在C/C++中有個叫指標的玩意存在感極其強烈,而說到指標又不得不提到記憶體管理,現在時不時能聽到一些朋友說指標很難,實際上說的是記憶體操作和管理方面的難,(這篇筆記咱也會結合自己的理解簡述一些相關的記憶體知識)
最近在寫C程式使用指標的時候遇到了幾個讓我印象深刻的地方,這里記錄一下,以便今后回顧,

“經一蹶者長一智,今日之失,未必不為后日之得,” - 王陽明《與薛尚謙書》
指標和二級指標
簡述下指標的概念,
指標
一個指標可以理解為一條記憶體地址,
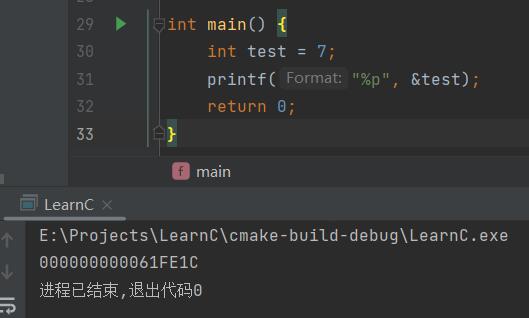
這里先定義了一個整型變數
test,接著用取址運算子&取得這個變數的記憶體地址并列印出來,
可以看到該變數的記憶體地址是000000000061FE1C
指標變數
指標變數就是存放指標(也就是存放記憶體地址)的變數,使用資料型別* 變數名進行定義,
值得注意的是指標變數內儲存的指標(記憶體地址)所代表的變數的資料型別,比如int*定義的指標變數就只能指向int型別的變數,
int test = 233;
int* ptr = &test;
test變數的型別是整型int,所以test存放的就是一個整形資料,
而ptr變數的型別是整型指標型別int*,存放則的是整性變數test的指標(記憶體地址),
二級指標
二級指標指的是一級指標變數的地址,
int main() {
int test = 233;
printf("%p\n", &test);
int *ptr = &test;
printf("%p", &ptr);
return 0;
}
/* stdout
000000000061FE1C
000000000061FE10
*/
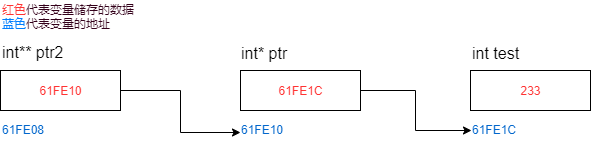
這個例子中二級指標就是
ptr變數的地址000000000061FE10,
二級指標變數
二級指標變數就是存放二級指標(二級指標的地址)的變數,使用資料型別** 變數名進行定義,
int main() {
int test = 233;
int *ptr = &test;
int **ptr2 = &ptr;
return 0;
}
ptr變數的型別是整型指標型別int*,存放的是整性(int)變數test的指標(記憶體地址),
ptr2變數的型別是二級整型指標型別int**,存放的是整性指標(int*)變數ptr的記憶體地址,
多級指標變數
雖然二級以上的指標變數相對來說不太常用,但我覺得基本的辨別方法還是得會的:
通過觀察發現,指標變數的資料型別定義其實就是在其所指向的資料型別名后加一個星號,
比如說:
-
指標
ptr指向整型變數int test,那么它的定義寫法就是int* ptr,(資料型別在int后加了一個星號) -
指標
ptr2指向一級指標變數int* ptr,那么它的定義寫法就是int** ptr2,(資料型別在int*后加了一個星號)
再三級指標變數int*** ptr3,乍一看星號這么多,實際上“剝”一層下來就真相大白了:
(int**)*
實際上三級指標變數指向的就是二級指標變數的地址,

其他更多級的指標變數可以依此類推,
堆疊記憶體和堆記憶體
指標和記憶體操作關系緊密,提到指標總是令人情不自禁地想起記憶體,
程式運行時占用的記憶體空間會被劃分為幾個區域,其中和這篇筆記息息相關的便是堆疊區(Stack)和堆區(Heap),
堆疊區 (Stack)
堆疊區的操作方式正如資料結構中的堆疊,是LIFO后進先出的,這種操作模式的一個很經典的應用就是遞回函式了,
每個函式被呼叫時需要從堆疊區劃分出一塊堆疊記憶體用來存放呼叫相關的資訊,這塊堆疊記憶體被稱為函式的堆疊幀,
堆疊幀存放的內容主要是(按入堆疊次序由先至后):
-
回傳地址,也就是函式被呼叫處的下一條指令的記憶體地址(記憶體中專門有代碼區用于存放),用于函式呼叫結束回傳時能接著原來的位置執行下去,
-
函式呼叫時的引數值,
-
函式呼叫程序中定義的區域變數的值,
-
and so on...
