餅圖常用于統計學模塊,畫餅圖用到的方法為:pie( )
一、pie()函式用來繪制餅圖
pie(x, explode=None, labels=None, colors=None, autopct=None, pctdistance=0.6, shadow=False, labeldistance=1.1, startangle=0, radius=1, counterclock=True, wedgeprops=None, textprops=None, center=0, 0, frame=False, rotatelabels=False, *, normalize=None, data=https://www.cnblogs.com/codingchen/p/None)
pie()函式引數較多,需要我們調整的常見為以下幾個
x: 每個扇形的占比的序列或陣列
explode :如果不是None,則是一個len(x)長度的陣列,指定每一塊的突出程度;突出顯示,設定每一塊分割出來的間隙大小
labels:為每個扇形提供標簽的字串序列
colors:為每個扇形提供顏色的字串序列
autopct :如果是一個格式字串,標簽將是fmt % pct,如果是一個函式,它將被呼叫,
shadow:陰影
startangle:從x軸逆時針旋轉,餅的旋轉角度 引數用法,可以去官網查詢,并自己多去償試,
二、一個簡單的例子:統計每天休息、作業、娛樂等時間的百分比
import matplotlib.pyplot as plt slices = [7,2,9,3,3] activities = ['sleeping','eating','working','studing','playing'] cols = ['r','m','y','c','b'] plt.pie(slices, labels=activities, colors=cols, #自定義的顏色序列,對比slices,可多可少,少時自動補充,如沒有,則默認不同顏色, startangle=90, shadow= True, explode=(0,0.1,0,0,0.2),#占比突出程度, autopct='%1.1f%%' #百分比的顯示格式 ) plt.title('Time statistics') plt.show()
實際運行結果:
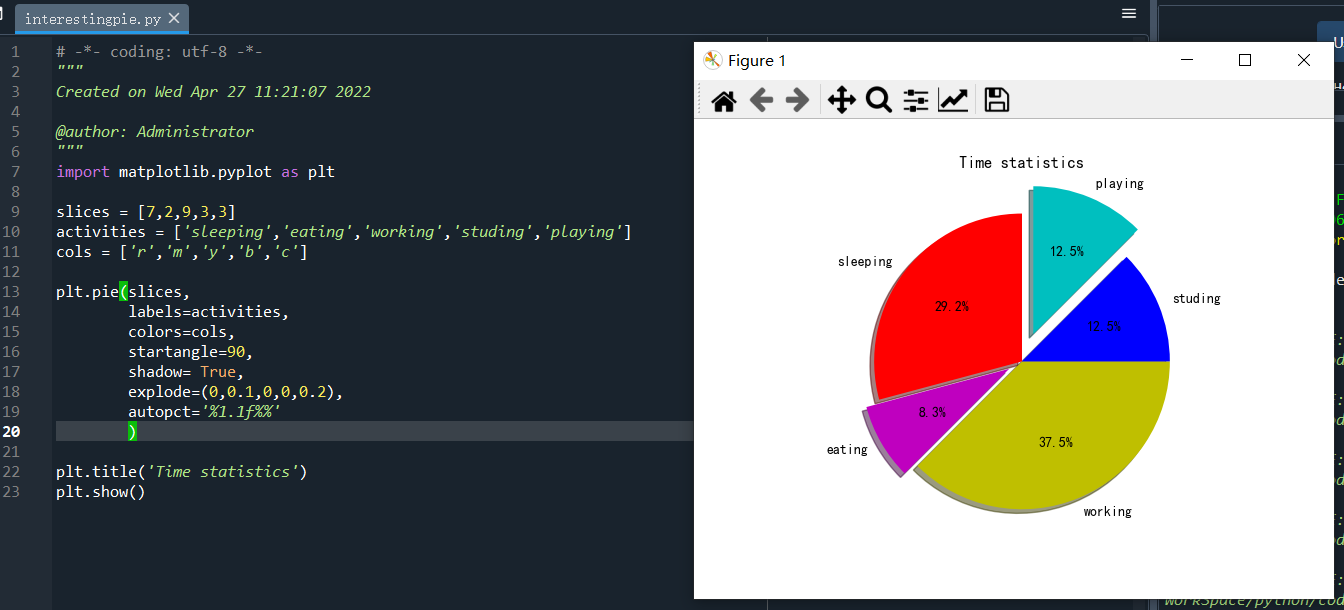
注意:startangle=90時的開始位置,整個餅圖是從0度(圓心向右方向)逆時針分布的,
那繼續用上篇創建的2個色子,來實作一個餅圖,
思考:上述餅圖代碼中最能決定餅圖形狀的引數是slices = [7,2,9,3,3],在不考慮每個占比名稱、美觀等的情況下,先確定如何實作slices中的各數值,
比如,當投擲2粒色子(一個8個面,一個6個面)時,1000000次時,分別統計出現點1、2、3、4、5……14的總次數,保存到slices中即可,用數列中的統計方法 list.count()即可,
主要就是增加兩行代碼:
new_slices=[] # 新建一個數列 while side <= max_result: side += 1 new_bins.append(side) #這是之前做柱狀圖需要用到的 new_slices.append( results.count(int(side)) ) #將保存兩色子之和的數列,直接進行統計,results.count(int(side))就是在results的數列中統計出現side的次數,
運行結果,一樣也是顯示出點數之和7,8,9的出現的次數最多,然后逐漸減小:
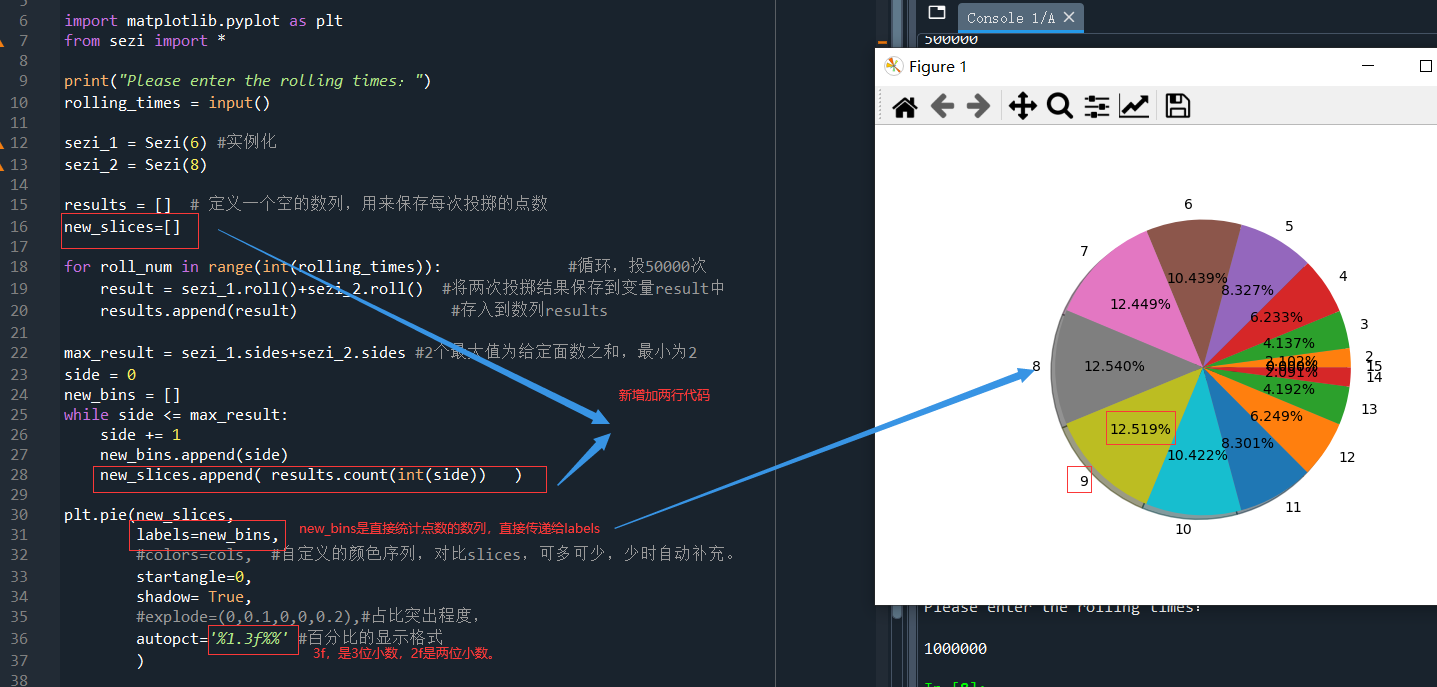
總之,餅圖通過將一個圓按照分類的占比劃分成多個區塊,整個圓餅代表資料的總量,每個區塊表示該分類占總體的比例大小,所有區塊的加和等于100%,
三、 堆疊圖
使用matplotlib中的stackplot()函式可以快速繪制堆積圖,stackplot()函式的語法格式如下所示
