我正在研究一個熊貓資料框,如果它只包含一個特定的單詞,我必須從中洗掉行。例如,
df = pd.DataFrame({'team': ['Team 1', 'Team 1 abc', 'Team 2',
'Team 3', 'Team 2', 'Team 3'],
'Subject': ['Math', 'Science', 'Science',
'Math', 'Science', 'Math'],
'points': [10, 8, 10, 6, 6, 5]})
我試圖洗掉Team 1單獨包含的行。為此我嘗試過,
df = df[df["team"].str.contains("Team 1") == False]
我得到了像
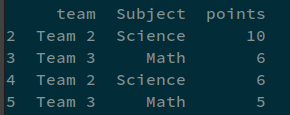
我需要的帶有行號的資料框也應該按順序排列
uj5u.com熱心網友回復:
只需使用!=而不是.str.contains:
df = df[df["team"] != "Team 1"]
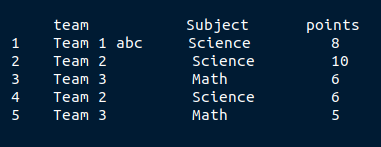
輸出:
>>> df
team Subject points
1 Team 1 abc Science 8
2 Team 2 Science 10
3 Team 3 Math 6
4 Team 2 Science 6
5 Team 3 Math 5
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/445122.html