一、引言
最近在進行大創專案的結題作業,一開始的資料處理程序,是用C#處理的,想著最近在學python,就試了試用python做了下,下面來分享下我的處理流程,目前還處于初學階段,有不足之處歡迎指點,
二、資料介紹
先看一下要處理的資料,
 .
.
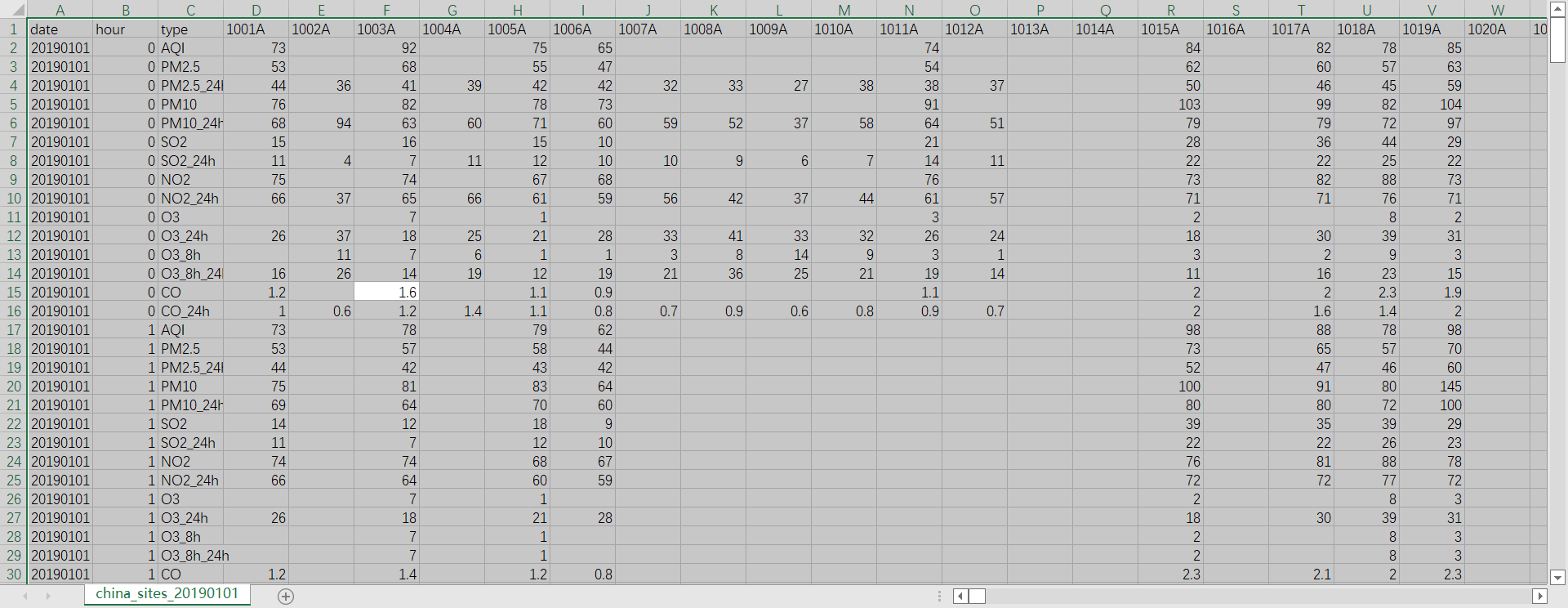
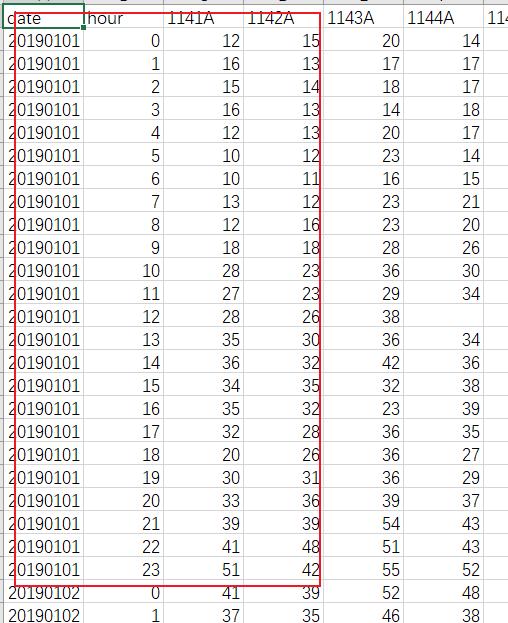
下面是具體20190101的站點資料,只列出了其中一部分,
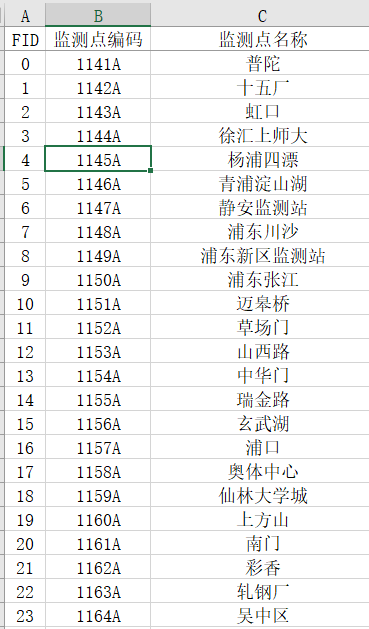
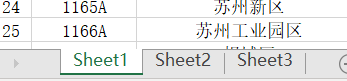
兩個檔案夾分別 為19年和20年的全國氣象站點資料,目標是要從這里面篩選出江蘇省內的以及周邊區域鄰近的站點的PM2.5資料,并計算其月均值資料,我將要篩選的站點資料存盤在了一個excel表格里,樣式如下:(資料只截取了一小部分)
三、資料處理
既然要篩選資料,那第一步就是將需要的站點編碼讀取出來,簡單介紹下我的資料處理流程,讀取目標站點,篩選天小時資料,計算日均值,計算月均值,
1.讀取站點編碼
站點存盤在excel檔案里,因此要使用python來操作excel檔案,這里我參考了openpyxl,下面是處理的代碼(跳轉至完整代碼)
第一步匯入openpyxl,
import openpyxl as xl
使用openpyxl庫的load_workbook()來獲得存盤站點的excel檔案
wb = xl.load_workbook(filename)
因為資料都是存盤在作業簿的表里的,因此我們要獲得作業簿里的表,也就是Sheet1,
sheet = wb['Sheet1']
在開始讀資料前,先定義一個用于存盤站點資料的串列,這里我定義的初始串列里有兩個值,'date','hour',這兩個值用來標識所讀取的PM2.5的資料的生產時間,
station_id = ['date', 'hour']
下面是開始讀資料,遍歷sheet1的每一行,將資料存盤在station_id里,
for row in range(2, sheet.max_row+1): cell = sheet.cell(row, 2) station_id.append(cell.value)
因為我這里存放目標站點編號的表格里存在多個空行,因此會station_id的后面會存放很多None(excel里的單元格為空的話就是None)

于是需要把station_id里的多余的None去除
if(None in station_id): index = station_id.index(None) del station_id[index:]
將上面的代碼封裝在一個函式里,完整代碼如下:
import openpyxl as xl ''' 獲得站點坐標,此處是以站點存盤在excel里為例,并且是存放在一列,且是在第2列 ''' def get_station_id(filename): # 獲得路徑對應的作業簿 wb = xl.load_workbook(filename) # 獲得作業簿里的表 sheet = wb['Sheet1'] # 定義一個存盤站點的資料串列 station_id = ['date', 'hour'] # 遍歷表,將站點資訊存盤在list里 for row in range(2, sheet.max_row+1): cell = sheet.cell(row, 2) station_id.append(cell.value) # 洗掉id_list中的空資料,因為有可能最大行數會超過excel的實際資料行數 if(None in station_id): index = station_id.index(None) del station_id[index:] return station_id
以上代碼我單獨放在了get_station_id.py檔案里
2.篩選目標站點的資料
簡單說下處理流程,先是獲得存放上面兩個csv檔案夾的檔案夾,也叫父級路徑,再獲得檔案夾下的所有csv檔案(這一步要盡量保證沒有其他csv檔案),最后是遍歷讀取需要的資料并寫入一個csv,存放著天小時的目標站點的PM2.5資料,(跳轉至完整代碼)
第一步,通過pathlib的Path來獲得父級路徑,匯入pathlib 下的Path類,以及接下來要進行處理csv檔案所需的csv庫
from pathlib import Path import csv
獲得存放csv檔案夾的路徑,并定義一個要存放資料的csv檔案路徑,
csv_dir = Path(r'F:\College\FileRecv\大創專案\站點資料201901-202012') target = r'F:\College\FileRecv\大創專案\19-20-hours.csv'
獲得路徑下的所有csv檔案
csv_list = list(csv_dir.rglob('*.csv'))
定義一個寫入流,做好寫入資料的準備,這里用dictwriter的寫入方法,是因為在要處理的資料檔案中,有的站點在某一年或某幾個月中并不存在,這樣處理更為準確方便,
with open(target, 'w', newline='') as out_file:
writer = csv.DictWriter(out_file, fieldnames=station_id)
接下來是寫入列頭,將station_id寫入要存放資料的csv(target)的第一行:
writer.writeheader()
遍歷讀取站點csv檔案,篩選資料寫入target,
for filename in csv_list: with open(filename, 'r') as file: # 將行資料映射到字典 reader = csv.DictReader(file) for row in reader: # 判斷當前資料是否是PM2.5 if row['type'] == datatype: # 查找對應station_id的資料,并存盤在一個list里 # data = https://www.cnblogs.com/madaao/p/{} # for id in station_id: # if id in row: # data[id] = row[id] data = https://www.cnblogs.com/madaao/p/{id: row[id] for id in station_id if id in row} writer.writerow(data)