由LIFO后進先出可知一次函式呼叫完畢后相較而言區域變數先出堆疊,接著是引數值,最后堆疊頂指標指向回傳地址,函式回傳,接著下一條指令執行下去,
堆疊區的特性:
-
交由系統(C語言這兒就是編譯器參與實作)自動分配和釋放,這點在函式呼叫中體現的很明顯,
-
分配速度較快,但并不受程式員控制,
-
相對來說空間較小,如果申請的空間大于堆疊剩余的記憶體空間,會引發堆疊溢位問題,(堆疊記憶體大小限制因作業系統而異)
比如遞回函式控制不當就會導致堆疊溢位問題,因為每層函式呼叫都會形成新的堆疊幀“壓到”堆疊上,如果遞回函式層數過高,堆疊幀遲遲得不到“彈出”,就很容易擠爆堆疊記憶體,
-
堆疊記憶體占用大小隨著函式呼叫層級升高而增大,隨著函式呼叫結束逐層回傳而減小;也隨著區域變數的定義而增大,隨著區域變數的銷毀而減小,
堆疊記憶體中儲存的資料的生命周期很清晰明確,
-
堆疊區是一片連續的記憶體區域,
堆區 (Heap)
堆記憶體就真的是“一堆”記憶體,值得一提的是,這里的堆和資料結構中的堆沒有關系,
相對堆疊區來說,堆區可以說是一個更加靈活的大記憶體區,支持按需進行動態分配,
堆區的特性:
-
交由程式員或者垃圾回識訓制進行管理,如果不加以回收,在整個程式沒有運行完前,分配的堆記憶體會一直存在,(這也是容易造成記憶體泄漏的地方)
在C/C++中,堆記憶體需要程式員手動申請分配和回收,
-
分配速度較慢,系統需要依照演算法搜索(鏈表)足夠的記憶體區域以分配,
-
堆區空間比較大,只要還有可用的物理記憶體就可以持續申請,
-
堆區是不連續(離散)的記憶體區域,(大概是依賴鏈表來進行分配操作的)
-
現代作業系統中,在程式運行完后會回收掉所有的堆記憶體,
要養成不用就釋放的習慣,不然運行程序中行程占用記憶體可能越來越大,
簡述C中堆記憶體的分配與釋放
分配
這里咱就直接報菜名吧!

這一部分的函式的原型都定義在頭檔案stdlib.h中,
-
void* malloc(size_t size)用于請求系統從堆區中分配一段連續的記憶體塊,
-
void* calloc(size_t n, size_t size);在和
malloc一樣申請到連續的記憶體塊后,將所有分配的記憶體全部初始化為0, -
void* realloc(void* block, size_t size)修改已經分配的記憶體塊的大小(具體實作是重新分配),可以放大也可以縮小,
malloc可以記成Memory Allocate 分配記憶體;
calloc可以記成Clear and Allocate 分配并設定記憶體為0;
realloc可以記成Re-Allocate 重分配記憶體,
簡單來說原理大概是這樣:
-
malloc記憶體分配依賴的資料結構是鏈表,簡單說來就是所有空閑的記憶體塊會被組織成一個空閑記憶體塊鏈表, -
當要使用
malloc分配記憶體時,它首先會依據演算法掃描這個鏈表,直到找到一個大小滿足需求的空閑記憶體塊為止,然后將這個空閑記憶體塊傳遞給用戶(通過指標),
(如果這塊的大小大于用戶所請求的記憶體大小,則將多余部分“切出來”接回鏈表中), -
在不斷的分配與釋放程序中,由于記憶體塊的“切割”,大塊的記憶體可能逐漸被切成許多小塊記憶體存在鏈表中,這些便是記憶體碎片,當
malloc找不到合適大小的記憶體塊時便會嘗試合并這些記憶體碎片以獲得大塊空閑的記憶體, -
實在找不到空閑記憶體塊的情況下,
malloc會回傳NULL指標,
釋放
釋放手動分配的堆記憶體需要用到free函式:
void free(void* block)
只需要傳入指向分配記憶體始址的指標變數作為實參傳入即可,
在
C/C++中,對于手動申請分配的堆記憶體在使用完后一定要及時釋放,
不然在運行程序中行程占用記憶體可能會越來越大,也就是所謂的記憶體泄漏,
不過在現代作業系統中,程式運行完畢后OS會自動回收對應行程的記憶體,包括泄露的記憶體,記憶體泄露指的是在程式運行程序中無法操作的記憶體,
free為什么知道申請的記憶體塊大小?
