圖論
圖論是數學的一個分支,它以圖為研究物件,圖論中的圖是由若干給定的點及連接兩點的線所構成的圖形,這種圖形通常用來描述某些事物之間的某種特定關系,用點代表事物,用連接兩點的線表示相應兩個事物間具有這種關系,
樹
樹是一種資料結構,它是由n(n≥1)個有限節點組成一個具有層次關系的集合,把它叫做“樹”是因為它看起來像一棵倒掛的樹,也就是說它是根朝上,而葉朝下的,它具有以下的特點:
其中每個元素稱為結點(node),每個節點有零個或多個子節點;沒有父節點的節點稱為根節點;每一個非根節點有且只有一個父節點;除了根節點外,每個子節點可以分為多個不相交的子樹,
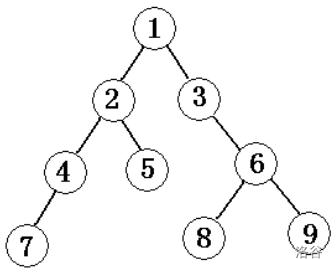
如圖是一棵樹:
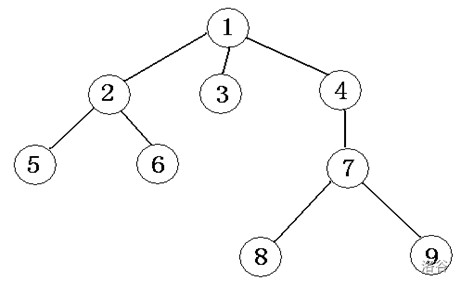
一棵樹中至少有1個結點,即根結點,
一個結點的子樹個數,稱為這個結點的度(如結點1的度為3,結點3的度為0),
度為0的結點稱為葉結點(leaf)(如結點3、5、6、8、9),
樹中各結點的度的最大值稱為這棵樹的度(此樹的度為3),
上端結點為下端結點的父結點,稱同一個父結點的多個子結點為兄弟結點(如結點1是結點2、3、4的父結點,結點 2、3、4是結點1的子結點,它們又是兄弟結點),
遍歷
樹結構解決問題時,按照某種次序獲得樹中全部結點的資訊,這種操作叫作樹的遍歷,
先序(根)遍歷
先訪問根結點,再從左到右按照先序思想遍歷各棵子樹(如,上圖先序遍歷的結果為125634789),
后序(根)遍歷
先從左到右遍歷各棵子樹,再訪問根結點(如,上圖后序遍歷的結果為562389741),
層次遍歷
按層次從小到大逐個訪問,同一層次按照從左到右的次序(如,上圖層次遍歷的結果為123456789),
葉結點遍歷
即從左到右遍歷所有葉節點(如,上圖葉節點遍歷的結果為56389),
二叉樹
二叉樹是一種特殊的樹型結構,它是度數為2的樹,即二叉樹的每個結點最多有兩個子結點,
每個結點的子結點分別稱為左兒子、右兒子,
五種基本形態
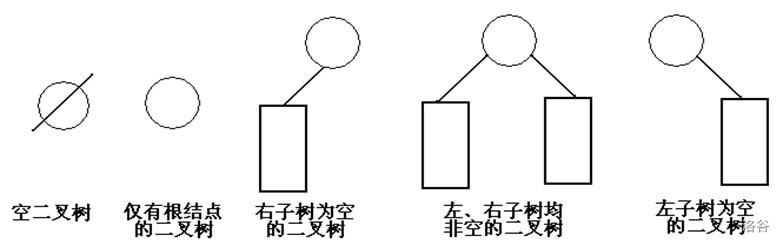
性質
性質一
二叉樹的第i層最多有2i-1個結點(i>=1)(可用二進制性質解釋,),
性質二
深度為k的二叉樹至多有2k–1個結點(k>=1),
性質三
任意一棵二叉樹,如果其葉結點數為n0,度為2的結點數為n2,則一定滿足:n0=n2+1,
性質四
有n個結點的完全二叉樹的深度為floor(log2n)+1,
性質五
一棵n個結點的完全二叉樹,對任一個結點(編號為i),有:如果i=1,則結點i為根,無父結點;如果i>1,則其父結點編號為floor(i/2),如果i為父節點編號,那么2i是左孩子,2i+1是右孩子,
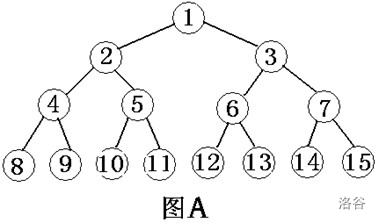
圖A-滿二叉樹
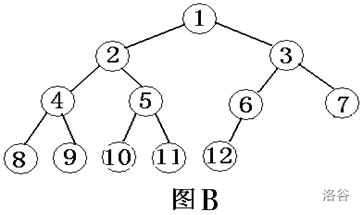
圖B-完全二叉樹
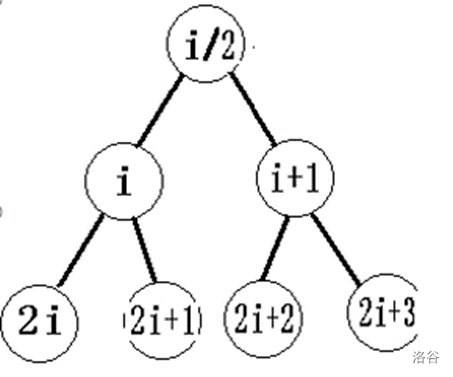
編號示意圖
遍歷
二叉樹的遍歷是指按一定的規律和次序訪問樹中的各個結點,
遍歷一般按照從左到右的順序,共有3種遍歷方法,先(根)序遍歷,中(根)序遍歷,后(根)序遍歷,
先序遍歷
若二叉樹為空,則空操作,否則:
訪問根結點、先序遍歷左子樹、先序遍歷右子樹
void preorder(tree bt)//先序遞回演算法
{
if(bt)
{
cout << bt->data;
preorder(bt->lchild);
preorder(bt->rchild);
}
}
先序遍歷此圖結果為:124753689
中序遍歷
若二叉樹為空,則空操作,否則:
中序遍歷左子樹、訪問根結點、中序遍歷右子樹
void inorder(tree bt)//中序遍歷遞回演算法
{
if(bt)
{
inorder(bt->lchild);
cout << bt->data;
inorder(bt->rchild);
}
}
中序遍歷上圖結果為:742513869
后序遍歷
若二叉樹為空,則空操作,否則:
后序遍歷左子樹、后序遍歷右子樹、訪問根結點
void postorder(tree bt)//后序遞回演算法
{
if(bt)
{
postorder(bt->lchild);
postorder(bt->rchild);
cout << bt->data;
}
}
后序遍歷上圖結果為:745289631
已知先序序列和中序序列可唯一確定一棵二叉樹;
已知中序序列和后序序列可唯一確定一棵二叉樹;
已知先序序列和后序序列不可唯一確定一棵二叉樹;
二叉樹操作(建樹、洗掉、輸出)
普通樹轉二叉樹
由于二叉樹是有序的,而且操作和應用更廣泛,所以在實際使用時,我們經常把普通樹轉換成二叉樹進行操作,
通用法則:“左孩子,右兄弟”
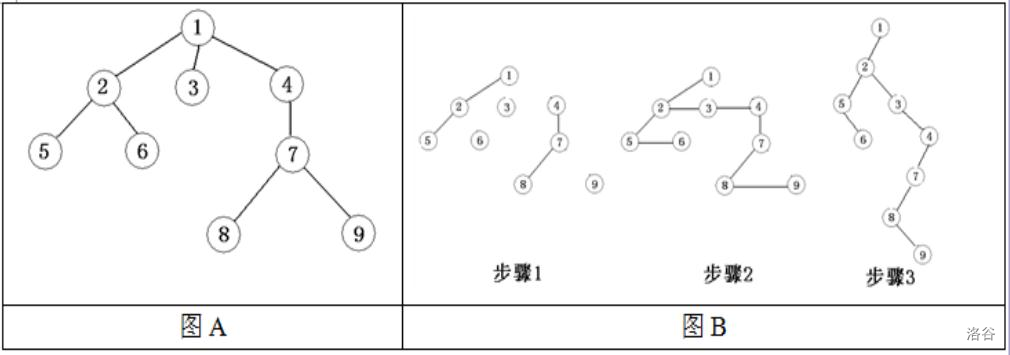
建樹

洗掉樹
插入一個結點到排序二叉樹中

在排序二叉樹中查找一個數

相關題目
擴展二叉樹
由于先序、中序和后序序列中的任一個都不能唯一確定一棵二叉樹,所以對二叉樹做如下處理,將二叉樹的空結點用“.”補齊,稱為原二叉樹的擴展二叉樹,擴展二叉樹的先序和后序序列能唯一確定其二叉樹,
現給出擴展二叉樹的先序序列,要求輸出其中序和后序序列,
輸入樣例:
ABD..EF..G..C..
