預警
在本篇文章中,將為各位老鐵介紹不同的搜索演算法以及它們的復雜度,因為力求通俗易懂,所以篇幅可能較長,大伙可以先Mark下來,每天抽時間看一點理解一點,本文配套的Github,歡迎各位老鐵star,會一直更新的,
開篇
和排序類似,搜索或者叫做查找,也是平時我們使用最多的演算法之一,無論我們搜索資料庫還是檔案,實際上都在使用某種搜索演算法來定位想要查找的資料,
線性查找
執行搜索的最常見的方法是將每個專案與我們正在尋找的資料進行比較,這就是線性搜索或順序搜索,它是執行搜索的最基本的方式,如果串列中有n項,在最壞的情況下,我們必須搜索n個專案才能找到一個特定的專案,下面遍歷一個陣列來查找一個專案,
function linearSearch(array $arr, int $needle) {
for ($i = 0, $count = count($arr); $i < $count; $i++) {
if ($needle === $arr[$i]) {
return true;
}
}
return false;
}
線性查找的復雜度
| best time complexity | O(1) |
|---|---|
| worst time complexity | O(n) |
| Average time complexity | O(n) |
| Space time complexity | O(1) |
二分搜索
線性搜索的平均時間復雜度或最壞時間復雜度是O(n),這不會隨著待搜索陣列的順序改變而改變,所以如果陣列中的項按特定順序排序,我們不必進行線性搜索,我們可以通過執行選擇性搜索而可以獲得更好的結果,最流行也是最著名的搜索演算法是“二分搜索”,雖然有點像二叉搜索樹,但我們不用構造二叉搜索樹就可以使用這個演算法,
function binarySearch(array $arr, int $needle) {
$low = 0;
$high = count($arr) - 1;
while ($low <= $high) {
$middle = (int)(($high + $low) / 2);
if ($arr[$middle] < $needle) {
$low = $middle + 1;
} elseif ($arr[$middle] > $needle) {
$high = $middle - 1;
} else {
return true;
}
}
return false;
}
在二分搜索演算法中,我們從資料的中間開始,檢查中間的項是否比我們要尋找的項小或大,并決定走哪條路,這樣,我們把串列分成兩半,一半完全丟棄,像下面的影像一樣,
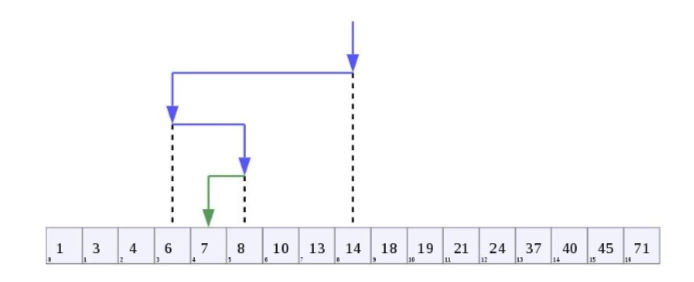
遞回版本:
function binarySearchRecursion(array $arr, int $needle, int $low, int $high)
{
if ($high < $low) return false;
$middle = (int)(($high + $low) / 2);
if ($arr[$middle] < $needle) {
return binarySearchRecursion($arr, $needle, $middle + 1, $high);
} elseif ($arr[$middle] > $needle) {
return binarySearchRecursion($arr, $needle, $low, $middle - 1);
} else {
return true;
}
}
二分搜索復雜度分析
對于每一次迭代,我們將資料劃分為兩半,丟棄一半,另一半用于搜索,在分別進行了1,2次和3次迭代之后,我們的串列長度逐漸減少到n/2,n/4,n/8...,因此,我們可以發現,k次迭代后,將只會留下n/2^k項,最后的結果就是 n/2^k = 1,然后我們兩邊分別取對數 得到 k = log(n),這就是二分搜索演算法的最壞運行時間復雜度,
| best time complexity | O(1) |
|---|---|
| worst time complexity | O(log n) |
| Average time complexity | O(log n) |
