一、什么是numpy?
NumPy(Numerical Python)是Python的一種開源的數值計算擴展,這種工具可用來存盤和處理大型矩陣,比Python自身的嵌套串列(nested list structure)結構要高效的多(該結構也可以用來表示矩陣(matrix)),支持大量的維度陣列與矩陣運算,此外也針對陣列運算提供大量的數學函式庫,
終極目的:讀取檔案數字資料進行處理
NumPy 是一個運行速度非常快的數學庫,主要用于陣列計算,包含:
1.一個強大的N維陣列物件 ndarray
2.廣播功能函式
3.整合 C/C++/Fortran 代碼的工具
4.線性代數、傅里葉變換、亂數生成等功能
二、安裝numpy(Windows版)
-
首先,第一步打開電腦的運行,快捷鍵是win+r,然后輸入cmd打開命令視窗,
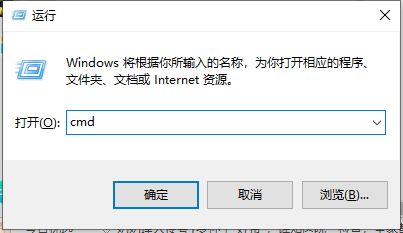
-
第二步,在打開的命令視窗中輸入pip --version,查看電腦是否有安裝pip(如果有輸出版本號即已經安裝好,若出現pip不是內部或外部命令則說明沒有安裝好),注意'--'前面有空格,
-
第三步,如果發現自己沒有安裝pip,就在命令視窗中輸入'easy_install.exe pip'這條命令進行下載,
-
第四步,如果發現自己已經安裝pip,但是版本是舊版本的話,可以輸入pip install pip --upgrade這條命令,以此來升級pip,
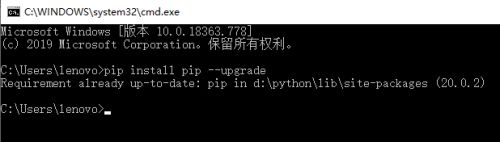
-
第五步,這時候可以重新輸入pip --version這條命令,來查看自己的版本,
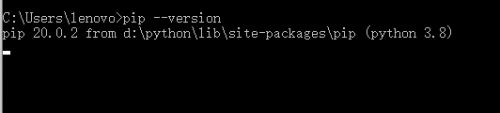
三、NumPy Ndarray 物件
NumPy 最重要的一個特點是其 N 維陣列物件 ndarray,它是一系列同型別資料的集合,以 0 下標為開始進行集合中元素的索引,
ndarray 物件是用于存放同型別元素的多維陣列,
ndarray 中的每個元素在記憶體中都有相同存盤大小的區域,
ndarray 內部由以下內容組成:
一個指向資料(記憶體或記憶體映射檔案中的一塊資料)的指標,
資料型別或 dtype,描述在陣列中的固定大小值的格子,
一個表示陣列形狀(shape)的元組,表示各維度大小的元組,
一個跨度元組(stride),其中的整數指的是為了前進到當前維度下一個元素需要"跨過"的位元組數,
ndarray 的內部結構:

跨度可以是負數,這樣會使陣列在記憶體中后向移動,切片中 obj[::-1] 或 obj[:,::-1] 就是如此,
創建一個 ndarray 只需呼叫 NumPy 的 array 函式即可:
1 numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
引數說明:
| 名稱 | 描述 |
|---|---|
| object | 陣列或嵌套的數列 |
| dtype | 陣列元素的資料型別,可選 |
| copy | 物件是否需要復制,可選 |
| order | 創建陣列的樣式,C為行方向,F為列方向,A為任意方向(默認) |
| subok | 默認回傳一個與基型別別一致的陣列 |
| ndmin | 指定生成陣列的最小維度 |
案例:
1 import numpy as np #給函式取別名方便呼叫 2 a = np.array([1,2,3]) 3 print (a) 4 #輸出結果如下:[1 2 3] 5 6 #實體 2 7 # 多于一個維度 8 a = np.array([[1, 2], [3, 4]]) 9 print (a) 10 #輸出結果如下: 11 # [[1 2] 12 # [3 4]] 13 14 #實體 3 15 # 最小維度 16 a = np.array([1, 2, 3, 4, 5], ndmin = 2) 17 print (a) 18 #輸出如下:[[1 2 3 4 5]] 19 20 #實體 4 21 # dtype 引數 22 a = np.array([1, 2, 3], dtype = complex) 23 print (a) 24 #輸出結果如下:[1.+0.j 2.+0.j 3.+0.j]
四、NumPy 資料型別
numpy 支持的資料型別比 Python 內置的型別要多很多,基本上可以和 C 語言的資料型別對應上,其中部分型別對應為 Python 內置的型別,下表列舉了常用 NumPy 基本型別,
| 名稱 | 描述 |
|---|---|
| bool_ | 布爾型資料型別(True 或者 False) |
| int_ | 默認的整數型別(類似于 C 語言中的 long,int32 或 int64) |
| intc | 與 C 的 int 型別一樣,一般是 int32 或 int 64 |
| intp | 用于索引的整數型別(類似于 C 的 ssize_t,一般情況下仍然是 int32 或 int64) |
| int8 | 位元組(-128 to 127) |
| int16 | 整數(-32768 to 32767) |
| int32 | 整數(-2147483648 to 2147483647) |
| int64 | 整數(-9223372036854775808 to 9223372036854775807) |
| uint8 | 無符號整數(0 to 255) |
| uint16 | 無符號整數(0 to 65535) |
| uint32 | 無符號整數(0 to 4294967295) |
| uint64 | 無符號整數(0 to 18446744073709551615) |
| float_ | float64 型別的簡寫 |
| float16 | 半精度浮點數,包括:1 個符號位,5 個指數位,10 個尾數位 |
| float32 | 單精度浮點數,包括:1 個符號位,8 個指數位,23 個尾數位 |
| float64 | 雙精度浮點數,包括:1 個符號位,11 個指數位,52 個尾數位 |
| complex_ | complex128 型別的簡寫,即 128 位復數 |
| complex64 | 復數,表示雙 32 位浮點數(實數部分和虛數部分) |
| complex128 | 復數,表示雙 64 位浮點數(實數部分和虛數部分) |
numpy 的數值型別實際上是 dtype 物件的實體,并對應唯一的字符,包括 np.bool_,np.int32,np.float32,等等,
資料型別物件 (dtype)
資料型別物件(numpy.dtype 類的實體)用來描述與陣列對應的記憶體區域是如何使用,它描述了資料的以下幾個方面::
- 資料的型別(整數,浮點數或者 Python 物件)
- 資料的大小(例如, 整數使用多少個位元組存盤)
- 資料的位元組順序(小端法或大端法)
- 在結構化型別的情況下,欄位的名稱、每個欄位的資料型別和每個欄位所取的記憶體塊的部分
- 如果資料型別是子陣列,那么它的形狀和資料型別是什么,
位元組順序是通過對資料型別預先設定 < 或 > 來決定的, < 意味著小端法(最小值存盤在最小的地址,即低位組放在最前面),> 意味著大端法(最重要的位元組存盤在最小的地址,即高位組放在最前面),
dtype 物件是使用以下語法構造的:
numpy.dtype(object, align, copy)
- object - 要轉換為的資料型別物件
- align - 如果為 true,填充欄位使其類似 C 的結構體,
- copy - 復制 dtype 物件 ,如果為 false,則是對內置資料型別物件的參考