輸出樣例:
DBFEGAC
DFGEBCA
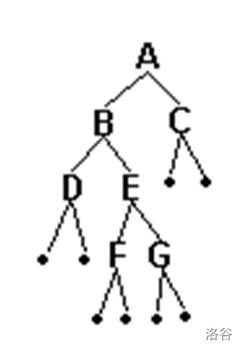


二叉樹的建立和輸出
以二叉鏈表作存盤結構,建立一棵二叉樹,并輸出該二叉樹的先序、中序、后序遍歷序列、高度和結點總數,
輸入樣例:
12##3##
//#為空
輸出樣例:
123
//先序排列
213
//中序排列
231
//后序排列
2
//高度
3
//結點總數
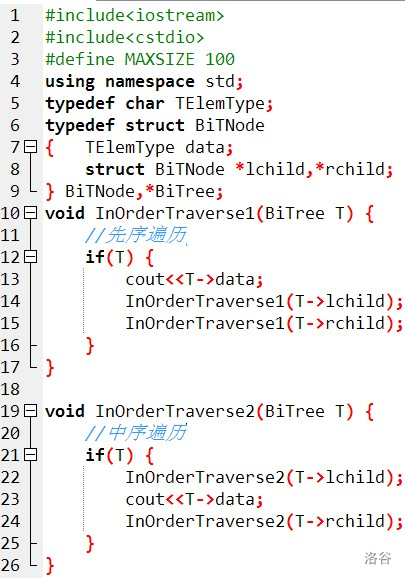
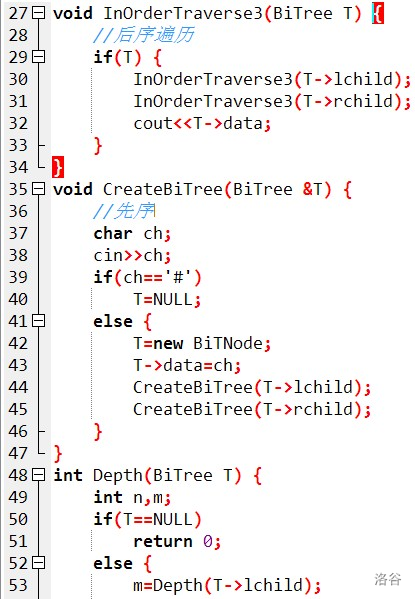
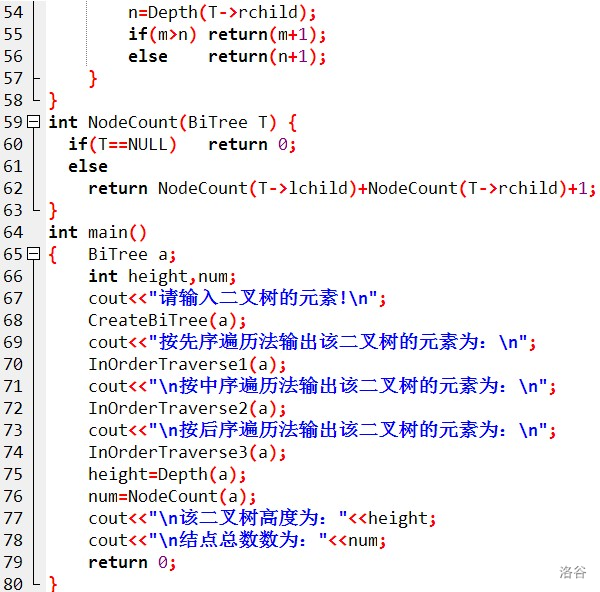
因為本蒟蒻不太會用指標,所以自己寫了一個不帶指標的,代碼很丑,見諒QwQ
#include<iostream>
#include<cstdio>
#define ll long long
using namespace std;
int top,maxh;
char s;
struct t{
int data,father,lson=0,rson=0,h=0;
//這里的father其實并沒有用,但記錄一下可以更方便地找到一個點的父節點
}tree[100005];
void build(int father,bool right){
cin>>s;
if(s=='\n')
return;
if(s!='#'){
++top;
int t=top;
tree[t].father=father;
tree[t].data=https://www.cnblogs.com/audrey-hall/archive/2022/03/29/s-'0';
tree[t].h=tree[father].h+1;
maxh=max(tree[t].h,maxh);
if(right==1)
tree[father].rson=t;
else
tree[father].lson=t;
build(t,0);
build(t,1);
}
else return;
}
void xian(int now){
cout<<tree[now].data;
if(tree[now].lson!=0)
xian(tree[now].lson);
if(tree[now].rson!=0)
xian(tree[now].rson);
}
void zhong(int now){
if(tree[now].lson!=0)
zhong(tree[now].lson);
cout<<tree[now].data;
if(tree[now].rson!=0)
zhong(tree[now].rson);
}
void hou(int now){
if(tree[now].lson!=0)
hou(tree[now].lson);
if(tree[now].rson!=0)
hou(tree[now].rson);
cout<<tree[now].data;
}
int main(){
build(0,0);
// for(int i=1;i<=top;i++){
// cout<<tree[i].data<<' '<<tree[i].father<<' ';
// cout<<tree[i].lson<<' '<<tree[i].rson<<' ';
// cout<<tree[i].h<<endl;;
// }
xian(1);
cout<<'\n';
zhong(1);
cout<<'\n';
hou(1);
cout<<'\n';
cout<<maxh<<'\n'<<top<<'\n';
return 0;
}
P1030 求先序排列
給出一棵二叉樹的中序與后序排列,求出它的先序排列,(約定樹結點用不同的大寫字母表示,長度<=8),
輸入:
2行,均為大寫字母組成的字串,表示一棵二叉樹的中序與 后序排列,
輸出:
1行,表示一棵二叉樹的先序,
輸入樣例:
BADC
BDCA
輸出樣例:
ABCD
分析
中序為BADC,后序為BDCA,所以A為根結點,B、DC分別為左右子樹的中序序列,B、DC分別為左右子樹的后序序列,然后再遞回處理中序為B,后序為B的子樹和中序為DC,后序為DC的子樹,
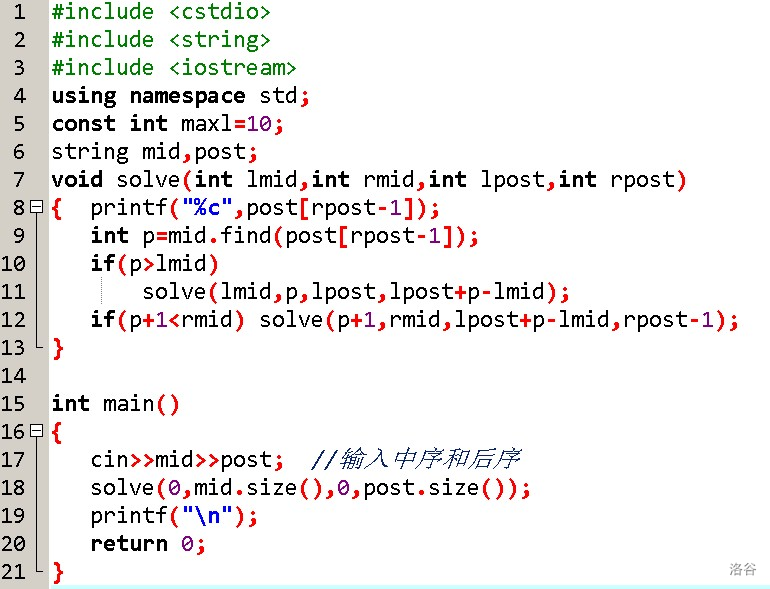
自己用char陣列寫的代碼QwQ
#include<iostream>
#include<cstring>
#include<cstdio>
#define ll long long
using namespace std;
char mid[10],post[10];
//mid陣列記錄中序排列,post陣列記錄后序排列
//除了打暴力最好不要用string
int z[10],m[10],p[10];
//z陣列做中轉使用,m陣列記錄mid陣列的內容,p陣列記錄post陣列的每一位在mid陣列中的位置
void find(int start,int end,int kai,int jie){
//start和end記錄我們正在找的mid陣列的范圍
//kai(開頭)和jie(結尾)記錄我們正在找的post陣列的范圍
if(start>end||kai>jie)return;
//如果開頭大于結尾,就回傳
if(start==end||kai==jie){
printf("%c",mid[p[jie]]);
return;
}
//如果開頭等于結尾,那此節點一定沒有兒子,輸出當前節點并回傳
printf("%c",mid[p[jie]]);
//前面說過后序排列的最后一位就是當前樹的根節點,所以p[jie]就是根節點在mid陣列中的位置
//開頭小于結尾,那就輸出當前節點然后再去尋找此節點的左兒子和右兒子
find(start,p[jie]-1,kai,kai+p[jie]-start-1);
//求左子樹的范圍,然后遞回尋找左兒子
find(p[jie]+1,end,kai+p[jie]-start,jie-1);
//求右子樹的范圍,然后遞回尋找右兒子
}
int main(){
scanf("%s%s",mid+1,post+1);
//輸入時下標從1開始(主要是因為我比較毛病)
int len=strlen(mid+1);
//輸入時下標從1開始那么計算字串長度時也要加1
for(int i=1;i<=len;i++){
m[i]=mid[i]-'A'+1;
//將每一位轉成數字以方便處理(是的,我很毛病)
z[m[i]]=i;
//z陣列記錄m陣列每一位的位置(這一步是為了方便后面記錄post數字)
}
for(int i=1;i<=len;i++){
p[i]=z[post[i]-'A'+1];
//記錄post陣列的每一位在mid陣列中的位置
//z:我滴任務完成啦!
