一、什么是scrapy?
Scrapy,Python開發的一個快速、高層次的螢屏抓取和web抓取框架,用于抓取web站點并從頁面中提取結構化的資料,Scrapy用途廣泛,可以用于資料挖掘、監測和自動化測驗.
其最初是為了頁面抓取 (更確切來說, 網路抓取 )所設計的, 后臺也應用在獲取API所回傳的資料(例如 Amazon Associates Web Services ) 或者通用的網路爬蟲.
Scrapy吸引人的地方在于它是一個框架,任何人都可以根據需求方便的修改,它也提供了多種型別爬蟲的基類,如BaseSpider、sitemap爬蟲等,最新版本又提供了web2.0爬蟲的支持.
二、Scrapy五大基本構成:
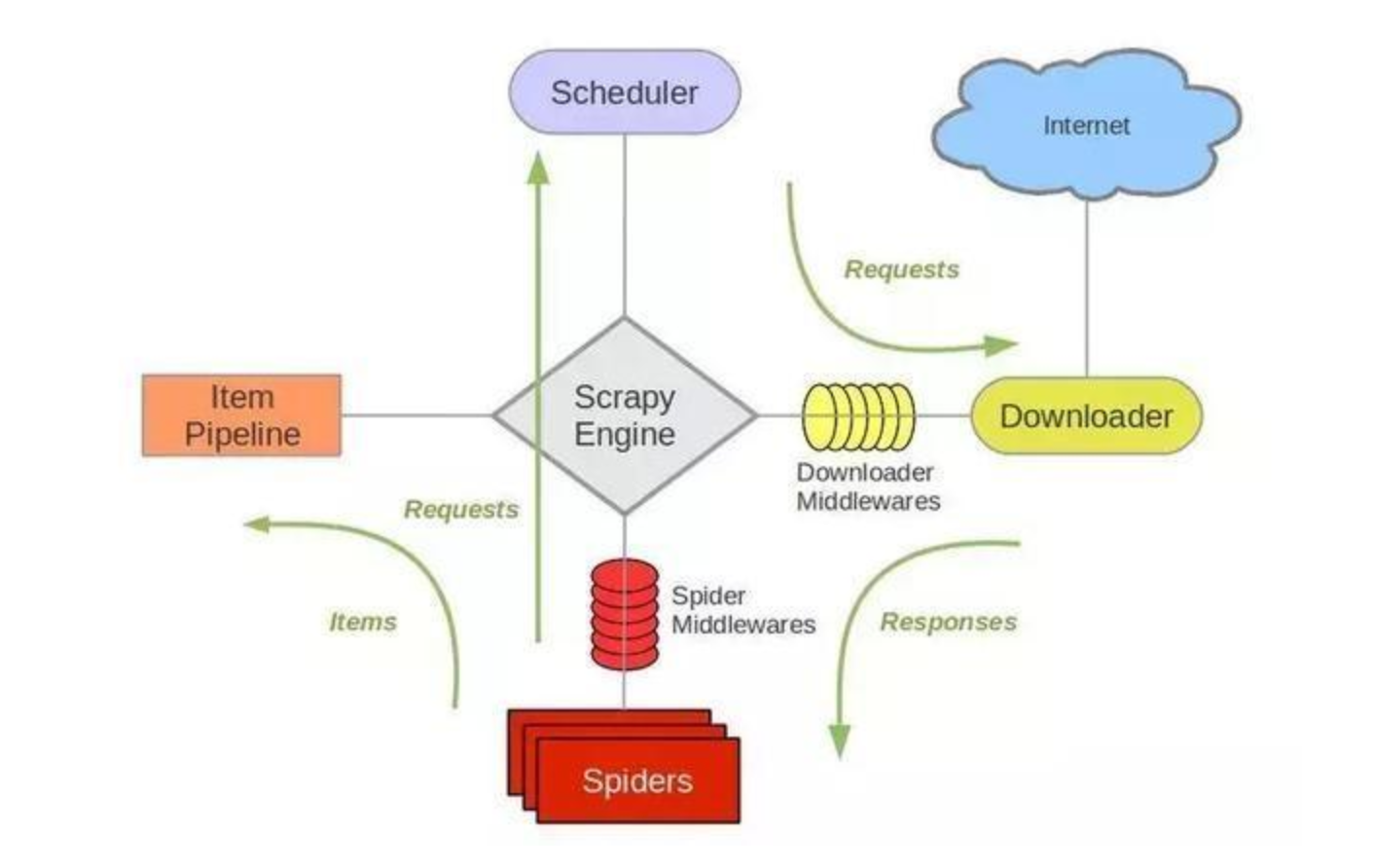
Scrapy框架主要由五大組件組成,它們分別是調度器(Scheduler)、下載器(Downloader)、爬蟲(Spider)和物體管道(Item Pipeline)、Scrapy引擎(Scrapy Engine),下面我們分別介紹各個組件的作用,
(1)、調度器(Scheduler):
調度器,說白了把它假設成為一個URL(抓取網頁的網址或者說是鏈接)的優先佇列,由它來決定下一個要抓取的網址是 什么,同時去除重復的網址(不做無用功),用戶可以自己的需求定制調度器,
(2)、下載器(Downloader):
下載器,是所有組件中負擔最大的,它用于高速地下載網路上的資源,Scrapy的下載器代碼不會太復雜,但效率高,主要的原因是Scrapy下載器是建立在twisted這個高效的異步模型上的(其實整個框架都在建立在這個模型上的),
(3)、 爬蟲(Spider):
爬蟲,是用戶最關心的部份,用戶定制自己的爬蟲(通過定制正則運算式等語法),用于從特定的網頁中提取自己需要的資訊,即所謂的物體(Item), 用戶也可以從中提取出鏈接,讓Scrapy繼續抓取下一個頁面,
(4)、 物體管道(Item Pipeline):
物體管道,用于處理爬蟲(spider)提取的物體,主要的功能是持久化物體、驗證物體的有效性、清除不需要的資訊,
(5)、Scrapy引擎(Scrapy Engine):
Scrapy引擎是整個框架的核心.它用來控制除錯器、下載器、爬蟲,實際上,引擎相當于計算機的CPU,它控制著整個流程
三、scrap框架架構圖
四、Scrapy安裝以及生成專案
1、安裝scrapy框架所需jar包:
打開終端cmd,依次執行如面幾條指令:
python -m pip install --upgrade pip
pip install wheel
pip install lxml
pip install twisted
pip install pywin32
pip install scrapy
2、創建專案
scrapy startproject 專案名
scrapy genspider 爬蟲名 域名
scrapy crawl 爬蟲名
工程目錄:
|-ProjectName #專案檔案夾
|-ProjectName #專案目錄
|-items.py #定義資料結構
|-middlewares.py #中間件
|-pipelines.py #資料處理
|-settings.py #全域配置
|-spiders
|-__init__.py #爬蟲檔案
|-baidu.py
|-scrapy.cfg #專案基本組態檔
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/455513.html
標籤:其他
下一篇:Firefox 禁止中國用戶!!