for 回圈是 Python 中的通用序列迭代器:它可以單步遍歷任何有序序列中的元素,for 陳述句適用于字串、串列、元組、其他內置可迭代物件和類創建的新物件,
for 通常比 while 回圈更容易編碼并且運行效率更高,當需要遍歷一個序列時,首先要考慮for回圈,一般而言,當物件有特定的長度時,可以使用 for 回圈,沒有時使用 while 回圈,例如:使用 for 回圈遍歷目錄中的檔案、檔案中的字符、串列中的元素等,無論是否知道度,所有這些都有自身特定的長度,但是在游戲中,一般使用 while 回圈,因為不知道用戶什么時候關閉程式,
下列代碼就是for回圈的基本格式,里面是需要回圈執行的內容:
for target in sequence: print(target)
Python 在運行 for 回圈時,會將序列物件中的元素一一賦值給目標,并執行一次回圈體,回圈體通常使用賦值目標來參考序列中的當前項,就好像它是一個在序列中步進的游標,在 for 中用作賦值目標的名稱通常是 for 回圈體范圍內的變數,也就區域變數,它可以在回圈體內更改,但當控制再次回傳回圈頂部時,將自動設定為序列中的下一項,在回圈之后,這個變數通常是最后訪問的專案,也就是序列中的最后一個專案,除非回圈
以break陳述句退出,
下面這個例子,我們從左到右依次將名稱 x 分配給串列中的三個元素,每次執行 print 陳述句,因為 print 函式默認為換行符,所以
每個元素在列印時都是一個新行,在第一次迭代中 x=‘spam’,第二次迭代 x=‘eggs’,第三次迭代 x=‘ham’,
Python學習交流Q群:906715085 for x in ['spam', 'eggs', 'ham']: print(x)
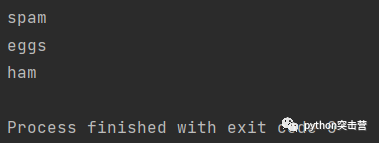
計算序列中元素總和,
total = 0 for i in [1,2,3,4]: total = total + i print(total)
也可以遍歷任何資料型別,比如,我們遍歷一個字串,并在每個字母之間留一個空格將其列印出來,
word = 'hello' for letter in word: print(letter, end=' ')
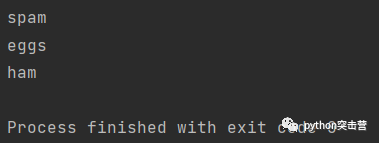
for回圈賦值給元組
當回圈遍歷元組序列時,可以將序列中的元素賦值給目標元組,序列中元組的專案依次賦值給目標元組對應的元素,
t = [(1,2), (3,4), (5,6)] for (a,b) in t: print(a,b)
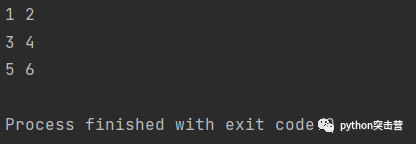
遍歷字典
d = {'a':1, 'b':2, 'c':3}
for key, value in d.items():
print(key, value)
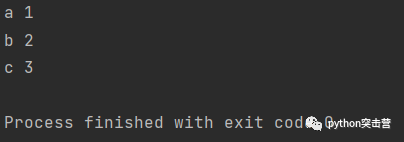
賦值后拆分
t = [(1,2), (3,4), (5,6)] for both in t: a,b = both print(a,b)
我們不一定要在for回圈中對應的賦值目標,也可以在回圈體中對賦值目標進行拆分,
嵌套回圈
for 回圈也可以嵌套,使用內置的 range() 函式回傳一個串列,為每個回圈生成數字 0-2,每個 i 回圈的內部 j 回圈回圈,在下面例子中,每個回圈運行 3 次,總共是9次,
for i in range(3): for j in range(3): print(i,j)

python 中可以使用 itertools 模塊獲得相同的結果,而不是兩個嵌套的 for 回圈
from itertools import product for pairs in product(range(3), range(3)): print(pairs)
