1.Transform
1.1.基本轉換算子
map/flatMap/filter
- map
把陣列流中的每一個值,使用所提供的函式執行一遍,一一對應,得到元素個數相同的陣列流
- flatmap
flat是扁平的意思,它把陣列流中的每一個值,使用所提供的函式執行一遍,一一對應,得到元素相同的陣列流,只不過,里面的元素也是一個子陣列流,把這些子陣列合并成一個陣列以后,元素個數大概率會和原陣列流的個數不同, 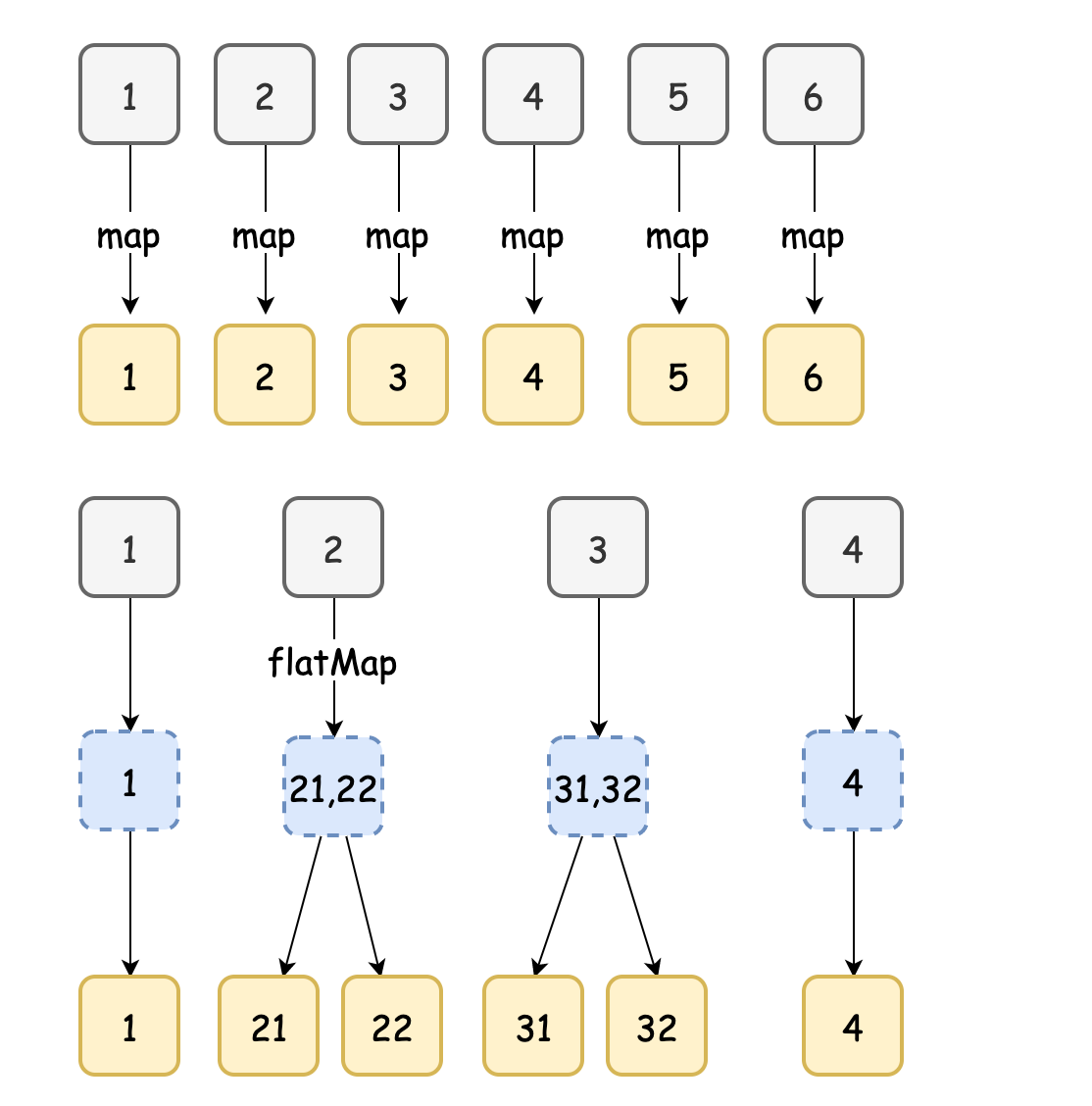
package com.frankcooper.apitest.transform;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class TransformTest1 {
public static void main(String[] args) throws Exception {
// 創建執行環境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 使得任務搶占同一個執行緒
env.setParallelism(1);
// 從檔案中獲取資料輸出
DataStream<String> dataStream = env.readTextFile("/Users/frankcooper/IdeaProjects/spring-boot-climbing/bigdata-flink-grab/src/main/resources/sensor.txt");
// 1. map, String => 字串長度INT
DataStream<Integer> mapStream = dataStream.map(new MapFunction<String, Integer>() {
@Override
public Integer map(String value) throws Exception {
return value.length();
}
});
// 2. flatMap,按逗號分割字串
DataStream<String> flatMapStream = dataStream.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
String[] fields = value.split(",");
for (String field : fields) {
out.collect(field);
}
}
});
// 3. filter,篩選"sensor_1"開頭的資料
DataStream<String> filterStream = dataStream.filter(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.startsWith("sensor_1");
}
});
// 列印輸出
mapStream.print("map");
flatMapStream.print("flatMap");
filterStream.print("filter");
env.execute();
}
}
輸入sensor.txt
sensor_1,1547718199,35.8
sensor_6,1547718201,15.4
sensor_7,1547718202,6.7
sensor_10,1547718205,38.1
sensor_1,1547718207,36.3
sensor_1,1547718209,32.8
sensor_1,1547718212,37.1
列印結果:
map> 24
flatMap> sensor_1
flatMap> 1547718199
flatMap> 35.8
filter> sensor_1,1547718199,35.8
map> 24
flatMap> sensor_6
flatMap> 1547718201
flatMap> 15.4
map> 23
flatMap> sensor_7
flatMap> 1547718202
flatMap> 6.7
map> 25
flatMap> sensor_10
flatMap> 1547718205
flatMap> 38.1
filter> sensor_10,1547718205,38.1
map> 24
flatMap> sensor_1
flatMap> 1547718207
flatMap> 36.3
filter> sensor_1,1547718207,36.3
