970
reduced chi-square = 0.03507345
Akaike info crit = -101.854407
Bayesian info crit = -93.0599914
[[Variables]]
amp1: 21.3565856 /- 193.951379 (908.16%) (init = 5)
cen1: -4.40637490 /- 3.81299642 (86.53%) (init = -4)
sig1: 0.77286862 /- 0.55925566 (72.36%) (init = 1)
amp2: 0.00401804 /- 7.5833e-04 (18.87%) (init = 0.1)
cen2: -0.74055538 /- 0.13043827 (17.61%) (init = -1)
sig2: 0.64346873 /- 0.04102122 (6.38%) (init = 1)
[[Correlations]] (unreported correlations are < 0.100)
C(amp1, cen1) = -0.999
C(cen1, sig1) = -0.999
C(amp1, sig1) = 0.997
C(cen2, sig2) = -0.964
C(amp2, cen2) = -0.940
C(amp2, sig2) = 0.849
C(sig1, amp2) = -0.758
C(cen1, amp2) = 0.740
C(amp1, amp2) = -0.726
C(sig1, cen2) = 0.687
C(cen1, cen2) = -0.669
C(amp1, cen2) = 0.655
C(sig1, sig2) = -0.598
C(cen1, sig2) = 0.581
C(amp1, sig2) = -0.567
并生成一個像
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/442933.html
上一篇:JMeterFor-Each控制器-似乎只運行前幾次迭代,然后停止
下一篇:php中的while演算法回圈