一、序言
在并發場景中,當熱點快取Key失效時,流量瞬間打到資料庫中,此所謂快取擊穿現象;當大范圍的快取Key失效時,流量也會打到資料庫中,此所謂快取雪崩現象,
當使用分布式行鎖時,能夠有效解決快取擊穿問題;當使用分布式表鎖時,能夠解決快取雪崩問題,實際操作中,分布式表鎖不在考慮范圍,理由是降低并發量,
本文將從另一個角度出發,將請求流量合并和拆分,以提高系統的并發量,
二、理論基礎
流量的合并與拆分原理是將多條請求合并成一條請求,執行后再將結果拆分,在資料庫與快取架構中,快取Key失效的瞬間,大量重復請求打到資料庫中,實際上除了第一條請求為有效請求,隨后的請求為無效請求,浪費資料庫連接資源,
流量的合并與拆分實踐是額外喚醒一個執行緒,每隔固定時間(比如200毫秒)發送合并后的請求,執行完成后將查詢結果進行拆分,分發到原始請求中,原始請求回應用戶請求,
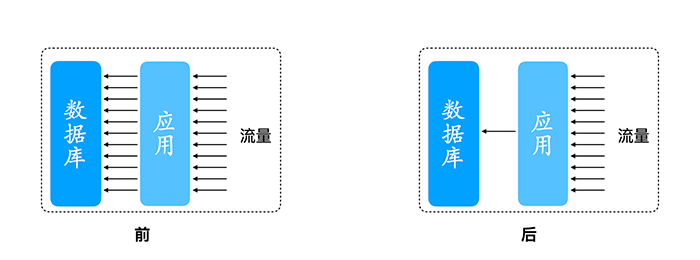
從應用到資料庫之間連接資源需求顯著下降,從而提高資料庫連接資源利用率,
三、應用實踐
(一)編碼與使用
基于MybatisPlus提供一個內置封裝的服務類QueueServiceImpl,透明的實作查詢詳情流量的合并與拆分,使用者可屏蔽內部實作,
<dependency>
<groupId>xin.altitude.cms</groupId>
<artifactId>ucode-cms-common</artifactId>
<version>1.4.4</version>
</dependency>
對于一定時間區間內的所有請求,合并成一條請求處理,
@Override
public BuOrder getOrderById(Long orderId) {
return getById(orderId);
}
舉例說明,如果特定時間區間內匯集了相同的主鍵請求,那么合并后的請求查詢一次資料庫便能夠回應所有的請求,
子類重寫父類方法,可修改合并與拆分的行為,
@Override
protected RequstConfig createRequstConfig() {
RequstConfig config = new RequstConfig();
/* 單次最大合并請求數量 */
config.setMaxRequestSize(100);
/* 核心執行緒池大小 */
config.setCorePoolSize(1);
/* 請求間隔(毫秒) */
config.setRequestInterval(200);
return config;
}
(二)實作細節
1、ConcurrentLinkedQueue
使用ConcurrentLinkedQueue并發安全佇列用于緩沖和接收請求,定時任務以固定頻率從佇列中消費資料,將多條請求條件合并后匯總查詢,
2、CompletableFuture
CompletableFuture類是合并與拆分的關鍵類,原始請求將查詢條件封裝成CompletableFuture物件,提交到佇列中后陷入阻塞,定時任務分批次組裝查詢條件,得到結果后將結果拆分并存入CompletableFuture物件中,原始請求執行緒被喚醒,繼續回應用戶請求,
3、ScheduledExecutorService
以一定的時間間隔發送合并后的請求,
(二)其它應用場景
應用于資料庫間流量的合并請求與拆分,首先提高資料庫連接資源(稀缺資源)利用率,其次提高網路間資料傳輸效率,100條資料收發100次與100條資料收發1次的效率差別,
1、服務間介面呼叫
服務間API介面呼叫同樣適用于流量的合并與拆分:比如向訂單服務發送Http API請求,同一時刻有100個用戶發起查詢請求,使用流量合并與拆分的思想可將多個訂單查詢請求轉換成批查詢請求,得到結果后分發到不同的請求執行緒,回應用戶請求,
四、小結
在本文中,選用的佇列是本地并發安全的佇列,在分布式系統中,本地佇列是否合適?此處選用本地佇列基于兩點考慮:一是無嚴格的分布式的需求;二是CompletableFuture類不支持序列化,考慮使用Redis做分布式佇列的想法無法實作,你用本地佇列,盡管會有少量查詢條件資料冗余(不影響結果),回避了分布式佇列的網路IO延遲,反而有更優的查詢效率,
本方案僅在高并發場景受益,屬于針對并發場景進行架構的優化,普通專案使用常規操作即可,
演示專案代碼地址
喜歡本文就【??推薦??】一下,激勵我持續創作,這個Github同樣精彩,收到您的star我會很激動,本文歸檔在專題博客,視頻講解在B站,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/445275.html
標籤:Java