1 import numpy as np 2 # 使用標量型別 3 dt = np.dtype(np.int32) 4 print(dt) 5 # 輸出結果為:int32 6 7 #實體 2 8 # int8, int16, int32, int64 四種資料型別可以使用字串 'i1', 'i2','i4','i8' 代替 9 dt = np.dtype('i4') 10 print(dt) 11 #輸出結果為:int32 12 #實體 3 13 14 15 # 位元組順序標注 16 dt = np.dtype('<i4') 17 print(dt) 18 #輸出結果為:int32 19 20 #下面實體展示結構化資料型別的使用,型別欄位和對應的實際型別將被創建, 21 22 #實體 4 23 # 首先創建結構化資料型別 24 dt = np.dtype([('age',np.int8)]) 25 print(dt) 26 #輸出結果為:[('age', 'i1')] 27 28 #實體 5 29 # 將資料型別應用于 ndarray 物件 30 dt = np.dtype([('age',np.int8)]) 31 a = np.array([(10,),(20,),(30,)], dtype = dt) 32 print(a) 33 #輸出結果為:[(10,) (20,) (30,)] 34 35 #實體 6 36 # 型別欄位名可以用于存取實際的 age 列 37 import numpy as np 38 dt = np.dtype([('age',np.int8)]) 39 a = np.array([(10,),(20,),(30,)], dtype = dt) 40 print(a['age']) 41 #輸出結果為:[10 20 30]
下面的示例定義一個結構化資料型別 student,包含字串欄位 name,整數欄位 age,及浮點欄位 marks,并將這個 dtype 應用到 ndarray 物件,
import numpy as np #實體 7 student = np.dtype([('name','S20'), ('age', 'i1'), ('marks', 'f4')]) print(student) #輸出結果為:[('name', 'S20'), ('age', 'i1'), ('marks', 'f4')] #實體 8 student = np.dtype([('name','S20'), ('age', 'i1'), ('marks', 'f4')]) a = np.array([('abc', 21, 50),('xyz', 18, 75)], dtype = student) print(a) #輸出結果為:[('abc', 21, 50.0), ('xyz', 18, 75.0)]
五、NumPy 陣列屬性
NumPy 陣列的維數稱為秩(rank),秩就是軸的數量,即陣列的維度,一維陣列的秩為 1,二維陣列的秩為 2,以此類推,
在 NumPy中,每一個線性的陣列稱為是一個軸(axis),也就是維度(dimensions),比如說,二維陣列相當于是兩個一維陣列,其中第一個一維陣列中每個元素又是一個一維陣列,所以一維陣列就是 NumPy 中的軸(axis),第一個軸相當于是底層陣列,第二個軸是底層陣列里的陣列,而軸的數量——秩,就是陣列的維數,
很多時候可以宣告 axis,axis=0,表示沿著第 0 軸進行操作,即對每一列進行操作;axis=1,表示沿著第1軸進行操作,即對每一行進行操作,
NumPy 的陣列中比較重要 ndarray 物件屬性有:
| 屬性 | 說明 |
|---|---|
| ndarray.ndim | 秩,即軸的數量或維度的數量 |
| ndarray.shape | 陣列的維度,對于矩陣,n 行 m 列 |
| ndarray.size | 陣列元素的總個數,相當于 .shape 中 n*m 的值 |
| ndarray.dtype | ndarray 物件的元素型別 |
| ndarray.itemsize | ndarray 物件中每個元素的大小,以位元組為單位 |
| ndarray.flags | ndarray 物件的記憶體資訊 |
| ndarray.real | ndarray元素的實部 |
| ndarray.imag | ndarray 元素的虛部 |
| ndarray.data | 包含實際陣列元素的緩沖區,由于一般通過陣列的索引獲取元素,所以通常不需要使用這個屬性, |
ndarray.ndim
ndarray.ndim 用于回傳陣列的維數,等于秩,
import numpy as np a = np.arange(24) print (a.ndim) # a 現只有一個維度 # 現在調整其大小 b = a.reshape(2,4,3) # b 現在擁有三個維度 print (b.ndim) #輸出結果為: #1 #3
ndarray.shape
ndarray.shape 表示陣列的維度,回傳一個元組,這個元組的長度就是維度的數目,即 ndim 屬性(秩),比如,一個二維陣列,其維度表示"行數"和"列數",
ndarray.shape 也可以用于調整陣列大小,
1 import numpy as np 2 3 a = np.array([[1,2,3],[4,5,6]]) 4 print (a.shape) 5 #輸出結果為: 6 #(2, 3) 7 #調整陣列大小, 8 9 #實體 10 11 a = np.array([[1,2,3],[4,5,6]]) 12 a.shape = (3,2) 13 print (a) 14 #輸出結果為: 15 16 #[[1 2] 17 # [3 4] 18 # [5 6]]
NumPy 也提供了 reshape 函式來調整陣列大小,
#實體 import numpy as np a = np.array([[1,2,3],[4,5,6]]) b = a.reshape(3,2) print (b) #輸出結果為: #[[1, 2] # [3, 4] # [5, 6]]
六、NumPy 創建陣列
darray 陣列除了可以使用底層 ndarray 構造器來創建外,也可以通過以下幾種方式來創建,
numpy.empty
numpy.empty 方法用來創建一個指定形狀(shape)、資料型別(dtype)且未初始化的陣列:
numpy.empty(shape, dtype = float, order = 'C')
引數說明:
| 引數 | 描述 |
|---|---|
| shape | 陣列形狀 |
| dtype | 資料型別,可選 |
| order | 有"C"和"F"兩個選項,分別代表,行優先和列優先,在計算機記憶體中的存盤元素的順序, |
下面是一個創建空陣列的實體:
實體
import numpy as np x = np.empty([3,2], dtype = int) print (x)輸出結果為:
[[ 6917529027641081856 5764616291768666155]
[ 6917529027641081859 -5764598754299804209]
[ 4497473538 844429428932120]]
注意 ? 陣列元素為隨機值,因為它們未初始化,
numpy.zeros
創建指定大小的陣列,陣列元素以 0 來填充:
numpy.zeros(shape, dtype = float, order = 'C')
引數說明:
| 引數 | 描述 |
|---|---|
| shape | 陣列形狀 |
| dtype | 資料型別,可選 |
| order | 'C' 用于 C 的行陣列,或者 'F' 用于 FORTRAN 的列陣列 |
實體
import numpy as np # 默認為浮點數 x = np.zeros(5) print(x) # 設定型別為整數 y = np.zeros((5,), dtype = np.int) print(y) # 自定義型別 z = np.zeros((2,2), dtype = [('x', 'i4'), ('y', 'i4')]) print(z)
輸出結果為:
[0. 0. 0. 0. 0.]