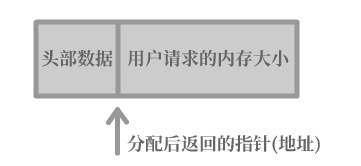
簡單來說,就是在malloc進行記憶體分配時會把記憶體大小分配地略大一點,多余的記憶體部分用于儲存一些頭部資料(這塊記憶體塊的資訊),這塊頭部資料內就包括分配的記憶體的長度,
但是在回傳指標的時候,malloc會將其往后移動,使得指標代表的是用戶請求的記憶體塊的起始地址,
頭部資料占用的大小通常是固定的(網上查了一下有一種說法是16位元組,也有說是sizeof(size_t)的),在將指標傳入free后,free會將指標向前移動指定長度以獲得頭部資料,讀取到分配的記憶體長度,然后連同頭部資料和所分配長度的記憶體一并釋放掉,
記憶體釋放可以理解為這塊記憶體被重新接到了空閑鏈表上,以備后面的分配,
(實際上記憶體釋放后的情況其實挺復雜的,得要看具體的演算法實作和運行環境)
二維陣列
定義和初始化
C語言中二維陣列的定義:
資料型別 陣列名[行數][列數];
初始化則可以使用大括號:
int a[3][4]={
{1,2,3,4},
{5,6,7,8},
{9,10,11,12}
};
int b[3][4]={ // 內層不要大括號也是可以的,具體為什么后面再說
1,2,3,4,
5,6,7,8,
9,10,11,12
};
char str[2][6]={
"Hello",
"World"
};
此外,在有初始化值的情況下,定義二維陣列時的一維長度(行數)是可以省略的:
int a[][4]={ // 如果沒有初始化,則一維長度不可省略
1,2,3,4,
5,6,7,8,
9,10,11,12
}
在記憶體中
按上述陳述句定義的陣列,在行程記憶體中一般儲存于:
-
堆疊區 - 在函式內部定義的區域陣列變數,
-
靜態儲存區 - 當用
static修飾陣列變數或者在全域作用域中定義陣列,
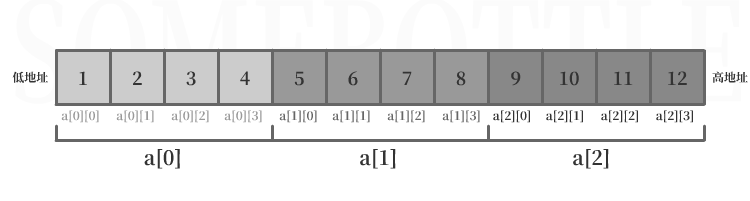
陣列在記憶體中是連續且呈線性儲存的,二維陣列也是不例外的,
雖然在使用程序中二維陣列發揮的是“二維”的功能,但其在記憶體中是被映射為一維線性結構進行儲存的,
實踐驗證一下:
int i, j;
int a[][4] = { // 如果沒有初始化,則一維長度不可省略
1, 2, 3, 4,
5, 6, 7, 8,
9, 10, 11, 12
};
size_t len1 = sizeof(a) / sizeof(a[0]);
size_t len2 = sizeof(a[0]) / sizeof(a[0][0]);
for (i = 0; i < len1; i++) {
for (j = 0; j < len2; j++)
printf(" [%d]%p ", a[i][j], &a[i][j]);
printf("\n");
}
輸出:

第一維有3行,第二維有4列,
一個int型別資料占用4個位元組,從上面的圖可以看出來:
-
[1]000000000061FDD0->[2]000000000061FDD4相隔4位元組,說明這兩個陣列元素相鄰,同一行中陣列元素儲存連續, -
[4]000000000061FDDC->[5]000000000061FDE0同樣相隔4位元組,這兩個陣列元素在記憶體中也是相鄰的, -
從
[1]000000000061FDD0到[12]000000000061FDFC正好相差44個位元組,整個二維陣列元素在記憶體中是連續儲存的,
這樣一看,為什么定義并初始化的時候二維陣列的第一維可以省略已經不言而喻了:
在初始化的時候編譯器通過陣列第二維的大小對元素進行“分組”,每一組可以看作是一個一維陣列,這些一維陣列在記憶體中從低地址到高地址連續排列儲存形成二維陣列:
在上面例子中大括號中的元素
{1,2,3,4,5,6,7,8,9,10,11,12}被按第二維長度4劃分成了{1,2,3,4},{5,6,7,8},{9,10,11,12}三組,這樣程式也能知道第一維陣列長度為3了,
二維陣列名代表的地址
