我有一個函式,它在其名稱的基礎上組織特定目錄中的檔案,基本上是根據其名稱拆分目錄中檔案的檔案,然后創建具有該名稱的檔案夾,然后包含該名稱的所有檔案移動到該檔案夾??中。例如,如果有兩個檔案wave.png,wave-edited.png它將創建一個名為的檔案夾wave,因為這兩個檔案包含關鍵字wave,它們將被移動到該檔案夾??中。我堅持弄清楚如何獲得關鍵字
List of file_names = ['ghosts-edited.png', 'ghosts.png', 'wave.png', 'wave-edited.png', '10-14-day', '12-11-day']
預期產出
['ghosts', 'wave', 'day']
代碼:
def name_category():
sub_file_names = []
file_names = []
delimiters = ['.', ',', '!', ' ', '-', ';', '?', '*', '!', '@', '#', '$', '%', '^', '&', '(', ')', '_', '/', '|', '<', '>']
try:
for filename in os.listdir(folder_to_track):
filename = filename.lower()
file_names.append(filename)
sub_file_names.append(max(re.findall(r'[A-Za-z] ',filename),key=len)) # I want to replace this method
sub_file_names = list(set(sub_file_names))
file_mappings = collections.defaultdict()
for filename in os.listdir(folder_to_track):
if not os.path.isdir(os.path.join(folder_to_track, filename)):
for sub_file_name in sub_file_names:
file_mappings.setdefault(sub_file_name, []).append(filename)
for folder_name, folder_items in file_mappings.items():
folder_path = os.path.join(folder_to_track, folder_name)
if not os.path.exists(folder_path):
os.mkdir(folder_path)
for filename in file_names:
filename = filename.lower()
i = 1
regexPattern = '|'.join(map(re.escape, delimiters))
splittedstring = re.split(regexPattern, filename, 0)
if folder_name in splittedstring:
new_name = filename
file_exits = os.path.isfile(folder_path '\\' new_name)
while file_exits:
i = 1
new_name = os.path.splitext(folder_to_track '\\' new_name)[0] str(i) os.path.splitext(folder_to_track '\\' new_name)[1]
new_name = new_name.split("\\")[4]
file_exits = os.path.isfile(folder_path "\\" new_name)
src = folder_to_track "\\" filename
new_name = folder_path "\\" new_name
os.rename(src, new_name)
except Exception as e:
print(e)
列印時子_file_names:
['ghosts', 'wave', 'edited']