[0 0 0 0 0]
[[(0, 0) (0, 0)]
[(0, 0) (0, 0)]]
numpy.ones
創建指定形狀的陣列,陣列元素以 1 來填充:
numpy.ones(shape, dtype = None, order = 'C')
引數說明:
| 引數 | 描述 |
|---|---|
| shape | 陣列形狀 |
| dtype | 資料型別,可選 |
| order | 'C' 用于 C 的行陣列,或者 'F' 用于 FORTRAN 的列陣列 |
實體
import numpy as np # 默認為浮點數 x = np.ones(5) print(x) # 自定義型別 x = np.ones([2,2], dtype = int) print(x)
輸出結果為:
[1. 1. 1. 1. 1.] [[1 1] [1 1]]
NumPy 從已有的陣列創建陣列
numpy.asarray
numpy.asarray 類似 numpy.array,但 numpy.asarray 引數只有三個,比 numpy.array 少兩個,
numpy.asarray(a, dtype = None, order = None)
引數說明:
| 引數 | 描述 |
|---|---|
| a | 任意形式的輸入引數,可以是,串列, 串列的元組, 元組, 元組的元組, 元組的串列,多維陣列 |
| dtype | 資料型別,可選 |
| order | 可選,有"C"和"F"兩個選項,分別代表,行優先和列優先,在計算機記憶體中的存盤元素的順序, |
實體
將串列轉換為 ndarray:
實體
import numpy as np x = [1,2,3] a = np.asarray(x) print (a)
輸出結果為:
[1 2 3]
將元組轉換為 ndarray:
實體
import numpy as np x = (1,2,3) a = np.asarray(x) print (a)
輸出結果為:
[1 2 3]
將元組串列轉換為 ndarray:
實體
import numpy as np x = [(1,2,3),(4,5)] a = np.asarray(x) print (a)
輸出結果為:
[(1, 2, 3) (4, 5)]
設定了 dtype 引數:
實體
import numpy as np x = [1,2,3] a = np.asarray(x, dtype = float) print (a)
輸出結果為:
[ 1. 2. 3.]
NumPy 從數值范圍創建陣列
numpy.arange
numpy 包中的使用 arange 函式創建數值范圍并回傳 ndarray 物件,函式格式如下:
numpy.arange(start, stop, step, dtype)
根據 start 與 stop 指定的范圍以及 step 設定的步長,生成一個 ndarray,
引數說明:
| 引數 | 描述 |
|---|---|
start |
起始值,默認為0 |
stop |
終止值(不包含) |
step |
步長,默認為1 |
dtype |
回傳ndarray的資料型別,如果沒有提供,則會使用輸入資料的型別, |
實體
生成 0 到 5 的陣列:
實體
import numpy as np x = np.arange(5) print (x)
輸出結果如下:
[0 1 2 3 4]
設定回傳型別位 float:
實體
import numpy as np # 設定了 dtype x = np.arange(5, dtype = float) print (x)
輸出結果如下:
[0. 1. 2. 3. 4.]
設定了起始值、終止值及步長:
實體
import numpy as np x = np.arange(10,20,2) print (x)
輸出結果如下:
[10 12 14 16 18]
numpy.linspace
numpy.linspace 函式用于創建一個一維陣列,陣列是一個等引數列構成的,格式如下:
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
引數說明:
| 引數 | 描述 |
|---|---|
start |
序列的起始值 |
stop |
序列的終止值,如果endpoint為true,該值包含于數列中 |
num |
要生成的等步長的樣本數量,默認為50 |
endpoint |
該值為 true 時,數列中包含stop值,反之不包含,默認是True, |
retstep |
如果為 True 時,生成的陣列中會顯示間距,反之不顯示, |
dtype |
ndarray 的資料型別 |
以下實體用到三個引數,設定起始點為 1 ,終止點為 10,數列個數為 10,
實體
import numpy as np a = np.linspace(1,10,10) print(a)
輸出結果為:
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
numpy.logspace
numpy.logspace 函式用于創建一個于等比數列,格式如下:
np.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
base 引數意思是取對數的時候 log 的下標,
| 引數 | 描述 |
|---|---|
start |
序列的起始值為:base ** start |
stop |
序列的終止值為:base ** stop,如果endpoint為true,該值包含于數列中 |
num |
要生成的等步長的樣本數量,默認為50 |
endpoint |
該值為 true 時,數列中中包含stop值,反之不包含,默認是True, |
base |
對數 log 的底數, |
dtype |
ndarray 的資料型別 |
實體
import numpy as np # 默認底數是 10 a = np.logspace(1.0, 2.0, num = 10) print (a)
輸出結果為:
[ 10. 12.91549665 16.68100537 21.5443469 27.82559402
35.93813664 46.41588834 59.94842503 77.42636827 100. ]
將對數的底數設定為 2 :
實體
import numpy as np a = np.logspace(0,9,10,base=2) print (a)
輸出如下:
[ 1. 2. 4. 8. 16. 32. 64. 128. 256. 512.]