| Space time complexity | O(1) |
重復二分查找
有這樣一個場景,假如我們有一個含有重復資料的陣列,如果我們想從陣列中找到2的第一次出現的位置,使用之前的演算法將會回傳第5個元素,然而,從下面的影像中我們可以清楚地看到,正確的結果告訴我們它不是第5個元素,而是第2個元素,因此,上述二分搜索演算法需要進行修改,將它修改成一個重復的搜索,搜索直到元素第一次出現的位置才停止,

function repetitiveBinarySearch(array $data, int $needle)
{
$low = 0;
$high = count($data);
$firstIndex = -1;
while ($low <= $high) {
$middle = ($low + $high) >> 1;
if ($data[$middle] === $needle) {
$firstIndex = $middle;
$high = $middle - 1;
} elseif ($data[$middle] > $needle) {
$high = $middle - 1;
} else {
$low = $middle + 1;
}
}
return $firstIndex;
}
首先我們檢查mid所對應的值是否是我們正在尋找的值, 如果是,那么我們將中間索引指定為第一次出現的index,我們繼續檢查中間元素左側的元素,看看有沒有再次出現我們尋找的值, 然后繼續迭代,直到low >low>high, 如果沒有再次找到這個值,那么第一次出現的位置就是該項的第一個索引的值, 如果沒有,像往常一樣回傳-1,我們運行一個測驗來看代碼是否正確:
public function testRepetitiveBinarySearch()
{
$arr = [1,1,1,2,3,4,5,5,5,5,5,6,7,8,9,10];
$firstIndex = repetitiveBinarySearch($arr, 6);
$this->assertEquals(11, $firstIndex);
}
發現結果正確,

到目前為止,我們可以得出結論,二分搜索肯定比線性搜索更快,但是,這一切的先決條件是陣列已經排序,在未排序的陣列中應用二分搜索會導致錯誤的結果, 那可能存在一種情況,就是對于某個陣列,我們不確定它是否已排序,現在有一個問題就是,是否應該首先對陣列進行排序然后應用二分查找演算法嗎?還是繼續使用線性搜索演算法?
小思考
對于一個包含n個專案的陣列,并且它們沒有排序,由于我們知道二分搜索更快,我們決定先對其進行排序,然后使用二分搜索,但是,我們清楚最好的排序演算法,其最差的時間復雜度是O(nlogn),而對于二分搜索,最壞情況復雜度是O(logn),所以,如果我們排序后應用二分搜索,復雜度將是O(nlogn),
但是,我們也知道,對于任何線性或順序搜索(排序或未排序),最差的時間復雜度是O(n),顯然好于上述方案,
考慮另一種情況,即我們需要多次搜索給定陣列,我們將k表示為我們想要搜索陣列的次數,如果k為1,那么我們可以很容易地應用之前的線性搜索方法,如果k的值比陣列的大小更小,暫且使用n表示陣列的大小,如果k的值更接近或大于n,那么我們在應用線性方法時會遇到一些問題,假設k = n,線性搜索將具有O(n2)的復雜度,現在,如果我們進行排序然后再進行搜索,那么即使k更大,一次排序也只會花費O(nlogn)時間復,然后,每次搜索的復雜度是O(logn),n次搜索的復雜度是O(nlogn),如果我們在這里采取最壞的運行情況,排序后然后搜索k次總的的復雜度是O(nlogn),顯然這比順序搜索更好,
我們可以得出結論,如果一些搜索操作的次數比陣列的長度小,最好不要對陣列進行排序,直接執行順序搜索即可,但是,如果搜索操作的次數與陣列的大小相比更大,那么最好先對陣列進行排序,然后使用二分搜索,
二分搜索演算法有很多不同的版本,我們不是每次都選擇中間索引,我們可以通過計算作出決策來選擇接下來要使用的索引,我們現在來看二分搜索演算法的兩種變形:插值搜索和指數搜索,
插值搜索
在二分搜索演算法中,總是從陣列的中間開始搜索程序, 如果一個陣列是均勻分布的,并且我們正在尋找的資料可能接近陣列的末尾,那么從中間搜索可能不是一個好選擇, 在這種情況下,插值搜索可能非常有用,插值搜索是對二分搜索演算法的改進,插值搜索可以基于搜索的值選擇到達不同的位置,例如,如果我們正在搜索靠近陣列開頭的值,它將直接定位到到陣列的第一部分而不是中間,使用公式計算位置,如下所示