}
find(1,len,1,len);
//開始遞回
return 0;
}
求后序排列
輸入:
二叉樹的前序序列與中序序列
輸出:
二叉樹的后序序列
樣例輸入:
abcdefg
cbdafeg
樣例輸出:
cdbfgea
#include<iostream>
#include<cstring>
#include<cstdio>
#define ll long long
using namespace std;
char qian[100005],zhong[100005];
int q[100005],z[100005],a[100005],cnt=0;
void find(int start,int end){
if(start>end){
return;
}
cnt++;
if(start==end){
cout<<char(z[q[cnt]]+'a'-1);
return;
}
int t=cnt;
find(start,q[t]-1);
find(q[t]+1,end);
cout<<char(z[q[t]]+'a'-1);
}
int main(){
cin>>qian>>zhong;
int len=strlen(qian);
for(int i=0;i<len;i++){
a[zhong[i]-'a']=i;
}
for(int i=0;i<len;i++){
z[i+1]=zhong[i]-'a'+1;
q[i+1]=a[qian[i]-'a']+1;
}
find(1,strlen(qian));
return 0;
}
因為有小可愛說我的代碼在輸入時的處理不清楚,所以又寫了一個版本QwQ
#include<iostream>
#include<cstring>
#include<cstdio>
#define ll long long
using namespace std;
char qian[100005],zhong[100005];
int q[100005],z[100005],a[100005],cnt=0;
void find(int start,int end){
// cout<<endl<<'*'<<start<<' '<<end<<'*'<<endl;
if(start>end){
return;
}
cnt++;
if(start==end){
cout<<char(z[q[cnt]]+'a'-1);
return;
}
int t=cnt;
find(start,q[t]-1);
find(q[t]+1,end);
cout<<char(z[q[t]]+'a'-1);
}
int main(){
// cin>>qian+1>>zhong+1;
scanf("%s%s",qian+1,zhong+1);//這里的輸入下標從1開始
int len=strlen(qian+1);
for(int i=1;i<=len;i++){
a[zhong[i]-'a']=i;
}
for(int i=1;i<=len;i++){
z[i]=zhong[i]-'a'+1;
q[i]=a[qian[i]-'a'];
}
find(1,len);
return 0;
}
運算式樹
關于運算式樹,我們可以分別用先序、中序、后序的遍歷方法得出完全不同的遍歷結果,如,對于下圖的遍歷結果如下,它們對應著運算式的3種表示方法,
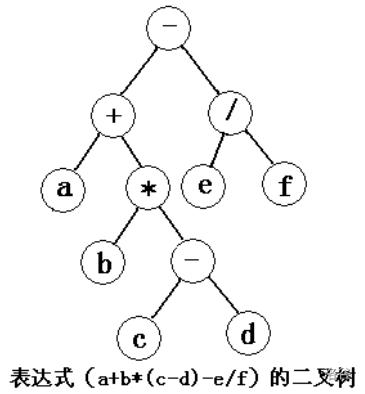
-+a*b-cd/ef (前綴表示、波蘭式)
a+b*(c-d)-e/f (中綴表示)
abcd-*+ef/- (后綴表示、逆波蘭式)
哈夫曼樹
QwQ,不是很會,那就推薦一篇博客吧,
前置知識
圖
如果資料元素集合中的各元素之間存在任意的關系,則此資料結構稱為圖,
如果將資料元素抽象為頂點(V),元素之間的關系用邊(E)表示,則圖亦可以表示為G=(V,E),其中V是頂點的有窮(非空)集合,E為邊的集合,
邊權
離散數學或資料結構中,圖的每條邊上帶的一個數值,它代表的含義可以是長度等等,這個值就是邊權,
頂點的度
與該頂點相關聯的邊的數目,有奇點、偶點之分,
入度(有向圖)
該頂點的入邊的數目,
出度(有向圖)
該頂點的出邊的數目,
補充:
一個圖中,全部頂點的度數之和為所有邊數的2倍;
有向圖中所有頂點的入度之和等于所有頂點的出度之和;
任意一個無向圖一定有偶數個奇點,
子圖
設兩個圖G=(V,E)和G’=(V’,E’),若V’是V的子集,且E’是E的子集,則稱G’是G的子圖,
路徑、簡單路徑、連通集
對于圖G=(V,E),對于頂點a、b,如果存在一些頂點序列x1=a,x2,……,xk=b(k>1),且(xi,xi+1)∈E,i=1,2…k-1,則稱頂點序列x1,x2,……,xk為頂點a到頂點b的一條路徑,而路徑上邊的數目(即k-1)稱為該路徑的長度,并稱頂點集合{x1,x2,……,xk}為一個連通集,
如果一條路徑上的頂點除了起點和終點可以相同外,其它頂點均不相同,則稱此路徑為一條簡單路徑,
回路
起點和終點相同的簡單路徑稱為回路(或環),
連通
在一個圖中,如果從頂點U到頂點V有路徑,則稱U和V是連通的,
連通圖
如果一個無向圖中,任意兩個頂點之間都是連通的,則稱該無向圖為連通圖,否則稱為非連通圖,
連通分量
一個無向圖的連通分量定義為該圖的最大連通子圖,
補充:
任何連通圖的連通分量只有一個,即本身,而非連通圖有多個連通分量,
強連通圖
在一個有向圖中,對于任意兩個頂點U和V,都存在著一條從U到V的有向路徑,同時也存在著一條從V到U的有向路徑,則稱該有向圖為強連通圖,
強連通分量
一個有向圖的強連通分量定義為該圖的最大的強連通子圖,
補充:
強連通圖只有一個強連通分量,即本身,非強連通圖有多個強連通分量,
圖的連通性判斷(用BFS和DFS實作)
分類
無向圖
邊集E(G)中為無向邊,
有向圖
邊集E(G)中為有向邊,
帶權圖
邊上帶有權的圖,也稱為網,(又分有向帶權圖、無向帶權圖)
完全圖
若是無向圖,則每兩個頂點之間都存在著一條邊;若是有向圖,則每兩個頂點之間都存在著方向相反的兩條邊,
補充:
一個n個頂點的完全無向圖含有n×(n-1)/2條邊;
一個n個頂點的完全有向圖含有n×(n-1)條邊,
稠密圖
邊數接近完全圖的圖,
稀疏圖
邊數遠遠少于完全圖的圖,
存盤
圖型結構的存盤分為靜態存盤和動態存盤,
鄰接矩陣
鄰接矩陣是表示頂點間相鄰關系的矩陣,若G=(V,E)是一個具有n個頂點的圖,則G的鄰接矩陣是如下定義的二維陣列a,其規模為n*n,
a[i,j]={1(或權),(vi,vj)∈E;
0(±∞),(vi,vj)?E}

//第8行將每一個點初始化為無窮大,表示不聯通,
//如果圖不帶權,可以用g[i][j]=0表示不連通,
#include<iostream>
using namespace std;
double g[101][101];//全為0,不通
int main(){
cin>>n;
//鄰接矩陣存盤
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++)
cin>>g[i][j];
for(int i=1;i<=n;i++){
int tot=0;
//統計每行數字1,即出度
for(int j=1;j<=n;j++)
if(g[i][j]>0)tot++;
a[i]=tot; //按行統計存盤
}
......