map> 24
flatMap> sensor_1
flatMap> 1547718209
flatMap> 32.8
filter> sensor_1,1547718209,32.8
map> 24
flatMap> sensor_1
flatMap> 1547718212
flatMap> 37.1
filter> sensor_1,1547718212,37.1
1.2.多流轉換算子
split/connect/union
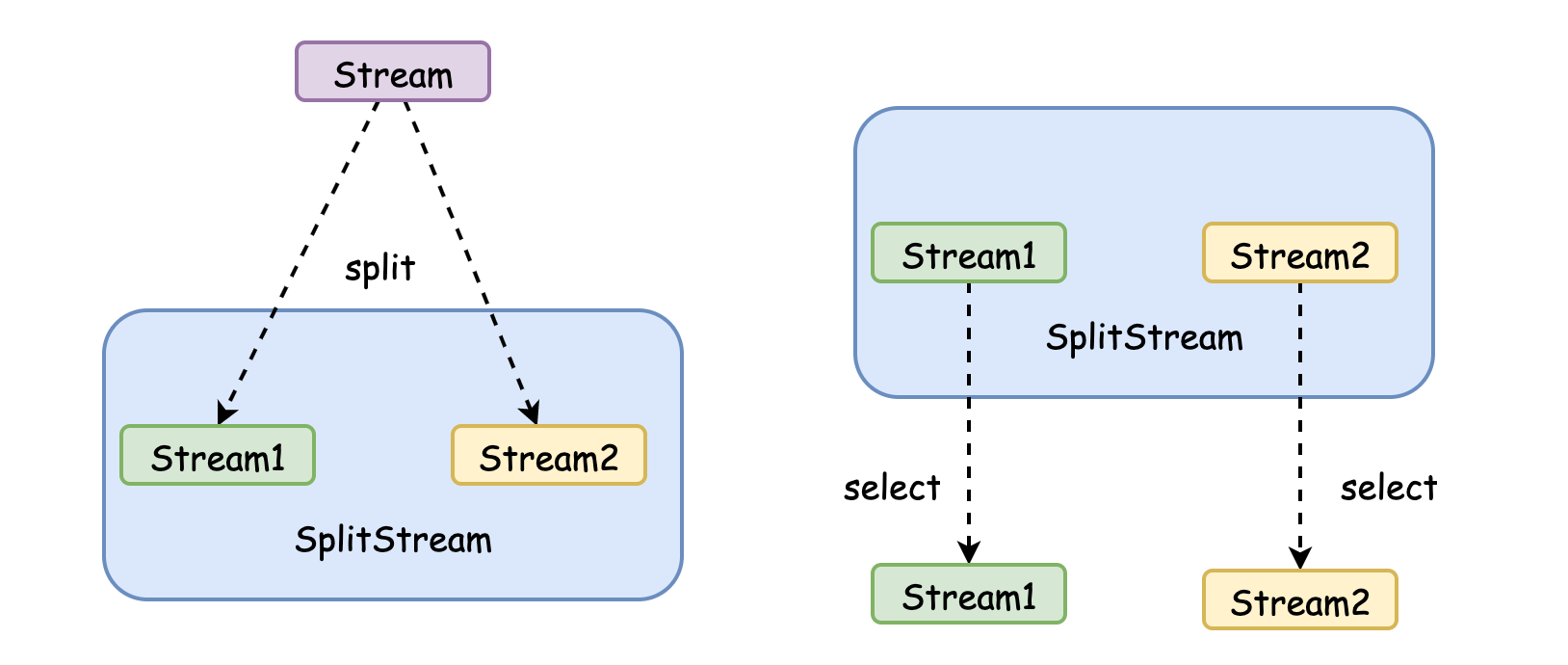
DataStream -> SplitStream
- 根據某些特征把DataStream拆分成SplitStream, SplitStream雖然看起來像是兩個Stream,但是其實它是一個特殊的Stream
import com.frankcooper.apitest.beans.SensorReading;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.collector.selector.OutputSelector;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.SplitStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
import java.util.Collections;
public class TransformTest4_MultipleStreams {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 從檔案讀取資料
DataStream<String> inputStream = env.readTextFile("/Users/frankcooper/IdeaProjects/spring-boot-climbing/bigdata-flink-grab/src/main/resources/sensor.txt");
// 轉換成SensorReading
DataStream<SensorReading> dataStream = inputStream.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
} );
// 1. 分流,按照溫度值30度為界分為兩條流
SplitStream<SensorReading> splitStream = dataStream.split(new OutputSelector<SensorReading>() {
@Override
public Iterable<String> select(SensorReading value) {
return (value.getTemperature() > 30) ? Collections.singletonList("high") : Collections.singletonList("low");
}
});
DataStream<SensorReading> highTempStream = splitStream.select("high");
DataStream<SensorReading> lowTempStream = splitStream.select("low");
DataStream<SensorReading> allTempStream = splitStream.select("high", "low");
highTempStream.print("high");
lowTempStream.print("low");
allTempStream.print("all");
env.execute();
}
}
輸出
high> SensorReading{id='sensor_1', timestamp=1547718199, temperature=35.8}
all > SensorReading{id='sensor_1', timestamp=1547718199, temperature=35.8}
low > SensorReading{id='sensor_6', timestamp=1547718201, temperature=15.4}
all > SensorReading{id='sensor_6', timestamp=1547718201, temperature=15.4}
...