這里pairs輸出為一個元組,再舉一個嵌套回圈的小栗子,比如,從一個句子中提取所有字母,
sentence = 'This is a sentence.' for word in sentence.split(' '): for char in word: print(char)
第一層for將句子按空格拆分成串列,也就是每個單詞,第二層是遍歷每個單詞的每個字母,這樣就提取出了除去空格的所有字母,
range
Python 內置的 range 函式是一個生成整數串列的迭代器,它通常與 for 回圈結合使用,是生成所需數字串列的簡單方法,如上例所示,它通過給它引數 3 來生成一個串列 [0, 1, 2],
range(start, stop[, step])
這是range的基本語法,start是初始值,stop的終止值,注意最終停的值不會等于,也不會超過stop的值,step是每次遞增的值,默認是1,
基本用法
for i in range(10): print(i)
生成0-9的序列,
特定范圍
for i in range(5,10): print(i)
生成5-9的一個序列,
特定間隔的序列
for i in range(5,10,2): print(i)
生成序列[5,7,9]
逆向序列
for i in range(10,0,-1): print(i)
step可以為負數,也就是每次遞減step,來生成一個減小的序列,
l = list(range(3)) print(l[::-1])
上述代碼也能得到一個逆向序列,其實list[start:stop:step],也可以看成一個for回圈來用,當然也可是使用list(reversed(l))來得到一個逆向序列,
說明一點
不要在 for 回圈中使用 range(len(sequence))來獲取序列中每個元素的索引,因為 Python 允許您直接回圈序列,在 Python 中,當您使用 for 回圈回圈序列時,大多數時候不需要知道索引,不建議使用下列例子中的用法,如果一定要獲取,可以使用列舉enumerate,
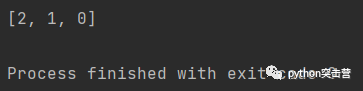
seq = ['spam', 'eggs', 'ham'] for i in range(len(seq)): print(f'{seq[i]} is at index {i}')
列舉
Enumerate 是一個內置的生成器物件,它有一個由 next 內置函式呼叫的 next 方法,該方法每次通過回圈回傳一個 (index, value) 元組,我們可以在 for 回圈中使用元組賦值來拆分這些元組,
for index, target in enumerate(['spam', 'eggs', 'ham']): print(f'{target} is at index {index}')
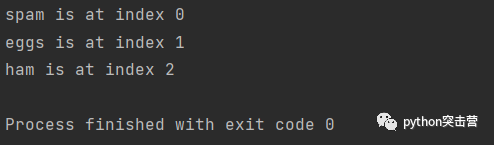
上述例子,就獲取了串列中元素的索引,
使用 enumerate 函式,索引變數會隨著序列中的目標序列遞增(默認從 0 開始),您可以將起始編號作為第二個引數來更改默認起始計數器,
for index, target in enumerate(['spam', 'eggs', 'ham'], 10): print(f'{target} is at index {index}')
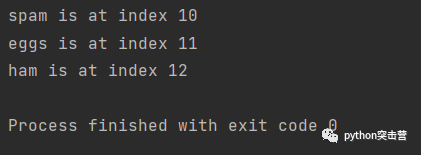
可以看到,起始索引變成了10,然后依次遞增1,
改變正在回圈中的序列
有時回圈程序中,需要對回圈的序列進行修改,
l = ['spam', 'eggs', 'ham']for word in l: if 's' in word: l.remove(word) print(l)
