使用帶有 SQL 的資料塊,我必須將我的 csv 資料集匯入一個表并使用它分析資料。我的問題是在我匯入 csv 資料集后,所有列都是字串型別,但其中一些需要是數字。我該如何解決?
如何定義 csv 檔案的列型別?我嘗試在 xlsx 中轉換檔案并設定數字型別,但隨后無法在 csv 中再次轉換(或者我不知道如何)。
感謝您的幫助
PS:databricks 只需要 csv 檔案而不是 xlsx 或類似檔案。
uj5u.com熱心網友回復:
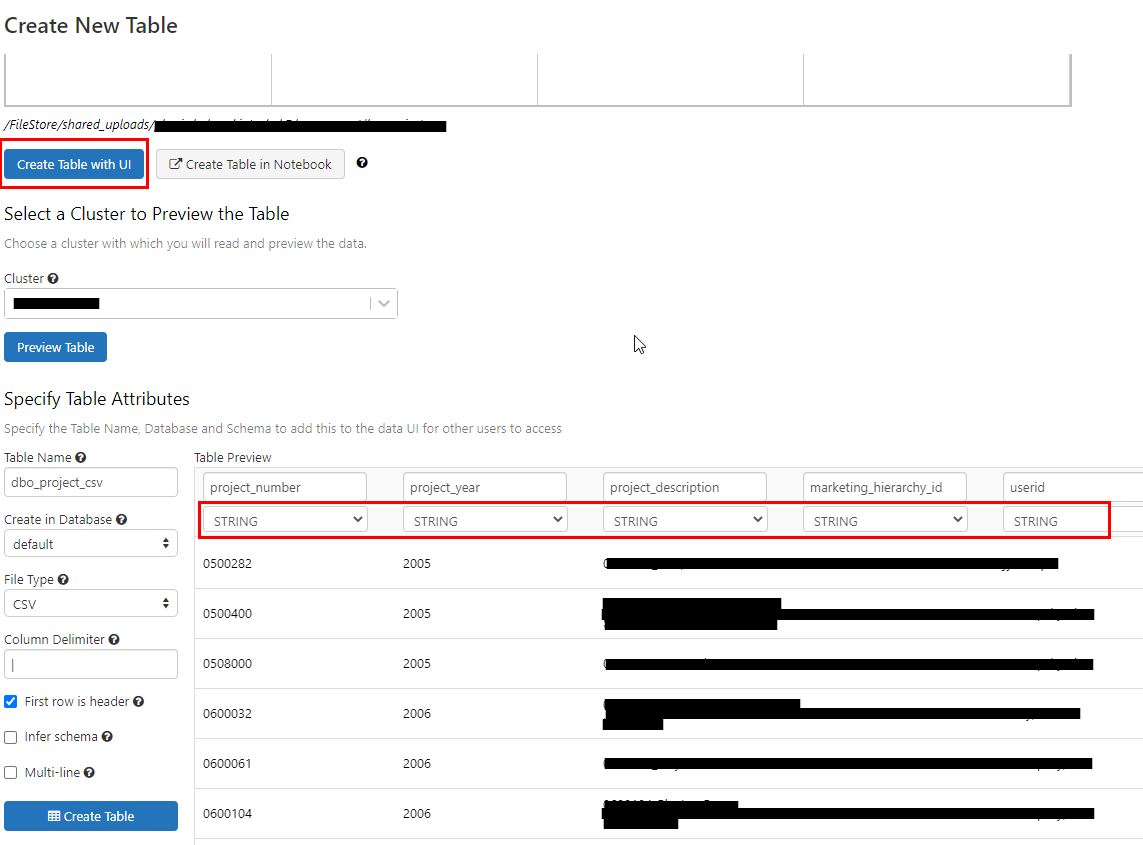
如果您在 Azure 上使用 Databricks,則當您選擇“使用 UI 創建表”時,應該有選項供您為每列選擇資料型別,如下面的螢屏截圖 A 所示。
如果您通過一些 Python Spark 代碼匯入表,應該有一個選項infer_schema供您設定。如果設定為“true”,則所有僅包含數字的列都將具有適當的數字資料型別。
file_location = "/FileStore/shared_uploads/xxx/dbo_project.csv"
file_type = "csv"
infer_schema = "true"
first_row_is_header = "false"
delimiter = ","
df = spark.read.format(file_type) \
.option("inferSchema", infer_schema) \
.option("header", first_row_is_header) \
.option("sep", delimiter) \
.load(file_location)
截圖一
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/464548.html