現在,我正在使用名為sub_file_name的檔案名中的最大單詞過濾關鍵字。
更新
這是包含檔案的目錄
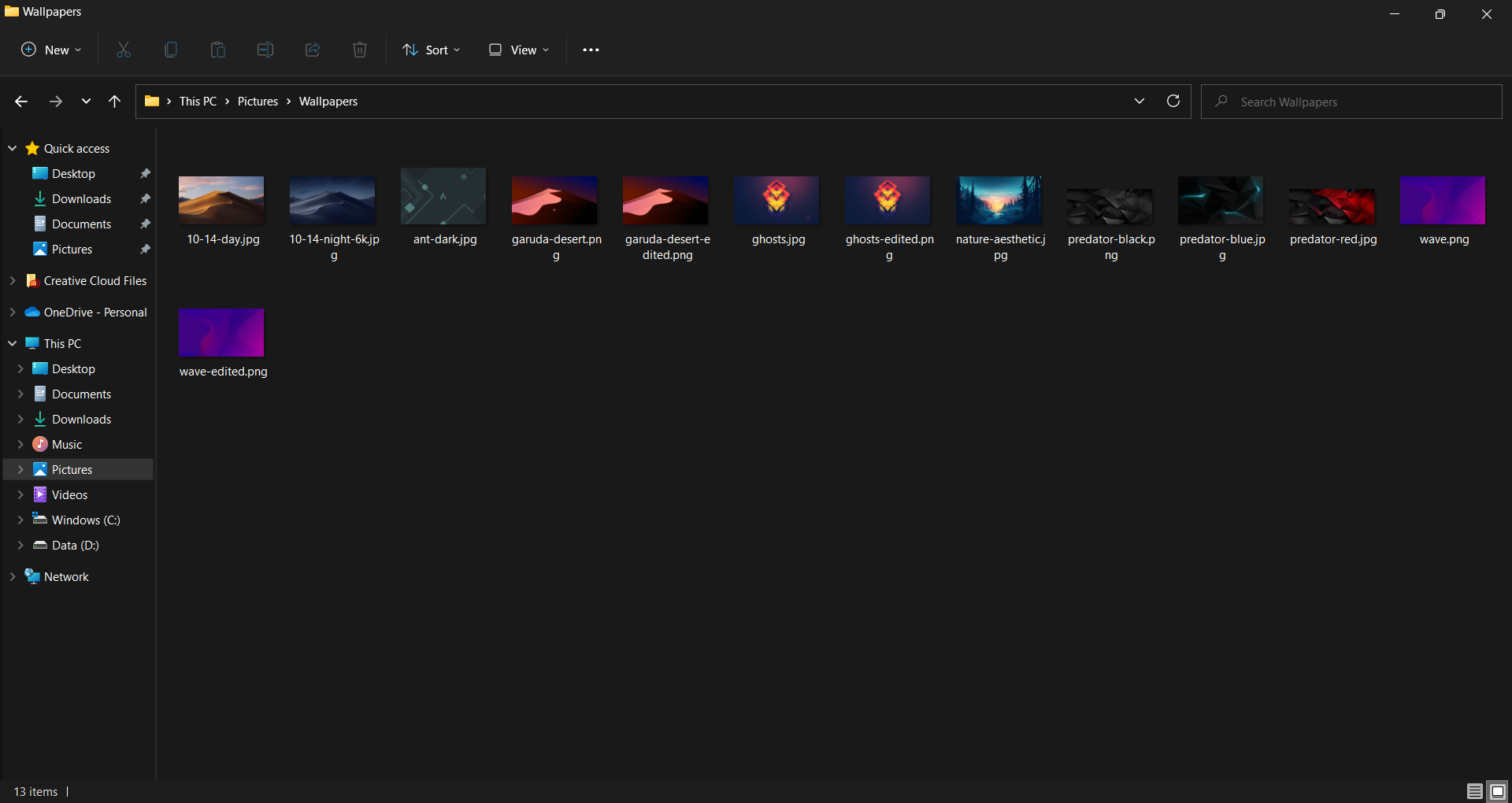
這是預期的產出
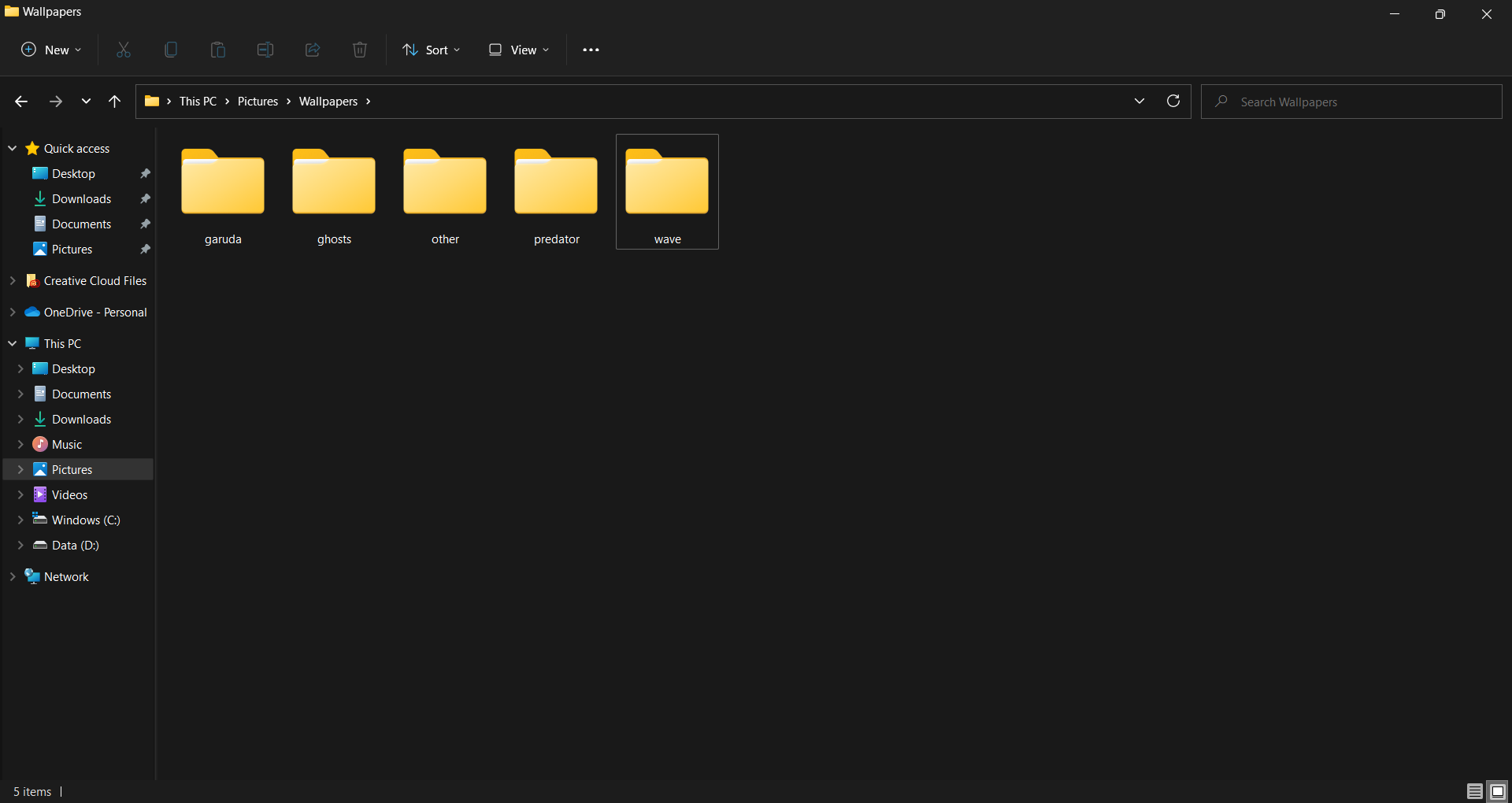
所有具有相同關鍵字的檔案,例如檔案wave.png并wave-edited.png包含關鍵字wave,因此創建了一個名為的檔案夾wave并將這些檔案移入其中,所有沒有重復關鍵字的檔案,如檔案ant-dark.png并nature-aesthetic.png移入other folder
uj5u.com熱心網友回復:
IIUC,您想要一種可以獲取第一個非單詞字符之前的名稱的方法。
代碼
from collections import Counter
def find_prefixes(strings):
'''
Finds common prefix in strings before non-alphanumeric character
Processing
- Separate each string in strings(list) into substrings by splitting non-alphanumeric boundaries
- Count occurence of substring based upon value and position (excluding suffixes)
- Filter (keep) substrings whose value & position is 2 or more
- Sort substrings value & position and counts (descending order by count, ascening by position)
- Get sorted substrings (value & position)
- Find which substrings are used in sorted list
'''
prefix_cnts = Counter() # Count of prefixes
pattern = re.compile('[^a-zA-Z0-9]') # pattern to detect non-alphanumeric character
for string in strings:
# Separate each string in strings(list) into substrings by splitting non-alphanumeric boundaries
arr = pattern.split(string) # single split on non-letter character
# Count occurence of substring based upon value and position (excluding suffixes)
for pos, prefix in enumerate(arr[:-1]):
if not prefix.isdigit():
prefix_cnts[f'{prefix} {pos}'] = 1 # Increment count of prefix at position pos
# Filter (keep) substrings whose value & position is 2 or more
prefix_cnts = {k:v for k, v in prefix_cnts.items() if v > 1}
# Sort substrings value & position and counts (descending order by count, ascening by position)
prefix_cnts = sorted(prefix_cnts.items(), key = lambda kv: (-kv[1], int(kv[0].split()[1])))
# Get sorted substrings (value & position)
prefixes = [k for k, v in prefix_cnts]
