隨著短視頻的大火,不僅可以給人們帶來娛樂,還有熱點新聞時事以及各種知識,刷短視頻也逐漸成為了日常生活的一部分,本
文以一個簡單的小例子,簡述如何通過Pyhton依托Selenium來爬取短視頻,僅供學習分享使用,如有不足之處,還請指正,

涉及知識點
關于爬蟲涉及知識點,如下所示:
?selenium,作為瀏覽器端一個自動化測驗工具,可以模擬用戶操作瀏覽器的動作,就像是人自己操作瀏覽器一樣,關于selenium的具體資訊如下
?Selenium進行元素定位,主要有ID,Name,ClassName,Css Selector,Partial LinkText,LinkText,XPath,TagName等8種方式,
?Selenium獲取單一元素(如:find_element)和獲取元素陣列(如:find_elements)兩種方式,
?Selenium元素定位后,可以給元素進行賦值和取值,或者進行相應的事件操作(如:click),
?requests,web請求物件,通過selenium獲取到視頻的url后,再通過requests庫進行視頻流的獲取,然后保存成本地視頻檔案,
?瀏覽器開發者工具,通過開發者工具可以查看頁面上某一個按鈕或鏈接等頁面元素對應的html標識,

目標分析
在爬取視頻之前,需要分析目標結構,本視頻爬取分析可分為三步,具體如下所示:
1. 分析熱榜目錄
熱榜目錄是一個ul標簽,每一個熱榜物件一個li子標簽,分別包含熱度,標題等內容,點擊標題鏈接可以進入具體視頻播放頁面,
目標分析如下所示:
2.分析視頻播放頁面
視頻在video標簽中播放,短視頻播放的真實地址,在video的source子標簽中,且為了保證播放質量,video下有三個source,任
取其一即可,如下所示:
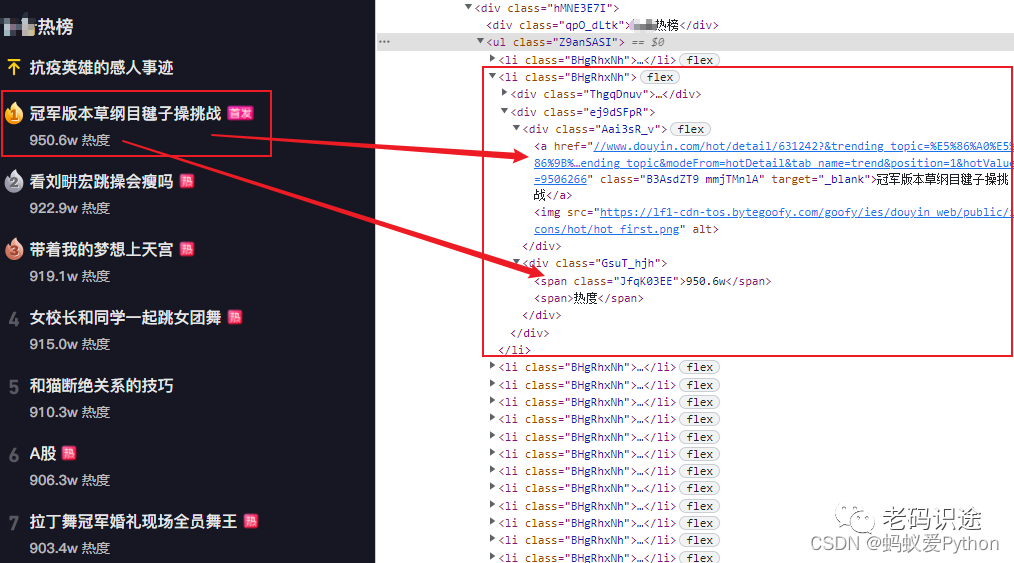