七、numpy對陣列的操作
1、NumPy 切片和索引
ndarray物件的內容可以通過索引或切片來訪問和修改,與 Python 中 list 的切片操作一樣,
ndarray 陣列可以基于 0 - n 的下標進行索引,切片物件可以通過內置的 slice 函式,并設定 start, stop 及 step 引數進行,從原陣列中切割出一個新陣列,
實體
import numpy as np a = np.arange(10) s = slice(2,7,2) # 從索引 2 開始到索引 7 停止,間隔為2 print (a[s])
輸出結果為:
[2 4 6]
以上實體中,我們首先通過 arange() 函式創建 ndarray 物件, 然后,分別設定起始,終止和步長的引數為 2,7 和 2,
我們也可以通過冒號分隔切片引數 start:stop:step 來進行切片操作:
實體
import numpy as np a = np.arange(10) b = a[2:7:2] # 從索引 2 開始到索引 7 停止,間隔為 2 print(b)
輸出結果為:
[2 4 6]
冒號 : 的解釋:如果只放置一個引數,如 [2],將回傳與該索引相對應的單個元素,如果為 [2:],表示從該索引開始以后的所有項都將被提取,如果使用了兩個引數,如 [2:7],那么則提取兩個索引(不包括停止索引)之間的項,
實體
import numpy as np a = np.arange(10) # [0 1 2 3 4 5 6 7 8 9] b = a[5] print(b)
輸出結果為:
5
實體
import numpy as np a = np.arange(10) print(a[2:])
輸出結果為:
[2 3 4 5 6 7 8 9]
實體
import numpy as np a = np.arange(10) # [0 1 2 3 4 5 6 7 8 9] print(a[2:5])
輸出結果為:
[2 3 4]
多維陣列同樣適用上述索引提取方法:
實體
import numpy as np a = np.array([[1,2,3],[3,4,5],[4,5,6]]) print(a) # 從某個索引處開始切割 print('從陣列索引 a[1:] 處開始切割') print(a[1:])
輸出結果為:
[[1 2 3]
[3 4 5]
[4 5 6]]
從陣列索引 a[1:] 處開始切割
[[3 4 5]
[4 5 6]]
切片還可以包括省略號 …,來使選擇元組的長度與陣列的維度相同, 如果在行位置使用省略號,它將回傳包含行中元素的 ndarray,
實體
import numpy as np a = np.array([[1,2,3],[3,4,5],[4,5,6]]) print (a[...,1]) # 第2列元素 print (a[1,...]) # 第2行元素 print (a[...,1:]) # 第2列及剩下的所有元素
輸出結果為:
[2 4 5]
[3 4 5]
[[2 3]
[4 5]
[5 6]]
2、NumPy 廣播(Broadcast)
廣播(Broadcast)是 numpy 對不同形狀(shape)的陣列進行數值計算的方式, 對陣列的算術運算通常在相應的元素上進行,
如果兩個陣列 a 和 b 形狀相同,即滿足 a.shape == b.shape,那么 a*b 的結果就是 a 與 b 陣列對應位相乘,這要求維數相同,且各維度的長度相同,
實體
import numpy as np a = np.array([1,2,3,4]) b = np.array([10,20,30,40]) c = a * b print (c)
輸出結果為:
[ 10 40 90 160]
當運算中的 2 個陣列的形狀不同時,numpy 將自動觸發廣播機制,如:
實體
import numpy as np a = np.array([[ 0, 0, 0], [10,10,10], [20,20,20], [30,30,30]]) b = np.array([1,2,3]) print(a + b)
輸出結果為:
[[ 1 2 3]
[11 12 13]
[21 22 23]
[31 32 33]]
實體
import numpy as np a = np.array([[ 0, 0, 0], [10,10,10], [20,20,20], [30,30,30]]) b = np.array([1,2,3]) bb = np.tile(b, (4, 1)) # 重復 b 的各個維度 print(a + bb)
輸出結果為:
[[ 1 2 3]
[11 12 13]
[21 22 23]
[31 32 33]]
3、NumPy 迭代陣列
NumPy 迭代器物件 numpy.nditer 提供了一種靈活訪問一個或者多個陣列元素的方式,
迭代器最基本的任務的可以完成對陣列元素的訪問,
接下來我們使用 arange() 函式創建一個 2X3 陣列,并使用 nditer 對它進行迭代,
實體
import numpy as np a = np.arange(6).reshape(2,3) print ('原始陣列是:') print (a) print ('\n') print ('迭代輸出元素:') for x in np.nditer(a): print (x, end=", " ) print ('\n')
輸出結果為:
原始陣列是:
[[0 1 2]
[3 4 5]]
迭代輸出元素:
0, 1, 2, 3, 4, 5,
控制遍歷順序
for x in np.nditer(a, order='F'):Fortran order,即是列序優先;
for x in np.nditer(a.T, order='C'):C order,即是行序優先;
import numpy as np a = np.arange(0,60,5) a = a.reshape(3,4) print ('原始陣列是:') print (a) print ('\n') print ('原始陣列的轉置是:') b = a.T print (b) print ('\n') print ('以 C 風格順序排序:') c = b.copy(order='C') print (c) for x in np.nditer(c): print (x, end=", " ) print ('\n') print ('以 F 風格順序排序:') c = b.copy(order='F') print (c) for x in np.nditer(c): print (x, end=", " )
4、陣列操作
numpy.reshape
numpy.reshape 函式可以在不改變資料的條件下修改形狀,格式如下:
numpy.reshape(arr, newshape, order='C')
arr:要修改形狀的陣列newshape:整數或者整數陣列,新的形狀應當兼容原有形狀- order:'C' -- 按行,'F' -- 按列,'A' -- 原順序,'k' -- 元素在記憶體中的出現順序,
實體
import numpy as np a = np.arange(8) print ('原始陣列:') print (a) print ('\n') b = a.reshape(4,2) print ('修改后的陣列:') print (b)
numpy.ndarray.flat
numpy.ndarray.flat 是一個陣列元素迭代器,實體如下:
實體
import numpy as np a = np.arange(9).reshape(3,3) print ('原始陣列:') for row in a: print (row) #對陣列中每個元素都進行處理,可以使用flat屬性,該屬性是一個陣列元素迭代器: print ('迭代后的陣列:') for element in a.flat: print (element)
numpy.ndarray.flatten
numpy.ndarray.flatten 回傳一份陣列拷貝,對拷貝所做的修改不會影響原始陣列,格式如下:
ndarray.flatten(order='C')
引數說明:
- order:'C' -- 按行,'F' -- 按列,'A' -- 原順序,'K' -- 元素在記憶體中的出現順序,
實體
import numpy as np a = np.arange(8).reshape(2,4) print ('原陣列:') print (a) print ('\n') # 默認按行 print ('展開的陣列:') print (a.flatten()) print ('\n') print ('以 F 風格順序展開的陣列:') print (a.flatten(order = 'F'))
numpy.ravel
numpy.ravel() 展平的陣列元素,順序通常是"C風格",回傳的是陣列視圖(view,有點類似 C/C++參考reference的意味),修改會影響原始陣列,
該函式接收兩個引數:
numpy.ravel(a, order='C')
引數說明:
- order:'C' -- 按行,'F' -- 按列,'A' -- 原順序,'K' -- 元素在記憶體中的出現順序,
實體
import numpy as np a = np.arange(8).reshape(2,4) print ('原陣列:') print (a) print ('\n') print ('呼叫 ravel 函式之后:') print (a.ravel()) print ('\n') print ('以 F 風格順序呼叫 ravel 函式之后:') print (a.ravel(order = 'F'))
numpy.transpose
numpy.transpose 函式用于對換陣列的維度,格式如下:
numpy.transpose(arr, axes)
引數說明:
arr:要操作的陣列axes:整數串列,對應維度,通常所有維度都會對換,
實體
import numpy as np a = np.arange(12).reshape(3,4) print ('原陣列:') print (a ) print ('\n') print ('對換陣列:') print (np.transpose(a))
numpy.rollaxis
numpy.rollaxis 函式向后滾動特定的軸到一個特定位置,格式如下:
numpy.rollaxis(arr, axis, start)
引數說明:
arr:陣列axis:要向后滾動的軸,其它軸的相對位置不會改變start:默認為零,表示完整的滾動,會滾動到特定位置,
實體
import numpy as np # 創建了三維的 ndarray a = np.arange(8).reshape(2,2,2) print ('原陣列:') print (a) print ('獲取陣列中一個值:') print(np.where(a==6)) print(a[1,1,0]) # 為 6 print ('\n') # 將軸 2 滾動到軸 0(寬度到深度) print ('呼叫 rollaxis 函式:') b = np.rollaxis(a,2,0) print (b) # 查看元素 a[1,1,0],即 6 的坐標,變成 [0, 1, 1] # 最后一個 0 移動到最前面 print(np.where(b==6)) print ('\n') # 將軸 2 滾動到軸 1:(寬度到高度) print ('呼叫 rollaxis 函式:') c = np.rollaxis(a,2,1) print (c) # 查看元素 a[1,1,0],即 6 的坐標,變成 [1, 0, 1] # 最后的 0 和 它前面的 1 對換位置 print(np.where(c==6)) print ('\n')
numpy.swapaxes
numpy.swapaxes 函式用于交換陣列的兩個軸,格式如下:
numpy.swapaxes(arr, axis1, axis2)
arr:輸入的陣列axis1:對應第一個軸的整數axis2:對應第二個軸的整數
實體
import numpy as np # 創建了三維的 ndarray a = np.arange(8).reshape(2,2,2) print ('原陣列:') print (a) print ('\n') # 現在交換軸 0(深度方向)到軸 2(寬度方向) print ('呼叫 swapaxes 函式后的陣列:') print (np.swapaxes(a, 2, 0))
numpy.broadcast
numpy.broadcast 用于模仿廣播的物件,它回傳一個物件,該物件封裝了將一個陣列廣播到另一個陣列的結果,
該函式使用兩個陣列作為輸入引數,如下實體:
實體
import numpy as np x = np.array([[1], [2], [3]]) y = np.array([4, 5, 6]) # 對 y 廣播 x b = np.broadcast(x,y) # 它擁有 iterator 屬性,基于自身組件的迭代器元組 print ('對 y 廣播 x:') r,c = b.iters # Python3.x 為 next(context) ,Python2.x 為 context.next() print (next(r), next(c)) print (next(r), next(c)) print ('\n') # shape 屬性回傳廣播物件的形狀 print ('廣播物件的形狀:') print (b.shape) print ('\n') # 手動使用 broadcast 將 x 與 y 相加 b = np.broadcast(x,y) c = np.empty(b.shape) print ('手動使用 broadcast 將 x 與 y 相加:') print (c.shape) print ('\n') c.flat = [u + v for (u,v) in b] print ('呼叫 flat 函式:') print (c) print ('\n') # 獲得了和 NumPy 內建的廣播支持相同的結果 print ('x 與 y 的和:') print (x + y)
numpy.broadcast_to
numpy.broadcast_to 函式將陣列廣播到新形狀,它在原始陣列上回傳只讀視圖, 它通常不連續, 如果新形狀不符合 NumPy 的廣播規則,該函式可能會拋出ValueError,
numpy.broadcast_to(array, shape, subok)
實體
import numpy as np a = np.arange(4).reshape(1,4) print ('原陣列:') print (a) print ('\n') print ('呼叫 broadcast_to 函式之后:') print (np.broadcast_to(a,(4,4)))
numpy.expand_dims
numpy.expand_dims 函式通過在指定位置插入新的軸來擴展陣列形狀,函式格式如下:
numpy.expand_dims(arr, axis)
引數說明:
arr:輸入陣列axis:新軸插入的位置
實體
import numpy as np x = np.array(([1,2],[3,4])) print ('陣列 x:') print (x) print ('\n') y = np.expand_dims(x, axis = 0) print ('陣列 y:') print (y) print ('\n') print ('陣列 x 和 y 的形狀:') print (x.shape, y.shape) print ('\n') # 在位置 1 插入軸 y = np.expand_dims(x, axis = 1) print ('在位置 1 插入軸之后的陣列 y:') print (y) print ('\n') print ('x.ndim 和 y.ndim:') print (x.ndim,y.ndim) print ('\n') print ('x.shape 和 y.shape:') print (x.shape, y.shape)
numpy.squeeze
numpy.squeeze 函式從給定陣列的形狀中洗掉一維的條目,函式格式如下:
numpy.squeeze(arr, axis)
引數說明:
arr:輸入陣列axis:整數或整數元組,用于選擇形狀中一維條目的子集
實體
import numpy as np x = np.arange(9).reshape(1,3,3) print ('陣列 x:') print (x) print ('\n') y = np.squeeze(x) print ('陣列 y:') print (y) print ('\n') print ('陣列 x 和 y 的形狀:') print (x.shape, y.shape)
numpy.concatenate
numpy.concatenate 函式用于沿指定軸連接相同形狀的兩個或多個陣列,格式如下:
numpy.concatenate((a1, a2, ...), axis)
引數說明:
a1, a2, ...:相同型別的陣列axis:沿著它連接陣列的軸,默認為 0
實體
import numpy as np a = np.array([[1,2],[3,4]]) print ('第一個陣列:') print (a) print ('\n') b = np.array([[5,6],[7,8]]) print ('第二個陣列:') print (b) print ('\n') # 兩個陣列的維度相同 print ('沿軸 0 連接兩個陣列:') print (np.concatenate((a,b))) print ('\n') print ('沿軸 1 連接兩個陣列:') print (np.concatenate((a,b),axis = 1))
numpy.split
numpy.split 函式沿特定的軸將陣列分割為子陣列,格式如下:
numpy.split(ary, indices_or_sections, axis)
引數說明:
ary:被分割的陣列indices_or_sections:如果是一個整數,就用該數平均切分,如果是一個陣列,為沿軸切分的位置(左開右閉)axis:設定沿著哪個方向進行切分,默認為 0,橫向切分,即水平方向,為 1 時,縱向切分,即豎直方向,
實體
import numpy as np a = np.arange(9) print ('第一個陣列:') print (a) print ('\n') print ('將陣列分為三個大小相等的子陣列:') b = np.split(a,3) print (b) print ('\n') print ('將陣列在一維陣列中表明的位置分割:') b = np.split(a,[4,7]) print (b)
numpy.resize
numpy.resize 函式回傳指定大小的新陣列,
如果新陣列大小大于原始大小,則包含原始陣列中的元素的副本,
numpy.resize(arr, shape)
引數說明:
arr:要修改大小的陣列shape:回傳陣列的新形狀
實體
import numpy as np a = np.array([[1,2,3],[4,5,6]]) print ('第一個陣列:') print (a) print ('\n') print ('第一個陣列的形狀:') print (a.shape) print ('\n') b = np.resize(a, (3,2)) print ('第二個陣列:') print (b) print ('\n') print ('第二個陣列的形狀:') print (b.shape) print ('\n') # 要注意 a 的第一行在 b 中重復出現,因為尺寸變大了 print ('修改第二個陣列的大小:') b = np.resize(a,(3,3)) print (b)