stackplot(x, y, labels=(), baseling='zero', data=https://www.cnblogs.com/codingchen/p/None, *args, **kwargs)
該函式常用引數的含義如下
x:表示x軸的資料,可以是一維陣列,
y:表示y軸的資料,可以是二維陣列或一維陣列序列,
labels:表示每組折線及填充區域的標簽,
baseline:表示計算基線的方法,包括'zero'、'sym'、'wiggle'和'weighted_wiggle',
其中,'zero'表示恒定零基線,即簡單的堆積圖;
'sym'表示對稱于零基線;
'wiggle'表示最小化平方斜率的總和;
'weighted_wiggle'表示執行相同的操作,但權重用于說明每層的大小,
用同一個例子來看一下堆疊圖的效果,代碼如下:
import matplotlib.pyplot as plt days = [1,2,3,4,5,6,7] sleeping =[7,8,6,8,7,8,6] eating = [2,3,3,3,2,2,2] working = [7,7,7,8,10,3,4] studing = [6,4,4,4,3,8,11] playing = [2,2,4,1,2,3,1] labellist = ['sleeping','eating','working','studing','playing'] colorlist = ['c','y','b','r','g'] plt.stackplot(days, sleeping,eating,working,studing,playing,labels=labellist,colors=colorlist) plt.xlabel('x') plt.ylabel('y') plt.legend(loc=(0.07, 0.05)) plt.title('Stack Plots') plt.show()