上述例子的直觀作用是,洗掉串列中帶有s的單詞,但是結果是,只是洗掉了第一個帶有s的spam這個單詞,并沒有洗掉eggs,
我們需要對串列的參考進行復制,然后回圈復制并修改原始內容,通過這種方式,回圈中的操作才能應用于原始串列,
l = ['spam', 'eggs', 'ham']for word in l[:]: if 's' in word: l.remove(word) print(l)
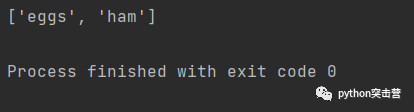
說明一點
在這里要注意 [:] 為串列的參考創建了一個淺拷貝,也可以匯入復制模塊使用 copy.copy(sequence),
嵌套串列其實需要深拷貝,取決于要洗掉的內容,需要匯入復制模塊來執行 copy.deepcopy(sequence),在迭代物件的同時洗掉
物件,了解它與 for 回圈的關系很重要,因為它可能導致意外輸出,至于深拷貝和淺拷貝,就是另外的知識點了,
zip
zip 允許我們使用 for 回圈來并行訪問多個序列,zip 將一個或多個序列作為引數并回傳一系列元組,這些元組將這些序列中的并
行項配對,
l1 = [1,2,3,4] l2 = [5,6,7,8] for x,y in zip(l1, l2): print(x, y, x + y)
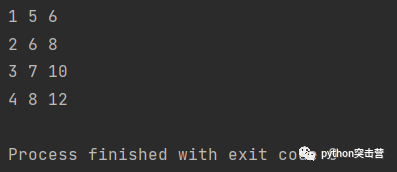
使用 zip 創建了一個元組對串列,我們在一個 for 回圈中回圈了兩個單獨的串列,當然,它也不限于兩個引數,只需要確保有相同
數量的目標來拆分給定的串列,這里我們有兩個串列,所以我們只需要 x 和 y 來解壓它們,
當引數長度不同時,zip 會以最短序列的長度截斷結果元組,
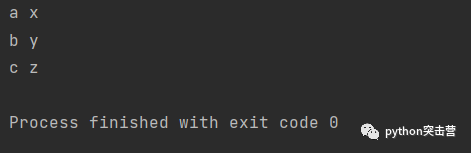
s1 = 'abc' s2 = 'xyz123' for x,y in zip(s1, s2): print(x, y)
可以在運行時使用 zip 構建字典,
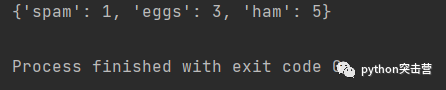
keys = ['spam', 'eggs', 'ham'] values = [1,3,5]d = {} for k,v in zip(keys, values): d[k] = vprint(d)
或者
keys = ['spam', 'eggs', 'ham'] values = [1,3,5] d = dict(zip(keys, values)) print(d)
排序
遍歷一個排序的串列,
abc = ['b','d','a','c','f','e'] for letter in sorted(abc): print(letter)
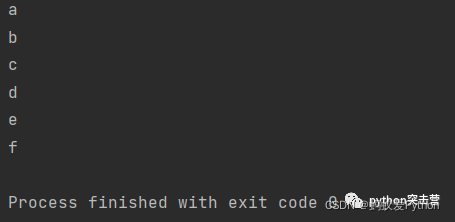
或者使用sorted(abc)得到一個升序的序列,使用sorted(abc, reverse=True)得到一個降序的序列,
串列組合
任何串列組合都可以轉換為 for 回圈,反之則不行,元素直接寫在方括號中,是構造新串列的一種方式,串列組合的速度大約是
手動 for 回圈的兩倍,因為它們的迭代是在解釋器中以 C 語言速度執行的,然而,使它們過于復雜會降低可讀性,
for y in ['foo','bar']: for x in [y.lower(), y.upper()]: print(x)
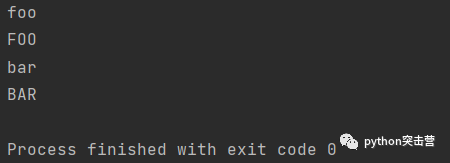
使用for回圈進行壓縮,
l = [x for y in ['foo','bar'] for x in [y.lower(),y.upper()]] print(l)
變換程序
第二個for放到第一個for后面,然后掉第一個for的冒號,在最前面寫一個第二個for的變數,最后將所有內容放在括號中,