這一步資料處理成功,我將其封裝在一個方法里,完整代碼如下:
from pathlib import Path import csv import get_station_id
# """ 獲得指定站點編號的資料,并寫入一個csv檔案 輸入的引數分別是 csv_dir----csv檔案所在的目錄的路徑, 以及要寫到目標檔案的路徑 target station_id 站點編號 """ def get_write_from_csv(csv_dir, target, station_id=['date', 'hour', '1141A'], datatype='PM2.5'): # 判斷路徑是否正確 if not csv_dir.is_dir(): return # 獲得路徑下所有的csv檔案 csv_list = list(csv_dir.rglob('*.csv')) with open(target, 'w', newline='') as out_file: writer = csv.DictWriter(out_file, fieldnames=station_id) # 寫入頭,station_id writer.writeheader() # 遍歷csv檔案并選擇資料寫入target for filename in csv_list: with open(filename, 'r') as file: # 將行資料映射到字典 reader = csv.DictReader(file) for row in reader: # 判斷當前資料是否是PM2.5 if row['type'] == datatype: # 查找對應station_id的資料,并存盤在一個list里 # data = https://www.cnblogs.com/madaao/p/{} # for id in station_id: # if id in row: # data[id] = row[id] data = https://www.cnblogs.com/madaao/p/{id: row[id] for id in station_id if id in row} writer.writerow(data) print('successed') csv_dir = Path(r'F:\College\FileRecv\大創專案\站點資料201901-202012') target = r'F:\College\FileRecv\大創專案\19-20-hours.csv' # 存放著stationID的excel檔案 filename = r'F:\College\FileRecv\大創專案\1920.xlsx' # 獲得stationid station_id = get_station_id.get_station_id(filename) get_write_from_csv(csv_dir, target, station_id)
3.對已篩選的資料進行計算日均值
觀察一下資料構成,發現可以通過date這一列進行分組來進行計算日均值,(跳轉至完整代碼)
談到分組就想到了pandas的groupby函式,要得到日均值只要按date這列分組就行了,首先匯入需要的庫,