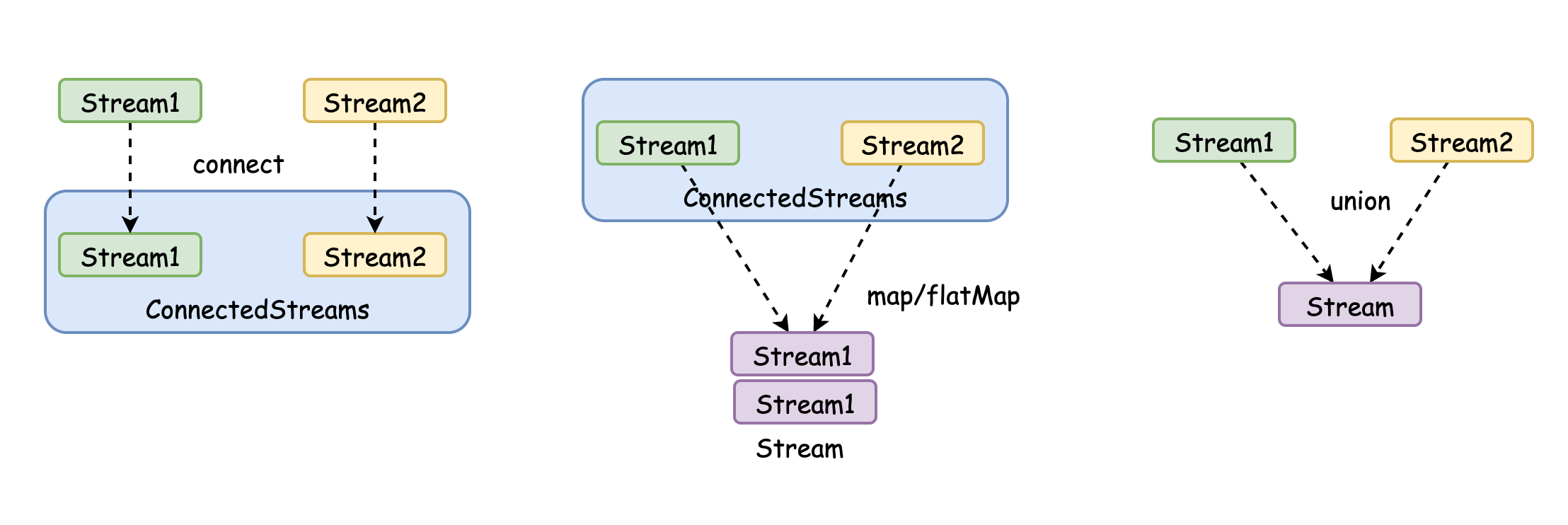
DataStream,DataStream -> ConnectedStreams
- 連接兩個保持他們型別的資料流,兩個資料流被Connect之后,只是被放在了一個流中,內部依然保持各自的資料和形式不發生任何變化,兩個流相互獨立,
DataStream -> DataStream
- 對兩個或者兩個以上的DataStream進行Union操作,產生一個包含多有DataStream元素的新DataStream,
對比
- 1.Connect 的資料型別可以不同,Connect 只能合并兩個流;
- 2.Union可以合并多條流,Union的資料結構必須是一樣的;
import com.frankcooper.apitest.beans.SensorReading;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.collector.selector.OutputSelector;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.SplitStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
import java.util.Collections;
/**
* @ClassName: TransformTest4_MultipleStreams
* @Description:
* @Author: wushengran on 2020/11/7 16:14
* @Version: 1.0
*/
public class TransformTest4_MultipleStreams {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 從檔案讀取資料
DataStream<String> inputStream = env.readTextFile("D:\\Projects\\BigData\\FlinkTutorial\\src\\main\\resources\\sensor.txt");
// 轉換成SensorReading
DataStream<SensorReading> dataStream = inputStream.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
} );
// 1. 分流,按照溫度值30度為界分為兩條流
SplitStream<SensorReading> splitStream = dataStream.split(new OutputSelector<SensorReading>() {
@Override
public Iterable<String> select(SensorReading value) {
return (value.getTemperature() > 30) ? Collections.singletonList("high") : Collections.singletonList("low");
}
});
DataStream<SensorReading> highTempStream = splitStream.select("high");
DataStream<SensorReading> lowTempStream = splitStream.select("low");
DataStream<SensorReading> allTempStream = splitStream.select("high", "low");
// highTempStream.print("high");
// lowTempStream.print("low");
// allTempStream.print("all");
// 2. 合流 connect,將高溫流轉換成二元組型別,與低溫流連接合并之后,輸出狀態資訊
DataStream<Tuple2<String, Double>> warningStream = highTempStream.map(new MapFunction<SensorReading, Tuple2<String, Double>>() {
@Override
public Tuple2<String, Double> map(SensorReading value) throws Exception {
return new Tuple2<>(value.getId(), value.getTemperature());
}
});
ConnectedStreams<Tuple2<String, Double>, SensorReading> connectedStreams = warningStream.connect(lowTempStream);