numpy.append
numpy.append 函式在陣列的末尾添加值, 追加操作會分配整個陣列,并把原來的陣列復制到新陣列中, 此外,輸入陣列的維度必須匹配否則將生成ValueError,
append 函式回傳的始終是一個一維陣列,
numpy.append(arr, values, axis=None)
引數說明:
arr:輸入陣列values:要向arr添加的值,需要和arr形狀相同(除了要添加的軸)axis:默認為 None,當axis無定義時,是橫向加成,回傳總是為一維陣列!當axis有定義的時候,分別為0和1的時候,當axis有定義的時候,分別為0和1的時候(列數要相同),當axis為1時,陣列是加在右邊(行數要相同),
實體
import numpy as np a = np.array([[1,2,3],[4,5,6]]) print ('第一個陣列:') print (a) print ('\n') print ('向陣列添加元素:') print (np.append(a, [7,8,9])) print ('\n') print ('沿軸 0 添加元素:') print (np.append(a, [[7,8,9]],axis = 0)) print ('\n') print ('沿軸 1 添加元素:') print (np.append(a, [[5,5,5],[7,8,9]],axis = 1))
numpy.delete
numpy.delete 函式回傳從輸入陣列中洗掉指定子陣列的新陣列, 與 insert() 函式的情況一樣,如果未提供軸引數,則輸入陣列將展開,
Numpy.delete(arr, obj, axis)
引數說明:
arr:輸入陣列obj:可以被切片,整數或者整數陣列,表明要從輸入陣列洗掉的子陣列axis:沿著它洗掉給定子陣列的軸,如果未提供,則輸入陣列會被展開
實體
import numpy as np a = np.arange(12).reshape(3,4) print ('第一個陣列:') print (a) print ('\n') print ('未傳遞 Axis 引數, 在插入之前輸入陣列會被展開,') print (np.delete(a,5)) print ('\n') print ('洗掉第二列:') print (np.delete(a,1,axis = 1)) print ('\n') print ('包含從陣列中洗掉的替代值的切片:') a = np.array([1,2,3,4,5,6,7,8,9,10]) print (np.delete(a, np.s_[::2]))
numpy.unique
numpy.unique 函式用于去除陣列中的重復元素,
numpy.unique(arr, return_index, return_inverse, return_counts)
arr:輸入陣列,如果不是一維陣列則會展開return_index:如果為true,回傳新串列元素在舊串列中的位置(下標),并以串列形式儲return_inverse:如果為true,回傳舊串列元素在新串列中的位置(下標),并以串列形式儲return_counts:如果為true,回傳去重陣列中的元素在原陣列中的出現次數
實體
import numpy as np a = np.array([5,2,6,2,7,5,6,8,2,9]) print ('第一個陣列:') print (a) print ('\n') print ('第一個陣列的去重值:') u = np.unique(a) print (u) print ('\n') print ('去重陣列的索引陣列:') u,indices = np.unique(a, return_index = True) print (indices) print ('\n') print ('我們可以看到每個和原陣列下標對應的數值:') print (a) print ('\n') print ('去重陣列的下標:') u,indices = np.unique(a,return_inverse = True) print (u) print ('\n') print ('下標為:') print (indices) print ('\n') print ('使用下標重構原陣列:') print (u[indices]) print ('\n') print ('回傳去重元素的重復數量:') u,indices = np.unique(a,return_counts = True) print (u) print (indices)
八、numpy函式
1、NumPy 字串函式
以下函式用于對 dtype 為 numpy.string_ 或 numpy.unicode_ 的陣列執行向量化字串操作, 它們基于 Python 內置庫中的標準字串函式,
這些函式在字符陣列類(numpy.char)中定義,
| 函式 | 描述 |
|---|---|
add() |
對兩個陣列的逐個字串元素進行連接 |
| multiply() | 回傳按元素多重連接后的字串 |
center() |
居中字串 |
capitalize() |
將字串第一個字母轉換為大寫 |
title() |
將字串的每個單詞的第一個字母轉換為大寫 |
lower() |
陣列元素轉換為小寫 |
upper() |
陣列元素轉換為大寫 |
split() |
指定分隔符對字串進行分割,并回傳陣列串列 |
splitlines() |
回傳元素中的行串列,以換行符分割 |
strip() |
移除元素開頭或者結尾處的特定字符 |
join() |
通過指定分隔符來連接陣列中的元素 |
replace() |
使用新字串替換字串中的所有子字串 |
decode() |
陣列元素依次呼叫str.decode |
encode() |
陣列元素依次呼叫str.encode |
numpy.char.add()
numpy.char.add() 函式依次對兩個陣列的元素進行字串連接,
實體
import numpy as np print ('連接兩個字串:') print (np.char.add(['hello'],[' xyz'])) print ('\n') print ('連接示例:') print (np.char.add(['hello', 'hi'],[' abc', ' xyz']))
numpy.char.multiply()
numpy.char.multiply() 函式執行多重連接,
實體
import numpy as np print (np.char.multiply('Runoob ',3))
numpy.char.center()
numpy.char.center() 函式用于將字串居中,并使用指定字符在左側和右側進行填充,
實體
import numpy as np # np.char.center(str , width,fillchar) : # str: 字串,width: 長度,fillchar: 填充字符 print (np.char.center('Runoob', 20,fillchar = '*'))
numpy.char.capitalize()
numpy.char.capitalize() 函式將字串的第一個字母轉換為大寫:
實體
import numpy as np print (np.char.capitalize('runoob'))
numpy.char.title()
numpy.char.title() 函式將字串的每個單詞的第一個字母轉換為大寫:
實體
import numpy as np print (np.char.title('i like runoob'))
numpy.char.lower()
numpy.char.lower() 函式對陣列的每個元素轉換為小寫,它對每個元素呼叫 str.lower,
實體
import numpy as np #操作陣列 print (np.char.lower(['RUNOOB','GOOGLE'])) # 操作字串 print (np.char.lower('RUNOOB'))
numpy.char.upper()
numpy.char.upper() 函式對陣列的每個元素轉換為大寫,它對每個元素呼叫 str.upper,
實體
import numpy as np #操作陣列 print (np.char.upper(['runoob','google'])) # 操作字串 print (np.char.upper('runoob'))
numpy.char.split()
numpy.char.split() 通過指定分隔符對字串進行分割,并回傳陣列,默認情況下,分隔符為空格,
實體
import numpy as np # 分隔符默認為空格 print (np.char.split ('i like runoob?')) # 分隔符為 . print (np.char.split ('www.runoob.com', sep = '.'))
numpy.char.splitlines()
numpy.char.splitlines() 函式以換行符作為分隔符來分割字串,并回傳陣列,
實體
import numpy as np # 換行符 \n print (np.char.splitlines('i\nlike runoob?')) print (np.char.splitlines('i\rlike runoob?'))