return 0;
}
特點
占用的存盤單元數只與頂點數n有關,與邊數無關,n*n的二維陣列,
方便度數的計算,
容易判斷兩點之間是否有邊相連,
尋找一個點相連的所有邊需要一個1到n的回圈,
鄰接表(用陣列+結構體模擬)
方法一
定義二維陣列g[101][101],g[i][0]表示i發出的邊的數量,g[i][j]表示i發出的第j條邊指向哪個頂點,
這樣就可以處理i發出的每條邊,也就能找到頂點i指向的頂點,
方法二
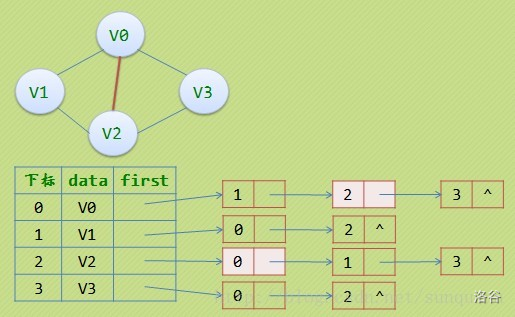
#include<iostream>
using namespace std;
const int maxn=1001,maxm=100001;
int head[maxn],num_edge,n,m,u,v;
struct Edge{
int next;//下一條邊的編號
int to;//這條邊到達的點
}edge[maxm];//結構體變數
void add_edge(int from,int to){
//加入一條從from到to的單向邊
edge[++num_edge].next=head[from];
edge[num_edge].to=to;
head[from]=num_edge;
}
int main(){
num_edge=0;
scanf("%d %d",&n,&m);//讀入點數和邊數
for(int i=1;i<=m;i++){
scanf("%d %d",&u,&v);//u、v之間有一條邊
add_edge(u,v);
}
int j,chudu[maxn];
for(int i=0;i<n;i++){
//求出每一個頂點的出度
int tot=0;
j=head[i];
while(j!=0){
tot++;
j=edge[j].next;
}
chudu[i]=tot;
}
......
return 0;
}
特點
適用于點多邊少的稀疏圖,
(對于有n個點,m條邊的稀疏圖來說,用鄰接矩陣存會開n2的空間;而鄰接表則是視邊數的多少來開記憶體大小)
可以快速找到與當前頂點相連的點,
(結構體的next指標比較方便)
判斷兩點是否相連不如鄰接矩陣快速,
(鄰接矩陣是看aij的數值,直接O(1)查詢即可;鄰接表判斷起來比較繁瑣,)
邊集陣列
是利用一維陣列存盤圖中所有邊的一種圖的表示方法,
邊集陣列由兩個一維陣列構成,一個存盤頂點的資訊,另一個存盤邊的資訊,這個邊陣列每個資料元素由一條邊的起點下標(begin),終點下標(end)和權(weight)組成,
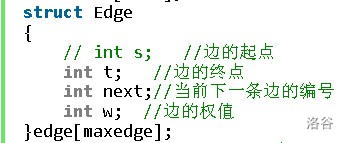
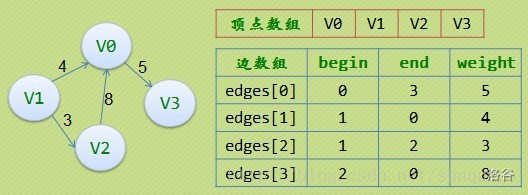
前向星
以儲存邊的方式來存盤圖,通常用在點的數目太多,或兩點之間有多潭訓的時候,一般在別的資料結構不能使用的時候才考慮用前向星,除了不能直接用起點終點定位以外,前向星幾乎是完美的,
實作
讀入每條邊的資訊,將邊存放在陣列中,把陣列中的邊按照起點順序排序(可以使用基數排序),前向星就構造完了,
#include<bits/stdc++.h>
using namespace std;
struct Node{
int v,next;
}E[100001];
int p[100001],eid=0;
inline void insert(int u,int v){
eid++;
E[eid].v=v;
E[eid].next=p[u];
p[u]=eid;
}
遍歷
從圖中某一頂點出發系統地訪問圖中所有頂點,使每個頂點恰好被訪問一次,這種運算操作被稱為圖的遍歷,
為避免重復訪問,需要一個狀態陣列vis[n],用來存盤各頂點的訪問狀態,如果vis[i]=1,則表示頂點i已經訪問過;如果vis[i]=0,則表示頂點i還未訪問過,初始化時,各頂點的訪問狀態均為0,
深度優先遍歷(dfs)
#include<iostream>
using namespace std;
int n,m;
int a[100][100];
int vis[100];//標記陣列
void dfs(int u){
cout<<"V"<<u<<" ";
vis[u]=1;//訪問標記
for(int i=1;i<=n;i++)
if(a[u][i]==1&&vis[i]==0)
dfs(i);
}
int main(){
cin>>n; //鄰接矩陣存盤
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++)
cin>>a[i][j];
dfs(1);//選定V1開始dfs遍歷,
return 0;
}
廣度優先遍歷(bfs)
為了實作逐層訪問,bfs演算法在實作時需要使用一個佇列,

補充
//如果是非連通圖,主程式做如下修改:
int main(){
...
memset(vis,0,sizeof(vis));
//把各個點全掃一遍
for(int i=1;i<=n;i++)
if(vis[i]==0)dfs(i);
...
