本文原來只計劃直接翻譯OptaPlanner官網一篇關于SolverManager下實時規劃的博文《Real-time planning meets SolverManager》,但在翻譯程序中,發現該文僅從具體的技術細節上描述使用SolverManager及其相關介面實作在批量規劃程序中的實時回應,因此,只能對具體使用OptaPlanner的開發人員有一定幫助,對于相關的業務分析和決策人員關注的適用場景,該文并未作深入描述;因而,未能從業務場景到工程實踐的角度和程序,來描述批量規劃與實時規劃的實用意義,本文將在該官方博文的基礎上進一步擴展,從業務需求到技術實作的整個架構,更全面深入地闡述相關功能特性在相應應用場景下的實踐步驟,因篇幅所限,將本文拆分為兩篇發布,本文為第一篇,先講解批量和實時規劃的需求與業務場景,以及在OptaPlanner中的批量規劃的實作方法簡介;下一篇將詳細介紹新OptaPlanner8.x之后,實時規劃的實作,并同時介紹批量并行規劃情景下,如何實作實時規劃,
在日常的規劃應用中,無論是APS,VRP還是排班場景,有兩個極其常見的需求,分別是批量規劃和實時規劃,下面我們對這兩種情況作更深入探討,
批量規劃
顧名思義,該功能是指規劃程式可批量地、且行地處理同一規劃模型的多個資料集,從而提高規劃效率,包括計算資源(CPU,記憶體等)和時間(將多個需要長時間運算的資料集安排在夜間進行),此外,批量規劃必然是異步運算,基于此特性,在一些計算頻率不同的場景,可實作多個計劃單位共用一個規劃服務,例如同一集團內的多個工廠或車間,只需要部署同套規劃服務,作為這些車間的共用基礎設施,從而提升APS專案的ROI. 因為引擎是批量地異步地執行規劃運算的,因此,各個工廠只需將自己的規劃資料集提交到規劃服務中,服務程式完成規劃運算后,規劃結果回傳到對應的WebAPI,或寫入相應的資料源即可,工廠與工廠之間的規劃時間無需排隊,關于批量規劃的實作,在OptaPlanner剛推出SolverManager可實作批量規劃時,本人曾寫過一篇簡介文章:OptaPlanner 7.32.0.Final版本彩蛋 - SolverManager之批量求解
而OptaPlanner在進入8.X版本后,對SolverManager的相關介面作了一些修改,改進了一些介面,以提高合理性與易用性,
通過SolverManager實作批量、并行規劃
如下代碼中,實作了一個更為簡潔的通過SolverManager實作批量規劃的步驟,該代碼片段將一個待規劃的資料集(problem)通過一個SolverManager物件的solve方法提交后,執行緒會馬上回傳,其回傳值是一個SolverJob物件,SolverJob是一個泛型類,型別分別是Solution類和一個用于標識當前傳入Problem的參考型別值,可以使用UUID或Long來標識不同的規劃資料集,SolverJob事實上就是在SolverManager對多個資料集進行批量并行運算程序中的一個句柄,通過這個句柄就可以實作對相關的規劃物件進行訪問和控制,包括下一篇中用到的實時規劃,
