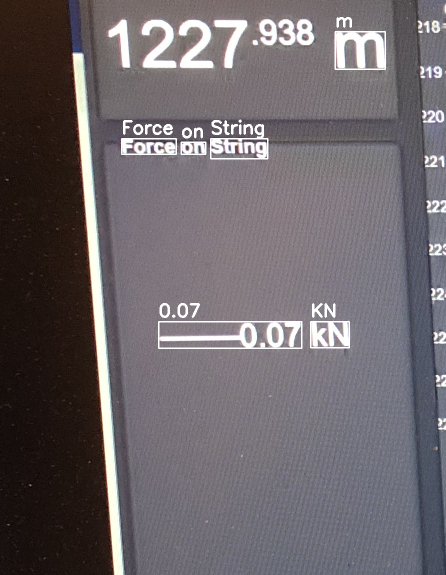
我的第一個猜測是image_to_data引數設定不正確。
檢查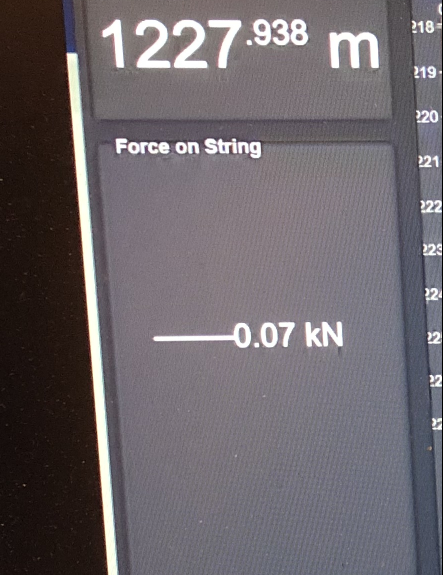
你有什么建議嗎?我在這里遺漏了一些明顯的東西嗎?
編輯:
應 Ann Zen 的要求,以下是用于獲取第一張影像的代碼:
import imutils
import cv2
import matplotlib.pyplot as plt
import numpy as np
import pytesseract
from pytesseract import Output
def get_grayscale(image):
return cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
filename = "IMAGE.JPG"
cropped_image = cv2.imread(filename)
inverted_cropped_image = cv2.bitwise_not(cropped_image)
gray = get_grayscale(inverted_cropped_image)
thresholded_image = cv2.threshold(gray, 100, 255, cv2.THRESH_BINARY)[1]
results = pytesseract.image_to_data(thresholded_image, config='--psm 11 --oem 3 -c tessedit_char_whitelist=0123456789m.', output_type=Output.DICT)
color = (255, 255, 255)
for i in range(0, len(results["text"])):
x = results["left"][i]
y = results["top"][i]
w = results["width"][i]
h = results["height"][i]
text = results["text"][i]
conf = int(results["conf"][i])
print("Confidence: {}".format(conf))
if conf > 70:
print("Confidence: {}".format(conf))
print("Text: {}".format(text))
print("")
text = "".join([c if ord(c) < 128 else "" for c in text]).strip()
cv2.rectangle(cropped_image, (x, y), (x w, y h), color, 2)
cv2.putText(cropped_image, text, (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX,1.2, color, 3)
cv2.imshow('Image', cropped_image)
cv2.waitKey(0)
uj5u.com熱心網友回復:
我使用 Tesseract 已經有一段時間了,所以讓我為你澄清一些事情。如果您嘗試比任何其他計算機視覺專案更多地識別檔案中的文本,Tesseract 將非常有用。它通常需要二值化影像才能獲得良好的輸出。因此,您總是需要一些影像預處理。
但是,在過去對所有頁面分割模式進行了幾次嘗試之后,我意識到當同一行的字體大小不同而沒有空格時,它會失敗。如果差異較小,有時 PSM 6 會有所幫助,但在您的情況下,您可以嘗試替代方案。如果您不關心小數,您可以嘗試以下解決方案:
img = cv2.imread(r'E:\Downloads\Iwzrg.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img_blur = cv2.GaussianBlur(gray, (3,3),0)
_,thresh = cv2.threshold(img_blur,200,255,cv2.THRESH_BINARY_INV)
# If using a fixed camera
new_img = thresh[0:100, 80:320]
text = pytesseract.image_to_string(new_img, lang='eng', config='--psm 6 --oem 3 -c tessedit_char_whitelist=0123456789')
輸出: 1227
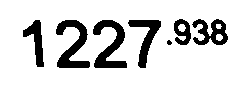
uj5u.com熱心網友回復:
我想推薦應用另一種影像處理方法。
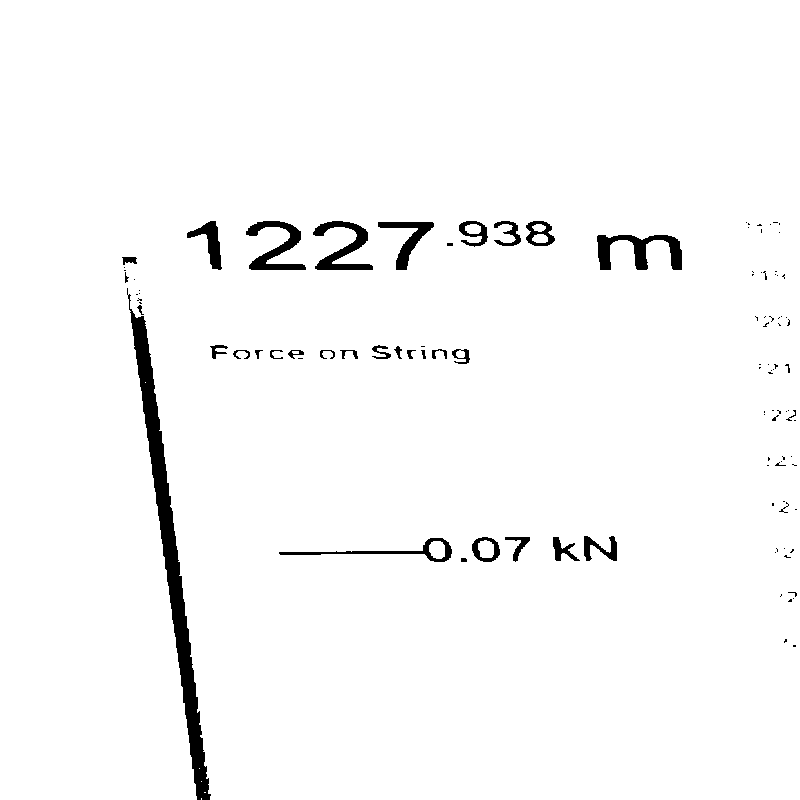
因為我正在處理深色背景,所以我首先反轉影像,然后將其轉換為灰度并對其進行閾值處理:
您應用了全域閾值,但無法達到預期的結果。
然后您可以應用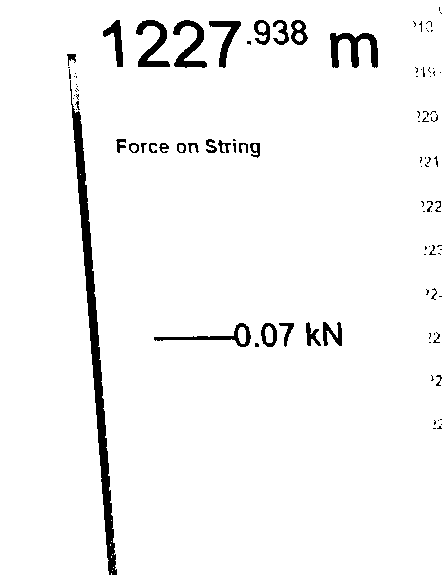
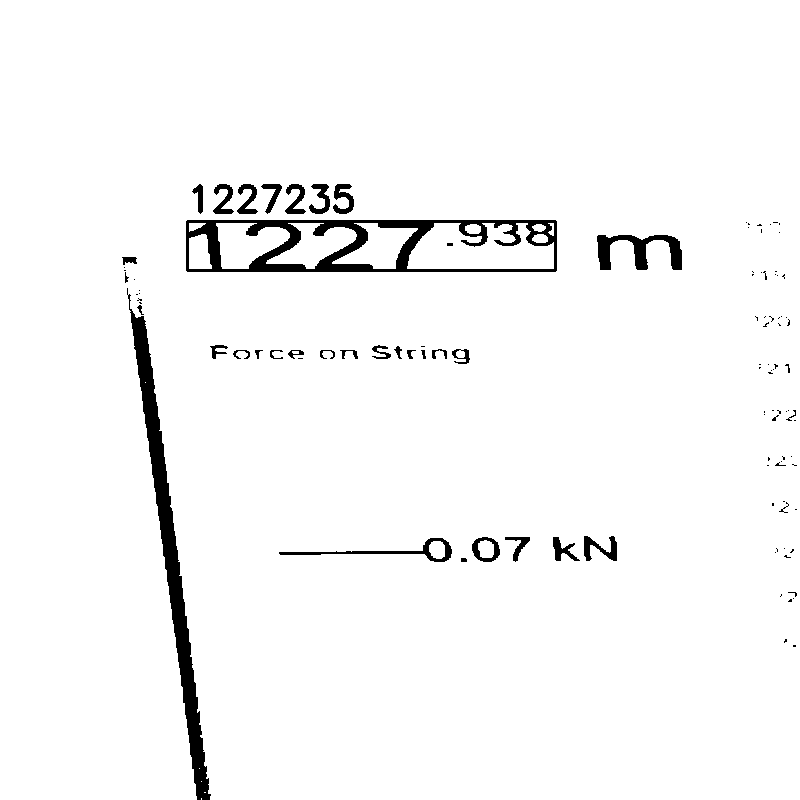
為了能夠盡可能準確地識別影像,我們可以在影像頂部添加邊框并調整影像大小(可選)
在 OCR 部分,檢查檢測到的區域是否包含數字
if text.isdigit():
然后在影像上顯示:
結果幾乎是期望值。現在您可以嘗試使用其他建議的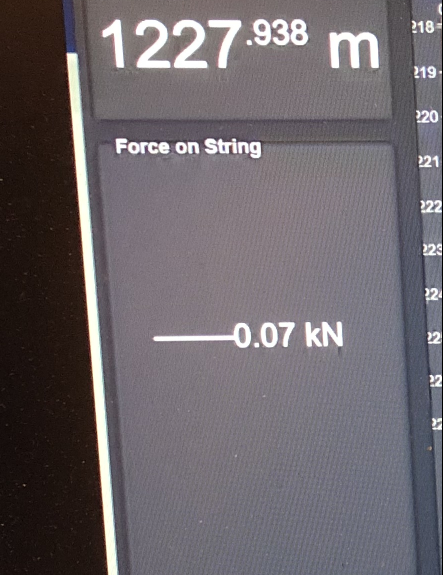
這是輸出影像:
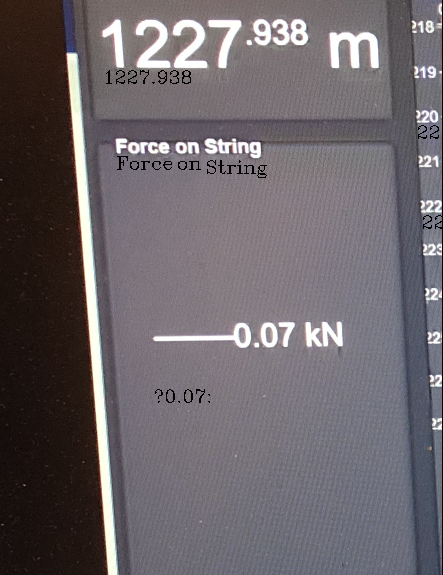
正如您在帖子中所說,唯一需要小數的部分1227.938。如果要過濾掉檢測到的其余文本,可以嘗試調整一些引數。例如,將180from _, thresh = cv2.threshold(gray, 180, 255, cv2.THRESH_BINARY)替換為230將產生輸出影像:
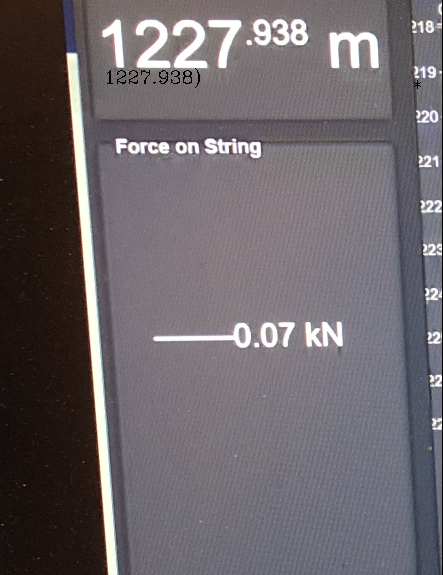
說明
- Import the necessary libraries:
import cv2
import numpy as np
import pytesseract
- Define a function,
process(), that will take in an image array, and return a binary image array that is the processed version of the image that will allow proper contour detection:
def process(img):
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
_, thresh = cv2.threshold(img_gray, 200, 255, cv2.THRESH_BINARY)
img_canny = cv2.Canny(thresh, 100, 100)
kernel = np.ones((3, 3))
img_dilate = cv2.dilate(img_canny, kernel, iterations=2)
return cv2.erode(img_dilate, kernel, iterations=2)
- I'm sure that you don't have to do this, but due to a problem in my environment, I have to add
