除了從檔案加載資料,另一個資料源是互聯網,互聯網每天產生各種不同的資料,可以用各種各樣的方式從互聯網加載資料,
一、了解 Web API
Web 應用編程介面(API)自動請求網站的特定資訊,再對這些資訊進行可視化,每次運行,都會獲取最新的資料來生成可視化,因此即便網路上的資料瞬息萬變,它呈現的資訊也都是最新的,
Web API是網站的一部分,用于與使用非常具體的URL請求特定資訊的程式互動,這種請求稱為API呼叫,請求的資料將以易于處理的格式(如JSON或CSV)回傳,
GitHub(https://github.com/)上的專案都存盤在倉庫中,后者包含與專案相關聯的一切:代碼、專案參與者的資訊、問題或bug報告等,撰寫一個自動下載GitHub上的Python專案的相關資訊,
在瀏覽器中打開: https://api.github.com/search/repositories?q=language:python&sort=stars,可以看到如下內容,
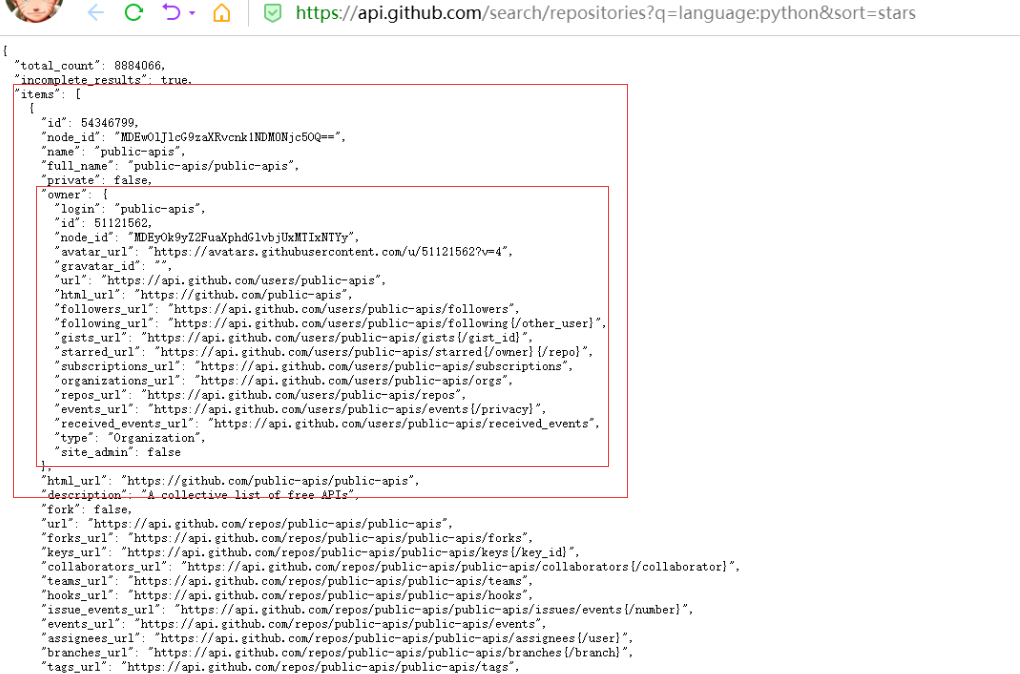
此呼叫回傳GitHub當前托管了total_count 8884066個Python專案,還有最受歡迎的Python倉庫的資訊,
其中第一部分( https://api.github.com/ )將請求發送到GitHub網站中回應API呼叫的部分;
第二部分( search/repositories )讓API搜索GitHub上的所有倉庫,
repositories 后面的問號指出我們要傳遞一個實參, q 表示查詢,而等號讓我們能夠開始指定
查詢( q= ),通過使用 language:python ,我們指出只想獲取主要語言為Python的倉庫的資訊,
最后一部分( &sort=stars )指定將專案按其獲得的星級進行排序,
但我們不能每次通過打開網頁的形式來獲取資料,但可以通過python中相關庫
二、安裝 requests
requests是一個很實用的Python HTTP客戶端庫,專門用于發送HTTP請求,方便編程,撰寫爬蟲和測驗服務器回應資料時經常會用到,
Requests主要相關引數有:
r.status_code 回應狀態碼
r.heards 回應頭
r.cookies 回應cookies
r.text 回應文本
r. encoding 當前編碼
r. content 以位元組形式(二進制)回傳
鑒于一直都使用的是anaconda3,可直接打開 anaconda prompt,然后輸入命令:pip install --user requests 安裝即可,
下面來撰寫一個程式,執行API呼叫并處理結果,找出GitHub上星級最高的Python專案,代碼如下:
import requests # 匯入模塊requests url='https://api.github.com/search/repositories?q=language:python&sort=stars'#存盤API呼叫的URL r = requests.get(url) # 呼叫get()并將URL傳遞給它,回應物件存盤在變數 r中 print("Status code:",r.status_code) #包含一個名為status_code的屬性 response_dict = r.json() # 使用方法json()將這些資訊轉換為一個Python字典 print(response_dict.keys()) #列印出字典的key
上述代碼有兩行列印,運行結果如下:
Status code: 200 dict_keys(['total_count', 'incomplete_results', 'items'])
狀態碼為200,請求成功,回應字典包含三個鍵: 'total_count'和 'incomplete_results'和 'items'
將API呼叫回傳的資訊存盤到字典中,就可以利用前面了解的字典的鍵-值對來研究自己喜歡的資訊了,
三、整理字典中的資訊
上述代碼response_dict = r.json()實際上已將請求資訊轉為字典,那查看一下字典里有些什么內容,
從瀏覽器中打開的內容可以看到,回傳的內容中是字典中包含字典
(items是作為最上那個大括號中的key,對應的值,是由多個字典組成的字典串列,‘id’,‘node_id’,‘name’等也是items串列中第一子字典的key,見紅色方框部分,串列字典等相互嵌套,好好分析一下),
1)先看一下與 'total_count'關聯的值
print("Total repositories:", response_dict['total_count'])
2)items本身是一個字典,‘id’,‘node_id’,‘name’等均是key,后面對應的都是值,可以查一下有多少個key
repo_dicts = response_dict['items'] #建一個變數字典repo_dicts,將items字典串列存盤在 repo_dicts print("Repositories returned:", len(repo_dicts))# 打 repo_dicts的長度,獲得item字典的長度資訊
3)查看第一個item的詳細資訊,并列印出所有key
repo_dict = repo_dicts[0] #提取了repo_dicts中的第一個字典 print("\nKeys:", len(repo_dict)) #列印這個字典包含的鍵數 print("\n") for key in repo_dict.keys():#列印這個字典的所有鍵 print(key)
整體運行結果(下圖白色部分為瀏覽器打開):
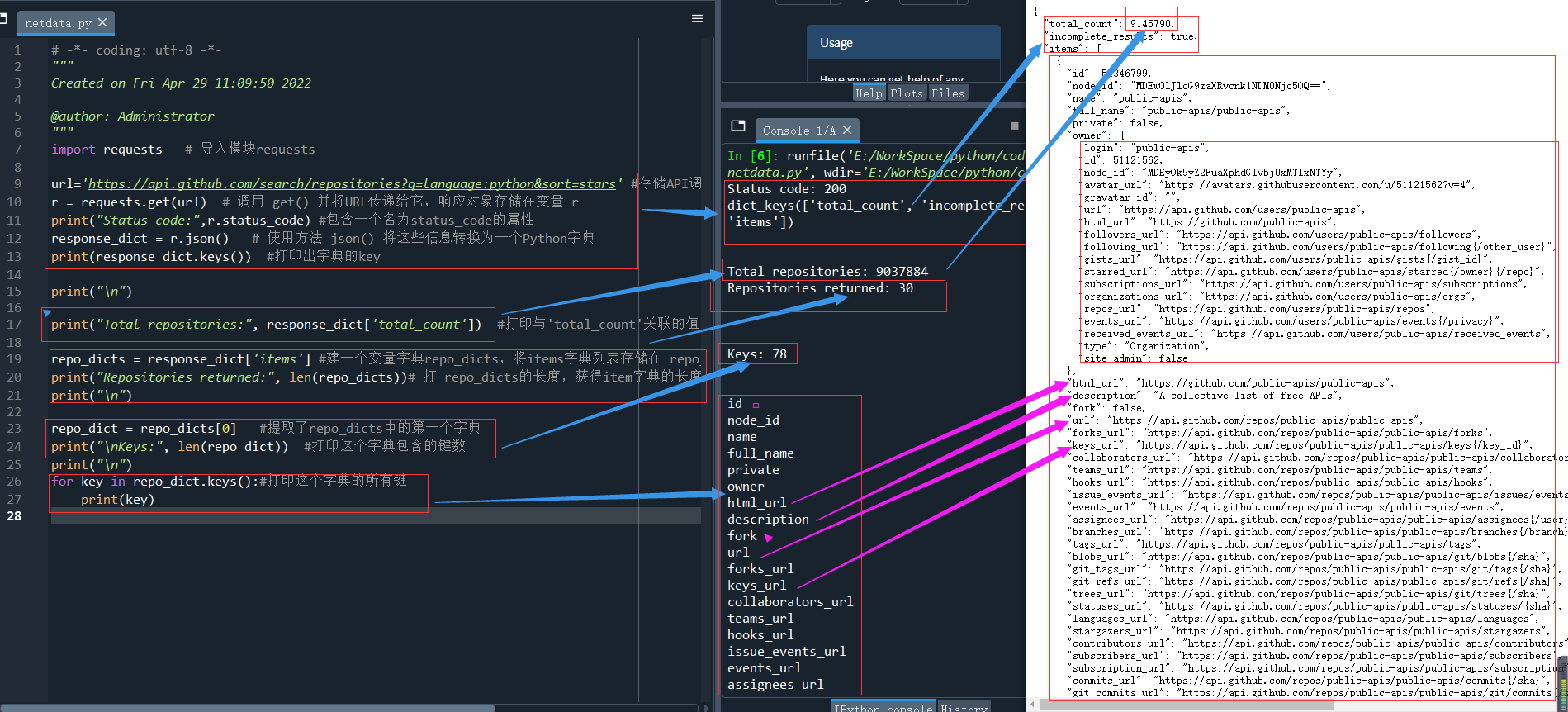