package org.acme.schooltimetabling.rest; import java.util.UUID; import java.util.concurrent.ExecutionException; import javax.inject.Inject; import javax.ws.rs.POST; import javax.ws.rs.Path; import org.acme.schooltimetabling.domain.TimeTable; import org.optaplanner.core.api.solver.SolverJob; import org.optaplanner.core.api.solver.SolverManager; @Path("/timeTable") public class TimeTableResource { // 定義一個SolverManager物件 @Inject SolverManager<TimeTable, UUID> solverManager; @POST @Path("/solve") public TimeTable solve(TimeTable problem) { // 創建一個UUID值作為規劃資料集的ID,也可以替換成Long, Sting等,但所提交給SolverManger的各個problem,其ID不可重復, UUID problemId = UUID.randomUUID(); // 將待規劃資料集(problem)提交給SolverManger,并開始規劃, // 將資料集提交到SolverManager之后,是否被即時執行規劃運算,要視當前設定的并行執行緒數,及當前規劃空間中正在運行的資料集數量有關, // SolverManger的solve方法回傳一個SolverJob物件,它是一個規劃行程的句柄,通這它可以對相應的資料集進行控制,其泛型與SolverManager一致, SolverJob<TimeTable, UUID> solverJob = solverManager.solve(problemId, problem); TimeTable solution; try { // 通過solverJob獲得對應資料集的最終解, // 注意:getFinalBestSolution方法需要在對應資料集的規劃行程結束(可以是提前結束,也可以是達到Termination條件滿足而結束)后才能獲得最終解 solution = solverJob.getFinalBestSolution(); } catch (InterruptedException | ExecutionException e) { throw new IllegalStateException("Solving failed.", e); } return solution; } }
實作可批量、并行運算的規劃服務
通過SolverManager的運行機制,我們利用OptaPlanner相關的特性實作一個可批量、并行運算的規劃服務,服務對規劃請求的回應程序如下,當然就是沒有SolverManager,我們自己通過Java的并行計算功能,也可以實作批量處理,但需要我們自行處理好Java并行計算的相關問題,
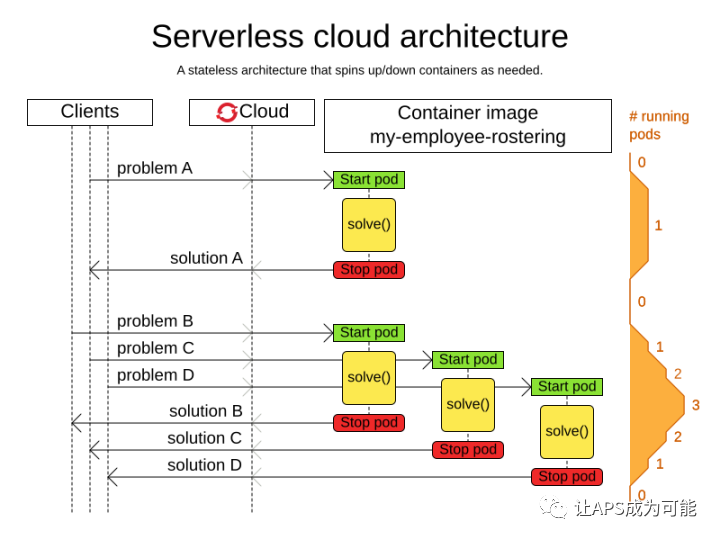