DataStream<Object> resultStream = connectedStreams.map(new CoMapFunction<Tuple2<String, Double>, SensorReading, Object>() {
@Override
public Object map1(Tuple2<String, Double> value) throws Exception {
return new Tuple3<>(value.f0, value.f1, "high temp warning");
}
@Override
public Object map2(SensorReading value) throws Exception {
return new Tuple2<>(value.getId(), "normal");
}
});
resultStream.print();
env.execute();
}
}
輸出
(sensor_1,35.8,high temp warning)
(sensor_6,normal)
(sensor_10,38.1,high temp warning)
(sensor_7,normal)
(sensor_1,36.3,high temp warning)
(sensor_1,32.8,high temp warning)
(sensor_1,37.1,high temp warning)
// 3. union聯合多條流
// warningStream.union(lowTempStream); 這個不行,因為warningStream型別是DataStream<Tuple2<String, Double>>,而highTempStream是DataStream<SensorReading>
highTempStream.union(lowTempStream, allTempStream);
1.3.算子轉換
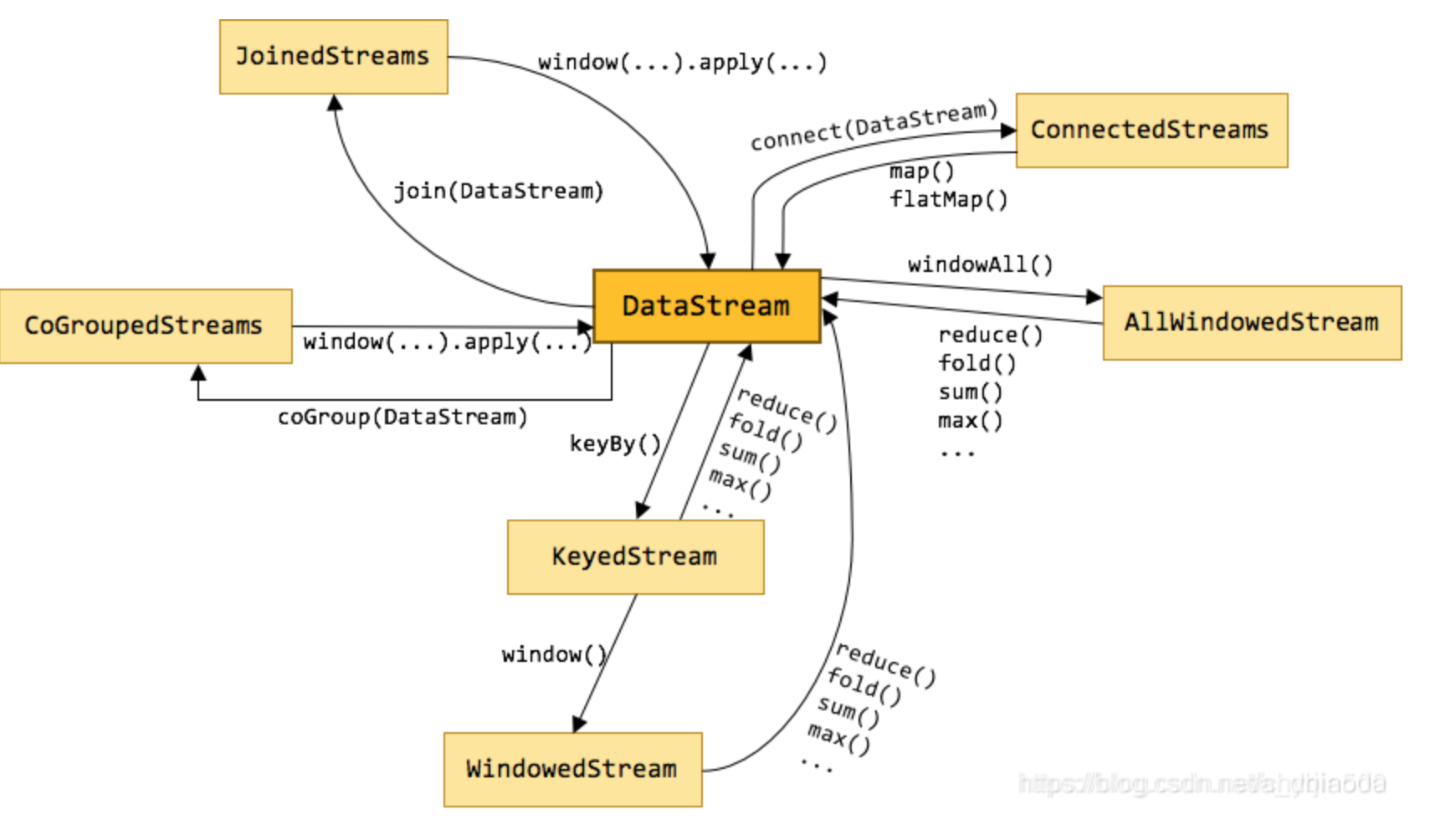
在Flink中,Transformation算子就是將一個或多個DataStream轉換為新的DataStream,可以將多個轉換組合成復雜的資料流拓撲, 如下圖所示,DataStream會由不同的Transformation操作,轉換、過濾、聚合成其他不同的流,從而完成我們的業務要求,
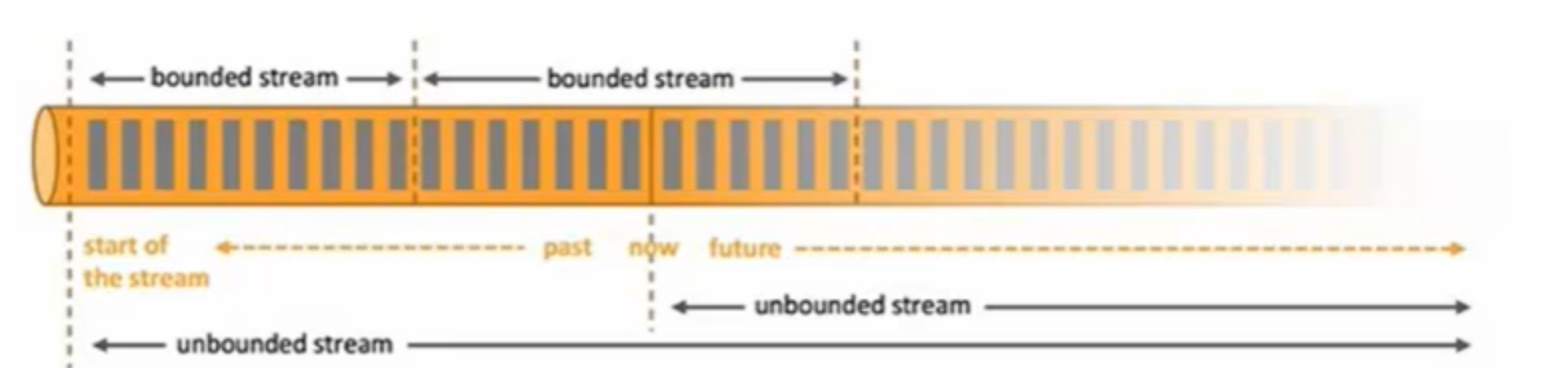
2.Window
- streaming流式計算是一種被設計用于處理無限資料集的資料處理引擎,而無限資料集是指一種不斷增長的本質上無限的資料集,而window是一種切割無限資料為有限塊進行處理的手段,
- Window是無限資料流處理的核心,Window將一個無限的stream拆分成有限大小的”buckets”桶,我們可以在這些桶上做計算操作,
2.1.Window的型別
- 時間視窗(Time Window):按照時間生成Window
- 滾動時間視窗
- 滑動時間視窗
- 會話視窗
- 計數視窗(Count Window):按照指定的資料條數生成一個Window,與時間無關
- 滾動計數視窗
- 滑動計數視窗
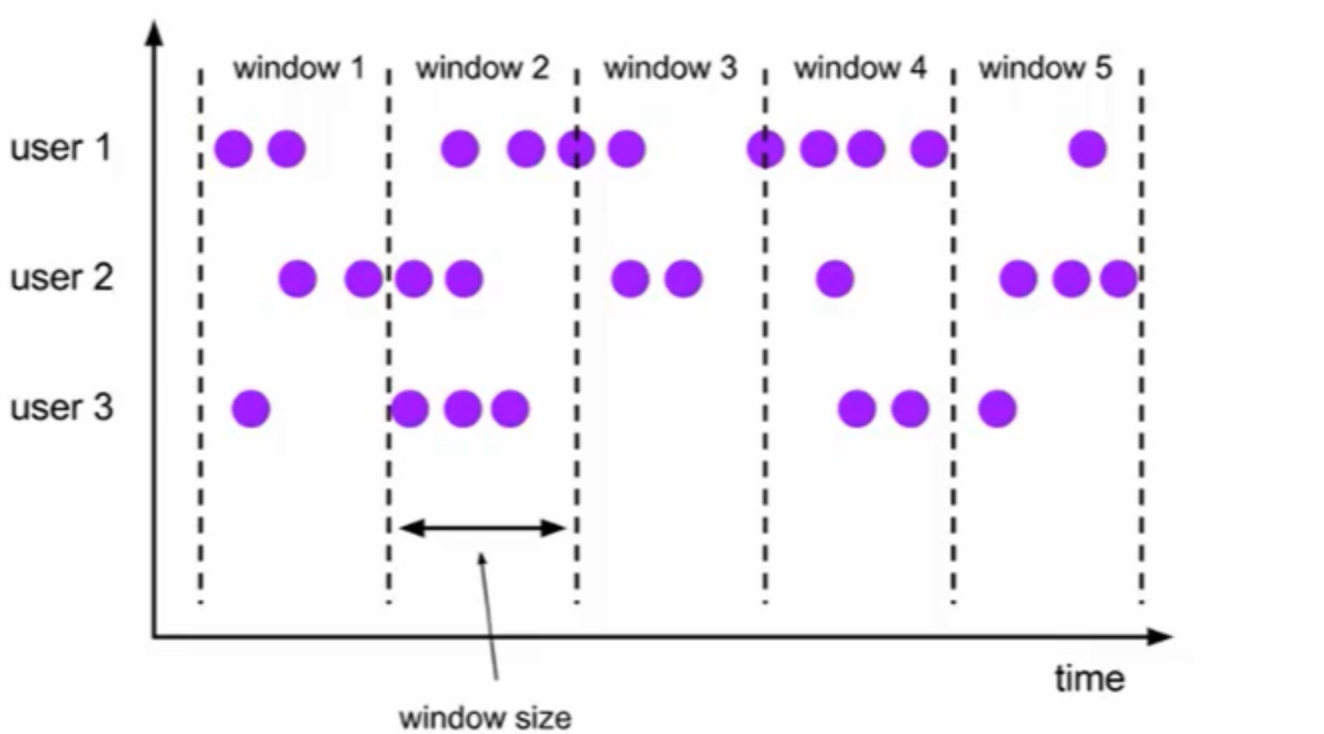
2.1.1滾動視窗(Tumbling Windows)
- 依據固定的視窗長度對資料進行切分
- 時間對齊,視窗長度固定,沒有重疊
2.1.2.滑動視窗(Sliding Windows)
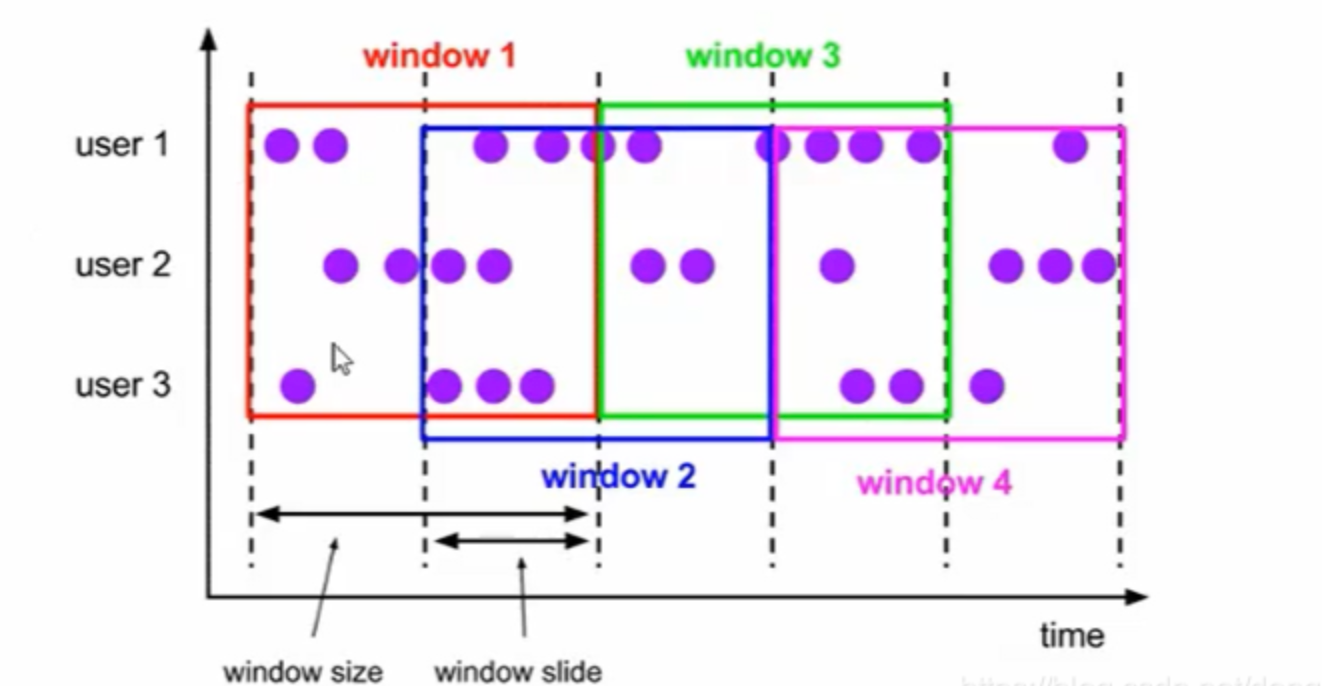
- 可以按照固定的長度向后滑動固定的距離
- 滑動視窗由固定的視窗長度和滑動間隔組成
- 可以有重疊(是否重疊和滑動距離有關系)
- 滑動視窗是固定視窗的更廣義的一種形式,滾動視窗可以看做是滑動視窗的一種特殊情況(即視窗大小和滑動間隔相等)
2.1.3.會話視窗(Session Windows)

- 由一系列事件組合一個指定時間長度的timeout間隙組成,也就是一段時間沒有接收到新資料就會生成新的視窗
- 特點:時間無對齊
2.2.概述
-
視窗分配器——
window()方法 -
我們可以用
.window()來定義一個視窗,然后基于這個window去做一些聚合或者其他處理操作,注意
window()方法必須在keyBy之后才能使用, -
Flink提供了更加簡單的
.timeWindow()和.countWindow()方法,用于定義時間視窗和計數視窗,
DataStream<Tuple2<String,Double>> minTempPerWindowStream =
datastream
.map(new MyMapper())
.keyBy(data -> data.f0)
.timeWindow(Time.seconds(15))