一維陣列名代表的是陣列的起始地址(也是第一個元素的地址),
二維陣列在記憶體中也是映射為一維進行連續儲存的,
既然如此,二維陣列名代表的地址其實也是整個二維陣列的起始地址,在上面的例子中相當于a[0][0]的地址,
在上面的示例最后加一行:
printf("Arr address: %p", a);
列印出來的地址和a[0][0]的地址完全一致,是000000000061FDD0,
二維陣列和二級指標
二維陣列不等于二級指標
首先要明確一點:二維陣列 ≠ 二級指標
剛接觸C語言時我總是想當然地把這兩個搞混了,實際上根本不是一回事兒,
-
二級指標變數儲存的是一級指標變數的地址,
-
二維陣列是記憶體中連續儲存的一組資料,二維陣列名相當于一個一級指標(二維陣列的起始地址),
int arr[][4]={
{1,2},{1},{3},{4,5}
};
int** ptr=arr; // 這樣寫肯定是不行的!,ptr儲存的是一級指標變數的地址
int* ptr=arr; // 這樣寫是可以的,但是不建議
int* ptr=&arr[0][0]; // 這樣非常ok, ptr儲存的是陣列起始地址(也就是首個變數的地址)
可以把之前二維陣列的例子改一下:
int i;
int a[][4] = { // 如果沒有初始化,則一維長度不可省略
1, 2, 3, 4,
5, 6, 7, 8,
9, 10, 11, 12
};
size_t len1 = sizeof(a) / sizeof(a[0]);
size_t len2 = sizeof(a[0]) / sizeof(a[0][0]);
size_t totalLen = len1 * len2; // 整個二維陣列的長度
int *ptr = &a[0][0]; // ptr指向二維陣列首地址
for (i = 0; i < totalLen; i++) {
// 一維指標操作就是基于一維的,所以整個二維陣列此時會被當作一條連續的記憶體
printf(" [%d]%p ", ptr[i], &ptr[i]);
// printf(" [%d]%p ", *(ptr + i), ptr + i);
if (i % len2 == 3) // 換行
printf("\n");
}
printf("Arr address: %p", ptr);
輸出結果和之前遍歷二維陣列的是一模一樣的,
指標陣列
實作“二維陣列”
既然二級指標變數不能直接指向二維陣列,那能不能依賴二級指標來實作一個類似的結構呢?當然是可以的啦!
整型變數存放著整型int資料,整型陣列int a[]中存放了整型資料;
如果是用申請堆記憶體來實作的整型陣列:
int* arr = (int*)malloc(sizeof(int) * 3);
指標int*變數arr此時指向的是連續存放整型(int)資料的記憶體的起始地址,相當于一個一維陣列的起始地址,
代碼實作
二級指標int**變數存放著一級指標變數的地址,那么就可以構建二級指標陣列來存放二級指標資料(也就是每個元素都是一級指標變數的地址),

具體代碼實作:
int rows = 3; // 行數/一維長度
int cols = 4; // 列數/二維長度
int **ptr = (int **) malloc(rows * sizeof(int *));
// 分配一段連續的記憶體,儲存int*型別的資料
int i, j, num = 1;
for (i = 0; i < rows; i++) {
ptr[i] = (int *) malloc(cols * sizeof(int));
// 再分配一段連續的記憶體,儲存int型別的資料
for (j = 0; j < cols; j++)
ptr[i][j] = num++; // 儲存一個整型資料1-12
}
其中
ptr[i] = (int *) malloc(cols * sizeof(int));
這一行,等同于
*(ptr+i) = ...