從上圖可以看到,客戶端的規劃請求發送到規劃服務后,規劃服務會為每個請求的資料集開啟一個solve執行緒,并在規劃運算完成后將結果回傳,當請求有重疊時,服務端會對這些資料集作并行運算,并在完成運算后各自回傳,
我們只需在應用OptaPlanner的服務后臺邏輯中,應用好SolverManager及其相關功能,即可實作內置的批量、并行規劃運算,而將這些功能設計成后端服務,并以Web API方式呈現作為各種場景下的基礎規劃設施,其實就是J2EE的內容的,大家可以自行參考相關的材料,
批量規劃目前的不足
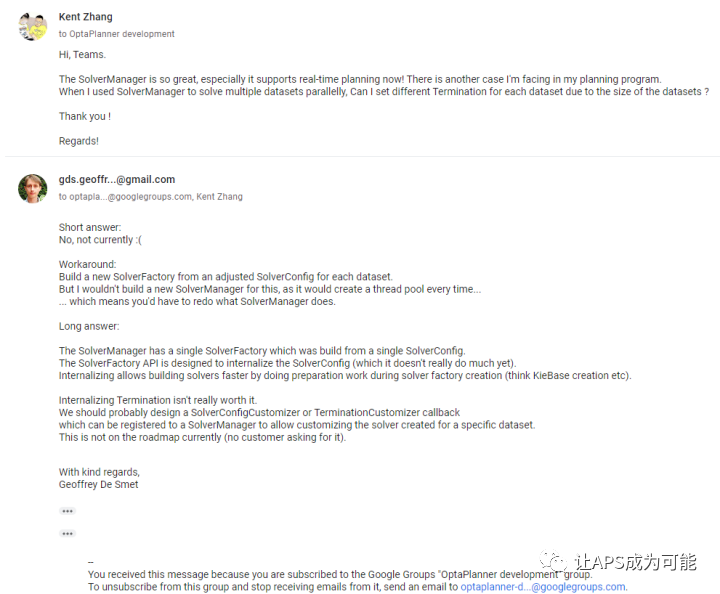
通過批量、并行規劃,可以實作同一個模型的多個資料集同時進行規劃運算,但有同學應該會想到,不同工廠有可能規劃資料集的資料量相差很大;或者不同時間(淡季旺季)因為生產任務量不同,規劃資料集的資料量也會有所差異,不同的資料量展開后的問題規模差異可能是相當驚人的,從而導致所需的規劃時間差異極大,那么,在批量規劃的程序中,能否為不同的資料集設定不同的規劃時間呢?很遺憾,OptaPlanner目前是不支持該功能的,這是一個相當實在的問題,希望OptaPlanner以后的版本可以支持,以下是OptaPlanner團隊關于該問題的答復,
實時規劃
實時規劃則與具體的規劃業務關系更強,根據業務具體要求來決定是否需要實時規劃,在絕大多數的規劃應用場景中,計劃是一種持續性、連貫性的作業,即前后兩個計劃周期存在一定承接要求,通常上一個周期的執行結果,作為下一周期計劃輸入內容的其中一部分,因此,相鄰兩個計劃之間的銜接存在一定的復雜度,并需要一定的設計才能切實反映實際的計劃情況,之前本專欄有一篇關于兩個相鄰計劃之間銜接的文章,提出了一些方案可參考:相鄰兩個生產計劃之間的銜接問題
實時規劃需求的來源
常言道 - “計劃永遠不如變化快”,要實作前后兩個周期性計劃的接續,除了使用上文中提到的一些技術手段(例如設定鎖定區)外,還可以換一個角度思考,既然周期性計劃存在連貫性問題難以處理,那么我們能否直接把這個周期取消,不區分計劃的生成時間與執行時間,而是直接讓引擎在整個計劃程序中都處于待命運行狀態?實作計劃跟隨變化?實時計劃技術就是為實作此理論而提供,本文將介紹實時計劃的相關適用場景、設計及實作方法,事實上從具體的業務出發,無論是周期性計劃還是實時計劃,都需要任務進行鎖定的,原因何在?大家可以在評論區討論,就是因為"計劃 - 執行 - 反饋 - 再計劃..."是一個持續的、連貫的程序,因此,若存在一種技術可無限接近這種需求,那就能很大程度上解決上述程序中前后計劃之間因時效性差異導致的各種問題,
實時規劃的定義
在規劃運算進行程序中,當被規劃的物件(包括規劃物體物件和問題事實物件)發生變化,引擎可實時地將這種變化納入規劃范圍,并在當前規劃結果的基礎上快速輸出變化后的新的解決方案,OptaPlanner稱之為實時規劃,例如:在生產計劃的場景中,規劃程式在規劃運算程序中,出現緊急插單需要即時處理,新插入的訂單提交到規劃服務后,規劃程式會即時基于現有的規劃結果,將新的訂單納入考慮后,輸出一個新的結果,洗掉訂單、機臺突發停機等情況亦然,又如在VRP場景中,當一位司機根據規劃好的運輸計劃執行運輸任務時,中途遇到堵車等不