運行結果如下:
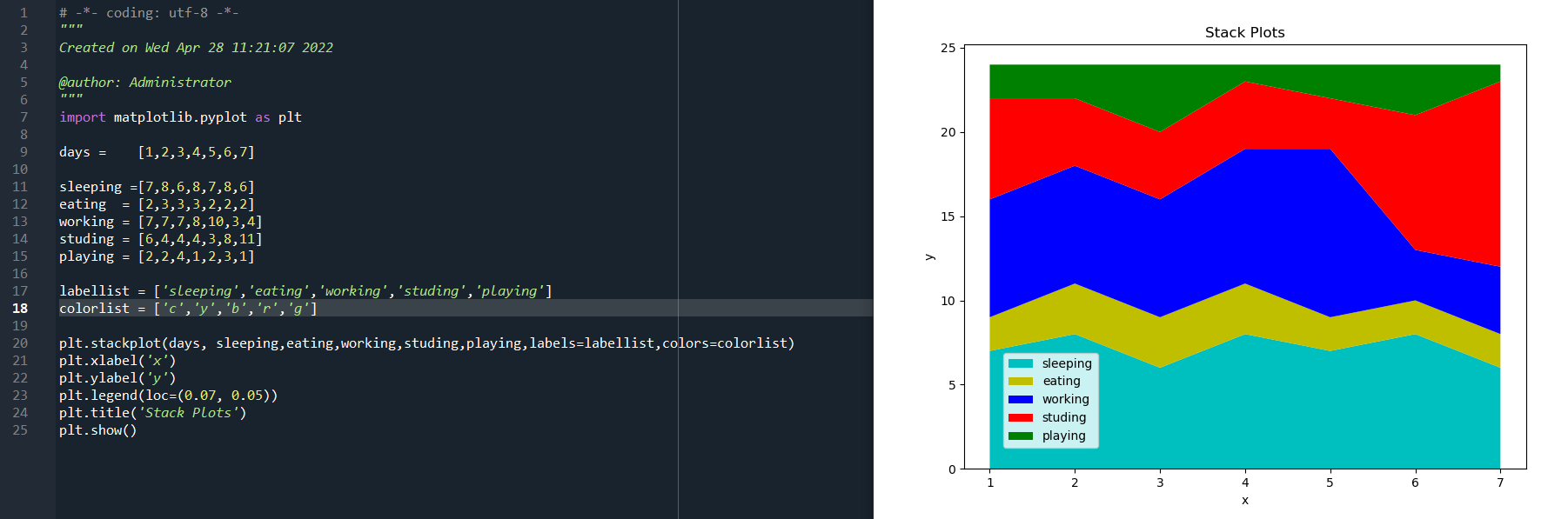
plt.legend()是顯示左下角的標簽,而陳述句plt.stackplot()函式中的sleeping,eating,working,studing,playing是一維陣列序列,即stackplot(x,y……)中的y值,是一系列一維資料,
很明顯,通過上述餅圖與堆疊圖的對比,它們的區別:餅圖只能展示一段時間里,某個專案所花時間占總時間的比,而堆疊圖可以展示這一段時間里,每天各項所花費時間,
既然sleeping,eating,working,studing,playing形成的一維陣列,感覺引數比較多,那直接形成一個二維陣列如何?做如下修改:
days = [1,2,3,4,5,6,7] """ sleeping =[7,8,6,8,7,8,6] eating = [2,3,3,3,2,2,2] working = [7,7,7,8,10,3,4] studing = [6,4,4,4,3,8,11] playing = [2,2,4,1,2,3,1] """ times =[ # 二維陣列,以數列作為元素的數列, [7,8,6,8,7,8,6], #上述sleeping數列 [2,3,3,3,2,2,2], [7,7,7,8,10,3,4], [6,4,4,4,3,8,11], [2,2,4,1,2,3,1] ]
plt.stackplot(days, times,labels=labellist,colors=colorlist)
運行結果如圖:
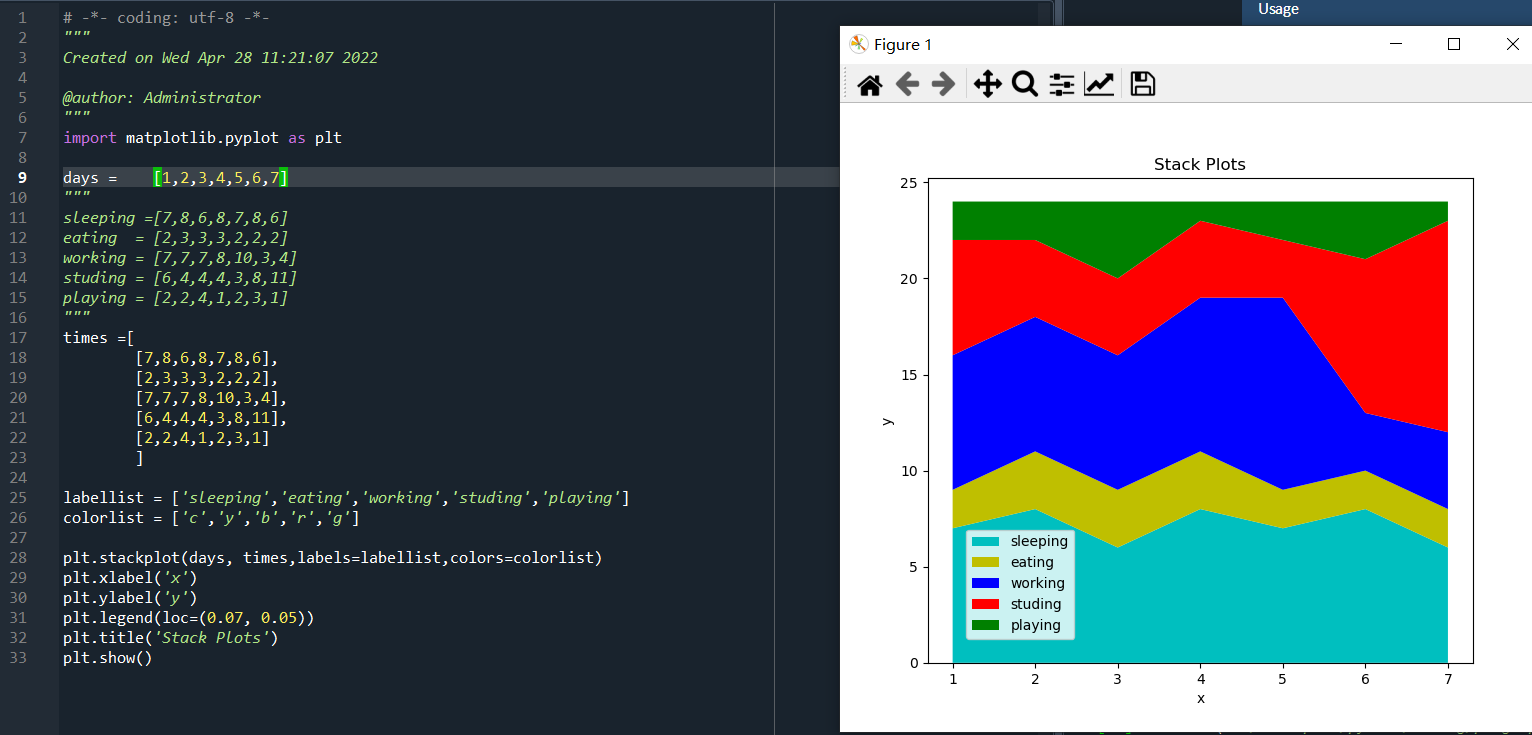
效果與原來的一維陣列一樣,
但手工這樣編程的時候錄入資料太過麻煩,下篇介紹直接讀取檔案資料并進行處理,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/466960.html
標籤:Python