return 0;
}
AOV網
在日常生活中,一項大的工程可以看作是由若干個子工程(這些子工程稱為“活動”)組成的集合,
這些子工程(活動)之間必定存在一些先后關系,即某些子工程(活動)必須在其它一些子工程(活動)完成之后才能開始,我們可以用有向圖來形象地表示這些子工程(活動)之間的先后關系,
子工程(活動)為頂點,子工程(活動)之間的先后關系為有向邊,這種有向圖稱為“頂點活動網路”,又稱“AOV網”,
在AOV網中,有向邊代表子工程(活動)的先后關系,我們把一條有向邊起點的活動稱為終點活動的前驅活動,同理終點的活動稱為起點活動的后繼活動,
而只有當一個活動全部的前驅全部都完成之后,這個活動才能進行,
一個AOV網必定是一個有向無環圖,即不應該帶有回路,否則,會出現先后關系的自相矛盾,
拓撲排序
所謂拓撲排序,就是把AOV網中的所有活動排成一個序列, 使得每個活動的所有前驅活動都排在該活動的前面,這個程序稱為“拓撲排序”,所得到的活動序列稱為“拓撲序列”,
即把有向圖上的n個點重新標號為1到n,滿足對于任意一條邊 (u, v),都有u<v,
并不是所有的圖都能進行拓撲排序,只要圖中有環,那么就可以匯出矛盾,
因此拓撲排序演算法只適用于AOV網(有向無環圖,DAG),有向無環圖有很多優美的性質,比如可以在拓撲序上進行DP,
一個AOV網的拓撲序列不一定是唯一的,
實作
我們記錄一下每一個點的入度和出度,用一個佇列維護當前所有入度為0的點,每次拿出來一個入度為0的點并且將它加到拓撲序中,然后列舉出邊更新度數上述兩步,重復,直到不存在入度為0的頂點為止,
若完成時佇列中的頂點數小于AOV網中的頂點數,則圖中有回路,否則此佇列中的頂點序列就是一種拓撲序,
可以看出,拓撲排序可以用來判斷一個有向圖是否有環,因為只有有向無環圖才存在拓撲序列,
時間復雜度O(n+m),
(在拓撲排序的程序中可以順帶進行DP)
思路
indgr[i]:頂點i的入度;
stack[ ]:堆疊;
初始化:top=0 (堆疊頂指標置零);
將初始狀態所有入度為0的頂點壓堆疊;
I=0 (計數器);
while 堆疊非空(top>0)
堆疊頂的頂點v出堆疊;top-1; 輸出v;i++;
for v的每一個后繼頂點u
ndgr[u]--;//u的入度減1
if (u的入度變為0) 頂點u入堆疊
演算法結束
代碼
for(int i=1;i<=n;i++)
if(d[i]==0)q.push(i);
while(!q.empty()){
int node=q.front();
q.pop();
res[++top]=node;
for(int hd=head[node];hd;hd=e[hd].nxt){
d[e[hd].to]--;
if(d[e[hd].to]==0)
q.push(e[hd].to);
}
}
歐拉路徑(歐拉通路)
如果圖中的一個路徑包括每個邊恰好一次,則該路徑稱為歐拉路徑,
歐拉回路
首尾相接的歐拉路徑稱為歐拉回路,
判定
由于每一條邊都要經過恰好一次,因此對于除了起點和終點之外的任意一個節點,只要進來,一定要出去,
一個無向圖存在歐拉回路,當且僅當該圖所有頂點度數都為偶數(即不存在奇點),且該圖只有一個存在邊的連通塊,
一個無向圖存在歐拉路徑,當且僅當該圖中奇點的數量為0或2,且該圖只有一個存在邊的連通塊;
如果存在2個奇點,則此歐拉路徑一定是從一個奇點出發,在另一個奇點結束,
一個有向圖存在歐拉回路,當且僅當所有點的入度等于出度,
一個混合圖存在歐拉回路,當且僅當存在一個對所有無向邊定向的方案,使得所有點的入度等于出度,需要用網路流,
求法
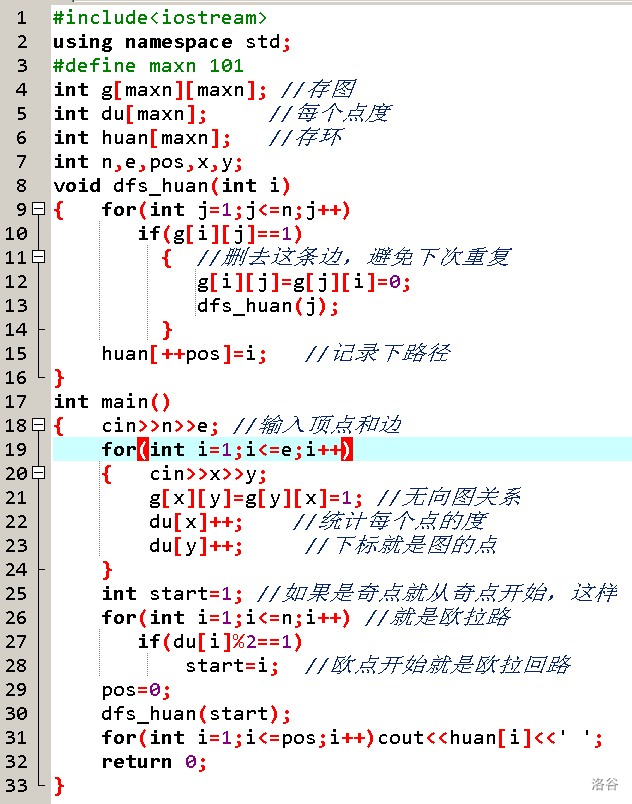
我們用 dfs來求出一張圖的歐拉回路,
我們給每一條邊一個 vis陣列代表是否訪問過,接下來從一個點出發,遍歷所有的邊,
直接dfs并且記錄的話會有一些問題,
為了解決這個問題,我們在記錄答案的時候倒著記錄,也就是當我們通過 (u, v) 這條邊到達 v 的時候,先把 v dfs 完再加入 (v, u) 這條邊,
還有一點需要注意,因為一個點可能被訪問多次,一不小心可能會寫成 O(n 2 ) 的(因為每次遍歷所有的出邊),解決方案就是設一個cur陣列,每次直接從上一次訪問到的出邊繼續遍歷,
時間復雜度 O(n + m),
代碼
void dfs(int x)
{
for(int&hd=head[x];hd;hd=e[hd].nxt)
{
if(flag[hd>>1])continue;
flag[hd>>1]=1;
dfs(e[hd].to);
a[++top]=x;
}
}
歐拉圖
有歐拉回路的圖稱為歐拉圖(Euler Graph);
有歐拉通路而沒有歐拉回路的圖稱為半歐拉圖,
哈密爾頓通路
通過圖中每個頂點一次且僅一次的通路,
哈密爾頓回路
通過圖中每個頂點一次且僅一次的回路,
求法
一般用搜索解決,
哈密爾頓圖
存在哈密爾頓回路的圖,
最短路徑
所謂最短路,就是把邊權看做邊的長度,從某個點 S到另一個點 T 的最短路徑,
用更加數學化的語言描述就是,對于映射 $ f : V \to R $ ,滿足 $ f \left ( S \right ) = 0 $ 且 $ \forall ( x , y , l ) \in E $ , | f ( x ) ? f ( y ) | $ \le l $ 的情況下,f(T) 的最大值,
最短路問題
最短路問題(short-path problem)是網路理論解決的典型問題之一,可用來解決管路鋪設、線路安裝、廠區布局和設備更新等實際問題,
基本內容是:若網路中的每條邊都有一個數值(長度、成本、時間等),則找出兩節點(通常是源節點和終節點)之間總權和最小的路徑,也就是最短路問題,
一般有兩類最短路徑問題:一類是求從某個頂點(源點)到其它頂點(終點)的最短路徑,(Dijkstra、Bellman-ford、SPFA);另一類是求圖中每一對頂點間的最短路徑,(floyed),
單源最短路——Dijkstra
在所有的邊權均為正的情況下,我們可以使用Dijkstra演算法求出一個點到所有其它點的最短路徑,
我們維護一個集合,表示這個集合內的點最短路徑已經確定了,
每次我們從剩下的點中選擇當前距離最小的點 u 加入這個集合,然后列舉另一個點 v 進行更新:
$ Dv = min \left ( Dv , Du + W \left ( u , v \right ) \right ) $
直接這樣做時間復雜度是 $ O \left ( n^2 \right ) $ 的,
實作
設起點為s,dis[ v ]表示從s到v的最短路徑,path[ v ]為v的前驅節點,用來輸出路徑,
1、初始化:
$ dis \left [ v \right ] = + \infty \left ( v \ne s \right ) ; $
$ dis \left [ s \right ] = 0 ; $
$ path \left [ s \right ] = 0 ; $
2、在沒有被訪問過的點中找一個頂點u使得dis[ u ]是最小的,
3、u標記為已確定最短路徑,
4、for與u相連的每個未確定最短路徑的頂點v,
#include<iostream>
#include<cstring>
using namespace std;
const int inf=99999;
const int maxn=101;
int f[maxn],a[maxn][maxn],d[maxn],path[maxn];
int n,start;
void init(){
cin>>n>>m>>start;
int x,y,w;
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++){
if(j==i) a[i][j]=0;
else a[i][j]=inf;
}
for(int i=1;i<=m;i++){
cin>>x>>y>>w;