也就是利用間接訪問符*讓一級指標變數指向在堆記憶體中分配的一段連續整形資料,這里相當于初始化了第二維,
而在給整型元素賦值時和二維陣列一樣用了中括號進行訪問:
ptr[i][j] = i * j;
其實就等同于:
*(*(ptr+i)+j) = i * j;
-
第一次訪問第一維元素,用第一維起始地址
ptr加上第一維下標i,取出對應的一級指標變數中存放的地址:*(ptr+i)
這個地址是第二維中一段連續記憶體的起始地址, -
第二次訪問第二維元素,用1中取到的地址
*(ptr+i)加上第二維下標j,再用間接訪問符*訪問對應的元素,并賦值,
在記憶體中的存放
指標陣列在記憶體中的存放不同于普通定義的二維陣列,它的每一個維度是連續儲存的,但是維度和維度之間在記憶體中的存放是離散的,
用一個回圈列印一下每個元素的地址:
for (i = 0; i < rows; i++) {
for (j = 0; j < cols; j++)
printf(" [%d]%p ", ptr[i][j], *(ptr + i) + j);
printf("\n");
}
輸出:

可以看到第二維度的地址是連續的,但是第二維度“陣列”之間并不是連續的,比如元素4和元素5的地址相差了20個位元組,并不是四個位元組,
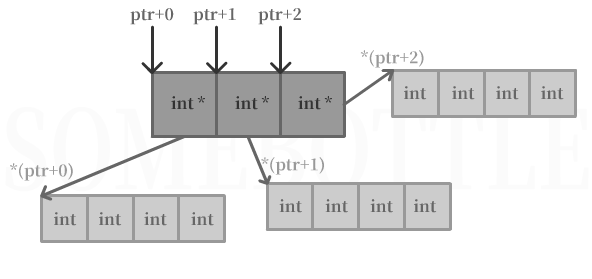
其在記憶體中的存放結構大致如上,并無法保證*(ptr+0)+3和*(ptr+1)的地址相鄰,也無法保證*(ptr+1)+3和*(ptr+2)的地址相鄰,
這種非連續的存放方式可以說是和二維陣列相比很大的一個不同點了,
釋放對應的堆記憶體
通常指標陣列實作的“二維陣列”是在堆記憶體中進行存放的,既然申請了堆記憶體,咱也應該養成好習慣,使用完畢后將其釋放掉:
for (i = 0; i < rows; i++)
free(ptr[i]);
free(ptr);
先利用一個回圈釋放掉每一個一級指標變數指向的連續記憶體塊(儲存整型資料),最后再把二級指標變數指向的連續記憶體塊(儲存的是一級指標變數的地址)釋放掉,
sizeof的事兒
sizeof()是C語言中非常常用的一個運算子,而二級指標和二維陣列的區別在這里也可以很好地展現出來,
對于直接定義的陣列
對于非變數長度定義的陣列,sizeof在編譯階段就會完成求值運算,被替換為對應資料的大小的常量值,
int arr[n];這種定義時陣列長度為變數的即為變數長度陣列(C99標準開始支持),不過還是不太推薦這種寫法,
直接固定長度定義二維陣列時,編譯器是知道這個變數是陣列的,比如:
int arr[3][4];
size_t arrSize = sizeof(arr);
在編譯階段,編譯器知道陣列arr是一個整型int二維陣列:
-
每個第二維陣列包含四個
int資料,長度為sizeof(int)*4=16個位元組, -
第一維陣列包含三個第二維陣列,每個第二維陣列長度為
16位元組,整個二維陣列總長度為16*3=48個位元組,
即sizeof(arr) = 48,
對于指標陣列
指標變數儲存的是指標,也就是一個地址,記憶體地址在運算的時候會存放在CPU的整數暫存器中,
64位計算機中整數暫存器寬度有64bit(位),而指標資料要能存放在這里,
目前來說 1 位元組(Byte) = 8 位(bit),那么64位就是8個位元組,
所以64位系統中指標變數的長度是8位元組,
int rows = 3; // 行數/一維長度
int **ptr = (int **) malloc(rows * sizeof(int *));
size_t ptrSize = sizeof(ptr); // 8 Bytes
size_t ptrSize2 = sizeof(int **); // 8 Bytes
size_t ptrSize3 = sizeof(int *); // 8 Bytes
size_t ptrSize4 = sizeof(char *); // 8 Bytes
雖然上面咱通過申請分配堆記憶體實作了二維陣列(用二級指標變數ptr指向了指標陣列起址),
但其實在編譯器眼中,ptr就單純是一個二級指標變數,占用位元組數為8 Bytes(64位),儲存著一個地址,因此在這里是無法通過sizeof獲得這塊連續記憶體的長度的,
通過上面的例子很容易能觀察出來:
sizeof(指標變數) = 8 Bytes (64位計算機)
無論指標變數指向的是什么資料的地址,它儲存的單純只是一個記憶體地址,所以所有指標變數的占用位元組數是一樣的,
函式傳參與回傳
得先明確一點:C語言中不存在所謂的陣列引數,通常讓函式接受一個陣列的資料需要通過指標變數引數傳遞,
傳參時陣列發生退化
int test(int newArr[2]) {
printf(" %d ", sizeof(newArr)); // 8
return 0;
}
int main() {
int arr[5] = {1, 2, 3, 4, 5};
test(arr);
return 0;
}
在上面這個例子中test函式的定義中宣告了“看上去像陣列的”形參newArr,然而sizeof的運算結果是8,
實際上這里的形參宣告是等同于int* newArr的,因為把陣列作為引數進行傳遞的時候,實際上傳遞的是陣列的首地址(因為陣列名就代表陣列的首地址),
這種情況下就發生了陣列到指標的退化,
在編譯器的眼中,newArr此時就被當作了一個指標變數,指向arr陣列的首地址,因此宣告中陣列的長度怎么寫都行:int newArr[5],int newArr[]都可以,
為了讓代碼更加清晰,我覺得最好還是宣告為int* newArr,這樣一目了然能知道這是一個指標變數!