.minBy(1);
2.2.1.視窗分配器(window assigner)
window()方法接收的輸入引數是一個WindowAssigner- WindowAssigner負責將每條輸入的資料分發到正確的window中
- Flink提供了通用的WindowAssigner
- 滾動視窗(tumbling window)
- 滑動視窗(sliding window)
- 會話視窗(session window)
- 全域視窗(global window
2.2.2.創建不同型別的視窗
- 滾動時間視窗(tumbling time window)
.timeWindow(Time.seconds(15)) - 滑動時間視窗(sliding time window)
.timeWindow(Time.seconds(15),Time.seconds(5)) - 會話視窗(session window)
.window(EventTimeSessionWindows.withGap(Time.minutes(10))) - 滾動計數視窗(tumbling count window)
.countWindow(5) - 滑動計數視窗(sliding count window)
.countWindow(10,2)
2.3.TimeWindow
TimeWindow將指定時間范圍內的所有資料組成一個window,一次對一個window里面的所有資料進行計算,
2.3.1滾動視窗
Flink默認的時間視窗根據ProcessingTime進行視窗的劃分,將Flink獲取到的資料根據進入Flink的時間劃分到不同的視窗中,
DataStream<Tuple2<String, Double>> minTempPerWindowStream = dataStream
.map(new MapFunction<SensorReading, Tuple2<String, Double>>() {
@Override
public Tuple2<String, Double> map(SensorReading value) throws Exception {
return new Tuple2<>(value.getId(), value.getTemperature());
}
})
.keyBy(data -> data.f0)
.timeWindow( Time.seconds(15) )
.minBy(1);
時間間隔可以通過Time.milliseconds(x),Time.seconds(x),Time.minutes(x)等其中的一個來指定,
2.3.2.滑動視窗
滑動視窗和滾動視窗的函式名是完全一致的,只是在傳引數時需要傳入兩個引數,一個是window_size,一個是sliding_size,
下面代碼中的sliding_size設定為了5s,也就是說,每5s就計算輸出結果一次,每一次計算的window范圍是15s內的所有元素,
DataStream<SensorReading> minTempPerWindowStream = dataStream
.keyBy(SensorReading::getId)
.timeWindow( Time.seconds(15), Time.seconds(5) )
.minBy("temperature");
時間間隔可以通過Time.milliseconds(x),Time.seconds(x),Time.minutes(x)等其中的一個來指定,
2.4.CountWindow
CountWindow根據視窗中相同key元素的數量來觸發執行,執行時只計算元素數量達到視窗大小的key對應的結果,
注意:CountWindow的window_size指的是相同Key的元素的個數,不是輸入的所有元素的總數,
2.4.1.滾動視窗
默認的CountWindow是一個滾動視窗,只需要指定視窗大小即可,當元素數量達到視窗大小時,就會觸發視窗的執行,
DataStream<SensorReading> minTempPerWindowStream = dataStream
.keyBy(SensorReading::getId)
.countWindow( 5 )
.minBy("temperature");
2.4.2.滑動視窗
滑動視窗和滾動視窗的函式名是完全一致的,只是在傳引數時需要傳入兩個引數,一個是window_size,一個是sliding_size,
下面代碼中的sliding_size設定為了2,也就是說,每收到兩個相同key的資料就計算一次,每一次計算的window范圍是10個元素,
DataStream<SensorReading> minTempPerWindowStream = dataStream
.keyBy(SensorReading::getId)
.countWindow( 10, 2 )