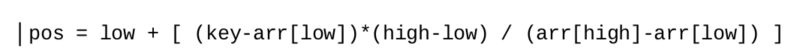
可以發現,我們將從通用的mid =(low * high)/2 轉變為更復雜的等式,如果搜索的值更接近arr[high],則此公式將回傳更高的索引,如果值更接近arr[low],則此公式將回傳更低的索引,
function interpolationSearch(array $arr, int $needle)
{
$low = 0;
$high = count($arr) - 1;
while ($arr[$low] != $arr[$high] && $needle >= $arr[$low] && $needle <= $arr[$high]) {
$middle = intval($low + ($needle - $arr[$low]) * ($high - $low) / ($arr[$high] - $arr[$low]));
if ($arr[$middle] < $needle) {
$low = $middle + 1;
} elseif ($arr[$middle] > $needle) {
$high = $middle - 1;
} else {
return $middle;
}
}
if ($needle == $arr[$low]) {
return $low;
}
return -1;
}
插值搜索需要更多的計算步驟,但是如果資料是均勻分布的,這個演算法的平均復雜度是O(log(log n)),這比二分搜索的復雜度O(logn)要好得多, 此外,如果值的分布不均勻,我們必須要小心, 在這種情況下,插值搜索的性能可以需要重新評估,下面我們將探索另一種稱為指數搜索的二分搜索變體,
指數搜索
在二分搜索中,我們在整個串列中搜索給定的資料,指數搜索通過決定搜索的下界和上界來改進二分搜索,這樣我們就不會搜索整個串列,它減少了我們在搜索程序中比較元素的數量,指數搜索是在以下兩個步驟中完成的:
- 我們通過查找第一個指數k來確定邊界大小,其中值2^k的值大于搜索項, 現在,2k和2(k-1)分別成為上限和下限,
- 使用以上的邊界來進行二分搜索,
下面我們來看下PHP實作的代碼
function exponentialSearch(array $arr, int $needle): int
{
$length = count($arr);
if ($length == 0) return -1;
$bound = 1;
while ($bound < $length && $arr[$bound] < $needle) {
$bound *= 2;
}
return binarySearchRecursion($arr, $needle, $bound >> 1, min($bound, $length));
}
我們把$needle出現的位置記位i,那么我們第一步花費的時間復雜度就是O(logi),表示為了找到上邊界,我們的while回圈需要執行O(logi)次,因為下一步應用一個二分搜索,時間復雜度也是O(logi),我們假設j是我們上一個while回圈執行的次數,那么本次二分搜索我們需要搜索的范圍就是2^j-1 至 2^j,而j=logi,即
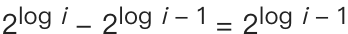
那我們的二分搜索時間復雜度需要對這個范圍求log2,即
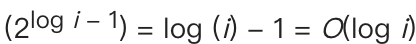
那么整個指數搜索的時間復雜度就是2 O(logi),省略掉常數就是O(logi),
| best time complexity | O(1) |
|---|---|
| worst time complexity | O(log i) |
| Average time complexity | O(log i) |
| Space time complexity | O(1) |
哈希查找
在搜索操作方面,哈希表可以是非常有效的資料結構,在哈希表中,每個資料都有一個與之關聯的唯一索引,如果我們知道要查看哪個索引,我們就可以非常輕松地找到對應的值,通常,在其他編程語言中,我們必須使用單獨的哈希函式來計算存盤值的哈希索引,散列函式旨在為同一個值生成相同的索引,并避免沖突,