函式內運算涉及到陣列長度時
當函式內運算涉及到陣列長度時,就需要在函式定義的時候另宣告一個形參來接受陣列長度:
int test(int *arr, size_t rowLen, size_t colLen) {
int i;
size_t totalLen = rowLen * colLen;
for (i = 0; i < totalLen; i++) {
printf(" %d ", arr[i]);
if (i % colLen == colLen - 1) // 每個第二維陣列元素列印完后換行
printf("\n");
}
return 0;
}
int main() {
int arr[3][3] = {
1, 2, 3,
4, 5, 6,
7, 8, 9
};
test(arr, sizeof(arr) / sizeof(arr[0]), sizeof(arr[0]) / sizeof(arr[0][0]));
return 0;
}
輸出:

這個例子中test函式就多接受了二維陣列的一維長度rowLen和二維長度colLen,以對二維陣列元素進行遍歷列印,
回傳“陣列”
經常有應用場景需要函式回傳一個“陣列”,說是陣列,實際上函式并無法回傳一個區域定義的陣列,哪怕是其指標(在下面一節有寫為什么),
取而代之地,常常會回傳一個指標指向分配好的一塊連續的堆記憶體,
(在演算法題中就經常能遇到要求回傳指標的情況)
int *test(size_t len) {
int i;
int *arr = (int *) malloc(len * sizeof(int));
for (i = 0; i < len; i++)
arr[i] = i + 1;
return arr;
}
int main() {
int i = 0;
int *allocated = test(5);
for (; i < 5; i++)
printf(" %d ", allocated[i]);
free(allocated); // 一定要記得釋放!
return 0;
}
這個示例中,test函式的回傳型別是整型指標,當呼叫了test函式,傳入要分配的連續記憶體長度后,其在函式內部定義了一個區域指標變數,指向分配好的記憶體,在記憶體中存放資料后將該指標回傳,
在主函式中,test回傳的整型指標被賦給了指標變數allocated,所以接下來可以通過一個回圈列印出這塊連續記憶體中的資料,
再次提醒,申請堆記憶體并使用完后,一定要記得使用free進行釋放!
生疏易犯-函式回傳區域變數
錯誤示例
記得初學C語言的時候,我曾經犯過一個錯誤:將函式內定義的陣列的陣列名作為回傳值:
int *test() {
int arr[4] = {1, 2, 3, 4};
return arr;
}
int main() {
int i = 0;
int *allocated = test();
for (; i < 4; i++)
printf(" %d ", *(allocated + i));
return 0;
}
這個例子中直到for回圈前行程仍然正常運行,但是一旦嘗試使用*運算子取出記憶體中的資料*(allocated + i),行程立馬接收到了系統發來的例外信號SIGSEGV,進而終止執行,
原因簡述
SIGSEGV是比較常見的一種例外信號,代表Signal Segmentation Violation,也就是記憶體分段沖突
造成例外的原因通常是行程 試圖訪問一段沒有分配給它的記憶體,“野指標”總是伴隨著這個例外出現,
上面簡述堆疊區的時候提到了堆疊幀,每次呼叫函式時會在堆疊上給函式分配一個堆疊幀用來儲存函式呼叫相關資訊,
函式呼叫完成后,先把運算出來的回傳值存入暫存器中,接著會在堆疊幀上進行彈堆疊操作,在這個程序中分配的區域變數就會被回收,
最后,程式在堆疊頂中取到函式的回傳地址,回傳上層函式繼續執行余下的指令,堆疊幀銷毀,此時區域變數相關的堆疊記憶體已經被回收了,
然而此時暫存器中仍存著函式的回傳值,是一個記憶體地址,但是記憶體地址代表的記憶體部分已經被回收了,
當將回傳值賦給一個指標變數時,野指標就產生了——此時這個指標變數指向一片未知的記憶體,
所以當行程試圖訪問這一片不確定的記憶體時,就容易參考到無效的記憶體,此時系統就會發送SIGSEGV信號讓行程終止執行,
教訓
教訓總結成一句話就是:
- 程式中請不要讓函式回傳代表堆疊記憶體的區域變數的地址,
延伸:回傳靜態區域變數是可以的,因為靜態區域變數是儲存在靜態儲存區的,
int *test() {
static int arr[4] = {1, 2, 3, 4};
return arr;
}
?? 如果之前例子中的test函式內這個區域陣列變數宣告為區域的靜態變數,程式就可以正常執行了,
實參結構體中的指標
改變指標變數指向的變數
用一個擁有指標變數的結構體作為實參傳入函式:
struct Hello {
int num;
int *ptr;
};
int test(struct Hello testStruct) {
printf(" [test]testStruct-Ptr: %p \n", ++testStruct.ptr);
*testStruct.ptr = 2;
return 1;
}
int main() {
int *testPtr = (int *) calloc(4, sizeof(int));
struct Hello testStruct = {
.num=5,
.ptr=testPtr
};
