我試圖在 A 列中保留包含單詞“NOA”的行,該列具有許多多行單元格,可以在此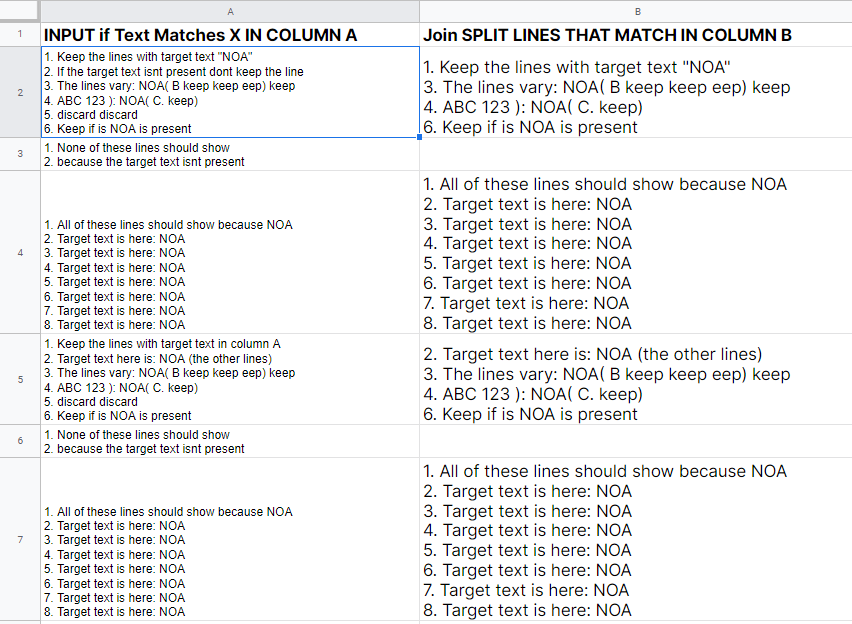
理論方法: 我一直在考慮解決這個問題的三種方法:
- ARRAYFORMULA(REGEXREPLACE - 無法讓它作業
- JOIN(FILTER(REGEXMATCH(TRANSPOSE - 顯示承諾,因為它在多個步驟中作業
- 使用 QUERY 函式 - 不熟悉 w/ 函式,但想知道這個函式是否有快速的解決方案
實際嘗試:
FIRST APPROACH: first I attempted using REGEXEXTRACT to extract out everything that did not have NOA in it, the Regex worked in demo but didn't work properly in sheets. I thought this might be a concise way to get the value, perhaps if my REGEX skill was better?
ARRAYFORMULA(REGEXREPLACE(A1:A7, "^(?:[^N\n]|N(?:[^O\n]|O(?:[^A\n]|$)|$)|$) ",""))
I think the Regex because overly complex, didn't work in Google or perhaps the formula could be improved, but because Google RE2 has limitations it makes it harder to do certain things.
SECOND APPROACH:
Then I came up with an alternate approach which seems to work 2 stages (with multiple helper cells) but I would like to do this with one equation.
=TRANSPOSE(split(A2,CHAR(10)))
=TEXTJOIN(CHAR(10),1,FILTER(C2:C7,REGEXMATCH(C2:C7,"NOA")))
Questions:
- Can these formulas be combined and applied to the entire Column using an Index or Array?
- Or perhaps, the REGEX in my first approach can be modified?
- Is there a faster solution using Query?
共享的Google 電子表格在這里。
預先感謝您的幫助。
uj5u.com熱心網友回復:
這是您可以做到這一點的一種方法:
=index(substitute(substitute(transpose(trim(
query(substitute(transpose(if(regexmatch(split(
filter(A2:A,A2:A<>""),char(10)),"NOA"),split(
filter(A2:A,A2:A<>""),char(10)),))," ","??")
,,9^9)))," ",char(10)),"??"," "))
首先,我們用換行符(char 10)分割資料,然后過濾掉不包含 NOA 的行,最后我們使用“查詢 smush”將所有內容重新連接在一起。
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/456354.html
上一篇:將名稱與ID關聯起來
下一篇:比較兩列并顯示“是”或“否”