.minBy("temperature");
2.5.window function
window function 定義了要對視窗中收集的資料做的計算操作,主要可以分為兩類:
- 增量聚合函式(incremental aggregation functions)
- 全視窗函式(full window functions)
2.5.1.增量聚合函式
- 每條資料到來就進行計算,保持一個簡單的狀態,(來一條處理一條,但是不輸出,到視窗臨界位置才輸出)
- 典型的增量聚合函式有ReduceFunction, AggregateFunction,
2.5.2.全視窗函式
- 先把視窗所有資料收集起來,等到計算的時候會遍歷所有資料,(來一個放一個,視窗臨界位置才遍歷且計算、輸出)
- ProcessWindowFunction,WindowFunction
2.5.3.其它
.trigger():window 什么時候關閉,觸發計算并輸出結果.evitor():定義移除某些資料的邏輯.allowedLateness():允許處理遲到的資料.sideOutputLateData():將遲到的資料放入側輸出流.getSideOutput():獲取側輸出流
2.6.測驗代碼
2.6.1.滾動時間視窗的增量聚合函式
增量聚合函式,特點即每次資料過來都處理,但是到了視窗臨界才輸出結果
import com.frankcooper.apitest.beans.SensorReading;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
public class WindowTest1_TimeWindow {
public static void main(String[] args) throws Exception {
// 創建執行環境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 并行度設定1,方便看結果
env.setParallelism(1);
// 從檔案讀取資料
// DataStream<String> dataStream = env.readTextFile("/Users/frankcooper/IdeaProjects/spring-boot-climbing/bigdata-flink-grab/src/main/resources/sensor.txt");
// 從socket文本流獲取資料
DataStream<String> inputStream = env.socketTextStream("localhost", 7777);
// 轉換成SensorReading型別
DataStream<SensorReading> dataStream = inputStream.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
});
// 開窗測驗
// 1. 增量聚合函式 (這里簡單統計每個key組里傳感器資訊的總數)
DataStream<Integer> resultStream = dataStream.keyBy("id")
// .countWindow(10, 2);
// .window(EventTimeSessionWindows.withGap(Time.minutes(1)));
// .window(TumblingProcessingTimeWindows.of(Time.seconds(15)))
// .timeWindow(Time.seconds(15)) // 已經不建議使用@Deprecated
.window(TumblingProcessingTimeWindows.of(Time.seconds(15)))
.aggregate(new AggregateFunction<SensorReading, Integer, Integer>() {
// 新建的累加器
@Override
public Integer createAccumulator() {
return 0;
}
// 每個資料在上次的基礎上累加
@Override
public Integer add(SensorReading value, Integer accumulator) {
return accumulator + 1;
}
// 回傳結果值
@Override
public Integer getResult(Integer accumulator) {
return accumulator;
}
// 磁區合并結果(TimeWindow一般用不到,SessionWindow可能需要考慮合并)
@Override
public Integer merge(Integer a, Integer b) {
return a + b;
}
});