import pandas as pd import numpy as np
讀取已篩選好的csv資料
df=pd.read_csv(r'F:\College\FileRecv\大創專案\target.csv')
將讀取到的資料按date分組
day_group=df.groupby('date')
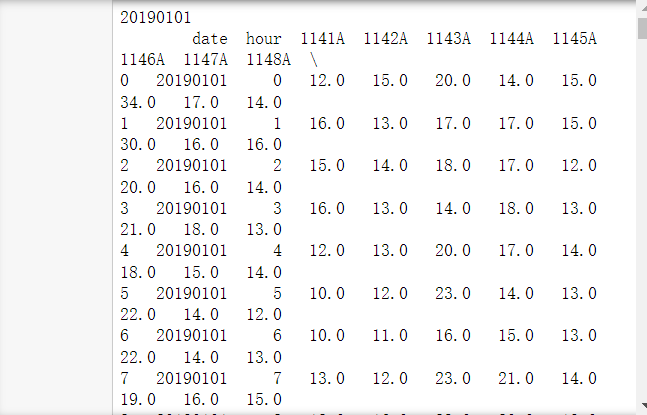
可以用下面的代碼查看一下分組的結果,
for date,group in day_group: print(date) print(group)
接下來是對分組進行聚合求平均,并查看下聚合的結果
data=https://www.cnblogs.com/madaao/p/day_group.agg(np.mean) print(data)
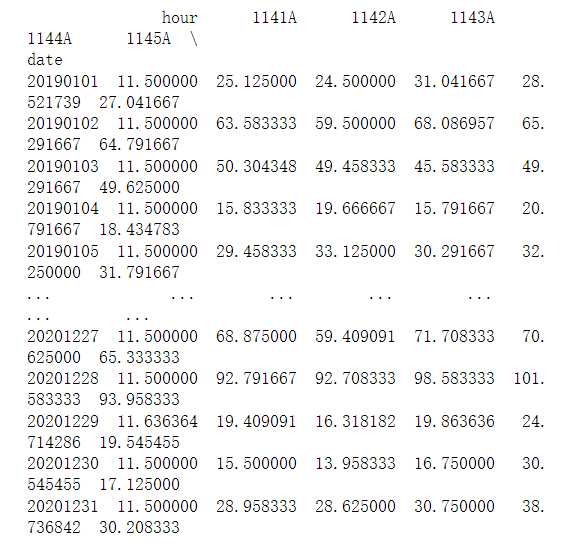
發現hour這列也被求平均了,這一列在接下來的處理中是不需要的,因此將它刪去,
day_data=https://www.cnblogs.com/madaao/p/data.drop('hour',axis='columns')
將刪去后的資料寫入daydata.csv(存盤日均值資料)
day_data.to_csv('daydata.csv')
完整代碼如下:
import pandas as pd import numpy as np df=pd.read_csv(r'F:\College\FileRecv\大創專案\target.csv') day_group=df.groupby('date') data=day_group.agg(np.mean) day_data=data.drop('hour',axis='columns') day_data.to_csv('daydata.csv')
4.計算月均值
對處理好的日均值資料來求月均值,首先是要將資料按月來歸類,簡單講下我的思路,首先將資料按年分開分為19年和20年的資料,再對19和20年的資料按月分類聚合求均值,(跳轉至完整代碼)
第一步,按年分割資料,
df=pd.read_csv('daydata.csv') # 年份區開資料 data2019=df[df['date']<=20191231] data2020=df[df['date']>=20200101]
第二步,對各年的按月分類聚合求均值,考慮到date這列的資料型別是數字,可以通過按條件篩選屬于某一月的資料,
def get_month_data(data,month_start,month_end): month=data[(data['date']<month_end)&(data['date']>=month_start)] # 這里聚合操作也將日期進行聚合了 return month.agg(np.mean)
第三步,獲得某年的月均值資料,并寫入csv檔案,考慮到0101到0201之間差了100,(實際上兩個月之間最多只差31天)設定了步長為100的形式來獲得月均值,
