我有個問題。這是我最初的示例資料庫:
nam <- c("Marco", "Clara")
code <- c("The liquidations code for Marco are: 51-BMR05, 74-VAD08, 176-VNF09.",
"The liquidations code for Clara are: 88-BMR05, 90-VAD08, 152-VNF09.")
df <- data.frame(name,code)
看起來像這樣:

所以我想要的是將雙點之后的代碼分開并成為同名的記錄。也就是說資料庫是這樣改造完成的:
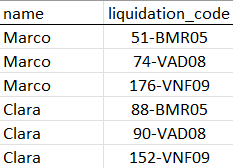
我需要知道 R 中是否有任何方法可以幫助我促進和加快這項作業。我在excel中做了例子。在此先感謝大家的幫助。
uj5u.com熱心網友回復:
這是一個整潔的解決方案:
library(tidyverse)
df %>%
# Remove text and trailing dot
mutate(
code = stringr::str_remove(
string = code,
pattern = "The liquidations code for .* are: "
),
code = stringr::str_remove(
string = code,
pattern = "\\.$"
)
) %>%
# Split the codes (results in list column)
mutate(code = stringr::str_split(code, ", ")) %>%
# Turn list column into new rows
unnest(code)
#> # A tibble: 6 × 2
#> name code
#> <chr> <chr>
#> 1 Marco 51-BMR05
#> 2 Marco 74-VAD08
#> 3 Marco 176-VNF09
#> 4 Clara 88-BMR05
#> 5 Clara 90-VAD08
#> 6 Clara 152-VNF09
由reprex 包創建于 2022-03-28 (v2.0.1)
資料
與 OP 發布的代碼相同,但固定nam為name:
name <- c("Marco", "Clara")
code <- c("The liquidations code for Marco are: 51-BMR05, 74-VAD08, 176-VNF09.",
"The liquidations code for Clara are: 88-BMR05, 90-VAD08, 152-VNF09.")
df <- data.frame(name,code)
uj5u.com熱心網友回復:
我用這個完成了輸出:
df1 <- separate_rows(df, code, sep=', ', convert = TRUE)
df1$liquidation_code <- gsub('The liquidations code for Marco are: |The liquidations code for Clara are: |\\.','',df1$code)
df1 <- df1[ , !(colnames(df1) %in% c('code'))]
df1
uj5u.com熱心網友回復:
這樣的事情應該有幫助
library(tidyverse)
#> Warning: package 'tidyr' was built under R version 4.1.3
#> Warning: package 'readr' was built under R version 4.1.3
#> Warning: package 'dplyr' was built under R version 4.1.3
name <- c("Marco", "Clara")
code <- c("The liquidations code for Marco are: 51-BMR05, 74-VAD08, 176-VNF09.",
"The liquidations code for Clara are: 88-BMR05, 90-VAD08, 152-VNF09.")
df_example <- data.frame(name,code)
df_example |>
mutate(codes = str_extract(code,pattern = "(?<=:). ") |>
str_split(',')) |>
unnest(codes) |>
mutate(codes = codes |> str_squish() |> str_remove('\\.'))
#> # A tibble: 6 x 3
#> name code codes
#> <chr> <chr> <chr>
#> 1 Marco The liquidations code for Marco are: 51-BMR05, 74-VAD08, 176-VNF0~ 51-B~
#> 2 Marco The liquidations code for Marco are: 51-BMR05, 74-VAD08, 176-VNF0~ 74-V~
#> 3 Marco The liquidations code for Marco are: 51-BMR05, 74-VAD08, 176-VNF0~ 176-~
#> 4 Clara The liquidations code for Clara are: 88-BMR05, 90-VAD08, 152-VNF0~ 88-B~
#> 5 Clara The liquidations code for Clara are: 88-BMR05, 90-VAD08, 152-VNF0~ 90-V~
#> 6 Clara The liquidations code for Clara are: 88-BMR05, 90-VAD08, 152-VNF0~ 152-~
由reprex 包創建于 2022-03-28 (v2.0.1)
uj5u.com熱心網友回復:
我們可以str_extract_all用來提取所有代碼list,然后unnest
library(dplyr)
library(stringr)
library(tidyr)
df %>%
mutate(code = str_extract_all(code, "\\d -[A-Z0-9] ")) %>%
unnest(code)
-輸出
# A tibble: 6 × 2
name code
<chr> <chr>
1 Marco 51-BMR05
2 Marco 74-VAD08
3 Marco 176-VNF09
4 Clara 88-BMR05
5 Clara 90-VAD08
6 Clara 152-VNF09
uj5u.com熱心網友回復:
使用正則運算式stringr
#build your df
name <- c("Marco", "Clara")
code <- c("The liquidations code for Marco are: 51-BMR05, 74-VAD08, 176-VNF09.",
"The liquidations code for Clara are: 88-BMR05, 90-VAD08, 152-VNF09.")
df <- data.frame(name,code)
# Processing
codes = stringr::str_extract_all(df$code, "([:alnum:] -[:alnum:] )")
names(codes) <- c(df$name)
liquidation_code = unlist(codes)
fix_names = substr(names(liquidation_code),1,nchar(names(liquidation_code))-1)
fix_df = data.frame(names = fix_names,liquidation_code)
names liquidation_code
Marco1 Marco 51-BMR05
Marco2 Marco 74-VAD08
Marco3 Marco 176-VNF09
Clara1 Clara 88-BMR05
Clara2 Clara 90-VAD08
Clara3 Clara 152-VNF09
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/451047.html