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'before I can call thepytesseract.image_to_data()method, or it throws an error:
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
- Read in the original image, make a copy of it, and define the rough height of the large part of the decimal:
img = cv2.imread("image.png")
img_copy = img.copy()
hh = 50
- Detect the contours of the processed version of the image, and add a filter that roughly filters out the contours so that the small text remains:
contours, _ = cv2.findContours(process(img), cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
for cnt in contours:
if 20 * hh < cv2.contourArea(cnt) < 30 * hh:
- Define the bounding box of each contour that didn't get filtered out, and use the properties to enlarge those parts of the image to the height defined for the large text (making sure to also scale the width accordingly):
x, y, w, h = cv2.boundingRect(cnt)
ww = int(hh / h * w)
src_seg = img[y: y h, x: x w]
dst_seg = img_copy[y: y hh, x: x ww]
h_seg, w_seg = dst_seg.shape[:2]
dst_seg[:] = cv2.resize(src_seg, (ww, hh))[:h_seg, :w_seg]
- Finally, we can use the
pytesseract.image_to_data()method to detect the text. Of course, we'll need to threshold the image again:
gray = cv2.cvtColor(img_copy, cv2.COLOR_BGR2GRAY)
_, thresh = cv2.threshold(gray, 180, 255, cv2.THRESH_BINARY)
results = pytesseract.image_to_data(thresh)
for b in map(str.split, results.splitlines()[1:]):
if len(b) == 12:
x, y, w, h = map(int, b[6: 10])
cv2.putText(img, b[11], (x, y h 15), cv2.FONT_HERSHEY_COMPLEX, 0.6, 0)
cv2.imshow("Result", img)
cv2.waitKey(0)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/444632.html
標籤:opencv 图像处理 ocr python-正方体