def write_month_data(year_data,outfilename,month_start=20190101,step=100): month_list=[] # 獲得每月均值資料,并添加到list里 for num in range(12): month_data=get_month_data(year_data,month_start,month_start+step) month_list.append(month_data) month_start+=step # 將list生成dataframe df=pd.DataFrame(month_list) # 修改日期格式為201901這種年加月形式 df['date']=df['date'].apply(lambda x: int(x/100)) df.to_csv(outfilename)
下面是完整的代碼
import pandas as pd import numpy as np df=pd.read_csv('daydata.csv') # 年份區開資料 data2019=df[df['date']<=20191231] data2020=df[df['date']>=20200101] # data2020.agg(np.mean) def get_month_data(data,month_start,month_end): month=data[(data['date']<month_end)&(data['date']>=month_start)] # 這里聚合操作也將日期進行聚合了 return month.agg(np.mean) def write_month_data(year_data,outfilename,month_start=20190101,step=100): month_list=[] # 獲得每月均值資料,并添加到list里 for num in range(12): month_data=get_month_data(year_data,month_start,month_start+step) month_list.append(month_data) month_start+=step # 將list生成dataframe df=pd.DataFrame(month_list) # 修改日期格式為201901這種年加月形式 df['date']=df['date'].apply(lambda x: int(x/100)) df.to_csv(outfilename) month_start2019=20190101 month_start2020=20200101 step=100 #因為20190101-20190201=-100 write_month_data(data2019,'19month.csv',month_start2019,step) write_month_data(data2020,'20month.csv',month_start2020,step)
結果圖:
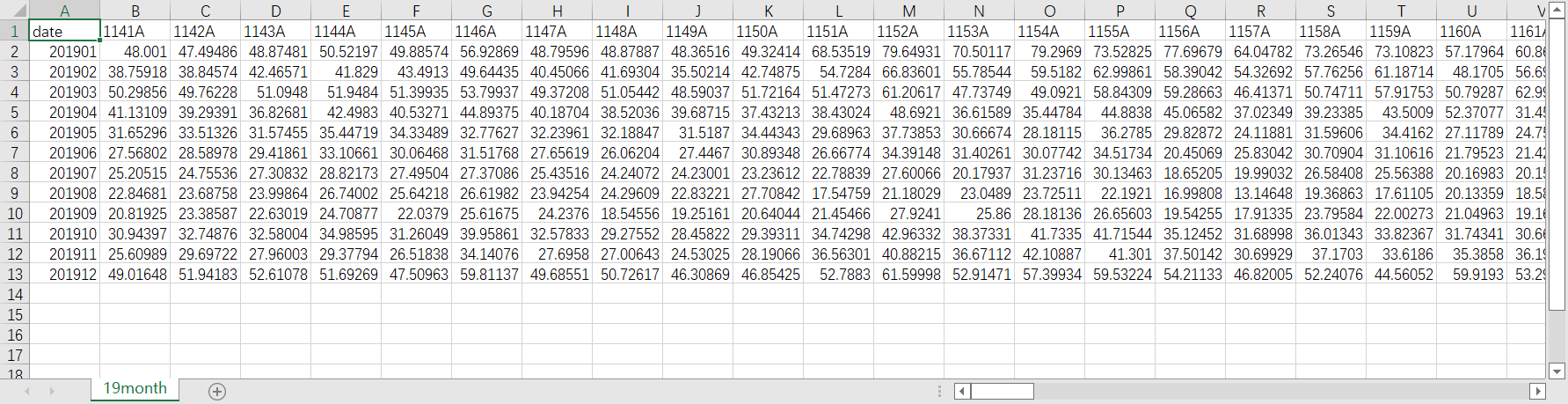
結語:以上就是我使用python處理資料的全流程了,作為一個python新手,如有錯誤還請指點,感謝大家花費寶貴的時間來閱讀,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/469582.html
標籤:Python
下一篇:Python 函式進階-遞回函式