printf(" [main]testStruct-Ptr: %p \n\tptr[1]=%d\n", testStruct.ptr, testStruct.ptr[1]);
test(testStruct);
printf(" [main]testStruct-Ptr: %p \n\tptr[1]=%d\n", testStruct.ptr, testStruct.ptr[1]);
free(testPtr);
return 0;
}
輸出:
[main]testStruct-Ptr: 0000000000A71420
ptr[1]=0
[test]testStruct-Ptr: 0000000000A71424
[main]testStruct-Ptr: 0000000000A71420
ptr[1]=2
在test函式中,通過自增操作和*運算子給testStruct.ptr指向的下一個元素賦值為2,
通過輸出可以看到,test函式內結構體中指標變數的自增操作并沒有影響到main函式中結構體的指標變數,這是因為結構體作為引數傳入時實際上是被拷貝了一份作為區域變數以供操作,
之所以能賦值是因為testStruct.ptr是指標變數,存放著一個記憶體地址,無論怎么拷貝,變數儲存的記憶體地址是沒有變的,所以通過*運算子仍然能直接對相應資料進行賦值,
改變原結構體的指標變數指向
如果要在test函式中改變原結構體中指標變數的指向,就需要把原結構體的地址傳入函式:
int test(struct Hello *testStruct) {
printf(" [test]testStruct-Ptr: %p \n", ++testStruct->ptr);
*testStruct->ptr = 2;
return 1;
}
int main() {
int *testPtr = (int *) calloc(4, sizeof(int));
struct Hello testStruct = {
.num=5,
.ptr=testPtr
};
printf(" [main]testStruct-Ptr: %p \n\t*ptr=%d\n", testStruct.ptr, *testStruct.ptr);
test(&testStruct);
printf(" [main]testStruct-Ptr: %p \n\t*ptr=%d\n", testStruct.ptr, *testStruct.ptr);
free(testPtr);
return 0;
}
輸出:
[main]testStruct-Ptr: 00000000001A1420
*ptr=0
[test]testStruct-Ptr: 00000000001A1424
[main]testStruct-Ptr: 00000000001A1424
*ptr=2
可以看到通過在函式內通過地址訪問到對應結構體,能直接修改結構體中指標變數的指向,這個例子中通過自增運算子讓指標變數指向的記憶體地址后移了一個int的長度,
通過指標訪問結構體時使用箭頭運算子
->獲取屬性,
最近摔了一跤的地方
被自己繞進去
最近寫的一個小工具中有個自動擴大堆記憶體以容納資料的需求,最開始我寫成了這個樣:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define SIZE_PER_ALLOC 10
void extend(int *arr, int arrPtr, int *arrMax) {
*arrMax += SIZE_PER_ALLOC; // 新分配這么多
arr = (int *) realloc(arr, (*arrMax) * sizeof(int));
memset(arr + arrPtr, 0, SIZE_PER_ALLOC * sizeof(int)); // 將新分配的部分初始化為0
}
int main() {
int i;
int arrPtr = 0;
int arrMax = 10; // 當前最多能容納多少元素
int *flexible = (int *) calloc(arrMax, sizeof(int));
for (i = 0; i < 95; i++) { // 模擬push 95 個元素
flexible[arrPtr++] = i + 1;
if (arrPtr >= arrMax) // 陣列要容納不下了,多分配一點
extend(flexible, arrPtr, &arrMax);
}
for (i = 0; i < 95; i++) // 列印所有元素
printf("%d ", flexible[i]);
return 0;
}
本來預期是95個元素能順利推入flexible這個“陣列”,“陣列”大小也會擴展為足夠容納100個元素,
然而程式運行未半而中道崩殂,這個例子中系統送來了SIGSEGV信號(除錯器Debugger可能會顯示因為SIGTRAP而終止行程),根據上面寫到的SIGSEGV產生原因,很明顯我又訪問到了未分配給行程的無效記憶體(產生了野指標),
為什么吶
觀察一下函式的宣告和呼叫時的傳參:
void extend(int *arr, int arrPtr, int *arrMax);
extend(flexible, arrPtr, &arrMax);
后面的arrPtr整型變數引數接受main函式傳入的arrPtr的值,用以確定當前“陣列”的下標指向哪;而arrMax指標變數引數接受main函式傳入的arrMax的地址,用以修改當前“陣列”的大小,這兩個引數沒有引發任何問題,
很明顯了,問題就出現在arr引數這兒!