PHP底層C實作中陣列本身就是一個哈希表,由于陣列是動態的,不必擔心陣列溢位,我們可以將值存盤在關聯陣列中,以便我們可以將值與鍵相關聯,
function hashSearch(array $arr, int $needle)
{
return isset($arr[$needle]) ? true : false;
}
樹搜索
搜索分層資料的最佳方案之一是創建搜索樹,在第理解和實作樹中,我們了解了如何構建二叉搜索樹并提高搜索效率,并且介紹了遍歷樹的不同方法, 現在,繼續介紹兩種最常用的搜索樹的方法,通常稱為廣度優先搜索(BFS)和深度優先搜索(DFS),
廣度優先搜索(BFS)
在樹結構中,根連接到其子節點,每個子節點還可以繼續表示為樹, 在廣度優先搜索中,我們從節點(主要是根節點)開始,并且在訪問其他鄰居節點之前首先訪問所有相鄰節點, 換句話說,我們在使用BFS時必須逐級移動,
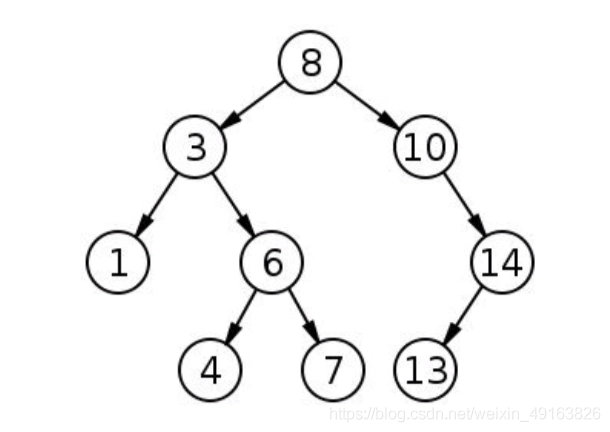
使用BFS,會得到以下的序列,
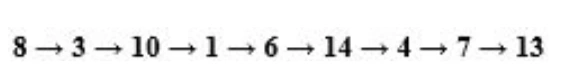
偽代碼如下:
procedure BFS(Node root)
Q := empty queue
Q.enqueue(root)
while(Q != empty)
u := Q.dequeue()
for each node w that is childnode of u
Q.enqueue(w)
end for each
end while
end procedure
下面是PHP代碼,
class TreeNode
{
public $data = https://www.cnblogs.com/it-abu/p/null;
public $children = [];
public function __construct(string $data = null)
{
$this->data = $data;
}
public function addChildren(TreeNode $treeNode)
{
$this->children[] = $treeNode;
}
}
class Tree
{
public $root = null;
public function __construct(TreeNode $treeNode)
{
$this->root = $treeNode;
}
public function BFS(TreeNode $node): SplQueue
{
$queue = new SplQueue();
$visited = new SplQueue();
$queue->enqueue($node);
while (!$queue->isEmpty()) {
$current = $queue->dequeue();
$visited->enqueue($current);
foreach ($current->children as $children) {
$queue->enqueue($children);
}
}
return $visited;
}
}
如果想要查找節點是否存在,可以為當前節點值添加簡單的條件判斷即可,BFS最差的時間復雜度是O(|V| + |E|),其中V是頂點或節點的數量,E則是邊或者節點之間的連接數,最壞的情況空間復雜度是O(|V|),
圖的BFS和上面的類似,但略有不同, 由于圖是可以回圈的(可以創建回圈),需要確保我們不會重復訪問同一節點以創建無限回圈, 為了避免重新訪問圖節點,必須跟蹤已經訪問過的節點,可以使用佇列,也可以使用圖著色演算法來解決,
深度優先搜索(DFS)
深度優先搜索(DFS)指的是從一個節點開始搜索,并從目標節點通過分支盡可能深地到達節點, DFS與BFS不同,簡單來說,就是DFS是深入挖掘而不是先擴散,DFS在到達分支末尾時然后向上回溯,并移動到下一個可用的相鄰節點,直到搜索結束,還是上面的樹
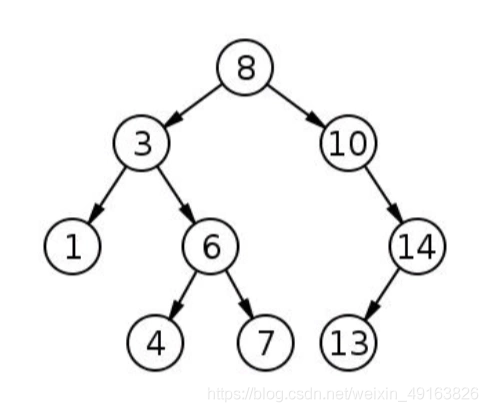
這次我們會獲得不通的遍歷順序:
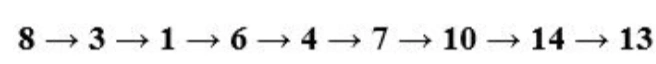
從根開始,然后訪問第一個孩子,即3,然后,到達3的子節點,并反復執行此操作,直到我們到達分支的底部,在DFS中,我們將采用遞回方法來實作,