numpy.char.strip()
numpy.char.strip() 函式用于移除開頭或結尾處的特定字符,
實體
import numpy as np # 移除字串頭尾的 a 字符 print (np.char.strip('ashok arunooba','a')) # 移除陣列元素頭尾的 a 字符 print (np.char.strip(['arunooba','admin','java'],'a'))
numpy.char.join()
numpy.char.join() 函式通過指定分隔符來連接陣列中的元素或字串
實體
import numpy as np # 操作字串 print (np.char.join(':','runoob')) # 指定多個分隔符操作陣列元素 print (np.char.join([':','-'],['runoob','google']))
numpy.char.replace()
numpy.char.replace() 函式使用新字串替換字串中的所有子字串,
實體
import numpy as np print (np.char.replace ('i like runoob', 'oo', 'cc'))
numpy.char.encode()
numpy.char.encode() 函式對陣列中的每個元素呼叫 str.encode 函式, 默認編碼是 utf-8,可以使用標準 Python 庫中的編解碼器,
實體
import numpy as np a = np.char.encode('runoob', 'cp500') print (a)
numpy.char.decode()
numpy.char.decode() 函式對編碼的元素進行 str.decode() 解碼,
實體
import numpy as np a = np.char.encode('runoob', 'cp500') print (a) print (np.char.decode(a,'cp500'))
2、NumPy 數學函式
NumPy 包含大量的各種數學運算的函式,包括三角函式,算術運算的函式,復數處理函式等,
三角函式(詳情:https://www.runoob.com/numpy/numpy-mathematical-functions.html)NumPy 提供了標準的三角函式:sin()、cos()、tan(),
實體
import numpy as np a = np.array([0,30,45,60,90]) print ('不同角度的正弦值:') # 通過乘 pi/180 轉化為弧度 print (np.sin(a*np.pi/180)) print ('\n') print ('陣列中角度的余弦值:') print (np.cos(a*np.pi/180)) print ('\n') print ('陣列中角度的正切值:') print (np.tan(a*np.pi/180))
函式 描述
add() 對兩個陣列的逐個字串元素進行連接
multiply() 回傳按元素多重連接后的字串
center() 居中字串
capitalize() 將字串第一個字母轉換為大寫
title() 將字串的每個單詞的第一個字母轉換為大寫
lower() 陣列元素轉換為小寫
upper() 陣列元素轉換為大寫
split() 指定分隔符對字串進行分割,并回傳陣列串列
splitlines() 回傳元素中的行串列,以換行符分割
strip() 移除元素開頭或者結尾處的特定字符
join() 通過指定分隔符來連接陣列中的元素
replace() 使用新字串替換字串中的所有子字串
decode() 陣列元素依次呼叫str.decode
encode() 陣列元素依次呼叫str.encode
舍入函式
numpy.around() 函式回傳指定數字的四舍五入值,
numpy.around(a,decimals)
引數說明:
- a: 陣列
- decimals: 舍入的小數位數, 默認值為0, 如果為負,整數將四舍五入到小數點左側的位置
實體
import numpy as np a = np.array([1.0,5.55, 123, 0.567, 25.532]) print ('原陣列:') print (a) print ('\n') print ('舍入后:') print (np.around(a)) print (np.around(a, decimals = 1)) print (np.around(a, decimals = -1))
numpy.floor()
numpy.floor() 回傳小于或者等于指定運算式的最大整數,即向下取整,
實體
import numpy as np a = np.array([-1.7, 1.5, -0.2, 0.6, 10]) print ('提供的陣列:') print (a) print ('\n') print ('修改后的陣列:') print (np.floor(a))
numpy.ceil()
numpy.ceil() 回傳大于或者等于指定運算式的最小整數,即向上取整,
實體
import numpy as np a = np.array([-1.7, 1.5, -0.2, 0.6, 10]) print ('提供的陣列:') print (a) print ('\n') print ('修改后的陣列:') print (np.ceil(a))
3、NumPy 算術函式
NumPy 算術函式包含簡單的加減乘除: add(),subtract(),multiply() 和 divide(),
需要注意的是陣列必須具有相同的形狀或符合陣列廣播規則,
import numpy as np a = np.arange(9, dtype = np.float_).reshape(3,3) print ('第一個陣列:') print (a) print ('\n') print ('第二個陣列:') b = np.array([10,10,10]) print (b) print ('\n') print ('兩個陣列相加:') print (np.add(a,b)) print ('\n') print ('兩個陣列相減:') print (np.subtract(a,b)) print ('\n') print ('兩個陣列相乘:') print (np.multiply(a,b)) print ('\n') print ('兩個陣列相除:') print (np.divide(a,b))
此外 Numpy 也包含了其他重要的算術函式,
numpy.reciprocal()
numpy.reciprocal() 函式回傳引數逐元素的倒數,如 1/4 倒數為 4/1,
#實體 import numpy as np a = np.array([0.25, 1.33, 1, 100]) print ('我們的陣列是:') print (a) print ('\n') print ('呼叫 reciprocal 函式:') print (np.reciprocal(a))
numpy.power()
numpy.power() 函式將第一個輸入陣列中的元素作為底數,計算它與第二個輸入陣列中相應元素的冪,
實體
import numpy as np a = np.array([10,100,1000]) print ('我們的陣列是;') print (a) print ('\n') print ('呼叫 power 函式:') print (np.power(a,2)) print ('\n') print ('第二個陣列:') b = np.array([1,2,3]) print (b) print ('\n') print ('再次呼叫 power 函式:') print (np.power(a,b))
numpy.mod()
numpy.mod() 計算輸入陣列中相應元素的相除后的余數, 函式 numpy.remainder() 也產生相同的結果,
實體
import numpy as np a = np.array([10,20,30]) b = np.array([3,5,7]) print ('第一個陣列:') print (a) print ('\n') print ('第二個陣列:') print (b) print ('\n') print ('呼叫 mod() 函式:') print (np.mod(a,b)) print ('\n') print ('呼叫 remainder() 函式:') print (np.remainder(a,b))
4、NumPy 統計函式
NumPy 提供了很多統計函式,用于從陣列中查找最小元素,最大元素,百分位標準差和方差等, 函式說明如下:
numpy.amin() 和 numpy.amax()
numpy.amin() 用于計算陣列中的元素沿指定軸的最小值,
numpy.amax() 用于計算陣列中的元素沿指定軸的最大值,
案例
import numpy as np a = np.array([[3,7,5],[8,4,3],[2,4,9]]) print ('我們的陣列是:') print (a) print ('\n') print ('呼叫 amin() 函式:') print (np.amin(a,1)) print ('\n') print ('再次呼叫 amin() 函式:') print (np.amin(a,0)) print ('\n') print ('呼叫 amax() 函式:') print (np.amax(a)) print ('\n') print ('再次呼叫 amax() 函式:') print (np.amax(a, axis = 0))
numpy.ptp()
numpy.ptp()函式計算陣列中元素最大值與最小值的差(最大值 - 最小值),
實體
import numpy as np a = np.array([[3,7,5],[8,4,3],[2,4,9]]) print ('我們的陣列是:') print (a) print ('\n') print ('呼叫 ptp() 函式:') print (np.ptp(a)) print ('\n') print ('沿軸 1 呼叫 ptp() 函式:') print (np.ptp(a, axis = 1)) print ('\n') print ('沿軸 0 呼叫 ptp() 函式:') print (np.ptp(a, axis = 0))