舉個例子,創建一個新串列并將字串“ham”輸入與原始串列中一樣多的次數,
Python學習交流Q群:906715085### lst = ['spam', 'ham', 'eggs', 'ham']ham_ lst = []for item in lst: if item == 'ham': ham_lst.append(item)print(ham_lst)
使用串列組合,
lst = ['spam', 'ham', 'eggs', 'ham']ham_ lst = [item for item in lst if item == 'ham'] print(ham_lst)
上述兩段代碼得到相同的結果,
map
內置 map 函式回傳一個迭代器,該迭代器對輸入迭代器中的值呼叫函式,并回傳結果,這里,我們創建一個函式來呼叫,它回傳給定數字的 2 倍,
def times_two(x): return 2 * x
現在我們將使用 map 回圈這個函式,在 range 函式給出的每個數字上呼叫這個函式,
for i in map(times_two, range(5)): print(i)
或者,下列兩種方式,都得到相同的串列,你可以理解為簡單的 for 回圈,map 所做的就是對序列中的每個結果呼叫 times_two 函式,Map 存在,可以不使用 for 回圈,
list(map(times_two, range(5))) [times_two(num) for num in range(5)]
面對疫情 不必恐慌
break:跳出最近的封倍訓圈
continue:跳到最近的封倍訓圈的頂部
pass:什么都不做,空陳述句占位符
else:當且僅當回圈正常退出時運行
break
for 回圈在迭代中途停止,一旦執行了 break 陳述句,這個 for 回圈就會停止,
for letter in 'Python': if letter == 'o': break print(letter)
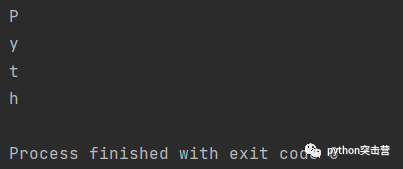
continue
將 break 替換為 continue 時,continue 陳述句在該單次迭代中停止了 for 回圈,并繼續下一次迭代(即字母 n),
for letter in 'Python': if letter == 'o': continue print(letter)
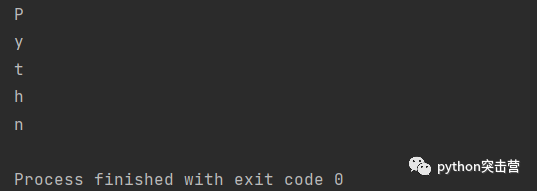
pass
在下列例子中,當 letter == ‘o’ 時沒有任何反應,就好像 if 條件從未存在過,它確實執行了,但沒有任何結果發生,這更像是一個占位符,如果知道會有一個 if 條件,會稍后再寫,只是還沒有放入 if 條件的內容,
for letter in 'Python': if letter == 'o': pass print(letter)
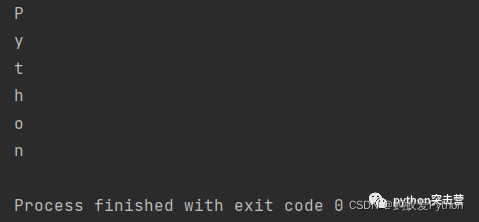
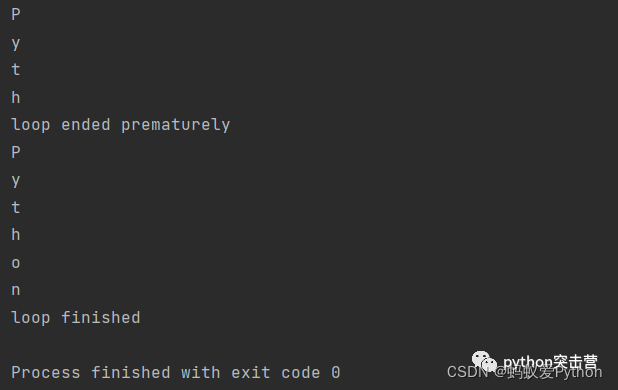
else
在下列示例中,else 子句僅在 for 回圈正常結束時執行,
#for非正常結束 for letter in 'Python': if letter == 'o': print('loop ended prematurely') break print(letter) else: print('loop finished')#for正常結束 for letter in 'Python': if letter == 'x': break print(letter) else: print('loop finished')
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/458483.html
標籤:Python