所以我有一個看起來像這樣的大文本檔案:
""" 是的,你成功了,用戶 1 ! — 25/03/2022 --------------- 用戶 2 加入了聚會。 — 22/03/2022 -------- ------- 是的,你成功了,用戶 3 !— 2022 年 3 月 29 日 --------------- 用戶 4 加入了聚會。— 28/03/2022"""
我如何獲得所有用戶的姓名,知道他們都在 python 的那些特定短語之后或之前?
我試過了 :
import re
text =""" ....""" #text is here
before_j = re.findall(r'\bjust showed up\S*', text)
print(before_j)
uj5u.com熱心網友回復:
采用
(?<=Yay you made it, )\S |\S (?= joined the party)
請參閱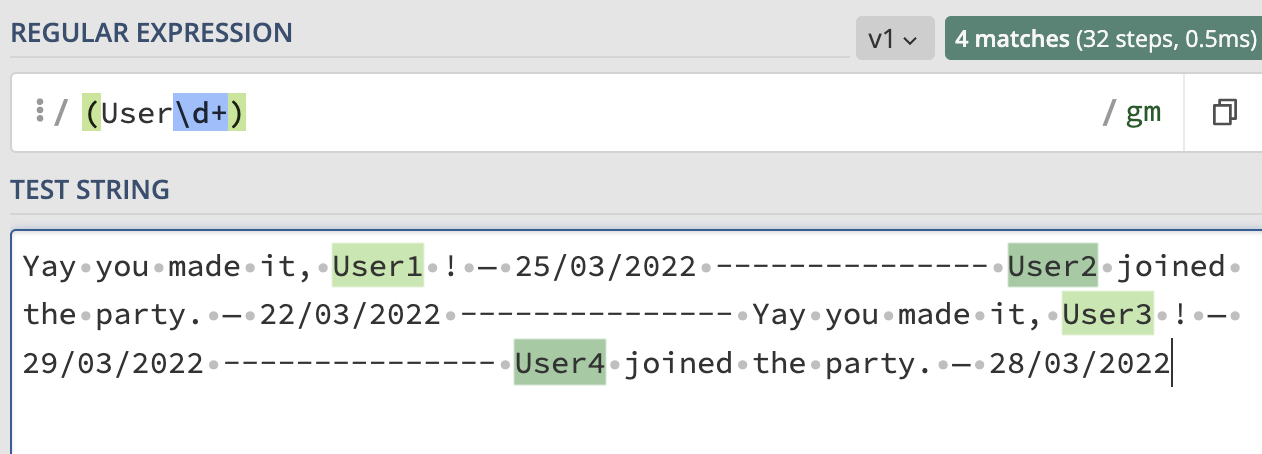
但是,我會假設用戶名可能更復雜,所以讓我們假設用戶名是一個或多個非空格字符(注意,這通常是無效的 - 如果在end -- User1!? -- 在這種情況下\w會是一個更好的說明符)。在這種情況下,我們希望匹配一個用戶名,前面有“你成功了”,或者后面有“加入派對”。在這種情況下,我們有:
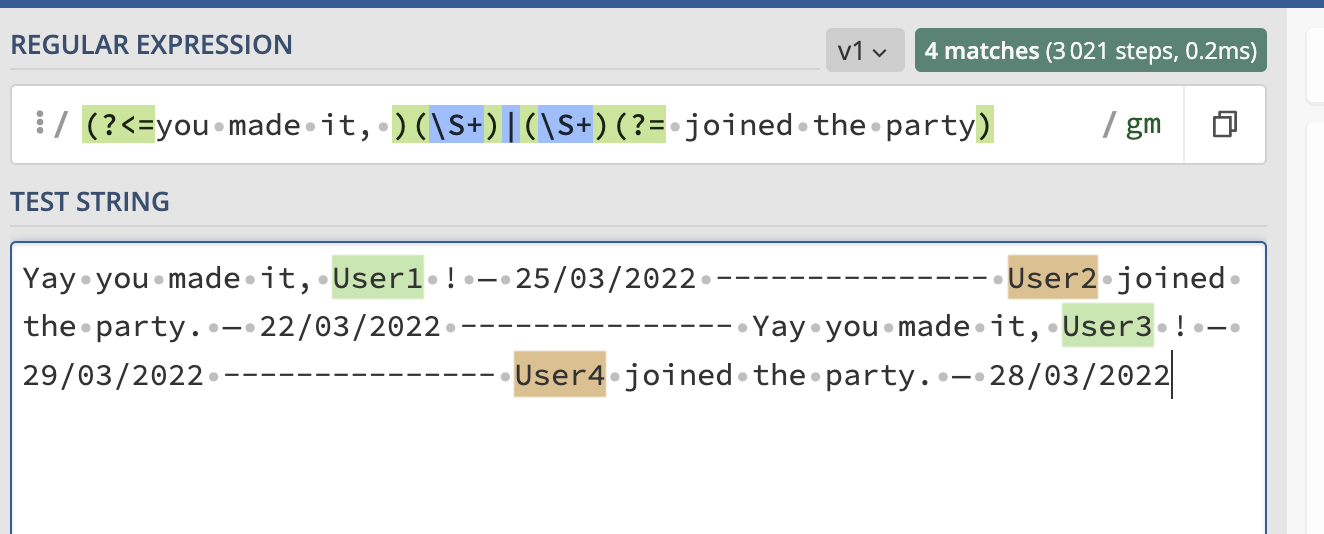
import re s = "Yay you made it, User1 ! — 25/03/2022 --------------- User2 joined the party. — 22/03/2022 --------------- Yay you made it, User3 ! — 29/03/2022 --------------- User4 joined the party. — 28/03/2022" [item[0] or item[1] for item in re.findall(r'(?<=you made it, )(\S )|(\S )(?= joined the party)', s)] # ['User1', 'User2', 'User3', 'User4']uj5u.com熱心網友回復:
可能的解決方案如下:
優點:“用戶”名稱可以包含除空格以外的任何字符。