numpy.percentile()
百分位數是統計中使用的度量,表示小于這個值的觀察值的百分比, 函式numpy.percentile()接受以下引數,
numpy.percentile(a, q, axis)
引數說明:
- a: 輸入陣列
- q: 要計算的百分位數,在 0 ~ 100 之間
- axis: 沿著它計算百分位數的軸
首先明確百分位數:
第 p 個百分位數是這樣一個值,它使得至少有 p% 的資料項小于或等于這個值,且至少有 (100-p)% 的資料項大于或等于這個值,
舉個例子:高等院校的入學考試成績經常以百分位數的形式報告,比如,假設某個考生在入學考試中的語文部分的原始分數為 54 分,相對于參加同一考試的其他學生來說,他的成績如何并不容易知道,但是如果原始分數54分恰好對應的是第70百分位數,我們就能知道大約70%的學生的考分比他低,而約30%的學生考分比他高,
這里的 p = 70,
實體
import numpy as np a = np.array([[10, 7, 4], [3, 2, 1]]) print ('我們的陣列是:') print (a) print ('呼叫 percentile() 函式:') # 50% 的分位數,就是 a 里排序之后的中位數 print (np.percentile(a, 50)) # axis 為 0,在縱列上求 print (np.percentile(a, 50, axis=0)) # axis 為 1,在橫行上求 print (np.percentile(a, 50, axis=1)) # 保持維度不變 print (np.percentile(a, 50, axis=1, keepdims=True))
numpy.median()
numpy.median() 函式用于計算陣列 a 中元素的中位數(中值)
實體
import numpy as np a = np.array([[30,65,70],[80,95,10],[50,90,60]]) print ('我們的陣列是:') print (a) print ('\n') print ('呼叫 median() 函式:') print (np.median(a)) print ('\n') print ('沿軸 0 呼叫 median() 函式:') print (np.median(a, axis = 0)) print ('\n') print ('沿軸 1 呼叫 median() 函式:') print (np.median(a, axis = 1))
numpy.mean()
numpy.mean() 函式回傳陣列中元素的算術平均值, 如果提供了軸,則沿其計算,
算術平均值是沿軸的元素的總和除以元素的數量,
實體
import numpy as np a = np.array([[1,2,3],[3,4,5],[4,5,6]]) print ('我們的陣列是:') print (a) print ('\n') print ('呼叫 mean() 函式:') print (np.mean(a)) print ('\n') print ('沿軸 0 呼叫 mean() 函式:') print (np.mean(a, axis = 0)) print ('\n') print ('沿軸 1 呼叫 mean() 函式:') print (np.mean(a, axis = 1))
numpy.average()
numpy.average() 函式根據在另一個陣列中給出的各自的權重計算陣列中元素的加權平均值,
該函式可以接受一個軸引數, 如果沒有指定軸,則陣列會被展開,
加權平均值即將各數值乘以相應的權數,然后加總求和得到總體值,再除以總的單位數,
考慮陣列[1,2,3,4]和相應的權重[4,3,2,1],通過將相應元素的乘積相加,并將和除以權重的和,來計算加權平均值,
加權平均值 = (1*4+2*3+3*2+4*1)/(4+3+2+1)
實體
import numpy as np a = np.array([1,2,3,4]) print ('我們的陣列是:') print (a) print ('\n') print ('呼叫 average() 函式:') print (np.average(a)) print ('\n') # 不指定權重時相當于 mean 函式 wts = np.array([4,3,2,1]) print ('再次呼叫 average() 函式:') print (np.average(a,weights = wts)) print ('\n') # 如果 returned 引數設為 true,則回傳權重的和 print ('權重的和:') print (np.average([1,2,3, 4],weights = [4,3,2,1], returned = True))
5、NumPy 排序、條件刷選函式
NumPy 提供了多種排序的方法, 這些排序函式實作不同的排序演算法,每個排序演算法的特征在于執行速度,最壞情況性能,所需的作業空間和演算法的穩定性, 下表顯示了三種排序演算法的比較,
numpy.sort()
numpy.sort() 函式回傳輸入陣列的排序副本,函式格式如下:
numpy.sort(a, axis, kind, order)
引數說明:
- a: 要排序的陣列
- axis: 沿著它排序陣列的軸,如果沒有陣列會被展開,沿著最后的軸排序, axis=0 按列排序,axis=1 按行排序
- kind: 默認為'quicksort'(快速排序)
- order: 如果陣列包含欄位,則是要排序的欄位
實體
import numpy as np a = np.array([[3,7],[9,1]]) print ('我們的陣列是:') print (a) print ('\n') print ('呼叫 sort() 函式:') print (np.sort(a)) print ('\n') print ('按列排序:') print (np.sort(a, axis = 0)) print ('\n') # 在 sort 函式中排序欄位 dt = np.dtype([('name', 'S10'),('age', int)]) a = np.array([("raju",21),("anil",25),("ravi", 17), ("amar",27)], dtype = dt) print ('我們的陣列是:') print (a) print ('\n') print ('按 name 排序:') print (np.sort(a, order = 'name'))
numpy.argsort()
numpy.argsort() 函式回傳的是陣列值從小到大的索引值,
實體
import numpy as np x = np.array([3, 1, 2]) print ('我們的陣列是:') print (x) print ('\n') print ('對 x 呼叫 argsort() 函式:') y = np.argsort(x) print (y) print ('\n') print ('以排序后的順序重構原陣列:') print (x[y]) print ('\n') print ('使用回圈重構原陣列:') for i in y: print (x[i], end=" ")
numpy.lexsort()
numpy.lexsort() 用于對多個序列進行排序,把它想象成對電子表格進行排序,每一列代表一個序列,排序時優先照顧靠后的列,
這里舉一個應用場景:小升初考試,重點班錄取學生按照總成績錄取,在總成績相同時,數學成績高的優先錄取,在總成績和數學成績都相同時,按照英語成績錄取…… 這里,總成績排在電子表格的最后一列,數學成績在倒數第二列,英語成績在倒數第三列,
實體
import numpy as np nm = ('raju','anil','ravi','amar') dv = ('f.y.', 's.y.', 's.y.', 'f.y.') ind = np.lexsort((dv,nm)) print ('呼叫 lexsort() 函式:') print (ind) print ('\n') print ('使用這個索引來獲取排序后的資料:') print ([nm[i] + ", " + dv[i] for i in ind])
numpy.nonzero()
numpy.nonzero() 函式回傳輸入陣列中非零元素的索引,
實體
import numpy as np
a = np.array([[30,40,0],[0,20,10],[50,0,60]])
print ('我們的陣列是:')
print (a)
print ('\n')
print ('呼叫 nonzero() 函式:')
print (np.nonzero (a))
numpy.where()
numpy.where() 函式回傳輸入陣列中滿足給定條件的元素的索引,
實體
import numpy as np x = np.arange(9.).reshape(3, 3) print ('我們的陣列是:') print (x) print ( '大于 3 的元素的索引:') y = np.where(x > 3) print (y) print ('使用這些索引來獲取滿足條件的元素:') print (x[y])
numpy.extract()
numpy.extract() 函式根據某個條件從陣列中抽取元素,回傳滿條件的元素,
實體
import numpy as np x = np.arange(9.).reshape(3, 3) print ('我們的陣列是:') print (x) # 定義條件, 選擇偶數元素 condition = np.mod(x,2) == 0 print ('按元素的條件值:') print (condition) print ('使用條件提取元素:') print (np.extract(condition, x))
全文來自:https://www.runoob.com/numpy/numpy-tutorial.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/463464.html
標籤:其他
上一篇:觀察執行緒的狀態
下一篇:執行緒有哪些狀態呢?