procedure DFS(Node current)
for each node v that is childnode of current
DFS(v)
end for each
end procedure
public function DFS(TreeNode $node): SplQueue
{
$this->visited->enqueue($node);
if ($node->children) {
foreach ($node->children as $child) {
$this->DFS($child);
}
}
return $this->visited;
}
如果需要使用迭代實作,必須記住使用堆疊而不是佇列來跟蹤要訪問的下一個節點,下面使用迭代方法的實作
public function DFS(TreeNode $node): SplQueue
{
$stack = new SplStack();
$visited = new SplQueue();
$stack->push($node);
while (!$stack->isEmpty()) {
$current = $stack->pop();
$visited->enqueue($current);
foreach ($current->children as $child) {
$stack->push($child);
}
}
return $visited;
}
這看起來與BFS演算法非常相似,主要區別在于使用堆疊而不是佇列來存盤被訪問節點,它會對結果產生影響,上面的代碼將輸出8 10 14 13 3 6 7 4 1,這與我們使用迭代的演算法輸出不同,但其實這個結果沒有毛病,
因為使用堆疊來存盤特定節點的子節點,對于值為8的根節點,第一個值是3的子節點首先入堆疊,然后,10入堆疊,由于10后來入堆疊,它遵循LIFO,所以,如果我們使用堆疊實作DFS,則輸出總是從最后一個分支開始到第一個分支,可以在DFS代碼中進行一些小調整來達到想要的效果,
public function DFS(TreeNode $node): SplQueue
{
$stack = new SplStack();
$visited = new SplQueue();
$stack->push($node);
while (!$stack->isEmpty()) {
$current = $stack->pop();
$visited->enqueue($current);
$current->children = array_reverse($current->children);
foreach ($current->children as $child) {
$stack->push($child);
}
}
return $visited;
}
由于堆疊遵循Last-in,First-out(LIFO),通過反轉,可以確保先訪問第一個節點,因為顛倒了順序,堆疊實際上就作為佇列在作業,要是我們搜索的是二叉樹,就不需要任何反轉,因為我們可以選擇先將右孩子入堆疊,然后左子節點首先出堆疊,
DFS的時間復雜度類似于BFS,
點關注,不迷路
好了各位,以上就是這篇文章的全部內容了,能看到這里的人呀,都是人才,之前說過,PHP方面的技術點很多,也是因為太多了,實在是寫不過來,寫過來了大家也不會看的太多,所以我這里把它整理成了PDF和檔案,如果有需要的可以
點擊進入暗號: 博客園
更多學習內容可以訪問【對標大廠】精品PHP架構師教程目錄大全,只要你能看完保證薪資上升一個臺階(持續更新)
以上內容希望幫助到大家,很多PHPer在進階的時候總會遇到一些問題和瓶頸,業務代碼寫多了沒有方向感,不知道該從那里入手去提升,對此我整理了一些資料,包括但不限于:分布式架構、高可擴展、高性能、高并發、服務器性能調優、TP6,laravel,YII2,Redis,Swoole、Swoft、Kafka、Mysql優化、shell腳本、Docker、微服務、Nginx等多個知識點高級進階干貨需要的可以免費分享給大家,需要的可以加入我的PHP技術交流群953224940
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/4499.html
標籤:PHP