import re string = """ Yay you made it, User1 ! — 25/03/2022 --------------- User2 joined the party. — 22/03/2022 --------------- Yay you made it, User3 ! — 29/03/2022 --------------- User4 joined the party. — 28/03/2022""" found = re.findall(r',\s(\S )\s!|-\s(\S )\sj', string, re.I) print(list(filter(None, [item for t in found for item in t])))印刷
['User1', 'User2', 'User3', 'User4']正則運算式演示
感謝@cards、@David542 對正則運算式模式的寶貴意見。
uj5u.com熱心網友回復:
我為名稱設定了兩個匹配規則:
it, (name_pattern) !“它”,然后是名稱,后跟“!”-{3,} (name_pattern)\s至少 3 個字符后跟名稱和一個空字符,其中名稱是任何以一位或多位數字結尾的字母字符序列,([a-zA-Z] \d )
模式匹配是同時完成的,需要洗掉回圈中的“空”匹配。
import re text = """ Yay you made it, User1 ! — 25/03/2022 --------------- User2 joined the party. — 22/03/2022 --------------- Yay you made it, User3 ! — 29/03/2022 --------------- User4 joined the party. — 28/03/2022""" # list of rules rules = (r'it, ([a-zA-Z\d] ) !', r'-{3,} ([a-zA-Z] \d )\s') # regex = '|'.join(rules) matches = [g1 if g2 == '' else g2 for g1, g2 in re.findall(regex, text)] print(matches)輸出
['User1', 'User2', 'User3', 'User4']編輯 為了避免過濾匹配文本的空字串,可以使用符號分組(只是帶有 id 的組):
# symbolic grouping rules = (r'it, (?=<g1>[a-zA-Z\d] ) !', r'-{3,} (?=<g2>[a-zA-Z] \d )\s') regex = '|'.join(rules) matches = [g.lastgroup for g in re.finditer(regex, text)]
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/454727.html上一篇:有沒有辦法讓字串作為串列索引?