a[x][y]=w;
a[y][x]=w;
}
}
void dijkstra(int s){
for(int i=1;i<=n;i++){
d[i]=inf;
f[i]=false;
}
d[s]=0;
for(int i=1;i<=n;i++){
int mind=inf;
int k;//用來記錄準備放入集合1的點
for(int j=1;j<=n;j++)//查找集合2中d[]最小的點
if((!f[j])&&(d[j]<mind)){
mind=d[j];
k=j;
}
if(mind==inf)break;//更新結點求完了
f[k]=true;//加入集合1
for(int j=1;j<=n;j++)//修改集合2中的d[j]
if((!f[j])&&(d[k]+a[k][j]<d[j])){
d[j]=d[k]+a[k][j];
path[j]=k;
}
}
}
void dfs(int i){
if(i!=start)dfs(path[i]);
cout<<i<<' ';
}
void write(){
cout<<start<<"到其余各點的最短距離是:"<<endl;
for(int i=1;i<=n;i++){
if(i!=start){
if(d[i]==inf)cout<<i<<"不可達";
else{
cout<<i<<"的最短距離:"<<d[i]<<",依次經過的點是:";
dfs(path[i]);
cout<<i<<endl;
}
}
}
}
int main(){
init();
dijkstra(start);
write();
return 0;
}
優化
我們注意到,復雜度主要來源于兩個地方,
第一個是找出當前距離最小的點,這個可以用堆很容易地實作,
第二個是列舉 v,如果我們用鄰接表存圖,可以降到邊數級別,
這樣我們就把復雜度降到了 O((n + m) log n),
單源最短路——Bellman-Ford
簡稱Ford(福特)演算法,另一種求單源最短路的演算法,復雜度不如Dijkstra優秀,能夠處理存在負邊權的情況,但無法處理存在負權回路的情況,
負權回路
存在負權回路的圖無法求出最短路徑,Bellman-Ford演算法可以在有負權回路的情況下輸出錯誤提示,
如果在Bellman-Ford演算法的兩重回圈完成后,還是存在某條邊使得: $ dis \left [ u \right ] + w \left [ j \right ] < dis \left [ v \right ] $ ,則存在負權回路,
if(dis[u]+w[j]<dis[v])return false;
實作
設s為起點,dis[ v ]即為s到v的最短距離,pre[v]為v前驅,w[ j ]是邊j的長度,且j連接u、v,
初始化:
$ dis \left [ v \right ] = + \infty \left ( v \ne s \right ) ; $
$ dis \left [ s \right ] = 0 ; $
$ path \left [ s \right ] = 0 ; $
考慮在上面出現過的松弛操作:
dv = min(dv, du + w(u, v))
由于最短路徑只會經過最多 n 個點,因此每一個點的最短路徑只會被松弛至多 n ? 1 次,
所以我們可以對整張圖進行 n ? 1 次松弛操作,每次列舉所有的邊進行更新,
for(i=1;i<=n-1;i++)
for(j=1;j<=E;j++)//列舉所有邊,而不是列舉點
if(dis[u]+w[j]<dis[v]){//u、v分別是這條邊連接的兩個點,
dis[v] =dis[u] + w[j];
pre[v] = u;
}
時間復雜度 O(nm),
SPFA
它死了,(因為它的復雜度是錯誤的)
應用:費用流
Bellman-Ford演算法不夠優秀,于是我們嘗試改進這個演算法,
注意到,在進行松弛操作的時候,如果點 u 的距離一直沒有發生變化,那么就不需要再列舉這個點的出邊進行松弛了,
也就是說我們可以用一個佇列保存所有距離發生變化的點, 每次取出一個點進行更新,
(主要思想:初始時將起點加入佇列,每次從佇列中取出一個元素,并對所有與它相鄰的點進行修改,若某個相鄰的點修改成功,則將其入隊,直到佇列為空時演算法結束,)
于是SPFA就誕生了,
如果圖是隨機的,SPFA的期望時間復雜度約為 O(2m),比之前提到的任何一個演算法都優秀,而且還可以有負權,
但是在最壞情況下它的復雜度和 Bellman-Ford 相同,都是 O(nm),在正式比賽中,沒有哪個出題人會放過它,(因為其復雜度本來就是錯的)
多源最短路——Floyed
對于一張圖,我們希望求出任意兩個點之間的最短路徑,
我們用 DP(動態規劃) 的思想,設 fi,j,k 表示從 i 到 j,途中僅經過前 k個點的最短路,
由于每一個點在最短路中只會出現一次(不然就出現負環了,不存在最短路),所以可以很寫出轉移方程:
fi,j,k = min(fi,j,k?1, fi,k,k?1 + fk,j,k?1)
時間復雜度是 $ O \left ( n^3 \right ) $ ,
在實際求的程序中,最后一維可以用滾動陣列優化掉,所以空間復雜度是 $ O \left ( n^2 \right ) $ ,
代碼
for(int k=1;k<=n;k++)
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++)
dis[i][j]=min(dis[i][j],dis[i][k]+dis[k][j]);
注意三層回圈的順序不能顛倒,
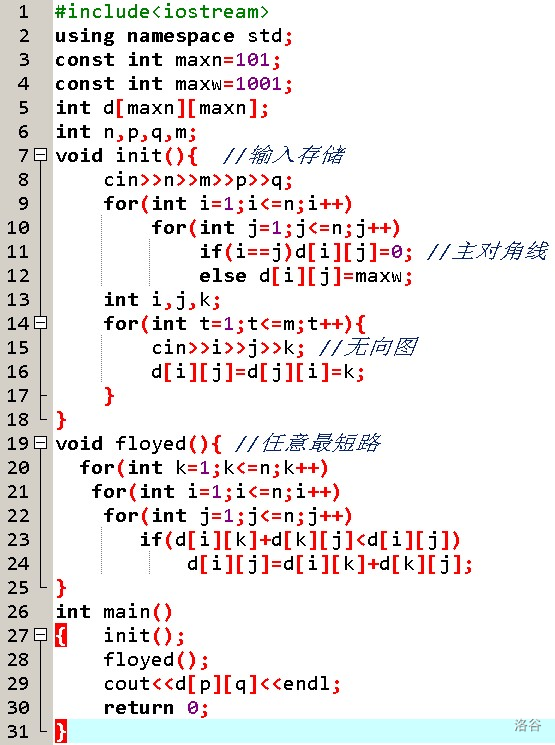
初始化
$ d \left [ i \right ] \left [ i \right ] = 0 $ //自己到自己為0;
$ d \left [ i \right ] \left [ i \right ] = 邊權 $ //i與j有直接相連的邊;
$ d \left [ i \right ] \left [ i \right ] = + \infty $ //i與j無直接相連的邊,
// 如果是int陣列,采用memset(d, 0x7f, sizeof(d))可全部初始化為一個很大的數
Floyd 傳遞閉包
有時候,我們需要維護一些有傳遞性的關系,比如相等,連通等等,(12連通,23連通,則 13連通)
初始條件往往是已知若干個點對具有這些關系,然后讓你弄 出來所有的關系,
可以直接把 Floyd 演算法做一下調整——
dis[i][j]=dis[i][j]|(dis[i][k]&dis[k][j]);
這個演算法叫做傳遞閉包,
多源最短路——Johnson 重賦權
對于多源最短路,如果我們列舉一個點然后跑堆優化的 Dijkstra,那么復雜度是 O(nm log n) 的,在圖比較稀疏的情況下,這個復雜度要優于 Floyd 演算法的 O(n 3 ),
但是 Dijkstra 演算法要求所有邊權均非負,
于是就有了重賦權的技巧,
我們新建一個 0 號點,并且從這個點出發向所有點連一條邊 權為 0 的邊,然后跑單源最短路,(SPFA 或者 Bellman-Ford)
設距離陣列為 h,接下來對于每條邊 (u, v),令 w ′ (u, v) = w(u, v) + h(u) ? h(v),
這樣所有的邊權就都變成非負了,我們就可以跑 Dijkstra 演算法了,
證明
首先由于 h(v) ≤ h(u) + w(u, v),新圖的邊權一定非負,
設新圖上的最短路徑為 d ′,原圖上的最短路徑為 d,
d ′ (u, v) = min a1,a2,...,ak w ′ (u, a1) + w ′ (a1, a2) + · · · + w ′ (ak, v)
= min a1,a2,...,ak w(u, a1) + (h(u) ? h(a1)) + w(a1, a2)+ (h(a2) ? h(a1)) + · · · + w(ak, v) + (h(v) ? h(ak))