可預見情況(引擎在進行規劃運算時,會預設所有路線都處在一個理想路況),可通過手機APP將當前情況反映到服務器,VRP規劃服務程式會即時變更當前路線的路況(例如將該路線修改為不可用,或延長途經時間),引擎將該變更納入考慮后,輸出一個新的行駛方案,并更新司機的手機上,這個程序需要具備實時性,且所產生新的運輸計劃影響程度降到最低,至少其它沒有出現例外情況的司機盡可能不受影響,以下用一個VRP示例討論各個不同階段出現新的訪問節點,通過OptaPlanner的實時規劃進行應對的情況,
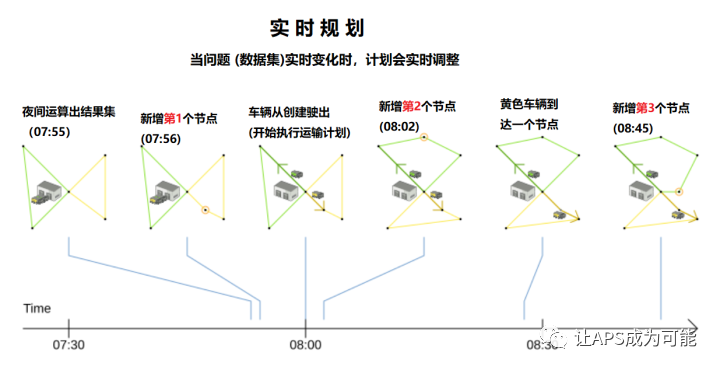
上圖展示的示例中,原始的資料集規劃于07:55生成計劃后,又增加了3個新的客戶(即3個節點),增加時間分別是07:56, 08:02 及 08:45, 且某些節點增加時,車輛已離開倉庫,即計劃已進入執行狀態,例如新增的第2,3個節點,在VRP場景中,規劃服務會在車輛上班開始執行運輸作業之前,生成一個行駛路徑方案,但訂單會不定時新增進來,每增加一個訂單,即表示運行圖上需要添加一個訪問點,當一個運輸計劃已經生成了,這個節點才添加進去,在傳統的規劃模式下,需要將新的節點納入規劃資料集中,將所有節點的車輛分配,及車輛的行駛路徑重置,重新跑一次VRP規劃,生成一個新的運輸計劃,但通過實時規劃技術則不需要重新將所有節點重新運行,僅需對新增的節點,實時地進行增量規劃即可,
實時規劃的實作
在具體的工程實踐中,實時規劃是一種非常實用的技術,對于一個求解器,就算沒有開箱即用的功能來支持該種作業方式,到了具體應用場景中,也需要通過系統設計的辦法來實作該種場景,Cplex, Gorubi, OR-Tools等求解器是否支持實時規劃,本人并未深入研究過,暫不好下定論,而OptaPlanner已提供了完整的內置功能,專門用于實時規劃情況,在之前發布的一篇關于機械師調度的文章中,詳細描述了實時規劃的程序和應用場景:機械師實時調度示例(I) - 實時規劃關于實時規劃在OptaPlanner 8.x之后,有了更為合理、好用的API,由于篇幅所限,將在下篇介紹,本文先介紹一下實時規劃如何應用在規劃服務中,下圖顯示了實時規劃服務的請求 - 處理 - 回應程序
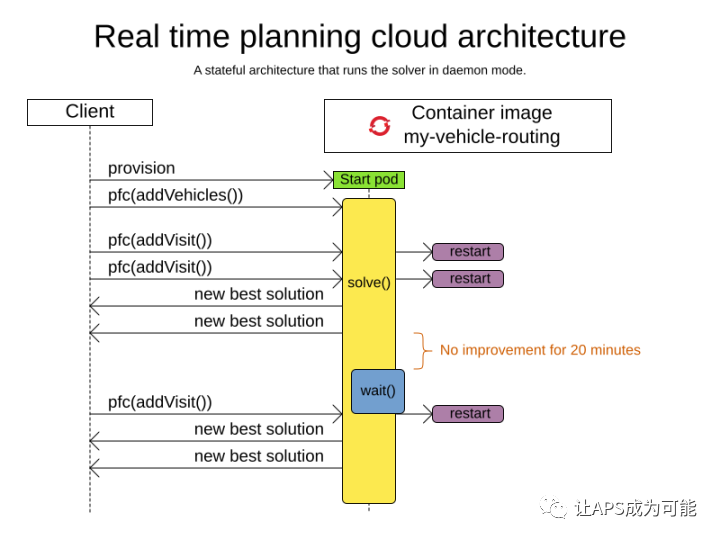
實時規劃開始時,引擎會先啟動一個規劃行程,該行程屬于留駐記憶體的守備行程,啟動后處理待命狀態,當有一個資料集傳入時,進行對該資料集進行規劃運算,在此程序中,通過對bestSolutionChanged事件的偵聽來獲取規劃結果,當行程符合結束條件時,引擎將會停止運算,回到待命程序,無論是在運算程序還是待狀態,當一個資料集有變更時,通過ProblemFactChanged介面(舊版本使用,新的版本將會整合到一個新的介面)接收變更,并觸發引擎處理此變更,上圖可清晰以反映上述程序,
一個IT老農,先盡力擔好當兒子、丈夫和父親的責任,然后做點有趣的事,轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/469588.html
標籤:其他
上一篇:[ Python ] PyQt5 PySide2 筆記
下一篇:Python 函式進階-遞回函式