resultStream.print("result");
env.execute();
}
}
2.6.2.滾動時間視窗的全視窗函式
全視窗函式,特點即資料過來先不處理,等到視窗臨界再遍歷、計算、輸出結果
import com.frankcooper.apitest.beans.SensorReading;
import org.apache.commons.collections.IteratorUtils;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
/**
* @author : Ashiamd email: [email protected]
* @date : 2021/2/1 7:14 PM
*/
public class WindowTest1_TimeWindow_1 {
public static void main(String[] args) throws Exception {
// 創建執行環境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 并行度設定1,方便看結果
env.setParallelism(1);
// // 從檔案讀取資料
// DataStream<String> dataStream = env.readTextFile("/tmp/Flink_Tutorial/src/main/resources/sensor.txt");
// 從socket文本流獲取資料
DataStream<String> inputStream = env.socketTextStream("localhost", 7777);
// 轉換成SensorReading型別
DataStream<SensorReading> dataStream = inputStream.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
});
// 2. 全視窗函式 (WindowFunction和ProcessWindowFunction,后者更全面)
SingleOutputStreamOperator<Tuple3<String, Long, Integer>> resultStream2 = dataStream.keyBy(SensorReading::getId)
.window(TumblingProcessingTimeWindows.of(Time.seconds(15)))
// .process(new ProcessWindowFunction<SensorReading, Object, Tuple, TimeWindow>() {
// })
.apply(new WindowFunction<SensorReading, Tuple3<String, Long, Integer>, String, TimeWindow>() {
@Override
public void apply(String s, TimeWindow window, Iterable<SensorReading> input, Collector<Tuple3<String, Long, Integer>> out) throws Exception {
String id = s;
long windowEnd = window.getEnd();
int count = IteratorUtils.toList(input.iterator()).size();
out.collect(new Tuple3<>(id, windowEnd, count));
}
});
resultStream2.print("result2");
env.execute();
}
}
2.6.3.滑動計數視窗的增量聚合函式
滑動視窗,當視窗不足設定的大小時,會先按照步長輸出,
eg:視窗大小10,步長2,那么前5次輸出時,視窗內的元素個數分別是(2,4,6,8,10),再往后就是10個為一個視窗了,
import com.frankcooper.apitest.beans.SensorReading;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class WindowTest2_CountWindow {
public static void main(String[] args) throws Exception {
// 創建執行環境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 并行度設定1,方便看結果
env.setParallelism(1);
// 從socket文本流獲取資料
DataStream<String> inputStream = env.socketTextStream("localhost", 7777);