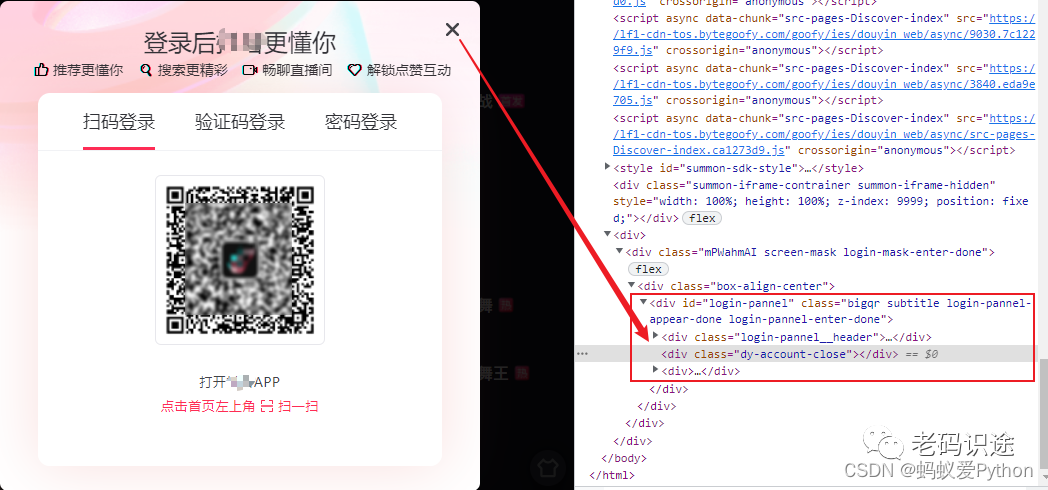
3. 分析彈出框
在爬取程序中,經過彈出需要登錄的視窗,需要及時關閉掉,否則可能會導致找不到頁面元素,從而爬取不成功,如下所示:
核心代碼
經過以上分析,就可以撰寫爬蟲代碼了,如下所示:
1. 遍歷熱點目錄
通過獲取頁面上對應的資訊,決議出熱點視頻的目錄,如下所示:
Python學習交流Q群;906715085### self.__driver.get(self.__url) self.close_popup_window() #4. 最大化視窗 self.__driver.maximize_window() time.sleep(self.__wait_sec) #打開以后,根據class=BHgRhxNh獲取ul下的li if self.checkIsExistsByClass(cls='BHgRhxNh'): #獲取 hots = self.__driver.find_elements(by=By.CLASS_NAME, value=https://www.cnblogs.com/123456feng/archive/2022/04/26/'BHgRhxNh') hot_infos = [] index = 0 for hot in hots: hot_info = {} a = hot.find_element(by=By.TAG_NAME, value=https://www.cnblogs.com/123456feng/archive/2022/04/26/'a') href = a.get_attribute("href") text = a.text hot_info['url'] = href hot_info['text'] = text if index > 0: div = hot.find_element(by=By.CLASS_NAME, value=https://www.cnblogs.com/123456feng/archive/2022/04/26/'GsuT_hjh') if div is not None: hot_value = div.find_element(by=By.TAG_NAME, value=https://www.cnblogs.com/123456feng/archive/2022/04/26/'span').text hot_info['value'] = hot_value hot_infos.append(hot_info) index = index + 1 print(hot_infos)
2. 獲取真實短視頻url
打開單個熱點視頻的url,并決議真實短視頻播放url,如下所示:
python 學習交流Q群:906715085### def open_video_html(self, url): """打開具體視頻的頁面""" self.__driver.get(url=url) time.sleep(1) self.close_popup_window() # 關閉彈窗 video = self.__driver.find_element(by=By.TAG_NAME, value=https://www.cnblogs.com/123456feng/archive/2022/04/26/'video') source = video.find_element(by=By.TAG_NAME, value=https://www.cnblogs.com/123456feng/archive/2022/04/26/'source') src = source.get_attribute('src') return src

3. 下載視頻
獲取真實的url后,即可進行下載,如下所示:
def download_video(self, url, video_name): """根據視頻源地址進行下載""" if os.path.exists(video_name): # 如果已重新下載過,則不需要再次下載 return else: with open(video_name, 'wb') as fp: fp.write(requests.get(url).content)

4. 關閉彈出的登錄視窗
在爬取程序中,經常彈出需要登錄的遮罩視窗,需要進行關閉,如下所示:
Python學習交流Q群:906715085#### def close_popup_window(self): try: login = self.__driver.find_element(by=By.ID, value=https://www.cnblogs.com/123456feng/archive/2022/04/26/'login-pannel') if login is not None: login.find_element(by=By.CLASS_NAME, value=https://www.cnblogs.com/123456feng/archive/2022/04/26/'dy-account-close').click() except BaseException as e: pass try: login = self.__driver.find_element(by=By.CLASS_NAME, value=https://www.cnblogs.com/123456feng/archive/2022/04/26/'GaDkStRD') if login is not None: btns = login.find_elements(by=By.TAG_NAME, value=https://www.cnblogs.com/123456feng/archive/2022/04/26/'button') for btn in btns: if btn.text == '取消': btn.click() break except BaseException as e: pass
5. 保存日志
在爬取成功后,對爬取的短視頻的相關內容進行保存,如下所示:
def save_data(self, hot_infos): """ 保存資料 :param res_list: 保存的內容檔案 :return: """ t = time.strftime("%Y-%m-%d", time.localtime()) with open(f'logs[{t}].json', 'a', encoding='utf-8') as f: res_list_json = json.dumps(hot_infos, ensure_ascii=False) f.write(res_list_json)
示例截圖
程式開發完成后,運行示例如下所示:
爬取的視頻保存在download目錄下,如下所示:
總結
為什么會采用selenium進行本次短視頻的爬取,而不直接采用requests庫,原因如下:
1.在對目標網站進行分析的程序中,發現目標網站采用異步呼叫的方式資料獲取,即網址請求獲取的只是空殼,并沒有真實的資料,
2.在對異步介面呼叫的url進行分析時發現,很多介面的url都具有時效性及有效性驗證,如token,時間戳等,構造起來相當麻煩,
由于以上兩點原因,結合selenium的特點及優勢,所以最終采用selenium進行此次爬蟲的最佳選擇,

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/465012.html
標籤:其他
下一篇:C++基礎-類與物件(3)