= h(u) ? h(v) + min a1,a2,...,ak w(u, a1) + · · · + w(ak, v)
= h(u) ? h(v) + d(u, v)
最短路樹(最短路圖)
所謂最短路樹,就是在求完從 S 出發的單源最短路之后,
只保留最短路上的邊形成的資料結構,
只需要在求的程序中維護一個pre陣串列示這個點的前驅即可,很多最短路的變種都需要用這個演算法,
最小生成樹
用來解決如何用最小的代價用N-1條邊連接N個點的問題,
Prim 演算法
類比 Dijkstra 演算法,我們維護一個集合 S,表示這個集合中 的生成樹已經確定了,
演算法流程和Dijkstra一樣,唯一的區別是用w(u, v) 去更新 dv 而不是用 du + w(u, v),
時間復雜度 $ O \left ( n^2 \right ) $ ,同樣可以用堆優化,
主要思想
Prim演算法采用“藍白點”思想:白點代表已經進入最小生成樹的點,藍點代表未進入最小生成樹的點,
Prim演算法每次回圈都將一個藍點u變為白點,并且此藍點u與白點相連的最小邊權min[u]還是當前所有藍點中最小的,
這樣相當于向生成樹中添加了n-1次最小的邊,最后得到的一定是最小生成樹,
n次回圈,每次回圈讓一個新的點加入生成樹,n次回圈就能把所有點囊括到其中;每次回圈我們都能讓一條新的邊加入生成樹,n-1次回圈就能生成一棵含有n個點的樹;每次回圈我們都取一條最小的邊加入生成樹,n-1次回圈結束后,我們得到的就是一棵最小的生成樹,
實作
以第一個點為起點生成最小生成樹,min[ v ]表示藍點v與白點相連的最小邊權,
MST表示最小生成樹的權值之和,
初始化:
$ min \left [ v \right ] = + \infty \left ( v \ne 1 \right ) ; $
$ min \left [ 1 \right ] = 0 ; $
$ MST = 0 ; $
部分偽代碼:
for (i = 1; i<= n; i++)
尋找min[u]最小的藍點u,
將u標記為白點
MST+=min[u]
for 與白點u相連的所有藍點v
if (w[u][v]<min[v])
min[v]=w[u][v];
演算法結束:
MST即為最小生成樹的權值之和
Kruskal 演算法
前置知識
并查集演算法
并查集主要用于解決一些元素分組的問題,它管理一系列不相交的集合,并支持兩種操作:
合并:把兩個不相交的集合合并為一個集合,
查詢:查詢兩個元素是否在同一個集合中,
主要思想
Kruskal演算法將一個連通塊當做一個集合,
Kruskal首先將所有的邊按從小到大順序排序(快排),并認為每一個點都是孤立的,分屬于n個獨立的集合,
然后按順序列舉每一條邊,如果這條邊連接著兩個不同的集合,那么就把這條邊加入最小生成樹,這兩個不同的集合就合并成了一個集合;如果這條邊連接的兩個點屬于同一集合,就跳過,
直到選取到第n-1條邊為止,
因為是求的最小生成樹,所以我們用貪心的思路,把所有的邊權從小到大排序,然后一條一條嘗試加入,用并查集維護連通性,
可以發現這樣一定能得到原圖的最小生成樹,
時間復雜度$ O \left ( m log m \right ) $ ,
實作
初始化并查集:
$ father \left [ x \right ] = x $
$ tot = 0 $
將所有邊用快排從小到大排序,
計數器 k=0;
for(i=1;i<=M;i++)//遍歷所有邊
if(這是一條u,v不屬于同一集合的邊(u,v)(因為已經排序,所以必為最小)){
合并u,v所在的集合
把邊(u,v)加入最小生成樹
tot=tot+W(u,v);
k++;
if(k=n-1)//說明最小生成樹已經生成
break;
}
結束,tot即為最小生成樹的總權值之和,
代碼
find(int x){
return x==pa[x]?x:pa[x]=find(pa[x])
}
證明
如果某一條邊 (u, v) 不屬于最小生成樹,那么考慮最小生成樹上 連接 u, v 的路徑,這上面一定有一條邊權不小于 w(u, v) 的邊 (因為我們是從小到大列舉的所有邊),這樣替換后答案一定不會變劣,
優化
路徑壓縮(O(logn))+安值合并(O(logn))→O(αn)(αn在 $ 10^8 $ 資料內不超過4,可視為常數)
Kruskal 重構樹
前置知識
dfs(深度優先搜索)
LCA(最近公共祖先)
在一棵沒有環的樹上,每個節點肯定有其父親節點和祖先節點,而最近公共祖先,就是兩個節點在這棵樹上深度最大的公共的祖先節點,
LCA主要是用來處理當兩個點僅有唯一一條確定的最短路徑時的路徑,
樹上倍增
用于求LCA(最近公共祖先),
倍增的思想是二進制,
首先開一個n×logn的陣列,比如fa[n][logn],其中fa[i][j]表示i節點的第2^j個父親是誰,
然后,我們會發現一個性質:
fa[i][j]=fa[fa[i][j-1]][j-1]
用文字敘述為:i的第2^j個父親 是i的第2(j-1)個父親的第2(j-1)個父親,
這樣,本來我們求i的第k個父親的復雜度是O(k),現在復雜度變成了O(logk),
Kruskal 重構樹是基于 Kruskal 最小生成樹演算法的一種算 法,它主要通過將邊權轉化為點權來實作,
流程
將所有邊按照邊權排序,設 r(x) 表示 x 所在連通塊的根節點,(注意這里要用并查集)
列舉所有的邊 (u, v),若 u, v 不連通,則新建一個點 x,令 x 的權值為 w(u, v), 連接 (x, r(u)) 和 (x, r(v)), 令 r(u) = r(v) = x,
不斷重復以上程序,直到所有點均連通,
時間復雜度 O(m log m),
性質
這樣,我們就得到了一棵有 2n ? 1 個節點的二叉樹,其中葉節點為原圖中的點,其余的點代表原圖中的邊,并且滿足父節點權值大于等于子節點,
它有什么用呢?
求 u, v 之間路徑上的最大邊權 → 求重構樹上 u, v 兩個點的 LCA,
只保留邊權小于等于 x 的邊形成的樹 → 重構樹上點權小于 等于 x 的點的子樹,
Bor?vka 演算法
前置知識
距離
(x1,y1)(x2,y2)
曼哈頓距離:|x1-x2|+|y1-y2|
切比雪夫距離:max(|x1-x2|,|y1-y2|
歐幾里得距離:√[(x1-x2)2+(y1-y2)2]
曼哈頓距離與切比雪夫距離的相互轉化
兩者之間的關系
我們考慮最簡單的情況,在一個二維坐標系中,設原點為(0,0),
如果用曼哈頓距離表示,則與原點距離為1的點會構成一個邊長為2–√2的正方形,
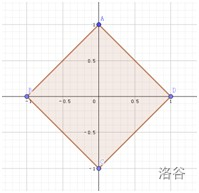
如果用切比雪夫距離表示,則與原點距離為1的點會構成一個邊長為2的正方形,
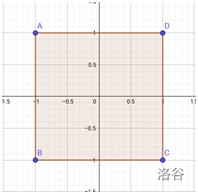
對比這兩個圖形,我們會發現這兩個圖形長得差不多,他們應該可以通過某種變換互相轉化,
事實上,
將一個點(x,y)的坐標變為(x+y,x?y)后,原坐標系中的曼哈頓距離 =新坐標系中的切比雪夫距離,
將一個點(x,y)的坐標變為((x+y)/2,(x?y)/2) 后,原坐標系中的切比雪夫距離 = 新坐標系中的曼哈頓距離,
(注意:切比雪夫距離轉曼哈頓距離要再除以二)
用處
切比雪夫距離在計算的時候需要取max,往往不是很好優化,對于一個點,計算其他點到該的距離的復雜度為O(n),
而曼哈頓距離只有求和以及取絕對值兩種運算,我們把坐標排序后可以去掉絕對值的影響,進而用前綴和優化,可以把復雜度降為O(1),
第三種求最小生成樹的演算法,雖然比較冷門但是很多題需要用到這個演算法,
我們維護當前形成的所有連通塊,接下來對于每一個連通塊,找到邊權最小的出邊,然后合并兩個連通塊,
不斷重復這個操作,直到整張圖變成一個連通塊,