// 轉換成SensorReading型別
DataStream<SensorReading> dataStream = inputStream.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
});
DataStream<Double> resultStream = dataStream.keyBy(SensorReading::getId)
.countWindow(10, 2)
.aggregate(new MyAvgFunc());
resultStream.print();
env.execute();
}
private static class MyAvgFunc implements AggregateFunction<SensorReading, Tuple2<Double, Integer>, Double> {
@Override
public Tuple2<Double, Integer> createAccumulator() {
return new Tuple2<>(0.0, 0);
}
@Override
public Tuple2<Double, Integer> add(SensorReading value, Tuple2<Double, Integer> accumulator) {
return new Tuple2<>(accumulator.f0 + value.getTemperature(), accumulator.f1 + 1);
}
@Override
public Double getResult(Tuple2<Double, Integer> accumulator) {
return accumulator.f0 / accumulator.f1;
}
@Override
public Tuple2<Double, Integer> merge(Tuple2<Double, Integer> a, Tuple2<Double, Integer> b) {
return new Tuple2<>(a.f0 + b.f0, a.f1 + b.f1);
}
}
}
-
這里為了方便,就只輸入同一個keyBy組的資料
sensor_1sensor_1,1547718199,1 sensor_1,1547718199,2 sensor_1,1547718199,3 sensor_1,1547718199,4 sensor_1,1547718199,5 sensor_1,1547718199,6 sensor_1,1547718199,7 sensor_1,1547718199,8 sensor_1,1547718199,9 sensor_1,1547718199,10 sensor_1,1547718199,11 sensor_1,1547718199,12 sensor_1,1547718199,13 sensor_1,1547718199,14 -
輸出
輸入時,會發現,每次到達一個視窗步長(這里為2),就會計算得出一次結果,
第一次計算前2個數的平均值
第二次計算前4個數的平均值
第三次計算前6個數的平均值
第四次計算前8個數的平均值
第五次計算前10個數的平均值
第六次計算前最近10個數的平均值
第七次計算前最近10個數的平均值
result> 1.5 result> 2.5 result> 3.5 result> 4.5 result> 5.5 result> 7.5 result> 9.5
2.6.4.其它
// 3. 其他可選API
OutputTag<SensorReading> outputTag = new OutputTag<SensorReading>("late") {
};
SingleOutputStreamOperator<SensorReading> sumStream = dataStream.keyBy("id")
.timeWindow(Time.seconds(15))
// .trigger() // 觸發器,一般不使用
// .evictor() // 移除器,一般不使用
.allowedLateness(Time.minutes(1)) // 允許1分鐘內的遲到資料<=比如資料產生時間在視窗范圍內,但是要處理的時候已經超過視窗時間了
.sideOutputLateData(outputTag) // 側輸出流,遲到超過1分鐘的資料,收集于此
.sum("temperature"); // 側輸出流 對 溫度資訊 求和,
- 個人主頁【阿飛演算法】 加我好友,進群一起交流~

本文由博客一文多發平臺 OpenWrite 發布!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/469757.html
標籤:Java