思考一下,為什么圖中的Total repositories一個是9037884,另一個為9145790,兩者不一致?
有了key,就很容易查詢到相關的值了(當然這里都是字串,如果是數字型的就能可視化)
四,數字可視化
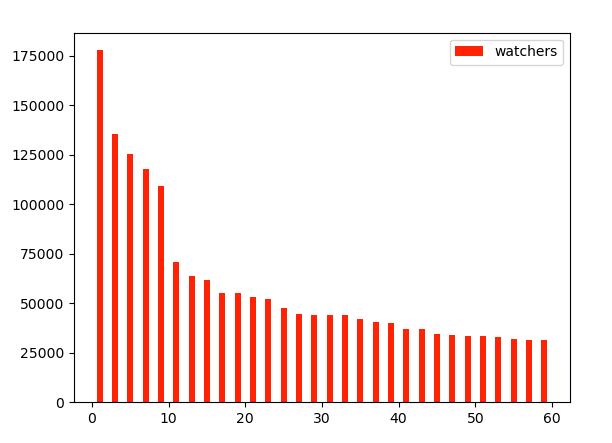
通過瀏覽器打開頁面,會發現"forks": 32471, "open_issues": 305, "watchers": 177777等有相關資料,于是,可以通過對應的key,將相關資料整合成一個資料串列,然后顯示出來,比如可視化wathers
count=0 watchers, counts= [], [] for repo_dict in repo_dicts: watchers.append(repo_dict['watchers']) count += 1 counts.append(count) plt.bar(counts,watchers, label="watchers", color='#ff2204') plt.legend() plt.show()
運行結果:
五、資料可視化的小總結:
matplotlib中資料可視化的方法主要就是呼叫pyplot介面,再直接呼叫物件的建立方法,在方法中對該物件進行相應的屬性設定,所以掌握這種方法的核心就在于掌握每種物件的建立方法和具體引數設定,Python資料可視化的難處在于掌握引數的設定,內置的引數雖然很多,但一般都用不上(可以留著慢慢鉆研),將用得上的引數和引數值幾何整理下來,做到這樣,對于Python的可視化學習暫時足矣,剩下的時間該去學習其他更為有用的!
簡而化之,
曲線圖 plt.plot(squares, linewidth=5) 只需要提供一組資料即可
散點圖 plt.scatter(x, y,c='r',edgecolor='none',s=100) ,x,y分別為x軸,y軸坐標位置,x,y對應
柱圖 plt.bar(x,y, label="Test one", color='r') x為x軸位置,y為值,x如為數列,則y對應相同長度
柱圖 plt.hist(list, bins, histtype='bar', rwidth=0.8,color='r') bins為柱圖劃分范圍,表現在x軸上,list為數列,顯示在y 軸
餅圖 plt.pie(slices) slices 為一數列
堆疊圖 plt.stackplot(days, times,labels=labellist,colors=colorlist) days為一維數列,times為一維或多維數列,每一維數列元素個數與days一樣,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/468727.html
標籤:Python
上一篇:maven生命周期詳解說明