由于每次操作連通塊數量至少減半,所以時間復雜度最壞為 O((n + m) log n),隨機圖的話復雜度可以降到 O(n + m),
Tarjan演算法
Tarjan 演算法不是某個特定的演算法,而是一群演算法,
強連通分量
割點/割邊/橋
點雙連通分量
邊雙連通分量
離線 O(n) 求 LCA
此外還有很多 Tarjan 獨立/合作創造的演算法:
Splay,LCT, 斐波那契堆,斜堆,配對堆,可持久化資料結構,……
有向圖——強連通分量
如果對于兩個點 u, v,同時存在從 u 到 v 的一條路徑和從 v 到 u 的一條路徑,那么就稱這兩個點強連通,
如果一張圖的任意兩個點均強連通,那么就稱這張圖為強連通圖,
強連通分量指的是一張有向圖的極大強連通子圖, (極大≠最大)
Tarjan 演算法可以用來找出一張有向圖的所有強連通分量,
我們用 dfs的方式來找出一張圖的強連通分量,
建出 dfs 樹,記錄一下每一個節點的時間戳(dfn),然后我們考慮強連通分量應該滿足什么條件,
我們可以再記錄一個 low 陣列,表示每一個點能夠到達的最小的時間戳,如果一個點的 dfn=low,那么這個點下方就形成了一個強連通分量,
在 dfs 的程序中,對于 (u, v) 這條邊:
若 v 未被訪問,則遞回進去 dfs 并且用 low[v] 更新 low[u],
若 v 已經被訪問并且在堆疊中,則直接用 dfn[v] 更新 low[u],
最后如果 dfn[u]=low[u],則直接把堆疊中一直到 u 的所有點 拿出來作為一個強連通分量,
時間復雜度 O(n),
有向圖——縮點
跑出來強連通分量之后,我們可以把一個強連通分量看成一 個點,
接下來列舉所有的邊,如果是一個強連通分量里的就忽略, 否則連接兩個對應的強連通分量,這個操作稱為縮點,
縮點后就變成了一張有向無環圖,處理連通性問題的時候會方便很多,
無向圖——割點
對于一張無向圖,我們希望求出它的割點,
無向圖的割點定義為刪掉這個點之后,連通塊數量會發生改變的點,
類比上面,我們還是記錄一下 dfn(時間戳)和 low,
對于 u 的一個子節點 v,若 dfn[u]≤low[v],則 u 是割點(因 為 v 無法繞過 u 往上走),
不過需要注意兩點:
根節點不能用這種方法,而是應該看它的子節點數量是否大于等于 2,如果是那么根節點就是割點,
列舉出邊的時候要特判掉父子邊的情況,
無向圖——橋
無向圖的橋定義為刪掉這條邊后,連通塊數量會發生改變的邊,
和上面的方法幾乎一模一樣,唯一的區別是判斷dfn[u]<low[v]而不是dfn[u]≤low[v],(如果從 v 出發連 u 都無法 到達,那么 (u, v) 就是一個橋邊)
甚至連根節點都不需要特判了,
無向圖——點/邊雙連通分量
如果兩個點之間存在兩條點互不相交的路徑,那么就稱這兩個點是點雙連通的,
如果兩個點之間存在兩條邊互不相交的路徑,那么就稱這兩個點是邊雙連通的,
其余的定義參考強連通分量,
割點將整張圖分成了若干個點雙連通分量,并且一個割點可以在多個點雙連通分量中,
而橋則把整張圖拆成了若干個邊雙連通分量,并且橋不在任意一個邊雙連通分量中,
魔改一下強連通分量演算法即可,
當然,無向圖也可以縮點,不過主要還是可以用來建圓方樹,
二分圖匹配
前置知識
匹配
在圖論中,一個匹配是一個邊的集合, 其中任意兩條邊都沒有公共頂點,
最大匹配
一個圖所有匹配中,所含匹配邊數最多的匹配, 稱為這個圖的最大匹配,
如果要求一般圖的最大匹配,需要用 O(n 3 ) 的帶花樹,至少 是 NOI+ 的演算法,在聯賽階段,我們一般只關注二分圖的匹配問題,
(最大匹配——匈牙利演算法)
完美匹配
如果一個圖的某個匹配中,所有的頂點都是匹配點,那么它就是一個完美匹配,
二分圖
如果一個圖的頂點能夠被分為兩個集合 X, Y,滿 足每一個集合內部都沒有邊相連,那么這張圖被稱作是一張二分圖,
(dfs可以判斷一張圖是否是二分圖)
交替路
從一個未匹配點出發,依次經過非匹配邊——匹配 邊——非匹配邊——……形成的路徑叫交替路,
增廣路
從一個未匹配點出發,依次經過非匹配邊——匹配 邊——非匹配邊——……——非匹配邊,最后到達一個未匹配點形成的路徑叫增廣路,
注意到,一旦我們找出了一條增廣路,將這條路徑上所有匹配邊和非匹配邊取反,就可以讓匹配數量+1,
匈牙利演算法就是基于這個原理,
假設我們已經得到了一個匹配,希望找到一個更大的匹配,
我們從一個未匹配點出發進行 dfs(深度優先搜索),如果找出了一個增廣路, 就代表增廣成功,我們找到了一個更大的匹配,
如果增廣失敗,可以證明此時就是最大匹配,
由于每個點只會被增廣一次,所以時間復雜度是 O(n(n + m)),
二分圖最大權匹配——KM 演算法
現在我們把所有的邊都帶上權值,希望求出所有最大匹配中權值之和最大的匹配,
我們的思路是給每一個點賦一個“期望值”,也叫作頂標函式 c,對于 (u, v) 這條邊來說,只有 c(u) + c(v) = w(u, v) 的時 候,才能被使用,
容易發現,此時的答案就是 ∑c(i),
初始,我們令左邊所有點的 c(u) = maxv w(u, v),也就是說最理想的情況下,每一個點都被權值最大的出邊匹配,
接下來開始增廣,每次只找符合要求的邊,我們定義只走這些邊訪問到的子圖為相等子圖,
如果能夠找到增廣路就直接增廣,否則,就把這次增廣訪問到的左邊的所有點的 c ? 1,右邊所有點的 c + 1,
經過這樣一通操作,我們發現原來的匹配每一條邊仍然滿足條件,同時由于訪問到的點左邊比右邊多一個(其余的都匹配上了),所以這樣會導致總的權值?1,
接下來再嘗試進行增廣,重復上述程序,直接這樣做時間復 雜度是 O(n 3 c) 的,(進行 n 次增廣,每次修改 c 次頂標,訪問所有 n 2 條邊)
優化
由于修改頂標的目標是讓相等子圖變大,因此可以每次加減 一個最小差值 delta,這樣每次增廣只會被修改最多 n 次頂標,時間復雜度降到 O(n 4 ),
注意到每次重新進行 dfs(深度優先搜索) 太不優秀了,可以直接進行 bfs, 每次修改完頂標之后接著上一次做,時間復雜度降到 O(n 3 ),
技巧
最小點覆寫
選取最少的點,使得每一條邊的兩端至少有一 個點被選中,
二分圖的最小點覆寫 = 最大匹配
證明
1.由于最大匹配中的邊必須被覆寫,因此匹配中的每一個點對 中都至少有一個被選中,
2.選中這些點后,如果還有邊沒有被覆寫,則找到一條增廣路,矛盾,
最大獨立集:選取最多的點,使得任意兩個點不相鄰,
最大獨立集 = 點數-最小點覆寫
證明
1.由于最小點覆寫覆寫了所有邊,因此選取剩余的點一定是一個合法的獨立集,
2.若存在更大的獨立集,則取補集后得到了一個更小的點覆寫,矛盾,
最小邊覆寫:選取最少的邊,使得每一個點都被覆寫,
最小邊覆寫 = 點數-最大匹配
證明
1.先選取所有的匹配邊,然后對剩下的每一個點都選擇一條和 它相連的邊,可以得到一個邊覆寫,
2.若存在更小的邊覆寫,則因為連通塊數量 = 點數-邊數,這 個邊覆寫在原圖上形成了更多的連通塊,每一個連通塊內選一條邊,我們就得到了一個更大的匹配,
最小不相交路徑覆寫:一張有向圖,用最少的鏈覆寫所有的點,鏈之間不能有公共點,
將點和邊分別作為二分圖的兩邊,然后跑匹配,最小鏈覆寫 = 原圖點數-最大匹配,
最小可相交路徑覆寫:一張有向圖,用最少的鏈覆寫所有的 點,鏈之間可以有公共點,
先跑一遍傳遞閉包,然后變成最小不相交路徑覆寫,
補充
小黃鴨除錯法
當你的代碼出現問題的時候,
將小黃鴨想象成你的同學,
將你的代碼一行一行地講給它,
也許講到一半你就知道問題出在哪了,
不要定義以下變數名
next,abs,x1,y1,size……
并非原創,僅是整理,請見諒
Lo問我為什么看星星,我覺得銀河和代碼是同一種東西,這也是一種回答,————Co轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/451995.html
標籤:其他
上一篇:java實作稀疏矩陣的壓縮與解壓
下一篇:10行代碼實作一個值班提醒應用