實際上,當我將指標變數flexible作為引數傳入時也只是傳入了一個地址,而不是指標本身,因此在extend里呼叫realloc重分配記憶體后,新的記憶體塊的地址會被賦給區域變數arr,此時外部的指標變數flexible的指向沒有任何改變,
realloc() 在重分配記憶體時,會盡量在原有的記憶體塊上進行擴展/縮減,盡量不移動資料,這種時候回傳的地址和原來一樣,
但是一旦原有記憶體塊及其后方相鄰的空閑記憶體不足以提供分配,就會找到一塊足夠大的新記憶體塊,并將原記憶體塊的資料“移動”過去,此時realloc()回傳的地址和原來的不同,并且原來的地址所代表的記憶體已經被回收,
也就是當realloc()移動了資料在記憶體中的位置時,外面的flexible指標變數還指向著原來的地址,原來地址代表的記憶體已經被回收了,
因此,extend函式呼叫結束后的flexible指標變數就變成了野指標,指向了一片無效記憶體,所以試圖訪問這片記憶體時,就導致了SIGSEGV例外,
怎么解決
根本原因在于我傳入函式的是一個地址而不是指標變數本身,所以把指標變數的地址傳入就能解決了!
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
#define SIZE_PER_ALLOC 10
void extend(int **arr, int arrPtr, int *arrMax) {
*arrMax += SIZE_PER_ALLOC; // 多分配這么多
*arr = (int *) realloc(*arr, (*arrMax) * sizeof(int));
memset(*arr + arrPtr, 0, SIZE_PER_ALLOC * sizeof(int)); // 將新分配的部分初始化為0
}
int main() {
int i;
int arrPtr = 0;
int arrMax = 10; // 當前最多能容納多少元素
int *flexible = (int *) calloc(arrMax, sizeof(int));
for (i = 0; i < 95; i++) { // 模擬push 95 個元素
flexible[arrPtr++] = i + 1;
if (arrPtr >= arrMax) // 陣列要容納不下了,多分配一點
extend(&flexible, arrPtr, &arrMax);
}
for (i = 0; i < 95; i++) // 列印所有元素
printf("%d ", flexible[i]);
free(flexible);
return 0;
}
因為二級指標變數存放一級指標變數的地址,所以在宣告形參arr的時候需要宣告為二級指標:
void extend(int **arr, int arrPtr, int *arrMax);
呼叫函式的時候,將指標變數flexible的地址傳入:
extend(&flexible, arrPtr, &arrMax);
接下來在函式extend內部通過*運算子訪問指標變數flexible以做出修改即可,
這樣一來程式就能成功運行完成了,輸出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95
教訓
說到最開始遇到這個問題的時候,我真的是找了半天都沒找著,因為push元素和陣列擴展我分開寫在了兩個源檔案中,而這個部分又涉及到其他記憶體分配的代碼,我甚至查了realloc是怎么導致SIGSEGV的,結果就...打斷點除錯了好多次才發現是這個問題,
涉及到指標變數和記憶體操作的時候,一定要牢記指標變數的指向,也一定要步步謹慎,不然一旦出現問題,很可能難以定位,
總結
C語言的記憶體管理很靈活,但正是因為靈活,在撰寫相關操作的時候要十分小心,
在接觸這類和底層接壤的編程語言時對基礎知識的要求真的很高...感覺咱還有超長的路要走呢,
那么就是這樣,感謝你看到這里,也希望這篇筆記能對你有些幫助!再會~

相關文章
-
【C語言】二十二步了解函式堆疊幀(壓堆疊、傳參、回傳、彈堆疊)
-
逆向基礎筆記:匯編二維陣列 - 52pojie論壇 <--- 這個筆記系列超棒的說!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/472244.html
標籤:其他
上一篇:面向物件和面向程序的區別