# Find which substrings are used in sorted list
prefix_cnts = Counter(prefixes)
for string in strings:
# Add first non-integer list
arr = pattern.split(string) # single split on non-letter character
for pos, prefix in enumerate(arr[:-1]): # use arr[:-1] to exclude file name suffixes
token = f'{prefix} {pos}'
if token in prefixes:
prefix_cnts[token] = 1 # Increment count of prefix at position pos
break
# Prefixes with count > 1
prefixes = {k.split()[0] for k, v in prefix_cnts.items() if v > 1}
# Generate string to prefix mapping
mapping = {}
for string in strings:
arr = pattern.split(string) # single split on non-letter character
for prefix in arr[:-1]: # use arr[:-1] to exclude file name suffixes
if prefix in prefixes:
mapping[string] = prefix
break
else:
mapping[string] = 'other'
return prefixes, mapping
測驗
# Using names from folder in posted image
file_names = ['10-14-day.jpg',
'10-14-night-6k.jpg',
'ant-dark.jpg',
'garuda-desert.png',
'garuda-desert-edited.png',
'ghosts.jpg',
'ghosts-edited.png',
'nature-aesthetic.jpg',
'predator-black.png',
'predator-blue.jpg',
'predator-red.jpg',
'wave.png',
'wave-edited.png']
folders, file_mapping = find_prefixes(file_names)
#print(f"Folder names: {folders}")
print("Folder names:", list(folders))
print("\nFile to folder name mapping:")
for k, v in file_mapping.items():
print(f"\t{k:>25} --> {v}")
輸出
Folder names: ['wave', 'garuda', 'predator', 'ghosts']
File to folder name mapping:
10-14-day.jpg --> other
10-14-night-6k.jpg --> other
ant-dark.jpg --> other
garuda-desert.png --> garuda
garuda-desert-edited.png --> garuda
ghosts.jpg --> ghosts
ghosts-edited.png --> ghosts
nature-aesthetic.jpg --> other
predator-black.png --> predator
predator-blue.jpg --> predator
predator-red.jpg --> predator
wave.png --> wave
wave-edited.png --> wave
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/451881.html
上一篇:在括號中的時間后添加換行符